

Mit
DiT können Videos ohne Qualitätsverlust und ohne Schulungsaufwand erstellt werden.
Die KI-Videogenerierung in Echtzeit ist da!
Am Mittwoch schlug das Team von You Yang von der National University of Singapore die branchenweit erste DiT-basierte Methode zur Videogenerierung vor, die in Echtzeit ausgegeben werden kann.

Die Technologie heißt Pyramid Attention Broadcast (PAB). Durch die Reduzierung redundanter Aufmerksamkeitsberechnungen erreicht PAB Bildraten von bis zu 21,6 FPS und eine 10,6-fache Beschleunigung, ohne auf die Vorteile beliebter DiT-basierter Videogenerierungsmodelle wie Open-Sora, Open-Sora-Plan und Latte-Qualität zu verzichten. Es ist erwähnenswert, dass PAB als Methode, die keine Schulung erfordert, Beschleunigung für jedes zukünftige DiT-basierte Videogenerierungsmodell bieten kann und ihm die Möglichkeit gibt, Echtzeitvideos zu generieren.
Seit diesem Jahr haben OpenAIs Sora und andere DiT-basierte Videogenerierungsmodelle eine weitere Welle im Bereich KI ausgelöst. Im Vergleich zur Bildgenerierung liegt der Schwerpunkt bei der Videogenerierung jedoch im Wesentlichen auf der Qualität, und nur wenige Studien konzentrieren sich auf die Untersuchung, wie die DiT-Modellinferenz beschleunigt werden kann. Die Beschleunigung der Inferenz von generativen Videomodellen hat für generative KI-Anwendungen bereits Priorität.
Die Entstehung der PAB-Methode hat uns einen Weg geebnet. Vergleich der ursprünglichen Methode und der Geschwindigkeit der PAB-Videoerzeugung. Der Autor hat 5 Videos mit einer Auflösung von 480p und 4 Sekunden (192 Bildern) auf Open-Sora getestet. 
Pyramid Attention Broadcast
In letzter Zeit haben Sora und andere DiT-basierte Videogenerierungsmodelle große Aufmerksamkeit erregt. Im Vergleich zur Bildgenerierung haben sich jedoch nur wenige Studien auf die Beschleunigung der Schlussfolgerung von DiT-basierten Videogenerierungsmodellen konzentriert. Darüber hinaus können die Inferenzkosten für die Erstellung eines einzelnen Videos hoch sein.散 Abbildung 1: Unterschiede zwischen den aktuellen Diffusionsschritten und den vorherigen Diffusionsschritten sowie der Differentialfehler (MSE) werden quantifiziert.Implementierung
Diese Studie enthüllt zwei wichtige Beobachtungen des Aufmerksamkeitsmechanismus im Videodiffusionstransformator: Erstens zeigt der Unterschied in der Aufmerksamkeit bei verschiedenen Zeitschritten ein U-förmiges Muster, bei den ersten und letzten 15 Der Prozentsatz der Schritte ändert sich erheblich, während die mittleren 70 % der Schritte mit kleinen Unterschieden sehr stabil sind.
Erstens zeigt der Unterschied in der Aufmerksamkeit bei verschiedenen Zeitschritten ein U-förmiges Muster, bei den ersten und letzten 15 Der Prozentsatz der Schritte ändert sich erheblich, während die mittleren 70 % der Schritte mit kleinen Unterschieden sehr stabil sind.
Zweitens gibt es innerhalb des stabilen Mittelsegments Unterschiede zwischen den Aufmerksamkeitstypen: Die räumliche Aufmerksamkeit verändert sich am stärksten und betrifft hochfrequente Elemente wie Kanten und Texturen. Die zeitliche Aufmerksamkeit zeigt mittelfrequente Veränderungen im Zusammenhang mit Bewegung und Dynamik im Video. Am stabilsten ist die modalübergreifende Aufmerksamkeit, die Text mit Videoinhalten verbindet, ähnlich wie niederfrequente Signale, die die Textsemantik widerspiegeln. Auf dieser Grundlage schlug das Forschungsteam eine Pyramiden-Aufmerksamkeitsübertragung vor, um unnötige Aufmerksamkeitsberechnungen zu reduzieren. Im mittleren Teil zeigt die Aufmerksamkeit kleine Unterschiede, und die Studie überträgt die Aufmerksamkeitsleistung eines Diffusionsschritts auf mehrere nachfolgende Schritte, wodurch der Rechenaufwand erheblich reduziert wird. Für eine effizientere Berechnung und minimalen Qualitätsverlust legt der Autor außerdem unterschiedliche Sendebereiche entsprechend der Stabilität und dem Unterschied verschiedener Aufmerksamkeiten fest. Auch ohne Nachschulung erreicht diese einfache, aber effektive Strategie Geschwindigkeitssteigerungen von bis zu 35 % bei vernachlässigbarem Qualitätsverlust der generierten Inhalte.
