

Fortgeschrittene Praxis des industriellen Wissensgraphen

1. Hintergrundeinführung
Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen.

Yunwen Technology Company...
2023 ist die Zeit, in der große Modelle vorherrschend sind, nachdem große Modelle untersucht wurden nicht mehr wichtig. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien zunichte macht. Es ist auch möglich, dass durch die Integration neuer und alter Technologien bessere Ergebnisse erzielt werden. Wir müssen auf den Schultern von Giganten stehen und weiter expandieren.
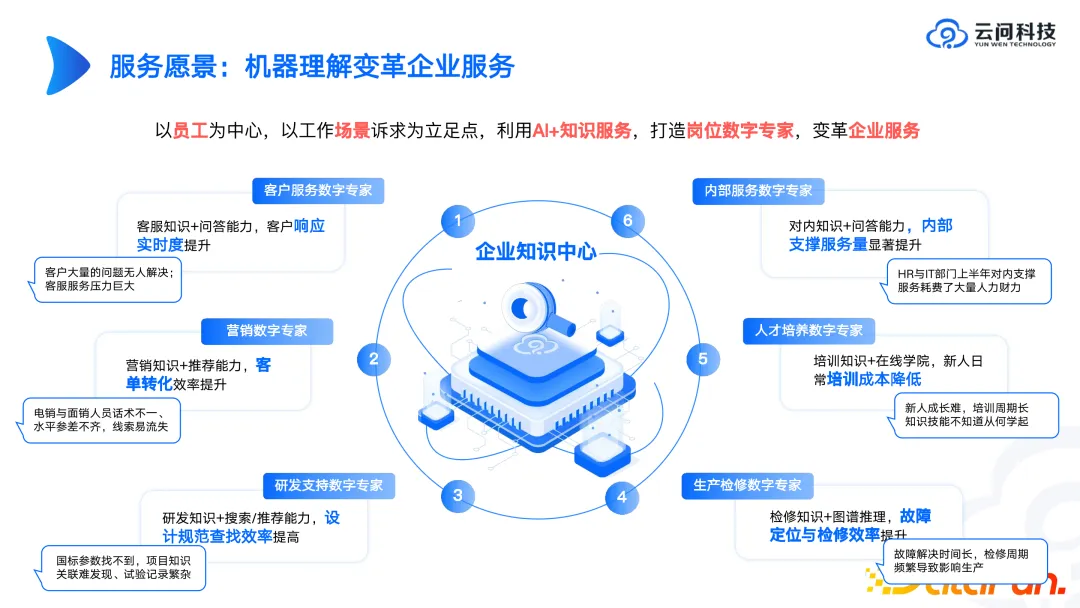
Warum konzentriert sich Yunwen Technology auf das Enterprise Knowledge Center? Denn wir haben in einigen Fällen in der Vergangenheit festgestellt, dass es bei vielen komplexen Szenarien wie Risikokontrolle, Drogentests usw. schwierig ist, kurzfristig ideale Ergebnisse zu erzielen und standardisierte Produkte zu liefern. Bei betrieblichen Wissensmanagement- oder bürobezogenen Betriebswirtschaftsszenarien kann der Probebetrieb relativ schnell aufgenommen und optimale Ergebnisse erzielt werden. Wenn wir in diesem Jahr mit Unternehmen zusammenarbeiten, um groß angelegte Privatisierungsmodelle zu entwickeln, werden wir daher das Unternehmenswissensmanagement, einschließlich Fragen und Antworten oder Suchen auf der Grundlage des Unternehmenswissensmanagements, als Schlüsselthema einbeziehen. Für Unternehmen ist der Aufbau eigener privatisierter Wissens- und Wissenszentren von großer Bedeutung.
Wenn es Freunde gibt, die die Richtung des Wissensgraphen studieren möchten, schlagen wir aus diesen Gründen vor, den gesamten Lebenszyklus des Wissens zu berücksichtigen, über die zu lösenden Probleme und den spezifischen Landeplatz nachzudenken. Einige Unternehmen verwenden beispielsweise vorhandene Dokumente, um Inhalte im Zusammenhang mit Prüfungen, Schulungen und Interviews zu generieren. Obwohl diese technischen Schlagworte so beliebt sind, ist ein solches Privatisierungsmodell effektiver als GPT3.5 oder GPT4, da in diesem Szenario einige Szenen vorhanden sind Die Vorproduktion ist abgeschlossen. Daher glauben wir, dass spezialisiertere und anspruchsvollere Modelle ein wichtiger Trend in der zukünftigen Entwicklung sein werden.
2. Kartenproduktformular
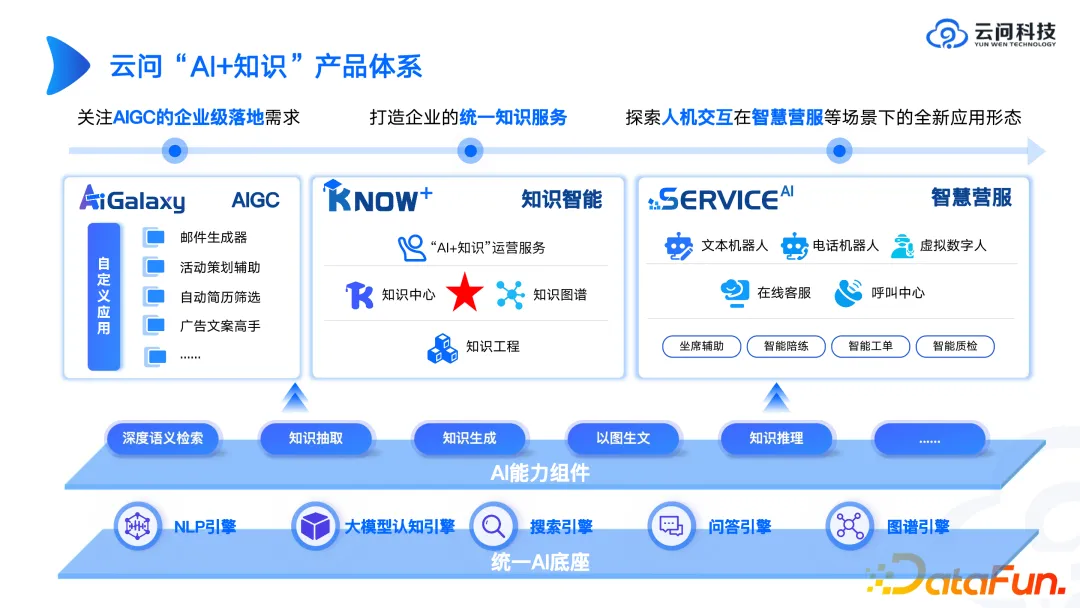
Wie sieht das Kartenproduktformular im obigen Hintergrund aus? Als nächstes stellen wir beispielhaft das Produktsystem „KI + Wissen“ von Yunwen Technology vor.
