
 Technologie-Peripheriegeräte
KI
Ilyas erste Aktion, nachdem er seinen Job aufgegeben hatte: Mir gefiel diese Zeitung, und die Internetnutzer beeilten sich, sie zu lesen
Technologie-Peripheriegeräte
KI
Ilyas erste Aktion, nachdem er seinen Job aufgegeben hatte: Mir gefiel diese Zeitung, und die Internetnutzer beeilten sich, sie zu lesen
Ilyas erste Aktion, nachdem er seinen Job aufgegeben hatte: Mir gefiel diese Zeitung, und die Internetnutzer beeilten sich, sie zu lesen

Seit Ilya Sutskever offiziell seinen Rücktritt von OpenAI bekannt gegeben hat, ist sein nächster Schritt in den Mittelpunkt aller Aufmerksamkeit gerückt.
Manche Leute achten sogar genau auf jede seiner Bewegungen.
Nein, Ilya mochte ❤️ einfach eine neue Arbeit –
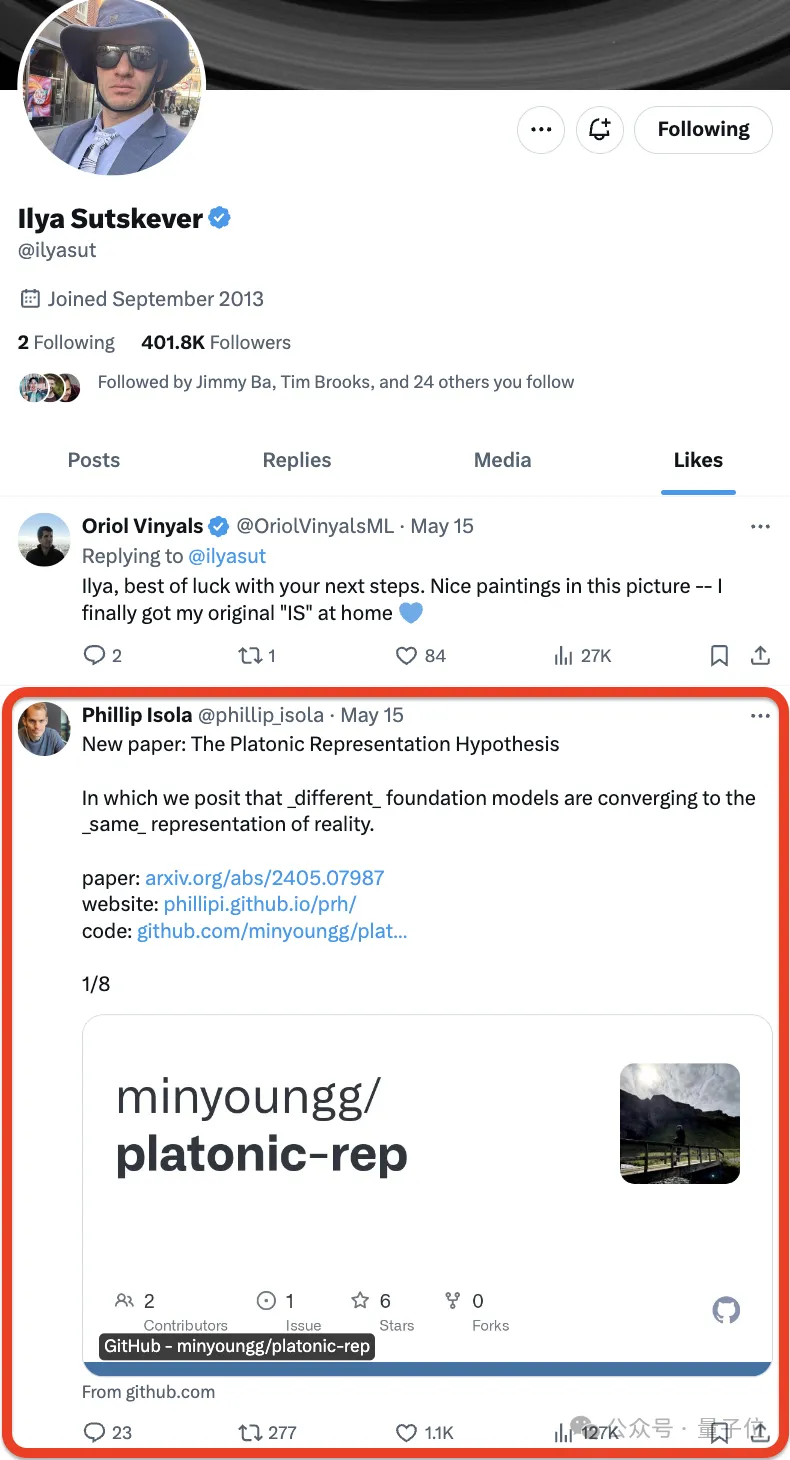
– und die Internetnutzer beeilten sich, sie zu mögen:

Die Arbeit kommt vom MIT, der Autor schlug eine Hypothese vor, die lässt sich in einem Satz wie folgt zusammenfassen:
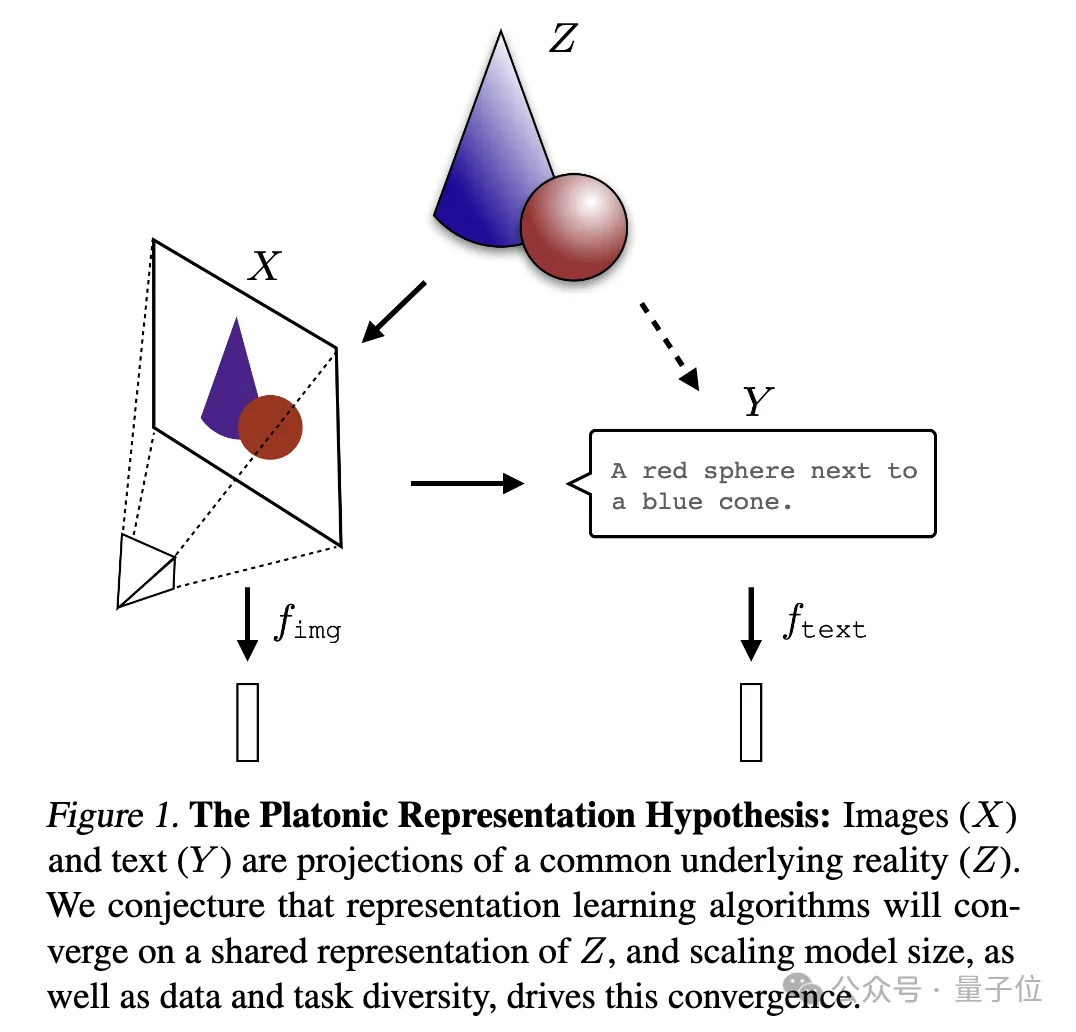
Neuronale Netze werden mit unterschiedlichen Zielen auf unterschiedliche Daten und Modalitäten trainiert und neigen dazu, in ihrem Repräsentationsraum einen gemeinsamen Repräsentationsraum zu bilden .