Abbildung 2: Diese Studie schlägt eine Pyramiden-Aufmerksamkeitsübertragung vor, bei der basierend auf Aufmerksamkeitsunterschieden unterschiedliche Übertragungsbereiche für drei Aufmerksamkeiten festgelegt werden. Je geringer die Änderung der Aufmerksamkeit ist, desto größer ist die Reichweite. Zur Laufzeit sendet die Methode die Aufmerksamkeitsergebnisse an die nächsten Schritte, um redundante Aufmerksamkeitsberechnungen zu vermeiden. x_t bezieht sich auf die Features zum Zeitpunkt t.
Parallel
Abbildung 3 unten zeigt den Vergleich zwischen der Methode in diesem Artikel und der ursprünglichen Dynamic Sequence Parallel (DSP). Wenn zeitliche Aufmerksamkeit verteilt wird, kann jegliche Kommunikation vermieden werden.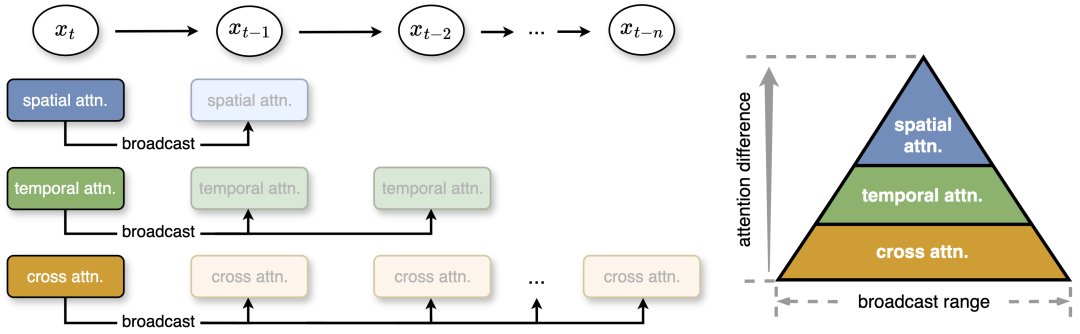
Um die Geschwindigkeit der Videogenerierung weiter zu verbessern, verwendet dieser Artikel DSP, um die Sequenzparallelität zu verbessern. Sequence Parallel teilt das Video in verschiedene Teile auf mehreren GPUs auf, wodurch die Arbeitslast auf jeder GPU reduziert und die Build-Latenz verringert wird. DSP führt jedoch zu einem hohen Kommunikationsaufwand, der Zeit und Aufmerksamkeit erfordert, um zwei All-to-All-Kommunikationen vorzubereiten.
Durch die Verbreitung der zeitlichen Aufmerksamkeit in PAB muss in diesem Artikel die zeitliche Aufmerksamkeit nicht mehr berechnet werden, wodurch die Kommunikation reduziert wird. Dementsprechend wird der Kommunikationsaufwand deutlich um mehr als 50 % reduziert, was eine effizientere verteilte Inferenz für die Echtzeit-Videogenerierung ermöglicht.
Bewertungsergebnisse
Beschleunigung
Die folgende Abbildung zeigt die gesamte PAB-Latenz, die von verschiedenen Modellen gemessen wurde, wenn ein einzelnes Video auf 8 NVIDIA H100-GPUs generiert wurde. Bei Verwendung einer einzelnen GPU erreichten die Autoren eine Beschleunigung um das 1,26- bis 1,32-fache und blieben über verschiedene Scheduler hinweg stabil.
Bei der Erweiterung auf mehrere GPUs erreichte diese Methode eine 10,6-fache Beschleunigung und profitierte von effizienten sequentiellen Parallelitätsverbesserungen, um eine nahezu lineare Erweiterung mit der Anzahl der GPUs zu erreichen.