Zuallererst muss es eine einheitliche KI-Basis geben. Dies kann nicht von einem Team oder sogar einem Unternehmen geleistet werden. Sie können APIs oder SDKs großer Modellmotoren von Drittanbietern verwenden. In vielen Fällen ist es nicht notwendig, ein Rad von Grund auf neu zu erstellen, da das Rad, dessen Erstellung mehrere Monate gedauert hat, wahrscheinlich nicht so effektiv ist wie ein offenes Quellmodell, das gerade veröffentlicht wurde. Daher wird für den KI-Basisteil empfohlen, mehr über die Kombination von Technologien von Drittanbietern nachzudenken. Wenn Sie ihn selbst entwickeln, ist es natürlich am besten, ihn voll auszuschöpfen den Wert der Plattform und berücksichtigen Sie beides.
In Bezug auf KI-Fähigkeitskomponenten haben wir bei einigen unserer Liefererfahrungen festgestellt, dass sich diese KI-Fähigkeitskomponenten tendenziell besser verkaufen als Produkte. Denn viele Unternehmen hoffen, die von professionellen Technologieunternehmen entwickelten Komponenten nutzen zu können, um ihre eigenen Oberschichtanwendungen zu erstellen. Im Zeitalter großer Modelle ist der Verkauf von KI-Fähigkeitskomponenten wie der Verkauf von Schaufeln, und die Goldminen werden immer noch von großen Unternehmen selbst abgebaut.
In Bezug auf Anwendungen der oberen Ebene werden wir sie aus drei Richtungen implementieren: AIGCs eigene Anwendung, Wissensintelligenz und intelligente Geschäftsdienste. Entdecken Sie, in welche Richtung es einen größeren Wert geben würde. Der Wissensgraph wird von uns als zentrales Glied in der gesamten Wissensintelligenz eingestuft. Es ist zu beachten, dass der Wissensgraph der Kern, aber nicht der einzige ist. Wir sind bereits auf viele Szenarien gestoßen, in denen Kunden über eine große Anzahl relationaler Datenbanken und eine große Anzahl unstrukturierter Dokumente verfügen. Wir hoffen, dass wir alle diese Wissenssysteme und Wissensbestände in den Wissensgraphen integrieren können. Wir glauben, dass die zukünftige Wissensarchitektur heterogen sein sollte, einiges Wissen in relationalen Datenbanken und einiges Wissen möglicherweise aus Graphnetzwerken stammt. Letztendlich müssen große Modelle auf mehreren basieren. Quelle heterogen Umfassende Analyse von Strukturdaten. Beispielsweise kann eine Intelligenz einige numerische Indikatoren aus einer relationalen Datenbank extrahieren, einige Vorschläge in Dokumenten finden, nach historischen Informationen aus Arbeitsaufträgen suchen und dann den gesamten Inhalt zur Analyse zusammenstellen. So stellen wir uns eine Kombination aus großen Modellen und Wissensgraphen vor. In einer Gesamtarchitektur führt das große Modell die endgültige Analyse durch, und der Wissensgraph hilft dem großen Modell durch sein Wissensdarstellungssystem, das dahinter verborgene Wissen schneller und genauer zu finden.
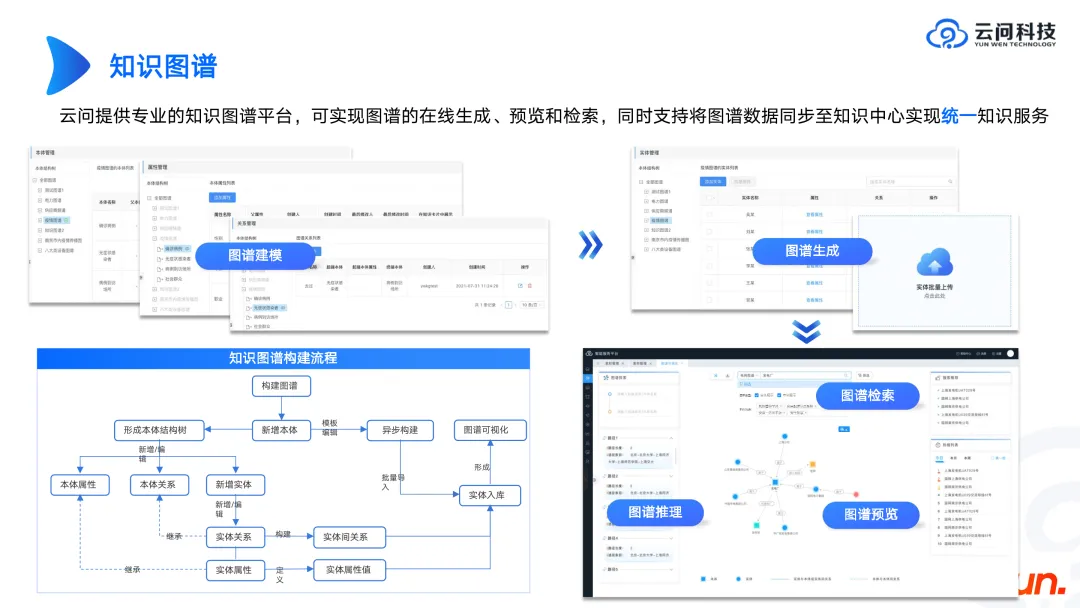
Wir haben zuvor die Beziehung zwischen dem großen Modell und der Karte besprochen. Sehen wir uns als Nächstes an, was die Karte selbst benötigt.