Sie nannten diese Spekulation die „Platonische Repräsentationshypothese“ in Anlehnung an Platons Höhlengleichnis und seine Vorstellungen über die Natur der idealen Realität.
 Die Auswahl von Ilya ist immer noch garantiert, nachdem sie es gelesen hatten:
Die Auswahl von Ilya ist immer noch garantiert, nachdem sie es gelesen hatten:
 Nachdem sie es gelesen hatten, verwendeten sie „Anna“. Zusammenfassend lässt sich der Eröffnungssatz von „Karenina“ zusammenfassen: Alle glücklichen Sprachmodelle sind ähnlich, und jedes unglückliche Sprachmodell hat sein eigenes Unglück.
Nachdem sie es gelesen hatten, verwendeten sie „Anna“. Zusammenfassend lässt sich der Eröffnungssatz von „Karenina“ zusammenfassen: Alle glücklichen Sprachmodelle sind ähnlich, und jedes unglückliche Sprachmodell hat sein eigenes Unglück.
 Um Whiteheads berühmtes Sprichwort zu paraphrasieren: Alles maschinelle Lernen ist eine Fußnote zu Platon.
Um Whiteheads berühmtes Sprichwort zu paraphrasieren: Alles maschinelle Lernen ist eine Fußnote zu Platon.
 Wir haben auch einen Blick darauf geworfen und der allgemeine Inhalt lautet:
Wir haben auch einen Blick darauf geworfen und der allgemeine Inhalt lautet:
Der Autor analysierte die
Repräsentationskonvergenz(Repräsentationskonvergenz) des KI-Systems, also die Darstellung von Datenpunkten in verschiedenen Neuronale Netzwerkmodelle werden in verschiedenen Modellarchitekturen, Trainingszielen und sogar Datenmodalitäten immer ähnlicher. Was treibt diese Konvergenz voran? Wird sich dieser Trend fortsetzen? Wo ist sein endgültiges Ziel?
