Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Das Forschungsteam des Generative Artificial Intelligence Laboratory (GAIR Lab) der Shanghai Jiao Tong University, die Hauptforschungsrichtungen sind: Training großer Modelle , Ausrichtung und Auswertung. Team-Homepage: https://plms.ai/Die KI-Technologie verändert sich mit jedem Tag. Vor kurzem wurde das neueste Claude-3.5-Sonett von Anthropic Company in großem Umfang in der Wissensbranche eingesetzt. Basierendes Denken, mathematisches Denken, Programmieraufgaben und visuelles Denken Das Setzen neuer Branchenmaßstäbe für andere Aufgaben hat eine breite Diskussion ausgelöst: Hat Claude-3.5-Sonnet OpenAIs GPT4o als „intelligentste KI“ der Welt abgelöst? Die Herausforderung bei der Beantwortung dieser Frage besteht darin, dass wir zunächst einen ausreichend anspruchsvollen Intelligenztest-Benchmark benötigen, der es uns ermöglicht, das aktuell höchste KI-Niveau zu unterscheiden. Die OlympicArena[1] (Olympische Arena), die vom Generative Artificial Intelligence Laboratory (GAIR Lab) der Shanghai Jiao Tong University ins Leben gerufen wurde, erfüllt diesen Bedarf.
Der Olympische Fachwettbewerb ist nicht nur eine extreme Herausforderung für die Denkfähigkeit, die Beherrschung von Wissen und das logische Denken des Menschen (kohlenstoffbasierte Intelligenz), sondern auch ein hervorragendes Trainingsgelände für KI („siliziumbasierte Intelligenz“). ). Ein wichtiger Maßstab, um den Abstand zwischen KI und „Superintelligenz“ zu messen. OlympicArena – eine echte KI-Olympia-Arena. Hier muss die KI nicht nur ihre Tiefe in traditionellen Fachkenntnissen unter Beweis stellen (Top-Wettbewerbe wie Mathematik, Physik, Biologie, Chemie, Geographie usw.), sondern auch bei den kognitiven Denkfähigkeiten zwischen Modellen konkurrieren.
Kürzlich schlug dasselbe Forschungsteam zum ersten Mal die Verwendung der Methode „
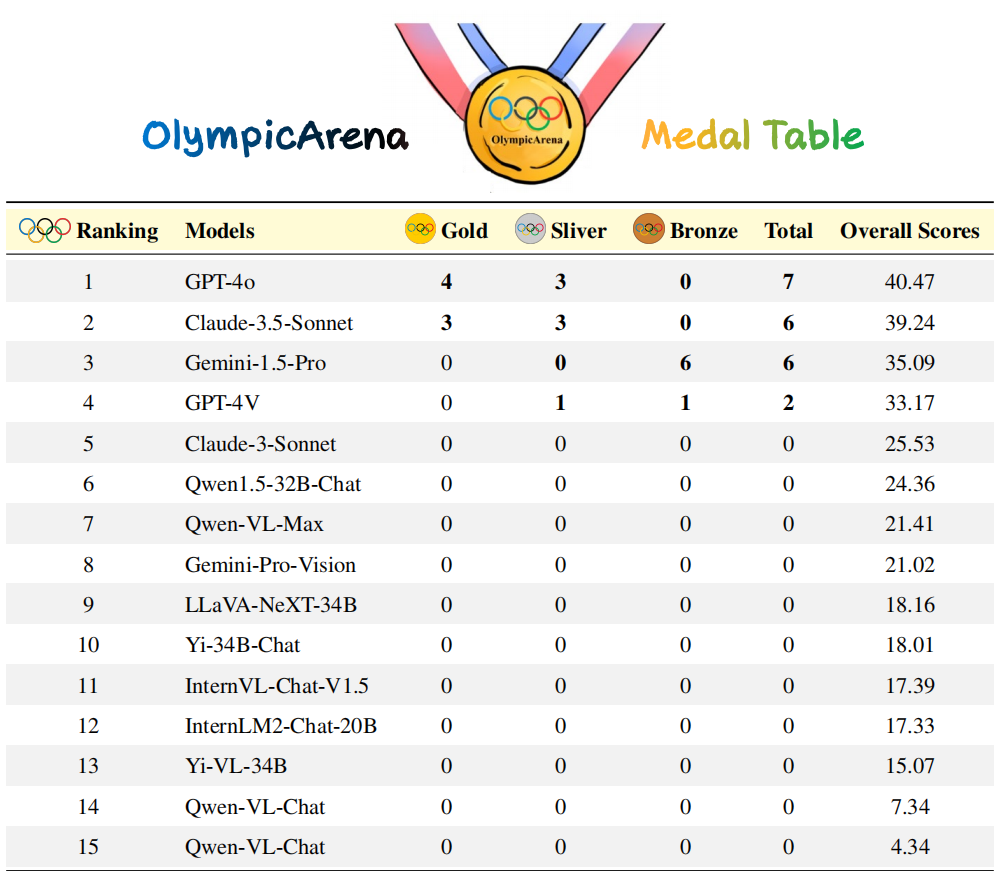
Olympic Medal List“ vor, um jedes KI-Modell anhand seiner Gesamtleistung in der olympischen Arena (verschiedene Disziplinen) einzustufen und auszuwählen das Beste bisher Die intelligenteste KI. In diesem Bereich konzentrierte sich das Forschungsteam auf die Analyse und den Vergleich zweier kürzlich veröffentlichter fortgeschrittener Modelle – Claude-3.5-Sonnet und Gemini-1.5-Pro – sowie der GPT-4-Serie von OpenAI (z. B. GPT4o). Auf diese Weise hofft das Forschungsteam, die Entwicklung der KI-Technologie besser bewerten und vorantreiben zu können. 