Zuallererst verbirgt sich hinter dem Diagramm eine Diagrammdatenbank wie Open Source Neo4j, Genius Graph und einige inländische Datenbankmarken. Wissensgraph und Diagrammdatenbank sind zwei unterschiedliche Konzepte. Das Erstellen eines Wissensdiagrammprodukts entspricht der Kapselung der oberen Schicht der Diagrammdatenbank, um eine schnelle Diagrammmodellierung und -visualisierung zu erreichen.
Wenn Sie ein Wissensgraphenprodukt erstellen möchten, können Sie sich zunächst auf die Produktform von Neo4j oder die Wissensgraphenprodukte einiger großer inländischer Hersteller beziehen, damit Sie ungefähr verstehen können, welche Funktionen und Verknüpfungen das Wissensgraphenprodukt benötigt implementieren. Wichtiger ist es zu wissen, wie man ein Wissensdiagramm erstellt. Dies scheint ein Geschäftsproblem zu sein, da verschiedene Unternehmen und unterschiedliche Szenarien unterschiedliche Diagramme haben. Wenn Sie als Techniker keine Kenntnisse über Elektrizität, Ausrüstung, Industrie usw. haben, ist es unmöglich, eine Karte zu erstellen, die das Geschäft zufriedenstellt. Es erfordert eine kontinuierliche Kommunikation mit dem Unternehmen und kontinuierliche Iteration, um schließlich ein Ergebnis zu erzielen. Der Diskussionsprozess kann tatsächlich zum Wesen des Schemas zurückkehren und eine Reihe ontologischer Theorien und logischer Konzepte des Schemas vorstellen. Diese Inhalte sind sehr wichtig. Sobald das Schema fertiggestellt ist, können relevantere Mitarbeiter einbezogen werden, um den Inhalt zu bereichern und das Produkt weiter zu verbessern. Hier sind einige unserer bisherigen Erfahrungen.

Das Folgende ist eine Einführung in die Gesamteigenschaften der Karte. Derzeit basieren Wissensgraphen noch hauptsächlich auf Tripeln, auf denen mehrgranulare und mehrstufige semantische Beziehungen wie Entitäten, Attribute und Beziehungen aufgebaut sind. In der industriellen Welt stoßen wir häufig auf Probleme, die nicht durch Tripel gelöst werden können. Wenn wir festgelegte Entitätsattributwerte verwenden, um die reale physische Welt zu beschreiben, treten viele Probleme auf. Zu diesem Zeitpunkt werden wir die eingeschränkten Bedingungen in Form von CVT umsetzen. Daher muss beim Aufbau eines Wissensgraphen zunächst jeder nachweisen, dass Tripel das aktuelle Problem lösen können.
Eine Sache, auf die hingewiesen werden muss, ist, dass beim Erstellen einer Karte diese nach Bedarf erstellt werden muss, da die Welt unendlich ist und der darin enthaltene Wissensgehalt ebenfalls unendlich ist. Zu Beginn haben wir oft die Vision, alle Entitäten, die in der physischen Welt existieren, in unserer Computerwelt abzubilden. Das Problem dabei ist, dass das gesamte am Ende erstellte Schema zu komplex ist und für das echte Geschäft nicht hilfreich ist. Die Tatsache, dass sich die Erde beispielsweise um die Sonne dreht, kann ich in einer Dreifachkonstruktion konstruieren. Aber dieses Triplett kann das eigentliche Problem, mit dem ich jetzt konfrontiert bin, nicht lösen, also muss ich das Triplett nach Bedarf erstellen.
Wie geht man also mit Fragen des gesunden Menschenverstandes um? Viele Fragen erfordern Tripel des gesunden Menschenverstandes. Wir glauben, dass dies großen Modellen überlassen werden kann. Wir hoffen auch, dass der Wissensgraph die Professionalität erforschen und wirklich relevantes Wissen in den Graphen einbauen kann. Dann kann das große Modell auf gesundem Menschenverstand basieren und mit dem durch den Wissensgraphen bereitgestellten Vorwissen kombiniert werden, das im freien Feld nicht erlangt werden kann, um bessere Ergebnisse zu erzielen.

Der Aufbau des Wissensgraphen erfordert eine gemeinsame Gestaltung durch Geschäftspersonal und Betriebspersonal, einschließlich der Definition von Ontologie, Beziehungen, Attributen und Entitäten sowie deren Visualisierung. Am Ende wird es um die Frage gehen, welche Inhalte den Nutzern in Produktform präsentiert werden sollen. Wenn der Benutzer der Endverbraucher ist, müssen nur visuelle Suche und Fragen und Antworten angezeigt werden. Denn diesem Kundentyp ist es egal, wie die Karte erstellt wird, ob automatisiert oder manuell.
Hier geht es um ein weiteres sehr wichtiges Problem: Selbst in großen Modellszenarien können nicht alle Karten automatisch erstellt werden. Die Kosten für die Erstellung eines Diagramms sind sehr hoch, anstatt viel Energie für die Diagrammmodellierung aufzuwenden, sollten wir unsere Energie für den Verbrauch aufwenden. Wenn Sie geschäftliche Akzeptanz erreichen möchten, müssen Sie möglicherweise auf manuelle Konstruktion zurückgreifen. Wenn beispielsweise eine Tabelle mit einem bestimmten Format tabellenübergreifend komplex ist, können wir versuchen, mithilfe eines großen Modells eine Basislinie zu finden. Dadurch wird Energie vom Bauen zum Verbrauch verlagert. Wenn ein Projektzyklus beispielsweise 100 Tage dauert, verbringen wir 70 Tage damit, die Karte zu erstellen, und verbringen die letzten 30 Tage damit, über die Anwendungsszenarien dieser Karte nachzudenken. Oder weil die frühe Bauzeit verlängert wird, bleibt keine Zeit zum Nachdenken Es kommt zu wertvollen Verbrauchsszenarien, die zu großen Fragen führen können. Unserer Erfahrung nach sollten Sie eine kleine Zeitspanne in die Erstellung investieren oder standardmäßig die manuelle Erstellung durchführen. Verbringen Sie dann viel Zeit damit, darüber nachzudenken, wie Sie den Wert der erstellten Karte maximieren können.

