

Baidu empfahl die Kaltstartpraxis für Ressourcen

1. Konzept und Herausforderungen für den Kaltstart von Inhalten

Baidu Feed Recommendation ist eine umfassende Informationsfluss-Empfehlungsplattform mit Hunderten Millionen Benutzern pro Monat. Die Plattform deckt eine Vielzahl von Inhaltstypen wie Grafiken, Videos, Updates, Miniprogramme, Fragen und Antworten usw. ab. Es bietet nicht nur Click-and-Click-Empfehlungen ähnlich einer Einzel- oder Doppelspalte, sondern beinhaltet auch verschiedene Empfehlungsformen wie Video-Immersion. Gleichzeitig ist das Empfehlungssystem ein Multi-Stakeholder-System, das nicht nur die C-seitige Benutzererfahrung berücksichtigt. Inhaltsproduzenten spielen eine wichtige Rolle im Empfehlungssystem von Baidu Feed. Es gibt eine große Anzahl aktiver Praktiker, die täglich riesige Mengen an Inhalten produzieren.
Der Kern des Content-Plattform-Empfehlungssystems besteht darin, eine Win-Win-Situation für alle Parteien zu erreichen: Die Plattform muss den Benutzern weiterhin hochwertige, frische und vielfältige Inhalte empfehlen und mehr anziehen Benutzer und mehr Zeit beitragen; Für die Autorenseite: Positive Anreize von Benutzern ermutigen Autoren, mehr hochwertige Inhalte zu produzieren. Im Gegenteil, wenn die vom Autor veröffentlichten hochwertigen und frischen Inhalte nicht schnell und ausreichend Beachtung finden , wird sich der Autor dafür entscheiden, die Plattform zu verlassen, was der nachhaltigen Entwicklung nicht förderlich ist. Basierend auf der obigen Diskussion können mehrere Schlüsselwörter extrahiert werden: Frische, hohe Qualität, Vielfalt, Autorenveröffentlichung und Bindung. Dies steht in engem Zusammenhang mit dem, was in diesem Artikel behandelt wird: dem Kaltstart. Erstens sollten mehr Ressourcen in der Lage sein, eine ausreichende Anzeige zu erhalten, und durch das Sammeln von mehr Inhaltsfeedback kann die Menge der vom System empfohlenen Inhalte erhöht werden, wodurch die Vielfalt der Benutzerverbrauchsressourcen erhöht wird schnell produziert werden, um die Anzahl der Benutzer zu erhöhen, wird wiederum die Dauer des Marktes, die DAU und die Klickrate (CTR) auf der Seite des Autors steigen, es wird die Anzahl der aktiven Autoren erhöhen und die Menge der veröffentlichten Inhalte erhöhen Begeisterung des Autors.

Es gibt einige Unterschiede zwischen dem Kaltstart neuer Ressourcen und regulären Empfehlungsalgorithmen. Die Herausforderungen beim Kaltstart lassen sich in drei Hauptaspekte zusammenfassen: 1. Datenknappheit: Neue Ressourcen verfügen oft nicht über genügend Daten zum Benutzerverhalten, um personalisierte Empfehlungen in der Anfangsphase zu unterstützen. Dies führt dazu, dass der Empfehlungsalgorithmus ungenau ist
Das erste ist die Herausforderung einer genauen Empfehlung. Mit der Entwicklung von Empfehlungsalgorithmen im letzten Jahrzehnt, von der anfänglichen Matrixzerlegung bis zur späteren weit verbreiteten Anwendung von Deep Learning, hat die Rolle von ID-Typ-Merkmalen im Modell allmählich an Bedeutung gewonnen. Da jedoch die Anzahl der Kaltstart-Stichproben neuer Ressourcen selten oder nicht vorhanden ist, werden ID-Typ-Funktionen nicht ausreichend auf Kaltstart-Stichproben trainiert, was sich auf die Empfehlungsgenauigkeit auswirkt.
Zweitens kommt der Matthew-Effekt häufig in Empfehlungssystemen vor, d. h. Ressourcen, die von Benutzern erkannt wurden, werden eher empfohlen, wodurch sie mehr Aufmerksamkeit und Klicks erhalten und ihren Status weiter festigen. Umgekehrt haben neue Ressourcen Schwierigkeiten, Empfehlungen zu erhalten, und werden möglicherweise sogar völlig ignoriert. Daher müssen Empfehlungssysteme kontinuierlich optimiert werden, um sie fairer und objektiver zu gestalten.
Abschließend Wir müssen neuen Ressourcen eine gewisse Kaltstartunterstützung bieten. Wie können also neue Ressourcen effizienter und fairer unterstützt werden? Dies führt die beiden Konzepte Fairness und Unparteilichkeit ein. Fairness bezieht sich auf: Jedes Content-Produkt kann in der frühen Phase des Kaltstarts bestimmte Sichtbarkeitsmöglichkeiten erhalten und die Chance haben, fair zu konkurrieren. Fairness bedeutet: Wir müssen den Wert hochwertiger Inhalte widerspiegeln und die Qualität der Inhalte muss das Gewicht der Unterstützung von Lengqi beeinflussen können. Daher ist es auch bei neuen Ressourcen eine große Herausforderung, die richtige Balance zwischen Fairness und Gerechtigkeit zu finden, damit sich hochwertige Ressourcen hervorheben und den Gesamtnutzen maximieren können. 2. Praxis des Kaltstartalgorithmus für Inhalte Neue Ressourcen und Benutzer Die Häufigkeit ist gering und die herkömmlichen Rückrufmethoden i-to-i (Element zu Element) und u-to-i (Benutzer zu Element) sind nicht anwendbar. Daher basiert der Kaltstart hauptsächlich auf Inhaltsempfehlungsmethoden. Direkte Rückrufmethoden, die auf den grundlegendsten Benutzerporträts, Inhalts-Tags und Klassifizierungen basieren, weisen beispielsweise einen geringen Grad an Personalisierung und eine relativ schlechte Rückrufgenauigkeit auf.
ZweitensDa immer mehr Autoren personalisierte Attribute auf großen Content-Plattformen haben, ist ein Kaltstart auf Basis von Aufmerksamkeitsbeziehungen zu einer effektiven Methode geworden. Allerdings ist die Aufmerksamkeit relativ gering und kann die Beiträge vieler Autoren mit geringer Fangemeinde nicht befriedigen. Deshalb gehen wir einen Schritt weiter und verwenden Algorithmen, um potenzielle Fans von Autoren zu ermitteln, um den Einfluss von Kaltstarts basierend auf der Aufmerksamkeit zu erweitern. Beispielsweise berechnen Benutzer, die den Autor häufig konsumieren, ihm aber nicht folgen, und basierend auf der Zusammensetzung der Aufmerksamkeitsbeziehung zwischen Benutzer und Autor potenzielle Aufmerksamkeitsbeziehungen.