: Das Forschungsteam sortiert die Modelle zunächst nach der Anzahl der Goldmedaillen Ebenso sind sie nach der Gesamtleistungsbewertung sortiert. Die experimentellen Ergebnisse zeigen, dass: Claude-3.5-Sonnet in der Gesamtleistung äußerst konkurrenzfähig zu GPT-4o ist und in einigen Fächern sogar GPT-4o übertrifft (z in Physik, Chemie und Biologie). Gemini-1.5-Pro und GPT-4V liegen knapp hinter GPT-4o und Claude-3.5-Sonnet, zwischen ihnen besteht jedoch ein deutlicher Leistungsunterschied.
-
Die Leistung der KI-Modelle der Open-Source-Community bleibt deutlich hinter diesen proprietären Modellen zurück.
-
Die unbefriedigende Leistung dieser Modelle bei diesem Benchmark zeigt, dass wir auf dem Weg zur Superintelligenz noch einen langen Weg vor uns haben.
-
- Projekthomepage: https://gair-nlp.github.io/OlympicArena/
Experimentelle EinstellungenDas Forschungsteam nahm das Testset von OlympicArena zur Bewertung. Die Antworten auf diesen Testsatz werden nicht veröffentlicht, um Datenlecks vorzubeugen und somit die tatsächliche Leistung des Modells widerzuspiegeln. Das Forschungsteam testete multimodale große Modelle (LMMs) und Nur-Text-große Modelle (LLMs). Beim Testen von LLMs werden dem Modell keine bildbezogenen Informationen als Eingabe bereitgestellt, sondern nur Text. Bei allen Beurteilungen werden Eingabeaufforderungswörter aus der Zero-Shot-Gedankenkette verwendet. Das Forschungsteam evaluierte eine Reihe multimodaler großer Open- und Closed-Source-Modelle (LMMs) und Nur-Text-großer Modelle (LLMs). Für LMMs wurden Closed-Source-Modelle wie GPT-4o, GPT-4V, Claude-3-Sonnet, Gemini Pro Vision, Qwen-VL-Max usw. ausgewählt, außerdem LLaVA-NeXT-34B, InternVL-Chat -V1.5, Yi-VL-34B und Qwen-VL-Chat sowie andere Open-Source-Modelle wurden ebenfalls evaluiert. Für LLMs wurden hauptsächlich Open-Source-Modelle wie Qwen-7B-Chat, Qwen1.5-32B-Chat, Yi-34B-Chat und InternLM2-Chat-20B evaluiert. Darüber hinaus hat das Forschungsteam gezielt das neu erschienene Claude-3.5-Sonnet sowie Gemini-1.5-Pro