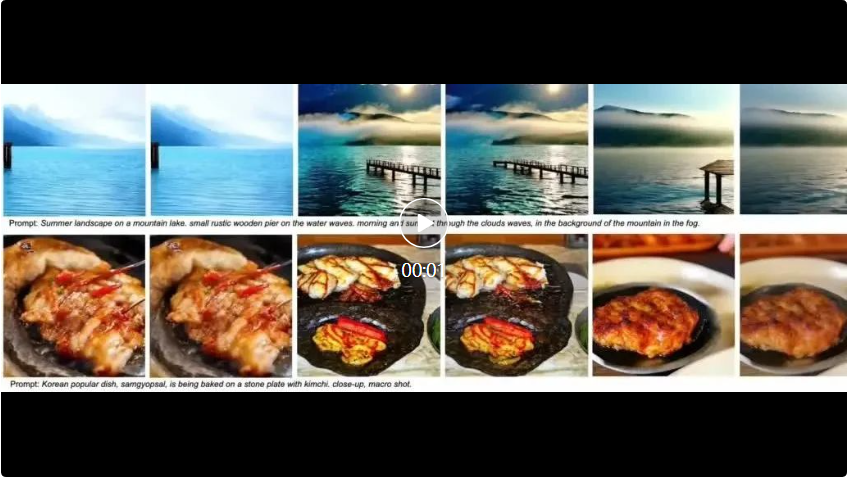
Qualitative Ergebnisse
Die folgenden drei Videos sind jeweils Open-Sora, Open-Sora-Plan und Latte. Drei verschiedene Modelle verwenden die Originalmethode, um die Auswirkungen der Methode in diesem Artikel zu vergleichen. Es ist ersichtlich, dass die Methode in diesem Artikel bei unterschiedlicher Anzahl von GPUs unterschiedliche Grade der FPS-Beschleunigung erreicht. 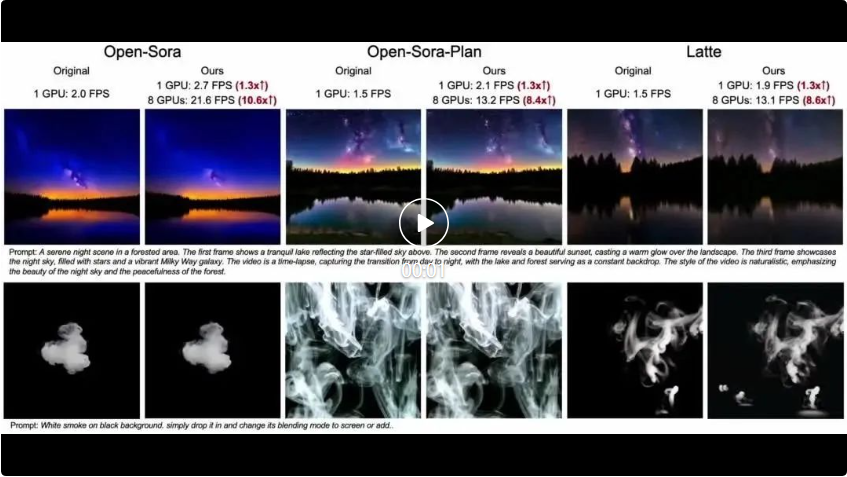

Quantitative Ergebnisse
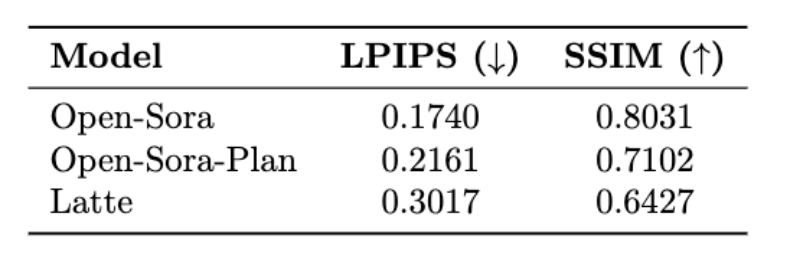
Die folgende Tabelle zeigt die LPIPS (Learning Perceptual Image Patch Similarity) und SSIM (Structural Similarity) der drei Modelle von Open-Sora, Open-Sora-Plan und Latte ) Indikatorergebnisse.
Weitere technische Details und Auswertungsergebnisse finden Sie im kommenden Paper.
Projektadresse: https://oahzxl.github.io/PAB/
Referenzlink:
https://oahzxl.github.io/PAB/
Das obige ist der detaillierte Inhalt vonDie erste Echtzeit-KI-Videogenerierungstechnologie der Geschichte: DiT universell, 10,6-mal schneller. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So lösen Sie das Problem, dass der DNS-Server nicht reagiert
So lösen Sie das Problem, dass der DNS-Server nicht reagiert
 Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
 Webservice-Aufruf
Webservice-Aufruf
 So erstellen Sie einen Bitmap-Index in MySQL
So erstellen Sie einen Bitmap-Index in MySQL
 Was führt dazu, dass der Computerbildschirm gelb wird?
Was führt dazu, dass der Computerbildschirm gelb wird?
 Einführung in Crawler-Tools
Einführung in Crawler-Tools
 Gründe, warum der Zugriff auf eine Website zu einem internen Serverfehler führt
Gründe, warum der Zugriff auf eine Website zu einem internen Serverfehler führt
 Was ist der Unterschied zwischen Legacy und UEFI?
Was ist der Unterschied zwischen Legacy und UEFI?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



