Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Das aktuelle Mainstream-Visual-Language-Modell (VLM) basiert zur weiteren Feinabstimmung hauptsächlich auf dem Large Language Model (LLM). Daher ist es notwendig, das Bild auf verschiedene Weise dem Einbettungsraum von LLM zuzuordnen und dann autoregressive Methoden zu verwenden, um die Antwort basierend auf dem Bild-Token vorherzusagen. In diesem Prozess wird die modale Ausrichtung implizit durch Text-Tokens umgesetzt Es ist sehr wichtig, diesen Schritt gut auszurichten. Als Reaktion auf dieses Problem schlugen Forscher der Universität Wuhan, des ByteDance Beanbao Large Model Team und der University of Chinese Academy of Sciences eine Text-Token-Screening-Methode (CAL) vor, die auf kontrastivem Lernen basiert, um Text-Tokens auszusortieren, die vorhanden sind Das Gewicht der Verlustfunktion wird erhöht, um eine genauere multimodale Ausrichtung zu erreichen.
- Papierlink: https://arxiv.org/pdf/2405.17871
- Codelink: https://github.com/foundation-multimodal-models/CAL
CAL hat folgende Highlights:
- kann ohne zusätzliche Vorbereitungsphase direkt in den Trainingsprozess eingebettet werden.
- hat erhebliche Verbesserungen bei OCR- und Untertitel-Benchmarks erzielt. Aus der Visualisierung geht hervor, dass CAL die modale Ausrichtung des Bildes verbessert.
- CAL macht den Trainingsprozess resistenter gegen verrauschte Daten.
Derzeit basiert das visuelle Sprachmodell auf der Ausrichtung von Bildmodalitäten, und es ist sehr wichtig, wie die Ausrichtung durchgeführt wird. Die derzeitige gängige Methode besteht darin, eine implizite Ausrichtung durch Text-Autoregression durchzuführen, aber der Beitrag jedes Text-Tokens zur Bildausrichtung ist sehr wichtig. Es ist sehr wichtig, diese Text-Token zu unterscheiden.
CAL schlug vor, dass in den vorhandenen Trainingsdaten des visuellen Sprachmodells (VLM) Text-Tokens in drei Kategorien unterteilt werden können:
- Text, der eng mit Bildern verbunden ist: wie Entitäten ( B. Menschen, Tiere, Gegenstände), Menge, Farbe, Text usw. Diese Token entsprechen direkt den Bildinformationen und sind für die multimodale Ausrichtung von entscheidender Bedeutung.
- Text mit geringer Korrelation zum Bild: Zum Beispiel folgende Wörter oder Inhalte, die aus dem vorherigen Text abgeleitet werden können. Diese Token werden eigentlich hauptsächlich zum Trainieren der Klartextfunktionen von VLM verwendet.
- Text, der dem Bildinhalt widerspricht: Diese Token stimmen nicht mit den Bildinformationen überein und können sogar irreführende Informationen liefern, was sich negativ auf den multimodalen Ausrichtungsprozess auswirkt.
标 Abbildung 1: Die grüne Markierung bezieht sich auf den hochbezogenen Token, die rote auf den Inhalt und die farblose auf den neutralen Token.
Während des Trainingsprozesses werden die beiden letztgenannten Typen angezeigt Tatsächlich nehmen Token einen größeren Anteil ein, aber da sie nicht stark vom Bild abhängig sind, haben sie kaum Auswirkungen auf die modale Ausrichtung des Bildes. Um eine bessere Ausrichtung zu erreichen, ist es daher erforderlich, das Gewicht des ersten Typs von Text-Token zu erhöhen, d. h. der Token, die einen engen Bezug zum Bild haben. Wie man diesen Teil des Tokens findet, ist zum Schlüssel zur Lösung dieses Problems geworden. Methode
Token finden, die in hohem Maße mit dem Bild zusammenhängen. Dieses Problem kann durch die kontrastive Bedingung gelöst werden.