einbezogen und mit den leistungsstarken GPT-4o und GPT-4V verglichen. um die neueste Modellleistung widerzuspiegeln. Metriken Da alle Probleme durch regelbasiertes Matching bewertet werden können, verwendete das Forschungsteam Genauigkeit für Nicht-Programmieraufgaben und unvoreingenommene Pass@k-Metriken für Programmieraufgaben, definiert als folgt:
In dieser Auswertung werden k = 1 und n = 5 gesetzt und c stellt die Anzahl der korrekten Proben dar, die alle Testfälle bestehen. Medaillenliste der Olympischen Arena: Ähnlich dem Medaillensystem der Olympischen Spiele handelt es sich um einen bahnbrechenden Ranking-Mechanismus, der speziell zur Bewertung der Leistung von KI-Modellen in verschiedenen akademischen Bereichen entwickelt wurde. Die Tabelle vergibt Medaillen an die Modelle, die in einer bestimmten Disziplin die besten drei Ergebnisse erzielen, und bietet so einen klaren und wettbewerbsfähigen Rahmen für den Vergleich verschiedener Modelle. Das Forschungsteam sortierte die Modelle zunächst nach der Anzahl der Goldmedaillen. Bei gleicher Anzahl der Goldmedaillen wurden sie nach der Gesamtleistungsbewertung sortiert. Es bietet eine intuitive und prägnante Möglichkeit, führende Modelle in verschiedenen akademischen Bereichen zu identifizieren und erleichtert Forschern und Entwicklern das Verständnis der Stärken und Schwächen verschiedener Modelle. Feingranulare Beurteilung: Das Forschungsteam führt auch eine genauigkeitsbasierte, feinkörnige Beurteilung durch, die auf verschiedenen Disziplinen, unterschiedlichen Modalitäten, verschiedenen Sprachen und verschiedenen Arten von logischen und visuellen Denkfähigkeiten basiert. Der Analyseinhalt konzentriert sich hauptsächlich auf Claude-3.5-Sonnet und GPT-4o und diskutiert teilweise auch die Leistung von Gemini-1.5-Pro.
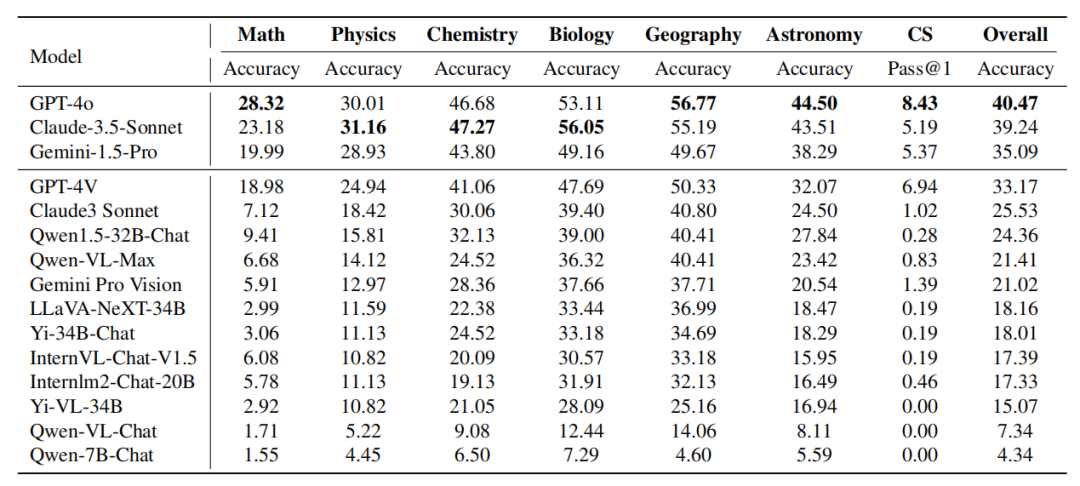
Tabelle: Leistung des Modells bei verschiedenen Themen. Die Leistung von Claude-3.5-Sonnet ist leistungsstark und erreicht nahezu vergleichbar mit GPT-4o. Der Gesamtgenauigkeitsunterschied zwischen den beiden beträgt nur etwa 1 %. Der neu veröffentlichte Gemini-1.5-Pro hat ebenfalls beträchtliche Stärke gezeigt und GPT-4V (das derzeit zweitstärkste Modell von OpenAI) in den meisten Disziplinen übertroffen.
