

Mit der Entwicklung und Durchbrüchen der Deep-Learning-Technologie haben kürzlich groß angelegte Grundlagenmodelle bedeutende Ergebnisse in den Bereichen natürliche Sprachverarbeitung und Computer Vision erzielt. Große Entwicklungsperspektiven bietet auch die Anwendung von Basismodellen beim autonomen Fahren, die das Verständnis und die Argumentation von Szenarien verbessern können.
Dieser Artikel beschreibt hauptsächlich die Anwendung des Basismodells im Bereich des autonomen Fahrens und basiert auf der Anwendung des Basismodells im autonomen Fahrmodell, der Anwendung des Basismodells bei der Datenverbesserung und der Anwendung des Weltmodell im Basismodell zum autonomen Fahren in Aspekten erweitern. Im Hinblick auf autonome Fahrmodelle können Basismodelle verwendet werden, um verschiedene autonome Fahrfunktionen wie Fahrzeugwahrnehmung, Entscheidungsfindung und Steuerung zu implementieren. Durch das Basismodell kann das Fahrzeug Informationen über die Umgebung erhalten und entsprechende Entscheidungen und Steuerungsmaßnahmen treffen. Im Hinblick auf die Datenverbesserung kann das Basismodell zur Datenverbesserung verwendet werden.
Link zu diesem Artikel: https://arxiv.org/pdf/2405.02288 und visuelle Grundmodelle
Viele Arbeiten haben gezeigt, dass Sprache und visuelle Funktionen das Verständnis des Modells für die Fahrszene effektiv verbessern können, nachdem das Basismodell ein allgemeines Wahrnehmungsverständnis der aktuellen Umgebung erhalten hat Geben Sie eine Reihe von Sprachbefehlen aus, z. B.: „Vor Ihnen ist eine rote Ampel, fahren Sie langsamer und fahren Sie langsam“, „Vor Ihnen befindet sich eine Kreuzung, achten Sie auf Fußgänger“ und andere verwandte Sprachbefehle, damit das Auto selbstfahren kann Das Auto kann das endgültige Fahrverhalten gemäß den relevanten Sprachbefehlen ausführen.
In den letzten Jahren haben Wissenschaft und Industrie die Sprachkenntnisse von GPT in den Entscheidungsprozess des autonomen Fahrens integriert. Verbessern Sie die Leistung des autonomen Fahrens in Form von Sprachbefehlen, um Anwendungen im autonomen Fahren großer Modelle zu fördern. Wenn man bedenkt, dass das große Modell voraussichtlich tatsächlich auf der Fahrzeugseite eingesetzt werden soll, muss es letztendlich auf Planungs- oder Steuerungsanweisungen zurückgreifen, und das Basismodell sollte letztendlich autonomes Fahren auf der Ebene des Aktionszustands zulassen. Einige Wissenschaftler haben erste Untersuchungen durchgeführt, es gibt jedoch noch viel Raum für Entwicklung. Noch wichtiger ist, dass einige Wissenschaftler die Konstruktion autonomer Fahrmodelle mithilfe einer GPT-ähnlichen Methode untersucht haben, die Trajektorien basierend auf umfangreichen Sprachmodellen direkt ausgibt und diese dann über Steuerbefehle implementiert. Verwandte Arbeiten wurden in der folgenden Tabelle zusammengefasst. 