Für jedes Bild-Text-Paar in den Trainingsdaten stellt der Logit auf jedem Text-Token LLMs Schätzung des Auftretens dieser Situation basierend auf dem Kontext und dem vorhandenen Wissenswert dar.
- Wenn Sie vorab eine Bildeingabe hinzufügen, entspricht dies der Bereitstellung zusätzlicher Kontextinformationen. In diesem Fall wird das Logit jedes Text-Tokens an die neue Situation angepasst. Die Logit-Änderungen in diesen beiden Fällen stellen die Auswirkung des neuen Zustands des Bildes auf jedes Text-Token dar.
Konkret gibt CAL während des Trainingsprozesses die Bild- und Textsequenzen sowie einzelne Textsequenzen in das große Sprachmodell (LLM) ein, um den Logit jedes Text-Tokens zu erhalten. Durch die Berechnung der Logit-Differenz zwischen den beiden Fällen können wir die Auswirkung des Bildes auf jeden Token messen. Je größer die Logit-Differenz ist, desto größer ist der Einfluss des Bildes auf das Token, sodass das Token für das Bild relevanter ist. Die folgende Abbildung zeigt das Flussdiagramm der Logit-Diff- und CAL-Methoden für Text-Tokens.对 Abbildung 2: Das linke Bild ist die Visualisierung des Token-Logit-Diffs in den beiden Situationen. Das Bild rechts ist die Visualisierung des CAL-Methodenprozesses
 Cal in Llava. Die experimentelle Verifizierung wurde an zwei durchgeführt Mainstream-Modelle: MGM und MGM, und Leistungsverbesserungen wurden bei Modellen unterschiedlicher Größe erzielt. Enthält die folgenden vier Teile der Verifizierung:
Cal in Llava. Die experimentelle Verifizierung wurde an zwei durchgeführt Mainstream-Modelle: MGM und MGM, und Leistungsverbesserungen wurden bei Modellen unterschiedlicher Größe erzielt. Enthält die folgenden vier Teile der Verifizierung: (1) Modelle, die CAL verwenden, schneiden bei verschiedenen Benchmark-Indikatoren besser ab.
(2) Erstellen Sie einen Stapel von Rauschdaten (Bild-Text-Nichtübereinstimmung), indem Sie den Text in den beiden Bild-Text-Paaren zufällig proportional austauschen, und verwenden Sie ihn für die Modelltrainings-CAL Macht den Trainingsprozess. Hat eine stärkere Daten-Anti-Rauschen-Leistung.度 Abbildung 3: Bei Lärmtraining mit unterschiedlicher Intensität werden anhand der Leistung von CAL und der Basislinie
(3) die Aufmerksamkeitswerte des Bildtokens im Antwortteil des QA-Falls berechnet und grafisch dargestellt Auf dem Originalbild verfügt das CAL-trainierte Modell über eine klarere Aufmerksamkeitsverteilungskarte.
C Abbildung 4: Die Grundlinie und die Aufmerksamkeitskarte von CAL können mit dem Text-Token in seinem ähnlichsten LLM-Vokabular visualisiert werden Im Originalbild liegt der Mapping-Inhalt des CAL-trainierten Modells näher am Bildinhalt. Abbildung 5: Imam ist dem Bild-Token am ähnlichsten und entspricht dem Originalbild. Das Modellteam wurde 2023 gegründet und hat sich zum Ziel gesetzt, die fortschrittlichste KI-Großmodelltechnologie der Branche zu entwickeln und ein Weltklasse-Forschungsteam zu werden und einen Beitrag zur technologischen und sozialen Entwicklung zu leisten.