Das Bild oben zeigt den Prozess der Erstellung eines Wissensgraphen. Beim Aufbau der Ontologie müssen wir akzeptieren, dass sich die Ontologie ändert, ebenso wie die Tabellenstruktur der Datenbank selbst aktualisiert werden kann. Berücksichtigen Sie daher beim Entwurf unbedingt die Robustheit und Skalierbarkeit. Wenn wir beispielsweise eine Karte eines bestimmten Gerätetyps erstellen, sollten wir das gesamte Gerätesystem berücksichtigen. In Zukunft müssen Sie möglicherweise über dieses System nach Geräten suchen. Sie sollten sich auch darüber im Klaren sein, dass andere Geräte unter diesem System noch keine Karten erstellt haben, die in Zukunft erstellt werden können. Bieten Sie Benutzern im gesamten großen System einen größeren Mehrwert.
Eine Frage, die wir oft hören, ist: Die Antwort finde ich in den FAQ oder im großen Modell. Warum sollte ich die Karte verwenden? Unsere Antwort lautet: Wenn wir das aktuelle Wissen mit der Karte verknüpfen, ist die Welt, die wir sehen, nicht mehr eindimensional, sondern eine vernetzte Welt. Dies ist ein Wert, den die Karte auf der Verbraucherseite realisieren kann, und es ist schwierig, ihn zu erreichen mit anderen Technologien. Derzeit liegt der Fokus aller oft auf der Größe und den verwendeten fortschrittlichen Algorithmen. Tatsächlich sollten wir jedoch über die Konstruktion des Diagramms aus der Perspektive des Verbrauchs und der Problemlösung nachdenken.

Da nun große Modelle vorherrschen, müssen wir die Kombination aus großen Modellen und Diagrammen berücksichtigen. Man kann davon ausgehen, dass der Graph die Anwendung der oberen Schicht ist, während das große Modell die zugrunde liegende Fähigkeit darstellt. Wir können aus verschiedenen Szenarien verstehen, welche Hilfe das große Modell für die Karte bringt.
Beim Erstellen des Diagramms kann die Informationsextraktion über einige Dokumente und Eingabeaufforderungswörter durchgeführt werden, um die ursprüngliche UIE, NER und andere verwandte Technologien zu ersetzen und so die Extraktionsfähigkeit weiter zu verbessern. Wir sollten auch überlegen, ob ein großes Modell oder ein kleines Modell im Fall von Zero-Shot, Fence-Shot und ausreichendem Datentraining besser ist. Auf diese Art von Frage gibt es keine einheitliche Antwort und es gibt unterschiedliche Lösungen für unterschiedliche Szenarien und unterschiedliche Datensätze. Dies ist ein völlig neuer Weg der Wissenskonstruktion. Derzeit verfügen große Modelle in Zero-Shot-Szenarien über bessere Extraktionsfähigkeiten. Sobald jedoch die Stichprobengröße zunimmt, bietet das kleine Modell mehr Vorteile hinsichtlich Kostenleistung und Inferenzgeschwindigkeit.
Auf der Verbraucherseite werden Diagramme verwendet, um Argumentationsprobleme zu lösen, beispielsweise politische Beurteilungen, etwa um zu beurteilen, ob ein Unternehmen eine bestimmte Richtlinie erfüllen kann und ob es die in der Richtlinie genannten Vorteile genießen kann. Der bisherige Ansatz bestand darin, Urteile anhand von Diagrammen, Regeln und Aussageausdrücken zu fällen. Der aktuelle Ansatz ähnelt Graph RAG, der Benutzerfragen verwendet, um Tripel oder Multitupel zu finden, die dem aktuellen Unternehmen ähneln, und große Modelle verwendet, um Antworten zu erhalten und Schlussfolgerungen zu ziehen. Daher können viele Graph-Argumentationsprobleme und Graphkonstruktionsprobleme durch die Technologie großer Modelle gelöst werden.
In Bezug auf die Diagrammspeicherung ist die Datenstruktur der Diagrammdatenbank und des Diagramms selbst sehr wichtig. Große Modelle können kurzfristig keinen langen Text oder das gesamte Diagramm verarbeiten, daher ist die Diagrammspeicherung eine sehr wichtige Richtung. Wie die Vektordatenbank wird sie zu einem sehr wichtigen Bestandteil des zukünftigen großen Modellökosystems. Die Anwendung der oberen Schicht entscheidet, ob diese Komponente zur Lösung des eigentlichen Problems verwendet wird.

Die Diagrammvisualisierung ist ein Front-End-Problem und muss entsprechend dem Szenario und dem zu lösenden Problem entworfen werden. Wir hoffen auch, dass die Technologie als mittlere Plattform genutzt werden kann, um in Zukunft bestimmte Fähigkeiten bereitzustellen, um verschiedenen Interaktionsformen wie mobilen Endgeräten, PCs, Handheld-Geräten usw. gerecht zu werden. Wir müssen nur eine Struktur bereitstellen und festlegen, wie das Front-End auf der Grundlage der tatsächlichen Anforderungen gerendert und präsentiert wird. Auch große Modelle wären eine Möglichkeit, solche Strukturen aufzurufen. Wenn das große Modell oder der Agent anhand der Anforderungen bestimmen kann, wie das Diagramm aufgerufen werden soll, kann der geschlossene Regelkreis geöffnet werden. Graph muss in der Lage sein, bessere APIs zu kapseln, um sich künftig an Aufrufe verschiedener Anwendungen anzupassen. Das Konzept der mittleren Plattform wird zunehmend ernst genommen. Ein unabhängiger und entkoppelter Dienst kann von allen Parteien umfassender genutzt werden.