Darüber hinaus ist auch der multimodale Rückruf eine wirksame Methode. Mit der Entwicklung der Cross-Modal-, Multi-Model- und Large-Model-Technologie hat die Integration verschiedener modaler Inhaltsinformationen in Empfehlungssystemen erhebliche Auswirkungen, insbesondere in Kaltstart-Empfehlungssystemen. CLIP ist eine vorab trainierte Methode, die auf dem Vergleich von Text und Bildern basiert. Sie umfasst hauptsächlich zwei Module: einen Text-Encoder und einen Bild-Encoder. Sie ordnet Text- und Bildinformationen demselben Bereich zu und bietet so eine bessere Hilfe für nachgelagerte Aufgaben. Es gibt bestimmte Probleme bei der direkten Verwendung dieses Vektors für den Rückruf. Dieser Vektor stellt die vorherige Ähnlichkeit des Inhalts dar. Wir müssen die vorherige Darstellung und die in der Empfehlung erlernten Verhaltensdaten kombinieren System. Posterior-Darstellungen sind verbunden.
Die spezifische Zuordnungsmethode basiert auf der Verteilung ausreichender Einbettungs- und ausreichender Lernressourcen. Einige Proben können gesammelt und als Etiketten für das Training des Projektionsnetzwerks verwendet werden. Dieses Projektionsnetzwerk ordnet die modalübergreifende vorherige Darstellung der hinteren Verhaltensdarstellung des Empfehlungssystems zu. Ein Vorteil dieses Ansatzes besteht darin, dass die vorhandenen Recall- und Ranking-Modelle im Empfehlungssystem nahtlos genutzt werden können, ohne dass Modelle hinzugefügt werden müssen. Für das Twin Towers-Modell müssen wir beispielsweise nur die vorhandenen benutzerseitigen Vektoren verwenden, ohne Änderungen vorzunehmen, und dann das Projektionsnetzwerk verwenden, um die neuen Ressourcen in den hinteren Darstellungsraum des Twin Towers-Modells zu projizieren, sodass wir Sie können einfach und schnell einen Twin Towers-Rückruf online durchführen. In ähnlicher Weise können auch der vorhandene Diagrammrückruf und der baumbasierte Rückruf zu geringen Kosten implementiert werden.Natürlich hat diese Zuordnungsmethode einen kleinen Nachteil, nämlich die Regression ist schwieriger. Bei CB2CF handelt es sich um ein Regressionsproblem, und Regression ist im Allgemeinen schwer zu erlernen. Daher können wir auch einen paarweisen Ansatz verwenden, um Zuordnungsbeziehungen zu lernen. Insbesondere können die positiven Stichproben auf ähnliche Elementpaare gesetzt werden, die von der Element-CF gelernt wurden. Die negativen Stichproben können durch globale negative Stichproben usw. erhalten werden. Die Eingabe umfasst auch einige vorherige und dynamische Informationen des Elements und dann eine solche Zuordnung.
Durch die Nutzung der Vorabinformationen des Inhalts ist es grundsätzlich möglich, die am Markt gängigen Rückrufmethoden zum Kaltstart effektiv umzusetzen.
2. Kaltstart basierend auf Seed-Benutzern

Ein wichtiger Vorteil von Lookalike ist, dass es extrem in Echtzeit arbeitet. Diese Methode stammt hauptsächlich aus dem Bereich der Internetwerbung. In der Vergangenheit wählten Werbetreibende einige potenziell interessierte Benutzer als Seed-Benutzer aus, und das System suchte dann nach ähnlichen Benutzern dieser Seed-Benutzer, um sie zu verbreiten. Im Empfehlungssystem können wir Online-Echtzeit-Streaming-Protokolle abonnieren, um positives Feedback zu Ressourcen zu erhalten, die bei früheren Kaltstarts gesammelt wurden, wie z. B. Klicks, Wiedergaben, Interaktionen, Aufmerksamkeit usw., und sogar negatives Feedback, wie z. B. Benutzer, die wischen schnell. Basierend auf diesen Seed-Benutzern kann das System dann die Darstellung des Elements durch die Einbettung des Benutzers und durch verschiedene Aggregationsmethoden oder das Hinzufügen einiger Selbstaufmerksamkeitsmechanismen erhalten. Diese Darstellung kann sehr schnell aktualisiert und dann basierend auf dieser Darstellung, die eine sehr hohe Aktualität aufweist, nach außen verbreitet werden. 3. Experimentelles Kaltstartsystem für Inhalte . und dynamische Parameter des Modells. Diese drei Paradigmen können tatsächlich in Kombination miteinander verwendet werden.
Für die ID-Verwerfungsoptimierung kann das Modell aufgrund der geringen Anzahl von Gesamtressourcenproben problemlos auf die Kopfressourcen eingehen. Daher ist das ID-Lernen der Kopfressourcen sehr ausreichend, und die Merkmalsbedeutung im Modell ist ebenfalls ausreichend besonders hoch. Das Auftreten von Kaltstartressourcen ist jedoch geringer und das ID-Lernen ist unzureichend. Es gibt zwei Möglichkeiten, über dieses Problem nachzudenken: Die eine besteht darin, die Verwendung von IDs so weit wie möglich zu vermeiden, und die andere darin, IDs besser zu nutzen.
Das erste Paradigma ist die Dropout-Optimierung, und eine der klassischen Methoden ist DropoutNet. Während des Trainingsprozesses verwirft DropoutNet nach dem Zufallsprinzip Element-ID- und Benutzer-ID-Funktionen, um den Schwerpunkt des Modells auf Nicht-ID-Funktionen zu maximieren und die Generalisierungsfähigkeit des Modells zu verbessern. Dadurch kann der Kaltstarteffekt neuer Benutzer oder neuer Ressourcen tatsächlich verbessert werden.