Es ist erwähnenswert, dass zum Zeitpunkt des Schreibens das früheste dieser drei Modelle erst vor einem Monat auf den Markt kam, was die rasante Entwicklung in diesem Bereich widerspiegelt.
- Feinkörnige Analyse für Disziplinen
GPT-4o vs. Claude-3.5-Sonnet:
Obwohl GPT-4o und Claude-3. 5-Sonett Im Großen und Ganzen ist die Leistung ähnlich, allerdings weisen beide Modelle unterschiedliche Fachvorteile auf. GPT-4o demonstriert überlegene Fähigkeiten bei traditionellen deduktiven und induktiven Denkaufgaben, insbesondere in Mathematik und Informatik. Claude-3.5-Sonnet schneidet in Fächern wie Physik, Chemie und Biologie gut ab, insbesondere in der Biologie, wo es GPT-4o um 3 % übertrifft.
GPT-4V vs. Gemini-1.5-Pro: Ein ähnliches Phänomen lässt sich beim Vergleich von Gemini-1.5-Pro vs. GPT-4V beobachten. Gemini-1.5-Pro übertrifft GPT-4V in Physik, Chemie und Biologie deutlich. In Bezug auf Mathematik und Informatik sind die Vorteile von Gemini-1.5-Pro jedoch nicht offensichtlich oder sogar denen von GPT-4V unterlegen. Aus diesen beiden Vergleichsreihen geht hervor, dass: Die GPT-Serie von OpenAI schneidet bei traditionellen mathematischen Argumentations- und Programmierfähigkeiten hervorragend ab. Dies zeigt, dass die Modelle der GPT-Serie streng darauf trainiert wurden, Aufgaben zu bewältigen, die viel deduktives Denken und algorithmisches Denken erfordern. Im Gegensatz dazu zeigten andere Modelle wie Claude-3.5-Sonnet und Gemini-1.5-Pro konkurrenzfähige Leistung, wenn es um Fächer geht, die eine Kombination von Wissen und logischem Denken erfordern, wie etwa Physik, Chemie und Biologie. Dies spiegelt die Fachgebiete und potenziellen Trainingsschwerpunkte der verschiedenen Modelle wider und weist auf mögliche Kompromisse zwischen schlussfolgerungsintensiven Aufgaben und Wissensintegrationsaufgaben hin. Feinkörnige Analyse von Argumentationstypen
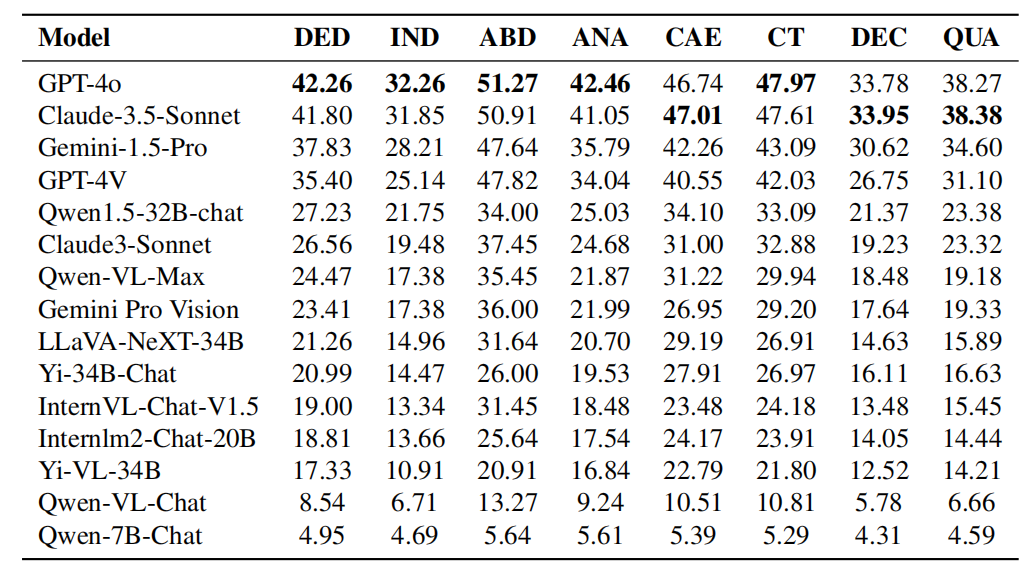
- Bildunterschrift: Die Leistung jedes Modells in Bezug auf logisches Denken. Zu den Fähigkeiten des logischen Denkens gehören: deduktives Denken (DED), induktives Denken (IND), abduktives Denken (ABD), analoges Denken (ANA), kausales Denken (CAE), kritisches Denken (CT), Dekompositionsdenken (DEC) und quantitatives Denken ( QUA).
Vergleich zwischen GPT-4o und Claude-3.5-Sonett im Hinblick auf die logischen Denkfähigkeiten:
Wie aus den experimentellen Ergebnissen in der Tabelle ersichtlich ist, weist GPT-4o eine hervorragende Leistung auf in den meisten Fähigkeiten zum logischen Denken. Besser als Claude-3.5-Sonett in Bereichen wie deduktives Denken, induktives Denken, abduktives Denken, analoges Denken und kritisches Denken. Allerdings übertrifft Claude-3.5-Sonett GPT-4o im kausalen Denken, beim Zerlegungsdenken und beim quantitativen Denken. Insgesamt ist die Leistung beider Modelle vergleichbar, wobei GPT-4o in den meisten Kategorien leicht im Vorteil ist. Tabelle: Leistung jedes Modells in Bezug auf visuelle Denkfähigkeiten. Zu den Fähigkeiten zum visuellen Denken gehören: Mustererkennung (PR), räumliches Denken (SPA), schematisches Denken (DIA), symbolische Interpretation (SYB) und visueller Vergleich (COM). GPT-4o vs. Claude-3.5-Sonnet Leistung im visuellen Denkvermögen: Wie aus den experimentellen Ergebnissen in der Tabelle ersichtlich ist, ist Claude-3.5-Sonnet besser Mustererkennung und Führend im Diagrammdenken, was seine Wettbewerbsfähigkeit bei der Mustererkennung und Interpretation von Diagrammen unter Beweis stellt. Die beiden Modelle schnitten bei der Symbolinterpretation vergleichbar ab, was darauf hindeutet, dass sie über vergleichbare Fähigkeiten beim Verstehen und Verarbeiten symbolischer Informationen verfügen. Allerdings übertrifft GPT-4o Claude-3.5-Sonnet beim räumlichen Denken und beim visuellen Vergleich und demonstriert seine Überlegenheit bei Aufgaben, die das Verständnis räumlicher Beziehungen und den Vergleich visueller Daten erfordern. Umfassende Analyse von Disziplinen und Argumentationsarten, das Forschungsteam stellte fest, dass:
- Mathematik und Computerprogrammierung legen Wert auf komplexe deduktive Denkfähigkeiten und die regelbasierte Ableitung universeller Schlussfolgerungen und verlassen sich tendenziell weniger darauf bereits vorhandenes Wissen. Im Gegensatz dazu benötigen Disziplinen wie Chemie und Biologie oft große Wissensbasen, um auf der Grundlage bekannter Informationen über kausale Zusammenhänge und Phänomene Schlüsse zu ziehen. Dies deutet darauf hin, dass mathematische Fähigkeiten und Programmierfähigkeiten zwar immer noch gültige Indikatoren für die Argumentationsfähigkeit eines Modells sind, andere Disziplinen jedoch die Fähigkeit eines Modells, auf der Grundlage seines internen Wissens zu argumentieren und Probleme zu analysieren, besser testen.