Manchmal müssen Sie beispielsweise einen bestimmten Wert in einer Tabelle in einem Dokument finden. Es ist schwierig, seine Position durch Suche oder große Modelltechnologie zu finden, wenn Sie die strukturellen Funktionen des Diagramms nutzen, um den Inhalt darzustellen Sie können den Wert dieser Karte abrufen, indem Sie eine Schnittstelle im Anwendungssystem aufrufen und das Dokument dort präsentieren, wo es sich befindet, oder die Analyseergebnisse des großen Modells. Diese Visualisierungsmethode ist für Benutzer am effizientesten. Dies ist auch die derzeit beliebte Copilot-Methode, die darin besteht, Probleme gemeinsam durch Aufrufen von Karten-, Such- oder anderen Anwendungsfunktionen zu lösen und schließlich mithilfe großer Modelle die „letzte Meile“ zu generieren, um die Effizienz zu verbessern.

Jetzt führen wir häufig verschiedene Integrationen von Wissensdatenbanken und Diagrammen durch. In diesem Jahr entstehen viele Wissensprojekte. Bisher war Wissen hauptsächlich für die Suche und den Konsum verfügbar. Mit dem Aufkommen großer Modelle entdeckte jeder, dass Wissen auch großen Modellen zum Konsum zur Verfügung gestellt werden kann. Daher legt jeder mehr Wert auf den Beitrag und Aufbau von Wissen. Wir verfügen selbst über viel Wissen und benötigen auch ein Wissensdiagrammsystem eines Drittanbieters, da unser Wissen unstrukturiert ist und viele sehr wichtige Kenntnisse wie Arbeitsaufträge, Gerätewartungsfälle usw. vorhanden sein werden Dieses Wissen muss auf strukturierte Inhalte übertragen werden. Diese Inhalte wurden zuvor für die Suche verwendet, können aber jetzt für SFT bei großen Modellen verwendet werden.
Die Wissensdatenbank und die Grafik sind natürlich kombinierbar. In Kombination kann eine Reihe von Wissensdienstprodukten für die Außenwelt bereitgestellt werden. Die Vitalität dieses Wissensdienstleistungsprodukts ist sehr groß und es wird eine Nachfrage nach Wissen bestehen, sei es in OA-, ERP-, MIS- oder PRM-Systemen.
Bei der Integration müssen Sie sehr darauf achten, wie Sie Wissen und Daten unterscheiden. Kunden stellen große Datenmengen zur Verfügung, bei diesen Daten handelt es sich jedoch möglicherweise nicht um Wissen. Wir müssen Wissen von der Nachfrageseite aus definieren. Beispielsweise müssen wir für ein Gerät normalerweise alle Daten wissen, z. B. Datenschwankungen, wenn das Gerät läuft, und die Fabrikzeit des Geräts, die letzte Wartungszeit usw. sind Wissen. Die Definition von Wissen ist sehr wichtig und muss gemeinsam unter Beteiligung und Anleitung des Unternehmens entwickelt werden.
3. Industrial Graph Advanced

Im Prozess der digitalen Transformation werden KI- und Graphtechnologien in Szenarien wie Planung, Ausrüstung, Marketing und Analyse eingesetzt. Insbesondere im Dispatching-Szenario, sei es Verkehrsdisposition, Energiedisposition oder Personaldisposition, erfolgt alles in Form einer Aufgabenverteilung. Wenn es beispielsweise brennt, wie viele Personen, Fahrzeuge usw. müssen bei der Planung abgefragt werden? Das aktuelle Problem besteht häufig nicht darin, dass keine Ergebnisse gefunden werden können, sondern darin, dass zu viele Inhalte vorhanden sind wird zurückgegeben, es können jedoch keine wirklich nützlichen Informationen gegeben werden. Da der Wissensverbrauch bei der Stichwortsuche weiterhin bestehen bleibt, werden alle Dokumente angezeigt, die das Wort „Feuer“ enthalten. Für eine bessere Darstellung können Sie die Grafik verwenden. Wenn Sie beispielsweise die Ontologie „Feuer“ entwerfen, ist die obere Ontologie eine Katastrophe. Für die Entität „Feuer“ können Sie ihre Vorsichtsmaßnahmen, Schutzmaßnahmen und Erfahrungsfälle entwerfen. Teilen Sie Wissen durch diese Inhalte auf. Auf diese Weise wird dem Benutzer, wenn er „Feuer“ eingibt, ein relevanter Kartenkontext und die als nächstes zu tunden Schritte angezeigt.
Bei planungsbezogenen Szenarien sollten Sie auf die Anweisungen des Agenten achten. Der Agent ist für die Planung sehr wichtig, da es sich bei der Planung selbst um ein Multitasking-Szenario handelt. Die von der Karte zurückgegebenen Ergebnisse werden genauer und umfangreicher.
Auch für Smart Devices gibt es viele Anwendungsszenarien. Geräteinformationen werden in verschiedenen Systemen gespeichert. Beispielsweise werden Fabrikinformationen in Produkthandbüchern, Wartungsinformationen in Wartungsaufträgen, der Betriebsstatus im Geräteverwaltungssystem und der Inspektionsstatus im industriellen Inspektionssystem gespeichert. . Ein großes Problem der Industrie besteht darin, dass es zu viele Systeme gibt. Wenn Sie die Informationen eines Geräts abfragen möchten, müssen Sie diese von mehreren Systemen aus abfragen, und die Daten in diesen Systemen sind nicht miteinander verbunden. Zu diesem Zeitpunkt wird ein System benötigt, das die Verbindung herstellen und alle Inhalte zuordnen und abbilden kann. Eine Wissensdatenbank mit Wissensgraphen als Kern kann dieses Problem lösen.
Wissensdiagramme können ihre zugehörigen Attribute, Felder, Feldquellen usw. über die Ontologie einschließen und die Reihen- und Parallelbeziehungen zwischen verschiedenen Systemen von unten beschreiben und zuordnen. Bedenken Sie beim Erstellen Ihres Diagramms jedoch, dass Sie Ihr Diagramm entsprechend entwerfen und erstellen müssen. Wenn viele Unternehmen eine Karte erstellen, übertragen sie alle Daten aus dem Rechenzentrum über die D2R-Technologie. Diese Karte hat eigentlich keine Bedeutung. Beim Erstellen einer Karte müssen Sie die Beziehung zwischen der dynamischen Karte und der statischen Karte berücksichtigen.