Die Kernidee der oben genannten verwandten Inhalte besteht darin, die Interpretierbarkeit autonomer Fahrentscheidungen zu verbessern, das Szenenverständnis und die Analyse zu verbessern und die Planung oder Steuerung des autonomen Fahrsystems leiten. In der letzten Zeit wurde viel daran gearbeitet, das vorab trainierte Modell-Backbone-Netzwerk auf verschiedene Weise zu optimieren und sehr gute Ergebnisse zu erzielen. Um die Anwendung grundlegender Modelle beim autonomen Fahren umfassender zusammenzufassen, fassen wir daher das vorab trainierte Backbone-Netzwerk und die Forschung zusammen und überprüfen sie, die sehr gute Ergebnisse erzielt hat. Die folgende Abbildung zeigt den Gesamtprozess des durchgängigen autonomen Fahrens. 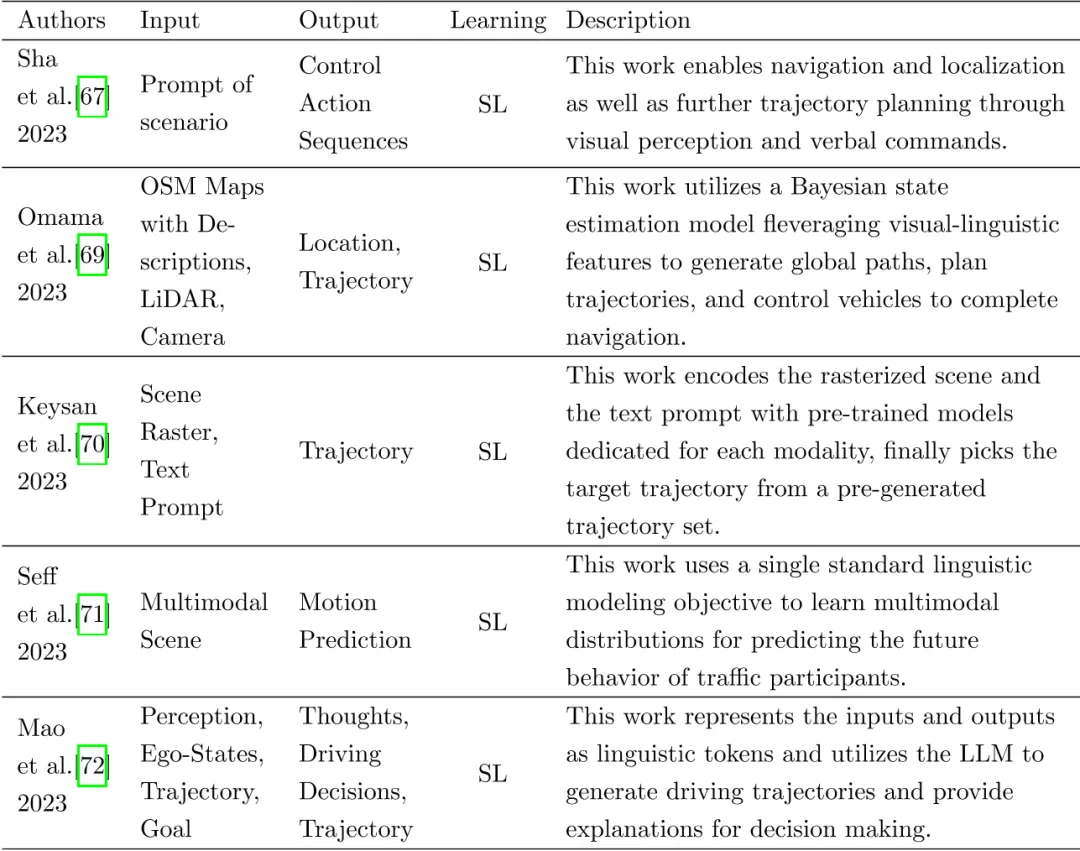
Im Gesamtprozess des durchgängigen autonomen Fahrens bestimmt das Extrahieren von Informationen auf niedriger Ebene aus Rohdaten bis zu einem gewissen Grad das Potenzial der nachfolgenden Modellleistung. Ein hervorragendes Pre-Training-Backbone kann dazu führen, dass das Modell über stärkere Funktionen zum Lernen verfügt. Vorab trainierte Faltungsnetzwerke wie ResNet und VGG sind die am häufigsten verwendeten Backbone-Netzwerke für die visuelle Merkmalsextraktion von End-to-End-Modellen. Diese vorab trainierten Netzwerke werden normalerweise mithilfe der Objekterkennung oder -segmentierung trainiert, um verallgemeinerte Merkmale zu extrahieren. Die von ihnen erzielte Leistung wurde in vielen Arbeiten überprüft.
Darüber hinaus basierten frühe End-to-End-Modelle für autonomes Fahren hauptsächlich auf verschiedenen Arten von Faltungs-Neuronalen Netzen und wurden durch Nachahmungslernen oder Verstärkungslernen vervollständigt. Einige neuere Arbeiten haben versucht, ein durchgängiges autonomes Fahrsystem mit einer Transformer-Netzwerkstruktur aufzubauen, und haben auch relativ gute Ergebnisse erzielt, wie z. B. Transfuser, FusionAD, UniAD und andere Arbeiten.
Mit der Weiterentwicklung der Deep-Learning-Technologie und der weiteren Verbesserung und Aktualisierung der zugrunde liegenden Netzwerkarchitektur hat das Basismodell mit Vortraining und Feinabstimmung eine immer leistungsfähigere Leistung gezeigt. Das von GPT dargestellte Grundmodell hat die Transformation großer Modelle von den Regeln des Lernparadigmas zu einem datengesteuerten Ansatz ermöglicht. Die Bedeutung von Daten als Schlüsselglied beim Modelllernen ist unersetzlich. Beim Training und Testen autonomer Fahrmodelle wird eine große Menge an Szenendaten verwendet, um dem Modell ein gutes Verständnis und eine gute Entscheidungsfähigkeit für verschiedene Straßen- und Verkehrsszenarien zu ermöglichen. Das Long-Tail-Problem beim autonomen Fahren besteht auch darin, dass es endlose unbekannte Randszenarien gibt, was dazu führt, dass die Generalisierungsfähigkeit des Modells scheinbar nie ausreicht, was zu einer schlechten Leistung führt.