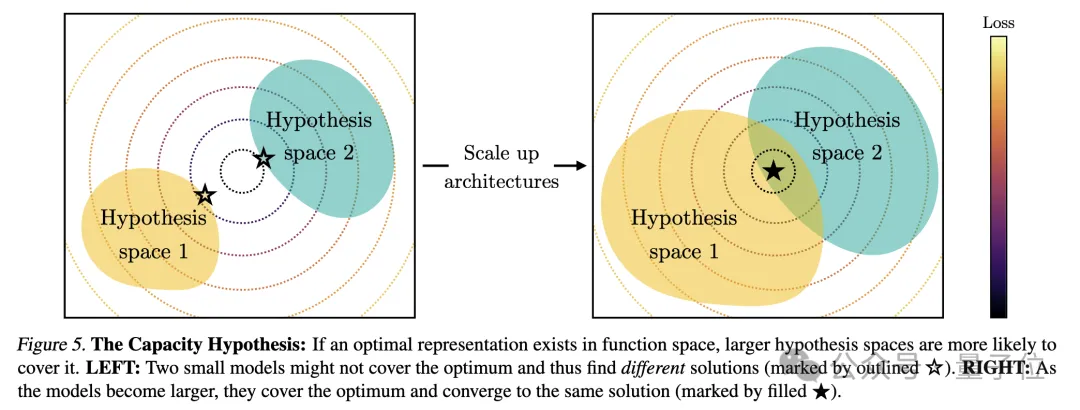
Nach einer Reihe von Analysen und Experimenten spekulierten die Forscher, dass diese Konvergenz tatsächlich einen Endpunkt und ein treibendes Prinzip hat:
Verschiedene Modelle streben danach, eine genaue Darstellung der Realität zu erreichen. Ein Bild zur Erklärung:
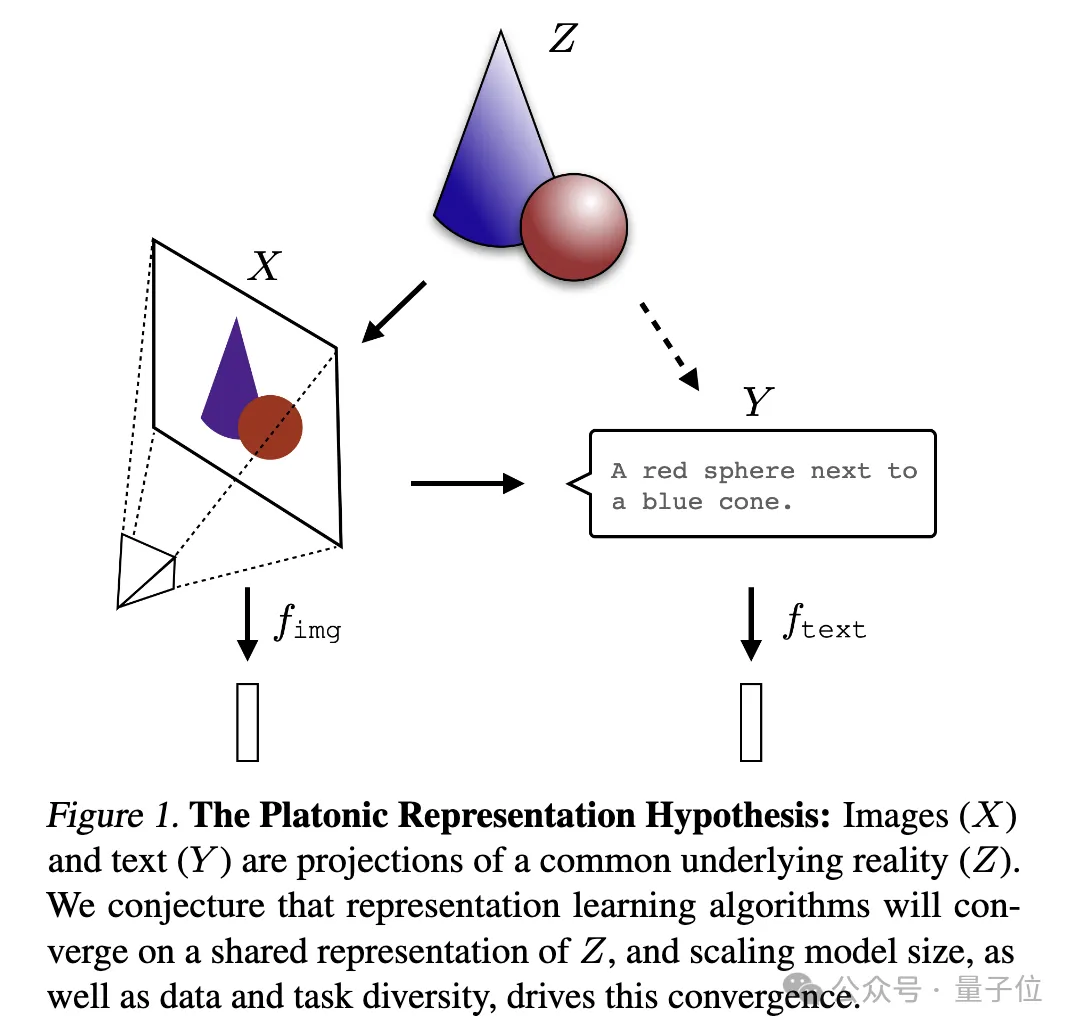 wobei Bild
wobei Bild
und Text (Y) unterschiedliche Projektionen einer gemeinsamen zugrunde liegenden Realität (Z) sind. Die Forscher spekulieren, dass Repräsentationslernalgorithmen zu einer einheitlichen Darstellung von Z konvergieren werden und dass die Zunahme der Modellgröße und die Vielfalt von Daten und Aufgaben Schlüsselfaktoren für diese Konvergenz sind. Ich kann nur sagen, dass es sich tatsächlich um eine Frage handelt, die Ilya interessiert. Sie ist zu tiefgreifend und wir verstehen sie nicht sehr gut. Bitten wir die KI, sie bei der Interpretation zu helfen und sie mit allen zu teilen~
 Beweise, die Konvergenz darstellen
Beweise, die Konvergenz darstellen
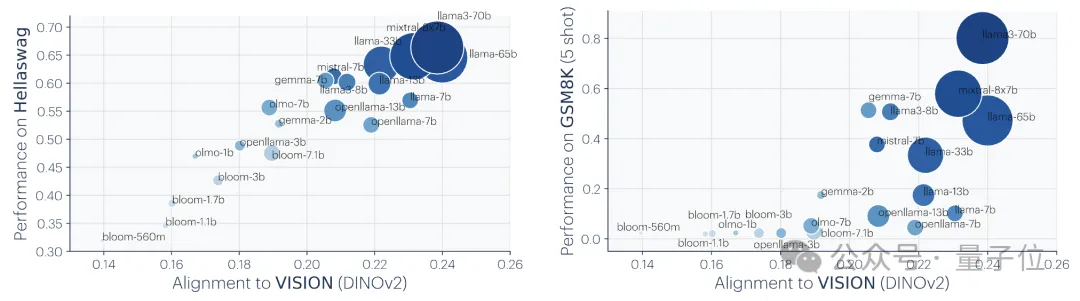
Zunächst hat der Autor eine große Anzahl früherer verwandter Studien analysiert und auch selbst Experimente durchgeführt und eine Reihe von Beweisen für Konvergenz erstellt, die Konvergenz, Umfang und Leistung sowie modalübergreifende Konvergenz demonstrieren verschiedener Modelle.