Es gibt auch viele Anwendungsszenarien und Designtechniken im Bereich intelligentes Marketing und Multi-Szenario-Energie-KI, die hier nicht behandelt werden und später besprochen werden können.

Beim Erstellen eines Diagramms ist die architektonische Gestaltung sehr wichtig. So integrieren Sie zugrunde liegende Bibliotheken und Prozesse in die Graphkonstruktion und -nutzung. Es gibt viele Details zu bedenken, wie es letztendlich geliefert wird. Für Design und Praxis können Sie auf die in der Abbildung oben aufgeführten Links verweisen.
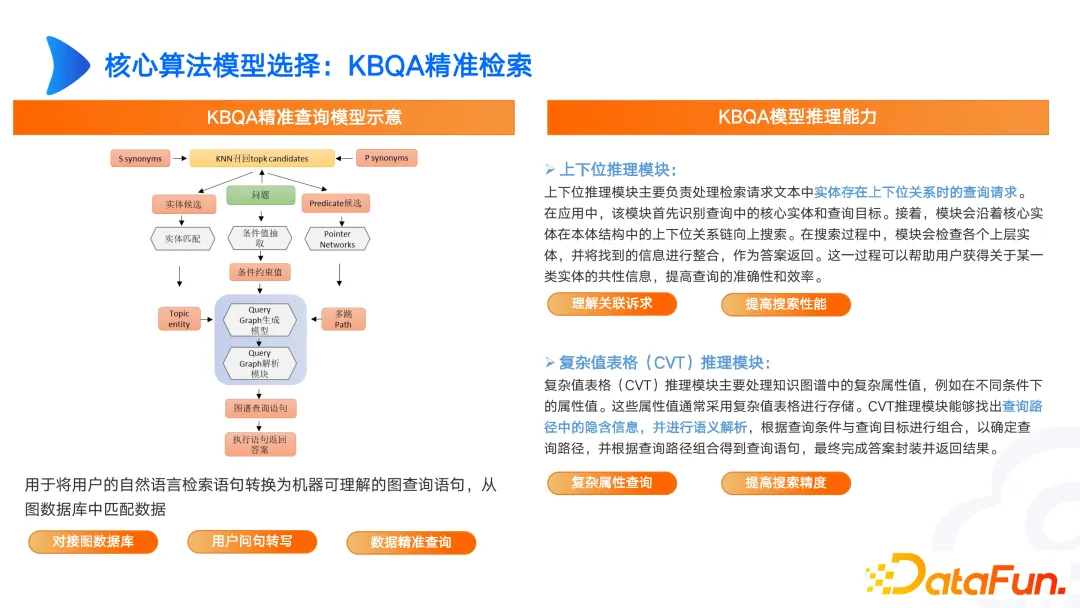
Wir haben auch einige Untersuchungen zum KBQA-Diagramm durchgeführt, z. B. obere und untere Bits, CVT-Abfrage für Diagramme usw. In medizinischen Szenarien werden beispielsweise Fieber und Kopfschmerzen mit abnormalen Körperdarstellungen in Verbindung gebracht. In den Originaldokumenten werden sie nicht separat gespeichert. Wenn es Unterschiede zwischen Benutzerdarstellungen und professionellen Darstellungen gibt, können wir diese durch überlegenes und minderwertiges Denken (CVT) lösen.
Der aktuell erstellte Graph darf nur eine Entitätsausrichtung wie SPO oder Multi-Hop oder TransE aufweisen. In tatsächlichen komplexen Szenarien muss CVT jedoch in Kombination mit oberen und unteren Positionen implementiert werden. Es gibt auch viele Arbeiten, die bei englischen Datensätzen sehr gut abschneiden, aber die Ergebnisse bei chinesischen Datensätzen sind nicht ideal. Daher müssen wir das Design auf der Grundlage unserer eigenen Bedürfnisse entwerfen und kontinuierlich iterieren, um gute Ergebnisse zu erzielen.
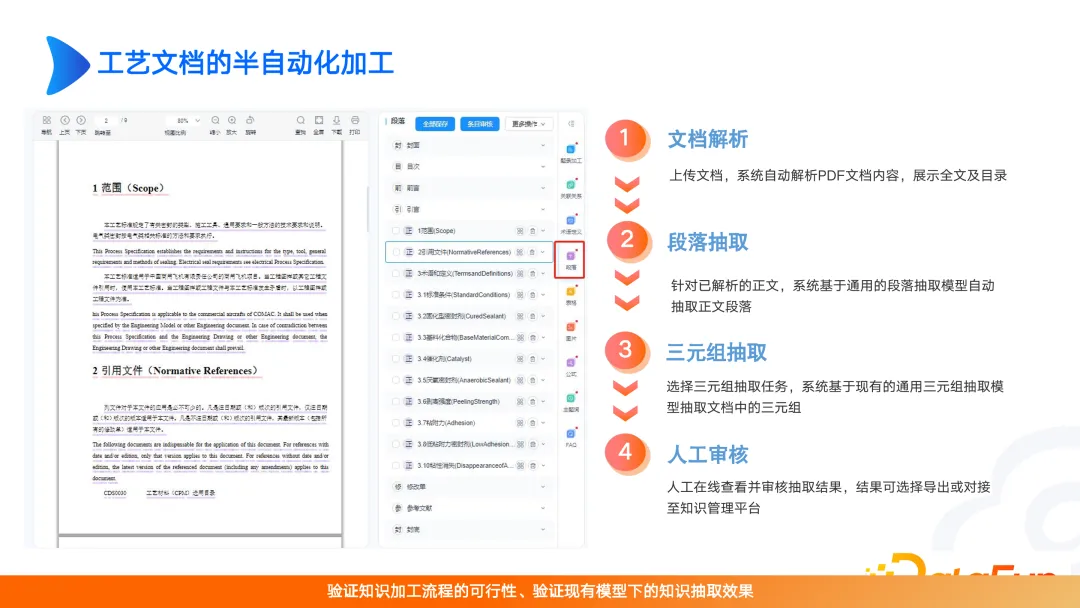
Halbautomatische Dokumentenverarbeitung, einschließlich Dokumentparsing, Absatzextraktion, Dreifachextraktion und manuelle Überprüfung. Dieser Schritt der manuellen Überprüfung wird häufig ignoriert, insbesondere nach der Einführung großer Modelle wird der manuellen Überprüfung weniger Aufmerksamkeit geschenkt. Tatsächlich wird der Modelleffekt erheblich verbessert, wenn Datenverarbeitung und Datenverwaltung durchgeführt werden. Daher müssen wir berücksichtigen, dass das Szenario, das wir letztendlich lösen möchten, einen hohen Wert haben muss, und wir müssen auch darauf achten, wo die Ressourcen investiert werden, sei es in die Erstellung der Karte oder in die Optimierung großer Modelle. Ohne diese Überlegungen kann das Produkt leicht ersetzt oder in Frage gestellt werden.