Darüber hinaus sind in den letzten Jahren auch einige vergleichende Lernmethoden aufgetaucht. Kontrastives Lernen ist eine selbstüberwachte Lernmethode, die nicht auf manuelle Anmerkungen angewiesen ist und eine große Anzahl von Stichproben erstellen kann, was zur Optimierung des Multiband-Kaltstartproblems beiträgt, da wir zusätzliche Stichproben erstellen können, um den Status der Kaltstartdaten zu stärken . Beispielsweise kann beim Zwei-Turm-Modell ein zusätzlicher Kontrastverlust auf der Artikelseite hinzugefügt werden. Die Parameter der beiden Türme werden gemeinsam genutzt. Durch die Maskierungsmethode können Proben mit ID-Merkmalen und anderen Kaltstartmerkmalen in unterschiedlichen Anteilen maskiert werden Berücksichtigen Sie die Generalisierungsfähigkeit des Modells und die Spezifität der Kaltstartressourcen.

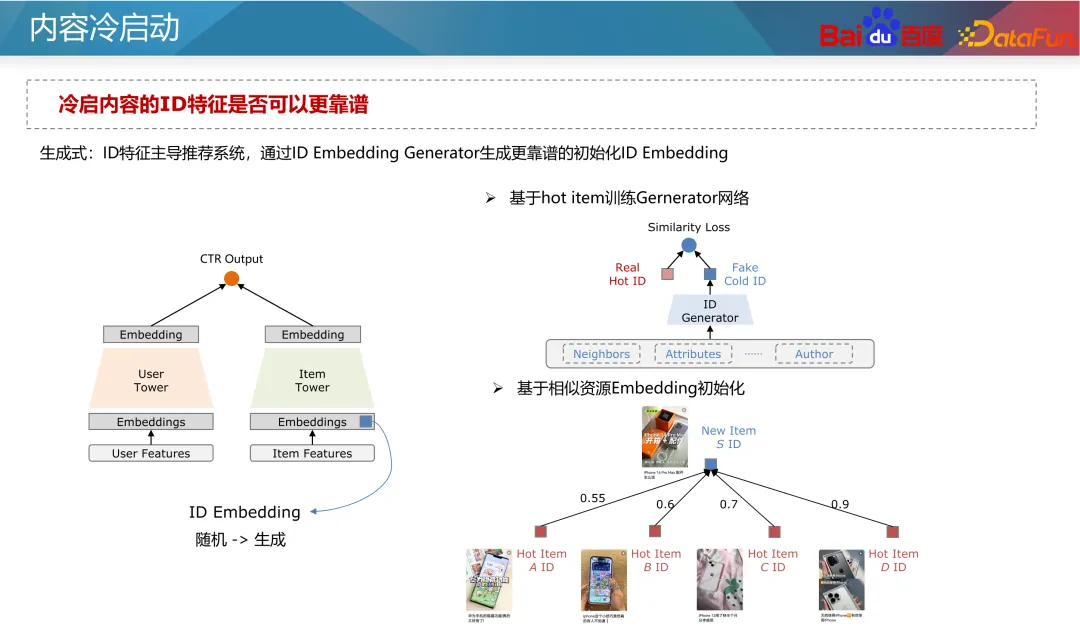
Der nächste Schritt ist die generative Optimierung. Wie bereits erwähnt, sollten unzuverlässige ID-Funktionen so wenig wie möglich verwendet werden, aber derzeit besteht der bessere Ansatz darin, sie zuverlässiger zu machen. Die herkömmliche Idee besteht darin, die Einbettung der ID basierend auf den vorherigen Merkmalen der ID zu initialisieren. Durch eine angemessene Initialisierung kann die Vorhersage neuer Ressourcen genauer sein und schneller konvergieren. Am Beispiel des Zwillingsturmmodells werden neue Features normalerweise zufällig initialisiert oder mit nur Nullen initialisiert, was zur Vorhersage neuer Ressourcen führt. Ungenau und langsame Konvergenz. Daher können einige A-priori-Funktionen des Inhalts wie Tags, Inhalts-Tags, Autoren-Tags usw. sowie einige ähnliche IDs (z. B. beliebte IDs) verwendet werden, um einige ID-Einbettungen mit ausreichend hohem posteriori und hohem Wert auszuwählen Verteilungsressourcen als Tags. Trainieren Sie dann einen Generator, um eine Einbettung der ID zu generieren, um den Anfangswert zu ersetzen. Natürlich können Sie die ID-Einbettungen der neuen Ressource auch direkt mit den ähnlichsten Top-K-Ressourcen mitteln, da die Einbettungsinitialisierung der neuen Ressource relativ stabil ist und die Kosten sehr niedrig sind Industrie.
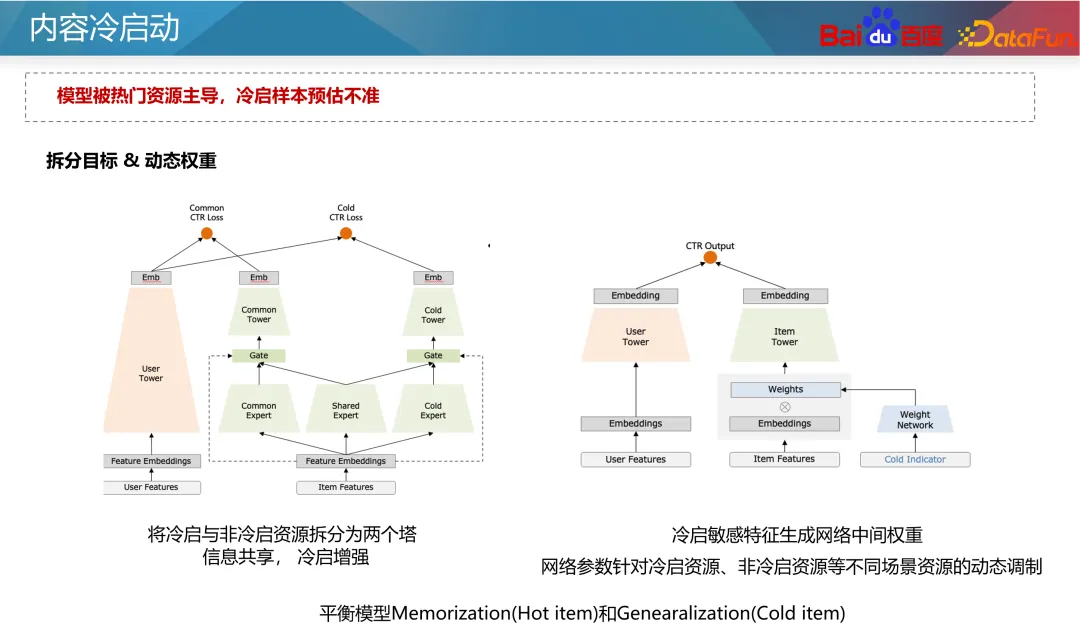
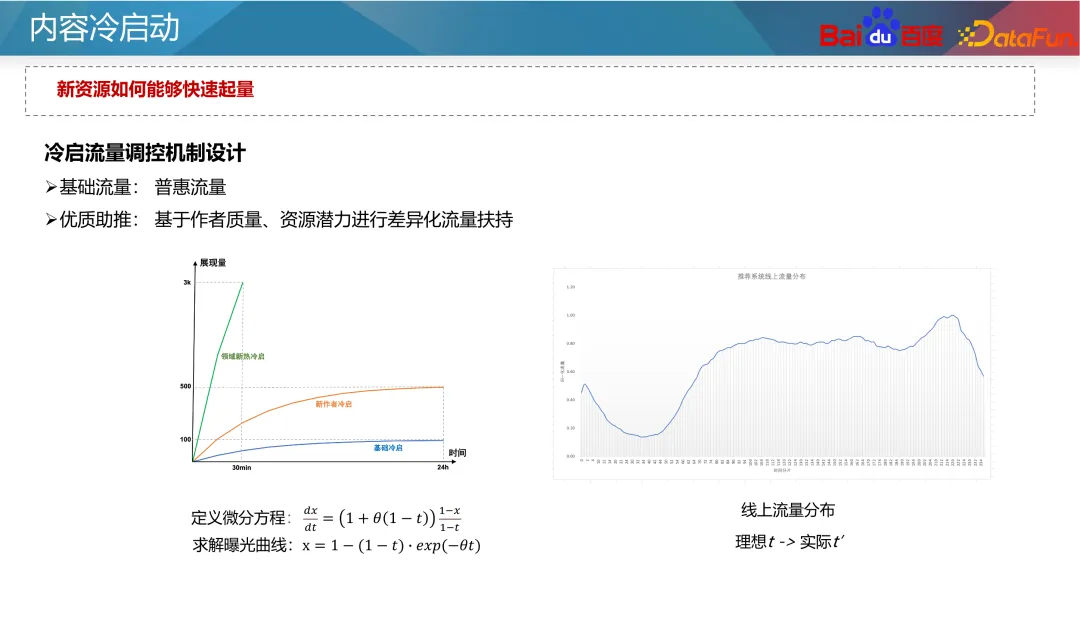
Für das Problem, dass beliebte IDs das Modell dominieren und das Modell stärker auf ID-Funktionen angewiesen ist, können wir zur Optimierung Ideen für mehrere Aufgaben und Szenarien verwenden. Am Beispiel des Twin-Tower-Modells lässt sich die Vorhersage der Kaltstart- und Nicht-Kaltstart-Ressourcen in zwei unabhängige Ziele aufteilen. Durch gängige Mehrzielmodelle schenkt das Modell neuen Inhalten mehr Aufmerksamkeit. Ein klassischer Ansatz ist das CGC-Netzwerk, links in der Abbildung oben dargestellt. In dieser Art von Netzwerk teilen sich alle Aufgaben die Einbettungsschicht, und dann werden unabhängige Expertennetzwerke durch Kaltstartaufgaben bzw. Nicht-Kaltstartaufgaben erlernt, um die Fähigkeit zur Kaltstartvorhersage zu verbessern. Eine