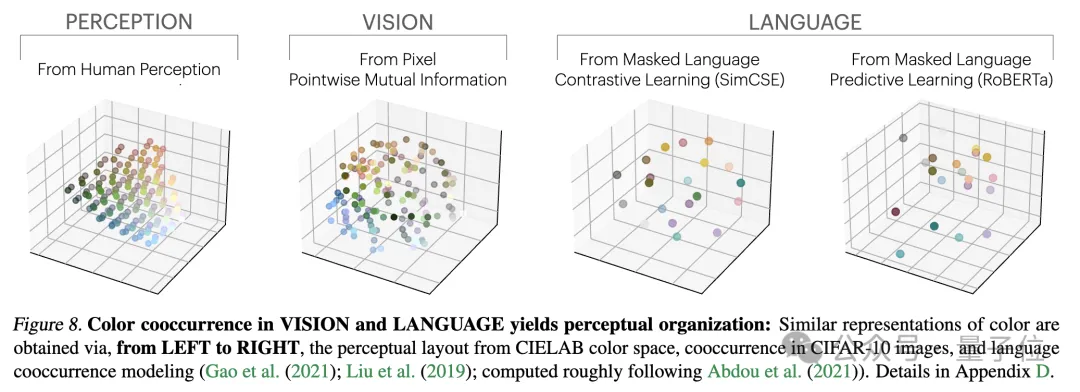
Ps: Diese Forschung konzentriert sich auf die Vektoreinbettungsdarstellung, das heißt, Daten werden in Vektorform umgewandelt und die Ähnlichkeit oder der Abstand zwischen Datenpunkten wird durch die Kernelfunktion beschrieben. Das Konzept der „Darstellungsausrichtung“ in diesem Artikel bedeutet, dass die beiden Darstellungen als ausgerichtet gelten, wenn zwei unterschiedliche Darstellungsmethoden ähnliche Datenstrukturen offenbaren.1. Die Konvergenz verschiedener Modelle mit unterschiedlichen Architekturen und Zielen ist in der Regel konsistent in ihrer zugrunde liegenden Darstellung. Die Anzahl der Systeme, die auf vorab trainierten Grundmodellen basieren, nimmt allmählich zu, und einige Modelle werden zur Standard-Kernarchitektur für Multitasking. Diese breite Anwendbarkeit in einer Vielzahl von Anwendungen spiegelt ihre gewisse Vielseitigkeit bei den Datendarstellungsmethoden wider. Während dieser Trend darauf hindeutet, dass KI-Systeme zu einem kleineren Satz von Basismodellen konvergieren, beweist er nicht, dass verschiedene Basismodelle dieselbe Darstellung bilden. Jedoch haben einige neuere Untersuchungen zum Modell-Stitching(Modell-Stitching) ergeben, dass die Darstellungen der mittleren Ebene von Bildklassifizierungsmodellen gut ausgerichtet werden können, selbst wenn sie auf verschiedenen Datensätzen trainiert werden. Einige Untersuchungen haben beispielsweise ergeben, dass die frühen Schichten von Faltungsnetzwerken, die auf den Datensätzen ImageNet und Places365 trainiert wurden, ausgetauscht werden können, was darauf hindeutet, dass sie ähnliche anfängliche visuelle Darstellungen gelernt haben. Es gibt auch Studien, die eine große Anzahl von „Rosetta-Neuronen“ entdeckt haben, also Neuronen mit sehr ähnlichen Aktivierungsmustern in verschiedenen visuellen Modellen... 2 Je größer die Modellgröße und Leistung, desto besser die Darstellung Je höher die Ausrichtung. mithilfe der Methode des gegenseitigen nächsten Nachbarn am Places-365-Datensatz gemessen und ihre Downstream-Aufgabenleistung anhand des Vision-Task-Adaption-Benchmarks VTAB bewertet. 3. Konvergenz der Modelldarstellung in verschiedenen Modi. 4. Das Modell und die Gehirndarstellung weisen ebenfalls einen gewissen Grad an Konsistenz auf, möglicherweise aufgrund ähnlicher Daten- und Aufgabenbeschränkungen. 5. Der Grad der Ausrichtung von Modelldarstellungen korreliert positiv mit der Leistung nachgelagerter Aufgaben. (logisches Denken) und GSM8K (Mathematik) . Und verwenden Sie das DINOv2-Modell als Referenz, um die Ausrichtung anderer Sprachmodelle mit dem visuellen Modell zu messen. Ein ähnliches Prinzip wurde bereits vorgeschlagen. Das Diagramm lautet wie folgt: Darüber hinaus gibt es für einfache Aufgaben mehrere Lösungen, während es für schwierige Aufgaben weniger Lösungen gibt. Daher konvergiert die Darstellung des Modells mit zunehmender Aufgabenschwierigkeit tendenziell zu besseren, weniger Lösungen. 