Datenerweiterung ist entscheidend, um die Generalisierungsfähigkeit autonomer Fahrmodelle zu verbessern. Bei der Implementierung der Datenerweiterung müssen zwei Aspekte berücksichtigt werden
Daher führt die verwandte Forschungsarbeit hauptsächlich verwandte technische Forschungen aus den beiden oben genannten Aspekten durch. Einer besteht darin, den Dateninhalt anzureichern im vorhandenen Datensatz und verbessern die Dateneigenschaften in Fahrszenarien. Die zweite besteht darin, durch Simulation mehrstufige Fahrszenarien zu generieren.
Bestehende autonome Fahrdatensätze werden hauptsächlich durch die Aufzeichnung von Sensordaten und die anschließende Kennzeichnung der Daten gewonnen. Die auf diese Weise erhaltenen Datenmerkmale sind in der Regel sehr niedrig und die Größe des Datensatzes ist ebenfalls relativ gering, was für den visuellen Merkmalsraum autonomer Fahrszenarien völlig unzureichend ist. Die erweiterten semantischen Verständnis-, Argumentations- und Interpretationsfähigkeiten des durch das Sprachmodell repräsentierten Grundmodells liefern neue Ideen und technische Ansätze für die Anreicherung und Erweiterung autonomer Fahrdatensätze. Die Erweiterung des Datensatzes durch Nutzung der erweiterten Verständnis-, Argumentations- und Interpretationsfähigkeiten des zugrunde liegenden Modells kann dazu beitragen, die Erklärbarkeit und Steuerung autonomer Fahrsysteme besser zu bewerten und dadurch die Sicherheit und Zuverlässigkeit autonomer Fahrsysteme zu verbessern.
Fahrszenen sind für das autonome Fahren von großer Bedeutung. Um unterschiedliche Fahrszenendaten zu erhalten, ist es mit enormen Kosten verbunden, sich bei der Echtzeiterfassung nur auf die Sensoren des Fahrzeugs zu verlassen, und es ist schwierig, für einige Randszenen genügend Szenendaten zu erhalten. Die Generierung realistischer Fahrszenen durch Simulation hat die Aufmerksamkeit vieler Forscher auf sich gezogen. Die Verkehrssimulationsforschung ist hauptsächlich in zwei Kategorien unterteilt: regelbasiert und datengesteuert.
Zusammenfassung verschiedener Strategien zur Datenerweiterung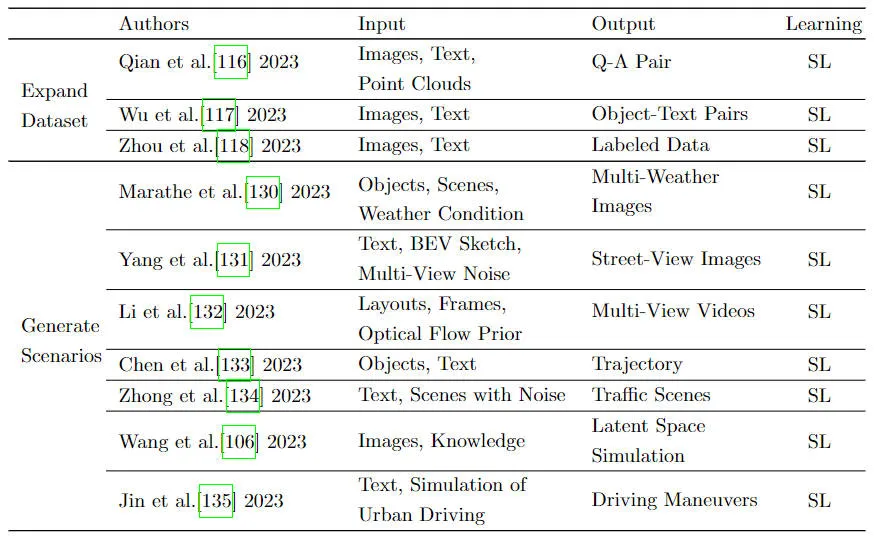