andere Methode besteht darin, die Parametergewichte verschiedener Ressourcentypen im Netzwerk durch dynamische Gewichte anzupassen, wie im rechten Teil der obigen Abbildung dargestellt. In diesem Netzwerk ist das Netzwerk ganz rechts ein Kaltstartindikator, der Informationen über Kaltstartressourcen empfängt (z. B. die aktuelle Anzahl von Klickimpressionen und Ressourcentypen) und dann die Gewichte jeder Schicht des Netzwerks ausgibt, um Informationen unter verschiedenen zu steuern Der Übertragungskanal im Netzwerk ermöglicht dem Modell eine genauere Vorhersage unter Kaltstartbedingungen. 2. Entwurf von Verkehrskontrollmechanismen eine gewisse Neigung zu neuen Ressourcen. Die allgemeine Kaltstartneigung kann in zwei Flüsse unterteilt werden: Basisfluss und Boostfluss. Basisdatenverkehr bedeutet Fairness, und wir müssen allen Ressourcen zu Testzwecken einen inklusiven Datenverkehr zur Verfügung stellen. Die Steigerung des Traffics bietet differenzierte Unterstützung basierend auf dem geschätzten Potenzial der Qualitätsressourcen des Autors und der Leistung des primären Traffics.
Der Unterstützungsmechanismus des Kaltstarts hat auf abstrakter Ebene zwei Parameter: Zeit und Verteilungsvolumen, das heißt, durch erzwungenes Einfügen, Leistungsanpassung und andere Mittel können Ressourcen innerhalb einer bestimmten Zeit ein bestimmtes Verteilungsvolumenziel erreichen. Für verschiedene Unternehmen legen wir unterschiedliche Vertriebsvolumina und erforderliche Zeiten fest. Für gewöhnliche Ressourcen können beispielsweise 100 Impressionen innerhalb von 24 Stunden ausreichen; für neue und beliebte Ressourcen kann es schneller sein, beispielsweise 3.000 Impressionen innerhalb einer halben Stunde. Gleichzeitig kann eine größere Kaltstartquote für neue Autoren festgelegt werden.
Konkret ausgedrückt stellt t in der Formel die Normalisierung der aktuellen Release-Zeit dividiert durch die für das Ziel erforderliche Zeit dar, also den aktuellen Zeitfortschritt, und x repräsentiert den aktuellen Verteilungsfortschritt. Wir möchten, dass t und x gleich sind, was eine Verteilung mit normalem Fortschritt bedeutet. Wenn x kleiner als t ist, bedeutet dies, dass die aktuelle Kaltstartgeschwindigkeit langsam ist und das Gewicht erhöht oder der Koeffizient erzwungen werden muss. θ in der Formel kann den Grad der Neigung der Ressourcenzuteilung im Frühstadium steuern.
Die Prämisse dieser Formel ist jedoch, dass der Produktverkehr in verschiedenen Zeiträumen einheitlich ist, die tatsächliche Situation diese Annahme jedoch nicht erfüllt. Die Verkehrsverteilung allgemeiner Internetprodukte weist Spitzen- und Tiefstunterschiede auf und muss daher an die tatsächliche Situation angepasst werden. Wenn ein Inhalt beispielsweise um 2 Uhr morgens veröffentlicht wird, sind bis 8 Uhr möglicherweise nur 25 Zustellungen erforderlich, da in den frühen Morgenstunden weniger Verkehr herrscht. Daher muss t in der Formel basierend auf der tatsächlichen Durchflussverteilung integriert werden.