2. Modellkapazität führt zu Konvergenz (Konvergenz über Modellkapazität) Wenn es eine global optimale Darstellung gibt, wird unter der Bedingung ausreichender Daten ein größeres Modell vorliegen effizienter sein. Daher neigen größere Modelle, die unabhängig von ihrer Architektur dasselbe Trainingsziel verwenden, dazu, dieser optimalen Lösung zuzustreben. Wenn verschiedene Trainingsziele ähnliche Minima haben, sind größere Modelle effizienter beim Finden dieser Minima und tendieren zu ähnlichen Lösungen für alle Trainingsaufgaben. 3. Konvergenz durch Simplicity Bias Tiefe Netzwerke neigen dazu, nach einfachen Anpassungen an die Daten zu suchen. Diese inhärente Tendenz zur Einfachheit führt dazu, dass große Modelle tendenziell vereinfacht dargestellt werden, was zu Konvergenz führt. Das heißt, größere Modelle haben eine größere Abdeckung und sind in der Lage, dieselben Daten auf alle möglichen Arten anzupassen. Die implizite Einfachheitspräferenz tiefer Netzwerke ermutigt jedoch größere Modelle, die einfachste dieser Lösungen zu finden. Der Endpunkt der KonvergenzNach einer Reihe von Analysen und Experimenten schlugen die Forscher, wie eingangs erwähnt, die „Plato-Repräsentationshypothese“ vor und spekulierten über den Endpunkt dieser Konvergenz. Das heißt, verschiedene KI-Modelle konvergieren, obwohl sie auf unterschiedliche Daten und Ziele trainiert wurden, in ihren Darstellungsräumen zu einem gemeinsamen statistischen Modell, das die reale Welt darstellt, die die von uns beobachteten Daten generiert. Als nächstes betrachtet der Autor eine Klasse kontrastiver Lernalgorithmen, die versuchen, eine Darstellung fX zu lernen, so dass das innere Produkt von fX(xa) und fX(xb) xa annähert und ) das Verhältnis der logarithmischen Quoten von (zufällig ausgewählt) Nach der mathematischen Ableitung stellte der Autor fest, dass dieser Algorithmus zu einer Kernelfunktion konvergiert, wenn die Daten glatt genug sind. Dies ist der Punkt gegenseitige Information (PMI) von xa und xb Das bedeutet, dass unabhängig davon, ob Darstellungen aus visuellen Daten Forscher haben diese Theorie durch eine empirische Studie zur Farbe getestet. Unabhängig davon, ob die Farbdarstellung aus der Statistik des gleichzeitigen Auftretens von Pixeln in Bildern oder aus der Statistik des gleichzeitigen Auftretens von Wörtern in Texten gelernt wird, ähneln die