Das Bild oben zeigt ein Produkt zur Gerätelebenszyklusverwaltung von Yunwen Technology. Solche Szenarien werden durch leichte Zwischenmodule und den Anwendungsaufbau der oberen Schicht in verschiedenen Szenarien realisiert. Die Vitalität dieser Module ist weitaus größer als die Vitalität des Knowledge-Graph-Systems selbst. Der alleinige Verkauf von Standalone- oder Middleware ist im Graphenbereich, insbesondere in industriellen Szenarien, nicht geeignet. Viele industrielle Probleme sind aus Kundensicht sehr komplex und können nicht durch Diagramme oder große Modelle gelöst werden. Wir müssen die Kunden von der Wirkung überzeugen.

Im Prozess der industriellen intelligenten Transformation gibt es viele Anwendungspunkte in Forschung und Entwicklung und Design, Produktionsmanagement, Beschaffungsmanagement, Pre-Sales-Marketing und umfassenden Dienstleistungen.

Das Bild oben ist ein Beispiel für ein Anwendungsszenario einer fehlerhaften Gerätekarte. In diesem Szenario haben wir nicht alle Diagrammelemente, wie z. B. den Betriebsstatus der Ausrüstung und einfache Daten, in eine relationale Datenbank aufgenommen. Wir glauben, dass wir uns bei der Gerätewartung hauptsächlich auf drei Arten von Daten konzentrieren. Der erste Typ sind die grundlegenden Informationen über das Gerät, z. B. der Zeitpunkt, zu dem es das Werk verlassen hat, der Hersteller und die zweite Art von Daten Typ sind Fehler, wie z. B. der Name des Fehlers, übergeordnete und untergeordnete Fehler, welche Fehler verursacht werden, welche Fehlertypen welche Art von Fehlern verursachen usw.; die dritte Kategorie sind Arbeitsaufträge, die beschreiben, bei welchen Fehlern aufgetreten sind welche Ausrüstung. Durch die Verbindung dieser drei Datentypen können wir ein kleines Diagramm mit geschlossenem Regelkreis erstellen. Zukünftig kann es auch auf Basis dynamischer Daten erweitert werden. Daher bevorzugen wir beim Erstellen eines Diagramms die Erstellung eines kleinen, schönen Diagramms mit einer Szene mit geschlossenem Regelkreis. Es handelt sich nicht um eine Karte, die nur ein hohes Maß an Größe anstrebt, aber die Bedürfnisse der Verbraucher nicht erfüllen kann.
Daher müssen wir beim Erstellen eines industriellen Wissensgraphen von bestimmten Szenarien ausgehen und den Graphen durch Analyse der Szenarioanforderungen erstellen, um eine bessere Implementierung und Anwendung zu erreichen.
Das obige ist der detaillierte Inhalt vonFortgeschrittene Praxis des industriellen Wissensgraphen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Tan Dai, Präsident von Volcano Engine, sagte, dass Unternehmen, die große Modelle gut implementieren wollen, vor drei zentralen Herausforderungen stehen: Modelleffekt, Inferenzkosten und Implementierungsschwierigkeiten: Sie müssen über eine gute Basisunterstützung für große Modelle verfügen, um komplexe Probleme zu lösen, und das müssen sie auch Dank der kostengünstigen Inferenzdienste können große Modelle weit verbreitet verwendet werden, und es werden mehr Tools, Plattformen und Anwendungen benötigt, um Unternehmen bei der Implementierung von Szenarien zu unterstützen. ——Tan Dai, Präsident von Huoshan Engine 01. Das große Sitzsackmodell feiert sein Debüt und wird häufig genutzt. Das Polieren des Modelleffekts ist die größte Herausforderung für die Implementierung von KI. Tan Dai wies darauf hin, dass ein gutes Modell nur durch ausgiebigen Gebrauch poliert werden kann. Derzeit verarbeitet das Doubao-Modell täglich 120 Milliarden Text-Tokens und generiert 30 Millionen Bilder. Um Unternehmen bei der Umsetzung groß angelegter Modellszenarien zu unterstützen, wird das von ByteDance unabhängig entwickelte Beanbao-Großmodell durch den Vulkan gestartet
 Entdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Entdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Produktpositionierung von TensorRT-LLM TensorRT-LLM ist eine von NVIDIA entwickelte skalierbare Inferenzlösung für große Sprachmodelle (LLM). Es erstellt, kompiliert und führt Berechnungsdiagramme auf der Grundlage des TensorRT-Deep-Learning-Kompilierungsframeworks aus und stützt sich auf die effiziente Kernels-Implementierung in FastTransformer. Darüber hinaus nutzt es NCCL für die Kommunikation zwischen Geräten. Entwickler können Betreiber entsprechend der Technologieentwicklung und Nachfrageunterschieden an spezifische Anforderungen anpassen, beispielsweise durch die Entwicklung maßgeschneiderter GEMM auf Basis von Entermessern. TensorRT-LLM ist die offizielle Inferenzlösung von NVIDIA, die sich der Bereitstellung hoher Leistung und der kontinuierlichen Verbesserung ihrer Praktikabilität verschrieben hat. TensorRT-LL
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Laut Nachrichten vom 4. April hat die Cyberspace Administration of China kürzlich eine Liste registrierter großer Modelle veröffentlicht, in der das „Jiutian Natural Language Interaction Large Model“ von China Mobile enthalten ist, was darauf hinweist, dass das große Jiutian AI-Modell von China Mobile offiziell generative künstliche Intelligenz bereitstellen kann Geheimdienste nach außen. China Mobile gab an, dass dies das erste groß angelegte Modell sei, das von einem zentralen Unternehmen entwickelt wurde und sowohl die nationale Doppelregistrierung „Generative Artificial Intelligence Service Registration“ als auch die „Domestic Deep Synthetic Service Algorithm Registration“ bestanden habe. Berichten zufolge zeichnet sich Jiutians großes Modell für die Interaktion mit natürlicher Sprache durch verbesserte Branchenfähigkeiten, Sicherheit und Glaubwürdigkeit aus und unterstützt die vollständige Lokalisierung. Es hat mehrere Parameterversionen wie 9 Milliarden, 13,9 Milliarden, 57 Milliarden und 100 Milliarden gebildet. und kann flexibel in der Cloud eingesetzt werden, Edge und End sind unterschiedliche Situationen
 Der GPT Store kann es nicht einmal wagen, diesen Weg einzuschlagen. ?