3. Auswahl der Bereitstellungsbenutzer
Eine weitere wichtige Frage ist, an welche Benutzer die Ressourcen in den frühen Phasen der Ressourcenverteilung bereitgestellt werden sollen. Der gebräuchlichste Ansatz besteht darin, zu versuchen, neue Ressourcen eher alten Benutzern als neuen Benutzern zu empfehlen, da alte Benutzer normalerweise toleranter sind und ungenaue Empfehlungen für neue Ressourcen vermeiden können, die neuen Benutzern schaden würden. Wenn außerdem die Verbesserung der Kaltstartressourcen als Intervention betrachtet wird, basierend auf der Uplift-Idee, können die Auswirkungen der Intervention auf die Benutzerdauer und -bindung gelernt werden, und es können Benutzer ausgewählt werden, die keinen negativen Einfluss auf die Intervention haben für Kaltstart.
Die beiden oben genannten Punkte basieren auf den Auswirkungen von C-Seiten-Benutzern. Die Auswahl des Kaltstartpublikums wirkt sich jedoch auch auf die spätere Kommunikationsentwicklung der Ressourcen aus. Aus Sicht der Informationsverbreitung unterteilt die Zwei-Ebenen-Kommunikationstheorie die Informationsverbreitung in zwei Schritte. Erstens verfügen einige Personengruppen, die wir Meinungsführer nennen, über die Fähigkeit, Informationen aus der großen Menge an täglich generierten Informationen herauszufiltern und zu fördern. Dann werden sich die von diesen Meinungsführern verstärkten und geförderten Ressourcen in großem Umfang verbreiten.
In der aktuellen Zeit existiert die Rolle von Meinungsführern auch auf sozialen Plattformen, bekannten Medien, Fernsehsendern usw. Für Empfehlungssysteme gibt es auch das Konzept der Key-Node-Benutzerressourcen. Sie filtern hochwertige Ressourcen und geben Empfehlungen ab, wodurch sie das Konsumverhalten anderer Benutzer beeinflussen.
Wie kann man also diese Schlüsselnutzer ansprechen? Aus der obigen Diskussion geht hervor, dass Hauptbenutzer zwei Merkmale aufweisen: Erstens verfügen sie über eine hohe Fähigkeit, die Ressourcenqualität zu erkennen, und zweitens besteht eine hohe Wahrscheinlichkeit, dass ihre empfohlenen Inhalte von anderen Benutzern akzeptiert werden. Daher gibt es zwei Abbaumethoden:
Erstens werden die Ressourcen entsprechend ihrem späteren Zustand in hochwertige und minderwertige Ressourcen unterteilt und als Etiketten verwendet. Anschließend werden die Benutzer-IDs, die ursprünglich auf diese Ressourcen geklickt haben, als Merkmale verwendet, um die spätere Situation der Ressourcen vorherzusagen. Das Gewicht jeder vom Modell gelernten Benutzer-ID kann als Schlüsselindex des Benutzers betrachtet werden.
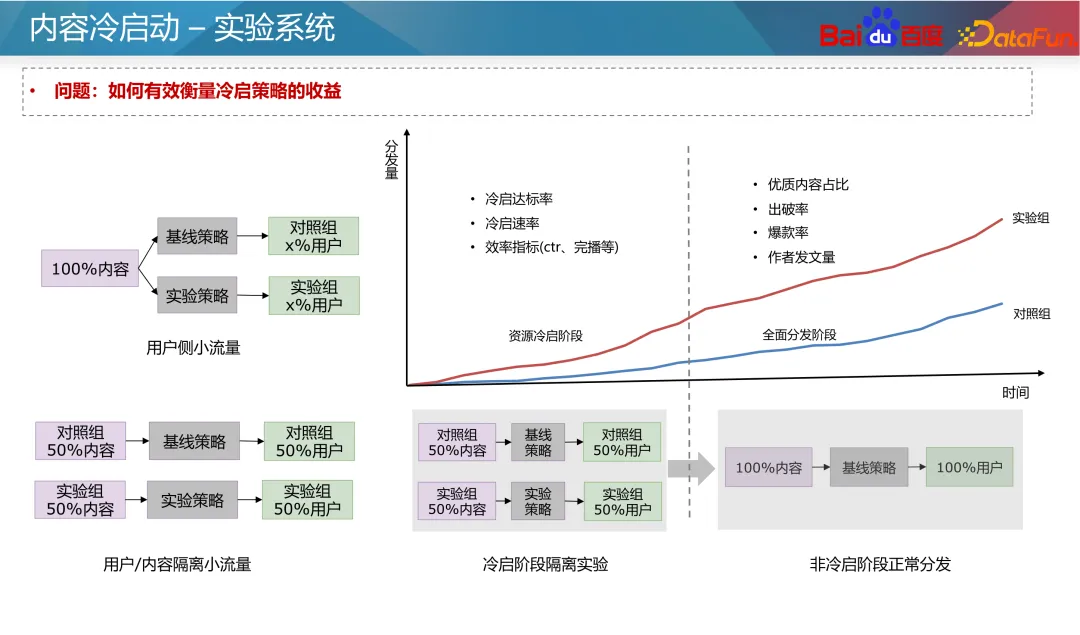
Zweitens können Sie mithilfe des kollaborativen Filterempfehlungssystems für Online-Benutzer die Empfehlungserfolgsrate zwischen Benutzern untersuchen. Benutzer mit einer höheren Empfehlungserfolgsquote können als Hauptbenutzer im Empfehlungssystem angesehen werden. Durch diese beiden Methoden werden wichtige Benutzer im Diagramm ermittelt und ihnen beim Kaltstart der Ressourcen zuerst empfohlen. 4. Experimentelles System Die experimentelle Gruppe wird auch mit dem Lernen in der Gruppe verglichen, was es schwierig macht, die Wirkung der Kaltstartstrategie genau zu messen. Daher müssen wir Experimente zur Inhaltsisolierung durchführen, um die Auswirkungen der Kaltstartstrategie auf das gesamte System zu bewerten.
Ein gängiges experimentelles Design besteht darin, Benutzer und Ressourcen vollständig zu isolieren, wie im unteren linken Teil der obigen Abbildung dargestellt. Unter ihnen können 50 % der Benutzer nur 50 % des Inhalts sehen und verschiedene Ressourcengruppen verwenden unterschiedliche Kaltstartstrategien. Dadurch können Sie die Auswirkungen der Kaltstartstrategie auf das gesamte System bewerten. Allerdings hat diese Methode möglicherweise größere Auswirkungen auf die Erfahrung von C-Seiten-Benutzern, da diese nur einen Teil des Inhalts sehen können.