resultierenden Farbabstände der menschlichen Wahrnehmung, und mit zunehmender Modellgröße wird diese Ähnlichkeit immer größer. Dies steht im Einklang mit der theoretischen Analyse, das heißt, eine größere Modellfähigkeit kann die Statistiken von Beobachtungsdaten genauer modellieren und so einen PMI-Kernel erhalten, der der idealen Ereignisdarstellung näher kommt. Am Ende des Artikels fasst der Autor die möglichen Auswirkungen der Repräsentationskonvergenz auf das Gebiet der KI und zukünftige Forschungsrichtungen sowie mögliche Einschränkungen und Ausnahmen von der platonischen Repräsentationsannahme zusammen. Sie wiesen darauf hin, dass die Konvergenz der Darstellung mit zunehmender Modellgröße unter anderem folgende Auswirkungen haben kann: Der Autor betont, dass die Prämisse der oben genannten Auswirkungen darin besteht, dass die Trainingsdaten zukünftiger Modelle ausreichend vielfältig und verlustfrei sein müssen, um wirklich zu einer Darstellung zu konvergieren, die die statistischen Gesetze der tatsächlichen Welt widerspiegelt. Gleichzeitig stellte der Autor auch fest, dass Daten unterschiedlicher Modalitäten einzigartige Informationen enthalten können, was es schwierig machen kann, eine vollständige Darstellungskonvergenz zu erreichen, selbst wenn die Modellgröße zunimmt. Darüber hinaus stimmen derzeit nicht alle Darstellungen überein. Beispielsweise gibt es im Bereich der Robotik keine standardisierte Darstellungsweise. Forscher und Community-Präferenzen können dazu führen, dass Modelle sich menschlichen Darstellungen annähern und dabei andere mögliche Formen der Intelligenz ignorieren. Und intelligente Systeme, die speziell für bestimmte Aufgaben entwickelt wurden, konvergieren möglicherweise nicht zu denselben Darstellungen wie die allgemeine Intelligenz. Die Autoren betonen außerdem, dass Methoden zur Messung der Darstellungsausrichtung umstritten sind und unterschiedliche Messmethoden zu unterschiedlichen Schlussfolgerungen führen können. Auch wenn die Darstellungen verschiedener Modelle ähnlich sind, müssen noch Lücken erklärt werden, und es ist derzeit nicht möglich zu bestimmen, ob diese Lücke wichtig ist. Für weitere Details und Argumentationsmethoden werde ich das Papier hier veröffentlichen~ Link zum Papier: https://arxiv.org/abs/2405.07987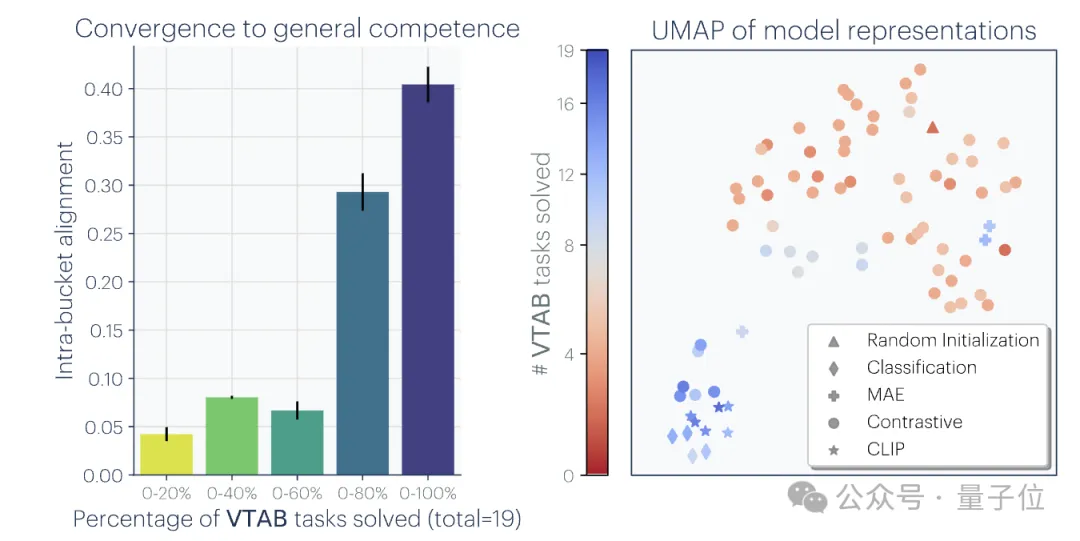




 Sie konstruierten zunächst ein idealisiertes diskretes Ereignisweltmodell. Die Welt enthält eine Reihe diskreter Ereignisse Z, jedes Ereignis wird aus einer unbekannten Verteilung P(Z) entnommen. Jedes Ereignis kann durch die Beobachtungsfunktion obs auf unterschiedliche Weise beobachtet werden, z. B. Pixel, Töne, Text usw.