Das Doubao Big Model-Team verfügt über eine langfristige Vision und Entschlossenheit auf dem Gebiet der KI. Seine Forschungsrichtungen umfassen NLP, Lebenslauf, Sprache usw. und es verfügt über Labore und Forschungsstellen in China. Singapur, die Vereinigten Staaten und andere Orte. Gestützt auf die ausreichenden Daten-, Rechen- und anderen Ressourcen der Plattform investiert das Team weiterhin in verwandte Bereiche. Es hat ein selbst entwickeltes allgemeines Großmodell zur Bereitstellung multimodaler Funktionen eingeführt, das über 50 Unternehmen wie Doubao, Buttons, unterstützt. und Jimeng und ist offen für die Volcano-Firmenkunden. Derzeit ist Doubao APP die AIGC-Anwendung mit der größten Benutzerzahl auf dem chinesischen Markt. Willkommen im ByteDance Beanbao-Modellteam. Das obige ist der detaillierte Inhalt vonBytedance Doubao und die Wuhan University schlugen CAL vor: Verbesserung multimodaler Ausrichtungseffekte durch visuell verwandte Token. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




 Cal in Llava. Die experimentelle Verifizierung wurde an zwei durchgeführt Mainstream-Modelle: MGM und MGM, und Leistungsverbesserungen wurden bei Modellen unterschiedlicher Größe erzielt.
Cal in Llava. Die experimentelle Verifizierung wurde an zwei durchgeführt Mainstream-Modelle: MGM und MGM, und Leistungsverbesserungen wurden bei Modellen unterschiedlicher Größe erzielt. 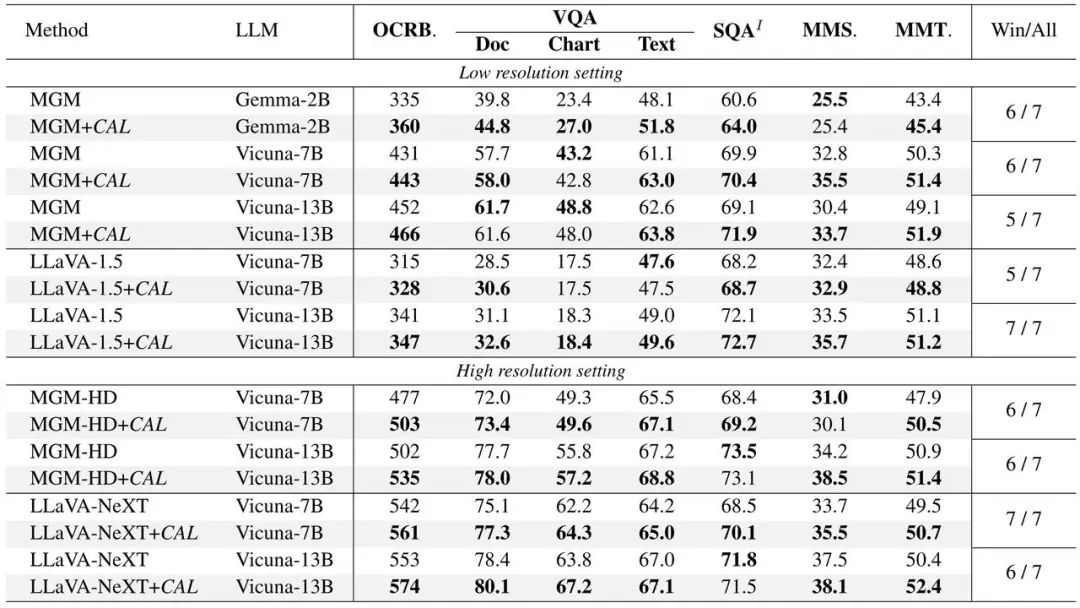
 Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
 Empfohlene Reihenfolge zum Erlernen von C++ und der C-Sprache
Empfohlene Reihenfolge zum Erlernen von C++ und der C-Sprache
 So lösen Sie verstümmelte Zeichen in PHP
So lösen Sie verstümmelte Zeichen in PHP
 Methode zur Reparatur von Datenbankzweifeln
Methode zur Reparatur von Datenbankzweifeln
 Timeout-Lösung für Serveranfragen
Timeout-Lösung für Serveranfragen
 IIS unerwarteter Fehler 0x8ffe2740 Lösung
IIS unerwarteter Fehler 0x8ffe2740 Lösung
 navigator.useragent
navigator.useragent
 So erhalten Sie ein Token
So erhalten Sie ein Token








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