Eine weitere sanfte Möglichkeit besteht darin, Benutzer und Ressourcen während der Kaltstartphase, beispielsweise den ersten 3000 Malen, vollständig zu isolieren und dann unterschiedliche Kaltstartstrategien für verschiedene Gruppen zu implementieren. Nach einem Kaltstart können Ressourcen an alle Benutzer verteilt werden. Ein solches Design kann die Auswirkungen auf die Benutzererfahrung auf der C-Seite verringern.
Durch Experimente können wir die folgenden Indikatoren analysieren:
- Kaltstart-Konformitätsrate, Geschwindigkeits- und Effizienzindikatoren während der Kaltstartphase, wie Klickrate (CTR), Abschlussrate usw.
- In der vollständigen Verbreitungsphase werden Indikatoren wie der Anteil hochwertiger Inhalte verschiedener Ressourcengruppen, die Breakout-Rate, die Trefferquote und die Anzahl der vom entsprechenden Autor veröffentlichten Artikel berücksichtigt.
4. Fragen und Antworten
F1: Wie beurteilt man die heißen und kalten Zwillingstürme? Einer ist ein heißer Turm und der andere ist ein kalter Turm.
A1: Die Beurteilung von heißen und kalten Türmen basiert in der Regel auf der Verteilung der Ressourcen. Im Allgemeinen gelten Ressourcen mit geringerem Verteilungsvolumen als Kalttürme, während Ressourcen mit höherem Verteilungsvolumen als Heißtürme gelten. Beispielsweise kann eine Ressource, die weniger als 100 Mal verteilt wurde, als Kaltstartressource betrachtet werden. Natürlich ist es notwendig, die Vorhersagegenauigkeit des Online-Modells zu analysieren und spezifische Beurteilungsstandards basierend auf der tatsächlichen Situation zu bestimmen.
F2: Wie lässt sich das Ressourcenpotenzial beurteilen, wenn der Kaltstartverkehr mit hoher Qualität gesteigert wird? Nutzen Sie Wertmodelle, um abzuschätzen, ob es sich um ein neues, aktuelles Thema in diesem Bereich handelt?
A2: Zur Qualitätssteigerung des Kaltstartverkehrs gehört in der Regel eine Einschätzung des Ressourcenpotenzials. Bei der Beurteilung des Ressourcenpotenzials können mehrere Signalquellen kombiniert werden. Um beispielsweise festzustellen, ob es sich um ein neues heißes Thema in diesem Bereich handelt, können Sie die Informationen des gesamten Netzwerks umfassend berücksichtigen, einschließlich der Hotlist-Informationen zu jedem Produkt sowie Themendiskussionen und Aufmerksamkeit in verwandten Bereichen usw. Bei der Bewertung des Ressourcenwerts kann die Qualität des Autors berücksichtigt werden, einschließlich Faktoren wie seiner Leistung in der Anfangsphase und seinen Interaktionen. Durch die umfassende Nutzung dieser Informationen kann eine umfassendere Einschätzung des Ressourcenpotenzials vorgenommen werden.
F3: Wie löst man das ideale t und das tatsächliche t? Spiegelt sich das in der Belichtungskurve wider? So stellen Sie sicher, dass das tatsächliche Engagement mit dem Markttrend übereinstimmt.
A3: Bei der Lösung nach idealer t und tatsächlicher t kann dies durch Beobachtung der Belichtungskurve widergespiegelt werden. Die Expositionskurve zeigt die Exposition von Ressourcen in verschiedenen Zeiträumen. Die ideale t bezieht sich auf den theoretischen Expositionsverlauf, der auf der Grundlage der eingestellten Zielzeit berechnet wird, während die tatsächliche t auf der Grundlage des aktuellen tatsächlichen Expositionsverlaufs ermittelt wird. Um sicherzustellen, dass die tatsächliche Exposition mit dem Gesamtmarkttrend übereinstimmt, muss der Anteil des Gesamtverkehrs stabil überwacht werden, um sicherzustellen, dass der Fortschritt des Kaltstarts mit dem Gesamtverkehrstrend übereinstimmt. Wenn der Kaltstart langsam voranschreitet, müssen Sie möglicherweise die Belichtung erhöhen oder andere empfohlene Strategien anpassen, um den Fortschritt zu beschleunigen. Wenn der Fortschritt zu schnell ist, müssen Sie möglicherweise die Belichtungsgeschwindigkeit verlangsamen, um eine Überbelichtung der Ressourcen zu vermeiden.
F4: Benutzer können während des Experiments nur 50 % des Inhalts und bei voller Kapazität 100 % des Inhalts sehen. Wie kann man beweisen, dass das Experiment mit der vollständigen Wirkung übereinstimmt?
A4: Was das Problem des Kaltstarts betrifft, ist es tatsächlich sehr schwierig, den genauen Wert des Effekts genau zu messen. Heutzutage vergleichen wir normalerweise die Versuchsgruppe und die Kontrollgruppe, um herauszufinden, welche besser ist.
 Konkret ausgedrückt stellt t in der Formel die Normalisierung der aktuellen Release-Zeit dividiert durch die für das Ziel erforderliche Zeit dar, also den aktuellen Zeitfortschritt, und x repräsentiert den aktuellen Verteilungsfortschritt. Wir möchten, dass t und x gleich sind, was eine Verteilung mit normalem Fortschritt bedeutet. Wenn x kleiner als t ist, bedeutet dies, dass die aktuelle Kaltstartgeschwindigkeit langsam ist und das Gewicht erhöht oder der Koeffizient erzwungen werden muss. θ in der Formel kann den Grad der Neigung der Ressourcenzuteilung im Frühstadium steuern.