Sie konstruierten zunächst ein idealisiertes diskretes Ereignisweltmodell. Die Welt enthält eine Reihe diskreter Ereignisse Z, jedes Ereignis wird aus einer unbekannten Verteilung P(Z) entnommen. Jedes Ereignis kann durch die Beobachtungsfunktion obs auf unterschiedliche Weise beobachtet werden, z. B. Pixel, Töne, Text usw. 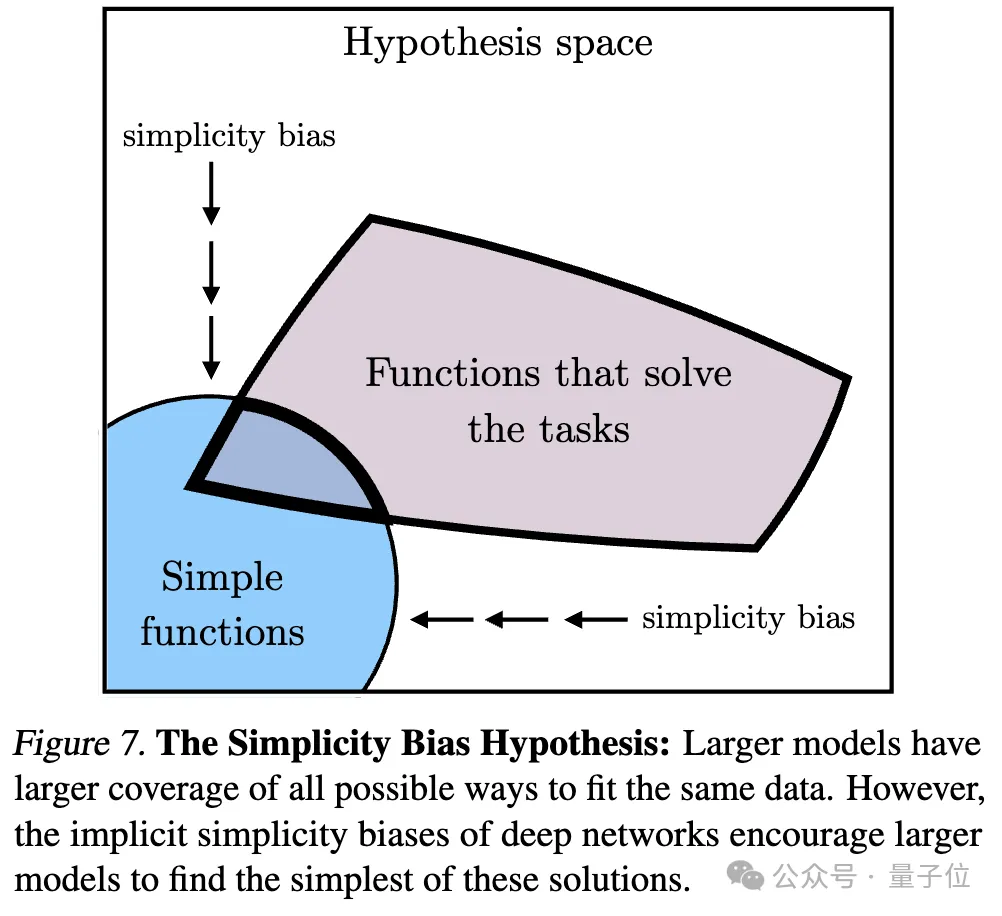 .
. 

Einige abschließende Gedanken
Das obige ist der detaillierte Inhalt vonIlyas erste Aktion, nachdem er seinen Job aufgegeben hatte: Mir gefiel diese Zeitung, und die Internetnutzer beeilten sich, sie zu lesen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1668
1668
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Neues SOTA für multimodale Dokumentverständnisfunktionen! Das Alibaba mPLUG-Team hat die neueste Open-Source-Arbeit mPLUG-DocOwl1.5 veröffentlicht, die eine Reihe von Lösungen zur Bewältigung der vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des allgemeinen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung externen Wissens vorschlägt. Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an. Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format: Es stehen Diagramme verschiedener Stile zur Verfügung: Auch eine detailliertere Texterkennung und -positionierung ist einfach zu handhaben: Auch ausführliche Erläuterungen zum Dokumentverständnis können gegeben werden: Sie wissen schon, „Document Understanding“. " ist derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen. Einige von ihnen verwenden hauptsächlich OCR-Systeme zur Texterkennung und arbeiten mit LLM zur Textverarbeitung zusammen.