- Die Merkmale verschiedener Disziplinen zeigen die Bedeutung maßgeschneiderter Trainingsdatensätze. Um beispielsweise die Modellleistung in wissensintensiven Fächern wie Chemie und Biologie zu verbessern, muss das Modell während des Trainings umfassend mit domänenspezifischen Daten konfrontiert werden. Im Gegensatz dazu können Modelle bei Fächern, die starke Logik und deduktives Denken erfordern, wie Mathematik und Informatik, von einer Schulung profitieren, die sich auf rein logisches Denken konzentriert.
- Darüber hinaus zeigt die Unterscheidung zwischen Argumentationsfähigkeit und Wissensanwendung das Potenzial des Modells für eine disziplinübergreifende Anwendung. Beispielsweise können Modelle mit starken deduktiven Denkfähigkeiten Bereiche unterstützen, in denen systematisches Denken zur Lösung von Problemen erforderlich ist, beispielsweise die wissenschaftliche Forschung. Und wissensreiche Modelle sind in Disziplinen wertvoll, die stark auf vorhandene Informationen angewiesen sind, wie etwa Medizin und Umweltwissenschaften. Das Verständnis dieser Nuancen hilft bei der Entwicklung spezialisierterer und vielseitigerer Modelle.的 Analyse der Feingranularität des Sprachtyps
Bildunterschrift: Die Fähigkeit, verschiedene Sprachprobleme in verschiedenen Sprachen zu lösen. Die obige Tabelle zeigt die Leistung des Modells in verschiedenen Sprachen. Das Forschungsteam stellte fest, dass die meisten Modelle auf Englisch genauer waren als auf Chinesisch, wobei dieser Unterschied bei den am besten bewerteten Modellen besonders groß war. Es wird spekuliert, dass es mehrere Gründe geben könnte:
Obwohl diese Modelle eine große Menge chinesischer Trainingsdaten enthalten und über sprachübergreifende Generalisierungsfunktionen verfügen, basieren ihre Trainingsdaten hauptsächlich auf Englisch.
Chinesische Fragen sind anspruchsvoller als englische Fragen, insbesondere in Fächern wie Physik und Chemie sind chinesische Olympia-Fragen schwieriger.
- Diese Modelle reichen nicht aus, um Zeichen in multimodalen Bildern zu identifizieren, und dieses Problem ist im chinesischen Umfeld noch schwerwiegender.
- Allerdings stellte das Forschungsteam auch fest, dass einige Modelle, die von chinesischen Herstellern entwickelt oder auf Basis von Basismodellen, die Chinesisch unterstützen, optimiert wurden, in chinesischen Szenarien besser abschneiden als in englischen Szenarien, wie zum Beispiel Qwen1.5-32B- Chat, Qwen-VL-Max, Yi-34B-Chat und Qwen-7B-Chat usw. Andere Modelle wie InternLM2-Chat-20B und Yi-VL-34B schneiden zwar immer noch besser auf Englisch ab, weisen jedoch viel geringere Genauigkeitsunterschiede zwischen englischen und chinesischen Szenen auf als die vielen am besten bewerteten Closed-Source-Modelle. Dies zeigt, dass der Optimierung von Modellen für chinesische Daten und noch mehr Sprachen weltweit noch erhebliche Aufmerksamkeit bedarf.