Konkret ausgedrückt stellt t in der Formel die Normalisierung der aktuellen Release-Zeit dividiert durch die für das Ziel erforderliche Zeit dar, also den aktuellen Zeitfortschritt, und x repräsentiert den aktuellen Verteilungsfortschritt. Wir möchten, dass t und x gleich sind, was eine Verteilung mit normalem Fortschritt bedeutet. Wenn x kleiner als t ist, bedeutet dies, dass die aktuelle Kaltstartgeschwindigkeit langsam ist und das Gewicht erhöht oder der Koeffizient erzwungen werden muss. θ in der Formel kann den Grad der Neigung der Ressourcenzuteilung im Frühstadium steuern. 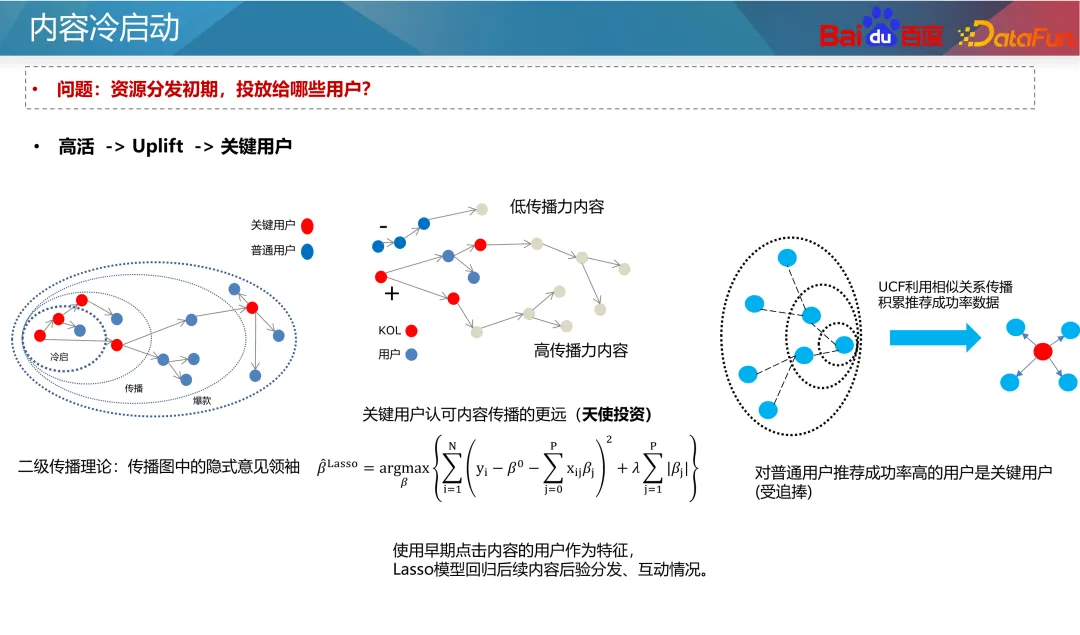
 Eine weitere sanfte Möglichkeit besteht darin, Benutzer und Ressourcen während der Kaltstartphase, beispielsweise den ersten 3000 Malen, vollständig zu isolieren und dann unterschiedliche Kaltstartstrategien für verschiedene Gruppen zu implementieren. Nach einem Kaltstart können Ressourcen an alle Benutzer verteilt werden. Ein solches Design kann die Auswirkungen auf die Benutzererfahrung auf der C-Seite verringern.
Eine weitere sanfte Möglichkeit besteht darin, Benutzer und Ressourcen während der Kaltstartphase, beispielsweise den ersten 3000 Malen, vollständig zu isolieren und dann unterschiedliche Kaltstartstrategien für verschiedene Gruppen zu implementieren. Nach einem Kaltstart können Ressourcen an alle Benutzer verteilt werden. Ein solches Design kann die Auswirkungen auf die Benutzererfahrung auf der C-Seite verringern. Das obige ist der detaillierte Inhalt vonBaidu empfahl die Kaltstartpraxis für Ressourcen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1668
1668
 14
1428
52
1329
25
1273
29
1256
24
14
1428
52
1329
25
1273
29
1256
24

 So implementieren Sie ein Empfehlungssystem mit der Go-Sprache und Redis
Oct 27, 2023 pm 12:54 PM
So implementieren Sie ein Empfehlungssystem mit der Go-Sprache und Redis
Oct 27, 2023 pm 12:54 PM
So verwenden Sie die Go-Sprache und Redis zur Implementierung eines Empfehlungssystems. Das Empfehlungssystem ist ein wichtiger Bestandteil der modernen Internetplattform. Es hilft Benutzern, interessante Informationen zu finden und zu erhalten. Die Go-Sprache und Redis sind zwei sehr beliebte Tools, die bei der Implementierung von Empfehlungssystemen eine wichtige Rolle spielen können. In diesem Artikel wird erläutert, wie Sie mithilfe der Go-Sprache und Redis ein einfaches Empfehlungssystem implementieren, und es werden spezifische Codebeispiele bereitgestellt. Redis ist eine Open-Source-In-Memory-Datenbank, die eine Speicherschnittstelle für Schlüssel-Wert-Paare bereitstellt und eine Vielzahl von Daten unterstützt
 Anwendungsbeispiel: Mit go-micro ein Microservice-Empfehlungssystem aufbauen
Jun 18, 2023 pm 12:43 PM
Anwendungsbeispiel: Mit go-micro ein Microservice-Empfehlungssystem aufbauen
Jun 18, 2023 pm 12:43 PM
Mit der Popularität von Internetanwendungen ist die Microservice-Architektur zu einer beliebten Architekturmethode geworden. Unter anderem besteht der Schlüssel zur Microservice-Architektur darin, die Anwendung in verschiedene Dienste aufzuteilen und über RPC zu kommunizieren, um eine lose gekoppelte Service-Architektur zu erreichen. In diesem Artikel stellen wir vor, wie man mit go-micro ein Microservice-Empfehlungssystem basierend auf tatsächlichen Fällen erstellt. 1. Was ist ein Microservice-Empfehlungssystem? Ein Microservice-Empfehlungssystem ist ein Empfehlungssystem, das auf einer Microservice-Architektur basiert. Es integriert verschiedene Module in das Empfehlungssystem (z. B. Feature-Engineering, Klassifizierung).