Apr 19, 2024 pm 09:30 PM
Der GPT Store kann es nicht einmal wagen, diesen Weg einzuschlagen. ?
Apr 19, 2024 pm 09:30 PM
Achtung, dieser Mann hat mehr als 1.000 große Modelle angeschlossen, sodass Sie problemlos anschließen und wechseln können. Kürzlich wurde ein visueller KI-Workflow eingeführt: Er bietet Ihnen eine intuitive Drag-and-Drop-Oberfläche, mit der Sie Ihren eigenen Workflow per Drag-and-Drop auf einer unendlichen Leinwand anordnen können. Wie das Sprichwort sagt: Krieg kostet Geschwindigkeit, und Qubit hörte, dass Benutzer innerhalb von 48 Stunden nach der Online-Schaltung dieses AIWorkflows bereits persönliche Workflows mit mehr als 100 Knoten konfiguriert hatten. Ohne weitere Umschweife möchte ich heute über Dify, ein LLMOps-Unternehmen, und seinen CEO Zhang Luyu sprechen. Zhang Luyu ist auch der Gründer von Dify. Bevor er in das Unternehmen eintrat, verfügte er über 11 Jahre Erfahrung in der Internetbranche. Ich beschäftige mich mit Produktdesign, verstehe Projektmanagement und habe einige einzigartige Einblicke in SaaS. Später er
 Neuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich
Apr 23, 2024 pm 12:13 PM
Neuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich
Apr 23, 2024 pm 12:13 PM
Wenn die Testfragen zu einfach sind, können sowohl Spitzenschüler als auch schlechte Schüler 90 Punkte erreichen, und der Abstand kann nicht vergrößert werden ... Mit der Veröffentlichung stärkerer Modelle wie Claude3, Llama3 und später sogar GPT-5 ist die Branche in Bewegung Dringender Bedarf an einem schwierigeren und differenzierteren Benchmark-Modell. LMSYS, die Organisation hinter der großen Modellarena, brachte den Benchmark der nächsten Generation, Arena-Hard, auf den Markt, der große Aufmerksamkeit erregte. Es gibt auch die neueste Referenz zur Stärke der beiden fein abgestimmten Versionen der Llama3-Anweisungen. Im Vergleich zu MTBench, das zuvor ähnliche Ergebnisse erzielte, stieg die Arena-Hard-Diskriminierung von 22,6 % auf 87,4 %, was auf den ersten Blick stärker und schwächer ist. Arena-Hard basiert auf menschlichen Echtzeitdaten aus der Arena und seine Übereinstimmungsrate mit menschlichen Vorlieben liegt bei bis zu 89,1 %.
 Mithilfe der Shengteng-KI-Technologie hilft das Qinling·Qinchuan-Transportmodell Xi'an beim Aufbau eines intelligenten Transportinnovationszentrums
Oct 15, 2023 am 08:17 AM
Mithilfe der Shengteng-KI-Technologie hilft das Qinling·Qinchuan-Transportmodell Xi'an beim Aufbau eines intelligenten Transportinnovationszentrums
Oct 15, 2023 am 08:17 AM
„Hohe Komplexität, hohe Fragmentierung und Cross-Domain“ waren schon immer die Hauptprobleme auf dem Weg zur digitalen und intelligenten Modernisierung der Transportbranche. Kürzlich ist das „Qinling·Qinchuan Traffic Model“ mit einer Parameterskala von 100 Milliarden, das gemeinsam von China Science Vision, der Bezirksregierung Xi'an Yanta und dem Xi'an Future Artificial Intelligence Computing Center entwickelt wurde, auf den Bereich des intelligenten Transports ausgerichtet und bietet Dienstleistungen für Xi'an und die umliegenden Gebiete. Die Region wird ein Dreh- und Angelpunkt für intelligente Transportinnovationen sein. Das „Qinling·Qinchuan Traffic Model“ kombiniert Xi'ans umfangreiche lokale verkehrsökologische Daten in offenen Szenarien, den ursprünglich von China Science Vision unabhängig entwickelten fortschrittlichen Algorithmus und die leistungsstarke Rechenleistung der Shengteng AI des Xi'an Future Artificial Intelligence Computing Center Überwachung des Straßennetzes, intelligente Transportszenarien wie Notfallkommando, Wartungsmanagement und öffentlicher Verkehr führen zu digitalen und intelligenten Veränderungen. Das Verkehrsmanagement weist in verschiedenen Städten und auf verschiedenen Straßen unterschiedliche Merkmale auf