Feinkörnige Analyse von Modalitäten
zu zu zu zu zu zu zu zu zu Die obige Tabelle zeigt die Leistung des Modells in verschiedenen Modalitäten. GPT-4o übertrifft Claude-3.5-Sonnet sowohl bei Klartext- als auch bei multimodalen Aufgaben und schneidet bei Klartext besser ab. Andererseits schneidet Gemini-1.5-Pro sowohl bei Klartext- als auch bei multimodalen Aufgaben besser ab als GPT-4V. Diese Beobachtungen deuten darauf hin, dass selbst die stärksten derzeit verfügbaren Modelle bei Nur-Text-Aufgaben eine höhere Genauigkeit aufweisen als bei multimodalen Aufgaben. Dies zeigt, dass das Modell bei der Nutzung multimodaler Informationen zur Lösung komplexer Argumentationsprobleme noch erheblichen Verbesserungsbedarf hat. In diesem Review konzentrierte sich das Forschungsteam hauptsächlich auf die neuesten Modelle: Claude-3.5-Sonnet und Gemini-1.5-Pro und verglich sie mit OpenAIs GPT-4o und GPT- 4V zum Vergleich. Darüber hinaus entwickelte das Forschungsteam ein neuartiges Rangsystem für große Modelle, den OlympicArena Medal Table, um die Fähigkeiten verschiedener Modelle klar vergleichen zu können. Das Forschungsteam stellte fest, dass GPT-4o in Fächern wie Mathematik und Informatik hervorragende Leistungen erbringt und über starke Fähigkeiten zum komplexen deduktiven Denken sowie die Fähigkeit verfügt, auf der Grundlage von Regeln allgemeine Schlussfolgerungen zu ziehen. Claude-3.5-Sonett hingegen ist besser darin, aus etablierten Kausalzusammenhängen und Phänomenen zu schließen. Darüber hinaus stellte das Forschungsteam auch fest, dass diese Modelle bei Problemen mit der englischen Sprache eine bessere Leistung erbrachten und erheblichen Raum für Verbesserungen bei den multimodalen Fähigkeiten boten. Das Verständnis dieser Modellnuancen kann dazu beitragen, spezialisiertere Modelle zu entwickeln, die den unterschiedlichen Anforderungen verschiedener akademischer und beruflicher Bereiche besser gerecht werden. Während das alle vier Jahre stattfindende olympische Ereignis näher rückt, können wir nicht umhin, uns vorzustellen, was für ein Gipfeltreffen zwischen Weisheit und Technologie es sein wird, wenn auch künstliche Intelligenz teilnehmen kann? Es handelt sich nicht mehr nur um einen physischen Wettbewerb. Die Hinzufügung von KI wird zweifellos eine neue Erkundung der Grenzen der Intelligenz eröffnen. Wir freuen uns auch darauf, dass weitere KI-Spieler an dieser intellektuellen Olympiade teilnehmen. [1] Huang et al., OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI. https://arxiv.org/abs/2406.12753 v1
Das obige ist der detaillierte Inhalt vonWahl der intelligentesten KI der Olympiade: Claude-3.5-Sonnet vs. GPT-4o?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



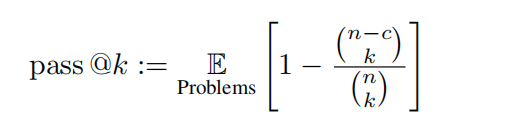

 Konfiguration der Python-Umgebungsvariablen
Konfiguration der Python-Umgebungsvariablen
 So überprüfen Sie die CPU-Auslastung unter Linux
So überprüfen Sie die CPU-Auslastung unter Linux
 Einführung in die Methode zum Abfangen von Zeichenfolgen in js
Einführung in die Methode zum Abfangen von Zeichenfolgen in js
 IP ändern
IP ändern
 So verwenden Sie die Vlookup-Funktion
So verwenden Sie die Vlookup-Funktion
 psrpc.dll keine Lösung gefunden
psrpc.dll keine Lösung gefunden
 So lösen Sie das Problem, dass JS-Code nach der Formatierung nicht ausgeführt werden kann
So lösen Sie das Problem, dass JS-Code nach der Formatierung nicht ausgeführt werden kann
 So konvertieren Sie PDF-Dateien in PDF
So konvertieren Sie PDF-Dateien in PDF
 Was ist ein UI-Designer?
Was ist ein UI-Designer?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