 Das Geheimnis einer genauen Empfehlung: Detaillierte Erläuterung des unvoreingenommenen Rückrufmodells für die entkoppelte Domänenanpassung von Alibaba
Jun 05, 2023 am 08:55 AM
Das Geheimnis einer genauen Empfehlung: Detaillierte Erläuterung des unvoreingenommenen Rückrufmodells für die entkoppelte Domänenanpassung von Alibaba
Jun 05, 2023 am 08:55 AM
1. Einführung in das Szenario Zunächst stellen wir das in diesem Artikel beschriebene Szenario vor – das Szenario „Gute Waren sind verfügbar“. Seine Position befindet sich im Vierquadratraster auf der Homepage von Taobao, die in eine One-Hop-Auswahlseite und eine Two-Hop-Akzeptanzseite unterteilt ist. Es gibt zwei Hauptformen von Akzeptanzseiten: eine ist die Bild- und Text-Akzeptanzseite und die andere ist die kurze Video-Akzeptanzseite. Das Ziel dieses Szenarios besteht hauptsächlich darin, den Benutzern zufriedenstellende Waren bereitzustellen und das Wachstum des GMV voranzutreiben, wodurch das Angebot an Experten weiter genutzt wird. 2. Was ist ein Beliebtheitsbias und warum befassen wir uns als nächstes mit dem Beliebtheitsbias? Was ist ein Beliebtheitsbias? Warum kommt es zu einem Beliebtheitsbias? 1. Was ist Popularitätsbias? Es gibt viele Pseudonyme, wie zum Beispiel Matthew-Effekt und Informationskokonraum. Intuitiv gesehen ist es ein Karneval hochexplosiver Produkte. Je beliebter das Produkt ist, desto einfacher ist es. Dies wird dazu führen
 In Java implementierte Algorithmen und Anwendungen von Empfehlungssystemen
Jun 19, 2023 am 09:06 AM
In Java implementierte Algorithmen und Anwendungen von Empfehlungssystemen
Jun 19, 2023 am 09:06 AM
Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Internet-Technologie werden Empfehlungssysteme als wichtige Technologie zur Informationsfilterung immer häufiger eingesetzt und beachtet. Bei der Implementierung von Empfehlungssystemalgorithmen ist Java als schnelle und zuverlässige Programmiersprache weit verbreitet. In diesem Artikel werden die in Java implementierten Empfehlungssystemalgorithmen und -anwendungen vorgestellt und der Schwerpunkt auf drei gängige Empfehlungssystemalgorithmen gelegt: benutzerbasierter kollaborativer Filteralgorithmus, artikelbasierter kollaborativer Filteralgorithmus und inhaltsbasierter Empfehlungsalgorithmus. Der benutzerbasierte kollaborative Filteralgorithmus basiert auf benutzerbasierter kollaborativer Filterung
 Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Nov 14, 2023 am 08:14 AM
Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Nov 14, 2023 am 08:14 AM
1. Problemhintergrund: Die Notwendigkeit und Bedeutung der Kaltstartmodellierung. Als Content-Plattform stellt Cloud Music täglich eine große Menge neuer Inhalte online. Obwohl die Menge an neuen Inhalten auf der Cloud-Musikplattform im Vergleich zu anderen Plattformen, wie etwa Kurzvideos, relativ gering ist, kann die tatsächliche Menge die Vorstellungskraft eines jeden bei weitem übersteigen. Gleichzeitig unterscheiden sich Musikinhalte deutlich von kurzen Videos, Nachrichten und Produktempfehlungen. Der Lebenszyklus von Musik erstreckt sich über extrem lange Zeiträume, oft gemessen in Jahren. Manche Songs können explodieren, nachdem sie monate- oder jahrelang inaktiv waren, und klassische Songs können auch nach mehr als zehn Jahren noch eine starke Vitalität haben. Daher ist es für das Empfehlungssystem von Musikplattformen wichtiger, unpopuläre und qualitativ hochwertige Long-Tail-Inhalte zu entdecken und sie den richtigen Nutzern zu empfehlen, als andere Kategorien zu empfehlen.
 Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
May 16, 2023 pm 11:21 PM
Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
May 16, 2023 pm 11:21 PM
Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Cloud-Computing-Technologie werden Cloud-Such- und Empfehlungssysteme immer beliebter. Als Antwort auf diese Nachfrage bietet die Go-Sprache ebenfalls eine gute Lösung. In der Go-Sprache können wir die Funktionen zur gleichzeitigen Hochgeschwindigkeitsverarbeitung und die umfangreichen Standardbibliotheken nutzen, um ein effizientes Cloud-Such- und Empfehlungssystem zu implementieren. Im Folgenden wird vorgestellt, wie die Go-Sprache ein solches System implementiert. 1. Suche in der Cloud Zunächst müssen wir die Vorgehensweise und die Prinzipien der Suche verstehen. Die Suchposition bezieht sich auf die Suchmaschinen-Matching-Seiten basierend auf den vom Benutzer eingegebenen Schlüsselwörtern.
 Tipps zur Verwendung des Caches zur Verarbeitung von Empfehlungssystem-Optimierungsalgorithmen in Golang.
Jun 20, 2023 pm 06:28 PM
Tipps zur Verwendung des Caches zur Verarbeitung von Empfehlungssystem-Optimierungsalgorithmen in Golang.
Jun 20, 2023 pm 06:28 PM
Das Empfehlungssystem ist ein in Internetprodukten weit verbreiteter Algorithmus und spielt eine wichtige Rolle bei der Verbesserung des Benutzererlebnisses und der Steigerung des Produktwerts. In Empfehlungssystemen kann die Algorithmusoptimierung die Empfehlungsgenauigkeit und Benutzerzufriedenheit verbessern. Die Verwendung von Caching zur Verarbeitung des Optimierungsalgorithmus des Empfehlungssystems in Golang kann die Leistung und Effizienz verbessern. Hier sind einige Tipps. 1. Caching-Grundlagen: Was ist Caching? Der Cache dient dazu, einige häufig wiederverwendete Daten in einem temporären Speicherbereich zu speichern, wenn ein Programm oder eine Anwendung verwendet wird, damit das Programm dies tun kann
 Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
1. Hintergrund der Ursache-Wirkungs-Korrektur 1. Abweichungen treten im Empfehlungssystem auf. Das Empfehlungsmodell wird durch das Sammeln von Daten trainiert, um Benutzern geeignete Elemente zu empfehlen. Wenn Benutzer mit empfohlenen Elementen interagieren, werden die gesammelten Daten verwendet, um das Modell weiter zu trainieren und so einen geschlossenen Regelkreis zu bilden. Allerdings kann es in diesem geschlossenen Kreislauf verschiedene Einflussfaktoren geben, die zu Fehlern führen. Der Hauptgrund für den Fehler besteht darin, dass es sich bei den meisten zum Trainieren des Modells verwendeten Daten um Beobachtungsdaten und nicht um ideale Trainingsdaten handelt, die von Faktoren wie der Expositionsstrategie und der Benutzerauswahl beeinflusst werden. Der Kern dieser Verzerrung liegt im Unterschied zwischen den Erwartungen empirischer Risikoschätzungen und den Erwartungen echter idealer Risikoschätzungen. 2. Häufige Vorurteile Es gibt drei Haupttypen häufiger Vorurteile in Empfehlungsmarketingsystemen: Selektive Voreingenommenheit: Sie ist auf die Herkunft des Benutzers zurückzuführen