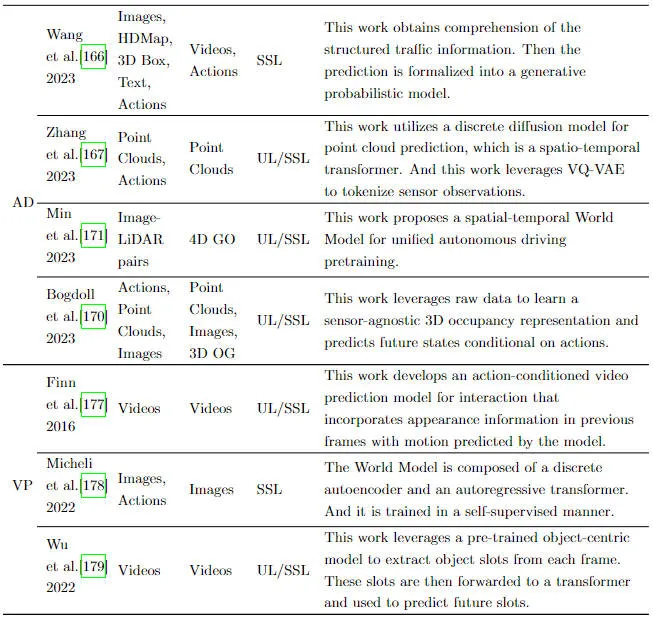
Ein Weltmodell wird als Modell der künstlichen Intelligenz betrachtet, das ein Gesamtverständnis oder eine Darstellung der Umgebung enthält, in der es operiert. Das Modell ist in der Lage, die Umgebung zu simulieren, um Vorhersagen oder Entscheidungen zu treffen. In der neueren Literatur wird im Zusammenhang mit Reinforcement Learning der Begriff „Weltmodell“ erwähnt. Aufgrund seiner Fähigkeit, die Dynamik der Fahrumgebung zu verstehen und aufzuklären, gewinnt dieses Konzept auch bei autonomen Fahranwendungen an Bedeutung. Weltmodelle stehen in engem Zusammenhang mit Verstärkungslernen, Nachahmungslernen und tiefen generativen Modellen. Die Verwendung von Weltmodellen beim Reinforcement Learning und Imitation Learning erfordert jedoch in der Regel gut gekennzeichnete Daten, und Methoden wie SEM2 und MILE werden im überwachten Paradigma durchgeführt. Gleichzeitig gibt es auch Versuche, verstärkendes Lernen und unüberwachtes Lernen basierend auf den Einschränkungen gekennzeichneter Daten zu kombinieren. Aufgrund ihrer engen Verbindung mit selbstüberwachtem Lernen erfreuen sich tiefe generative Modelle immer größerer Beliebtheit und es wurden zahlreiche Arbeiten vorgeschlagen. Die folgende Abbildung zeigt das Gesamtflussdiagramm der Verwendung des Weltmodells zur Verbesserung des autonomen Fahrmodells.
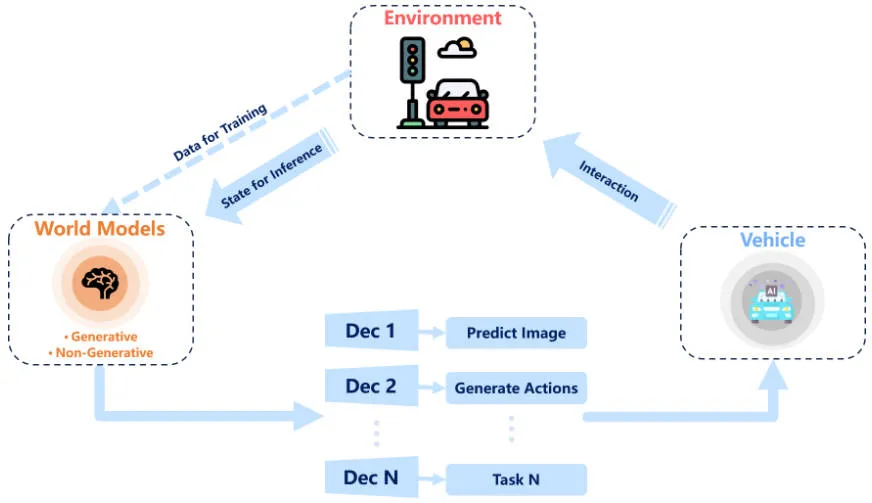
Gesamtflussdiagramm für die Verbesserung des Weltmodells für autonomes Fahren
Tief generative Modelle umfassen normalerweise Variations-Autoencoder, generative gegnerische Netzwerke, Flussmodelle und autoregressive Modelle.
Kurz gesagt: Obwohl die Anwendung des Grundmodells auf das autonome Fahren viele Herausforderungen mit sich bringt, verfügt es über einen sehr breiten Anwendungsbereich und Entwicklungsperspektiven. Auch in Zukunft werden wir den Fortschritt grundlegender Modelle für das autonome Fahren beobachten.
Das obige ist der detaillierte Inhalt vonRezension! Fassen Sie umfassend die wichtige Rolle von Basismodellen bei der Förderung des autonomen Fahrens zusammen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



