Gemma 2 mit doppelter Leistung, wie spielt man Llama 3 mit dem gleichen Level?
Auf der KI-Strecke konkurrieren Technologiegiganten hart. Der GPT-4o erschien am Vorderfuß und der Claude 3.5 Sonnet am Hinterfuß. Obwohl Google seine Bemühungen in einem so erbitterten Kampf erst spät startete, verfügt es über eine erhebliche Fähigkeit, in kurzer Zeit nachzufolgen, was sein Potenzial für technologische Entwicklung und Innovation zeigt. Neben dem Gemini-Modell scheint Gemma, eine Reihe leichter SOTA-Open-Modelle, näher bei uns zu sein. Es basiert auf der gleichen Forschung und Technologie wie das Gemini-Modell und zielt darauf ab, jedem die Werkzeuge zum Aufbau von KI an die Hand zu geben. Google erweitert die Gemma-Familie weiterhin um CodeGemma, RecurrentGemma und PaliGemma – jedes Modell bietet einzigartige Funktionen für verschiedene KI-Aufgaben und ist über Partner wie Hugging Face, NVIDIA und Ollama leicht zugänglich. 
Jetzt heißt die Gemma-Familie ein neues Mitglied willkommen – Gemma 2, und setzt damit die Tradition fort, kurz und prägnant zu sein. Die beiden von Gemma 2 bereitgestellten Versionen der 9 Milliarden (9B) und 27 Milliarden (27B) Parameter weisen diesmal eine bessere Inferenzleistung und Effizienz als die erste Generation auf und weisen erhebliche Sicherheitsverbesserungen auf. Tatsächlich kann die 27-Milliarden-Parameter-Version auf dem gleichen Niveau mit Modellen konkurrieren, die mehr als doppelt so groß sind und eine Leistung bieten, die bisher nur von proprietären Modellen erreicht wurde, die jetzt auf einer einzelnen NVIDIA H100 Tensor Core GPU oder TPU implementiert werden kann Host, wodurch die Bereitstellungskosten erheblich gesenkt werden.
Das Google-Team baute Gemma 2 auf einer neu gestalteten Architektur auf, sodass dieses neue Mitglied der Gemma-Familie sowohl hervorragende Leistung als auch effiziente Inferenzfunktionen bieten kann. Um es kurz zusammenzufassen: Leistung, Kosten und Schlussfolgerung sind seine herausragenden Merkmale:
- Ausgezeichnete Leistung: Das Modell Gemma 2 27B bietet die beste Leistung in seiner Volumenkategorie und konkurriert sogar mit Modellen, die mehr als doppelt so groß sind wie die Modellkonkurrenz. Auch das Modell 9B Gemma 2 schnitt in seiner Größenklasse gut ab und übertraf das Llama 3 8B und andere vergleichbare offene Modelle.
- Hohe Effizienz, niedrige Kosten: Das 27B Gemma 2-Modell ist darauf ausgelegt, Inferenz effizient und mit voller Präzision auf einem einzelnen Google Cloud TPU-Host, einer NVIDIA A100 80 GB Tensor Core GPU oder einer NVIDIA H100 Tensor Core GPU auszuführen und dabei eine hohe Leistung aufrechtzuerhalten Reduzieren Sie die Kosten drastisch. Dies macht die KI-Bereitstellung bequemer und erschwinglicher.
- Ultraschnelle Inferenz: Gemma 2 ist für die Ausführung mit rasender Geschwindigkeit auf einer Vielzahl von Hardware optimiert, egal ob es sich um einen leistungsstarken Gaming-Laptop, einen High-End-Desktop oder ein cloudbasiertes Setup handelt. Benutzer können versuchen, Gemma 2 mit voller Präzision auf Google AI Studio auszuführen oder eine quantisierte Version von Gemma.cpp auf der CPU zu verwenden, um die lokale Leistung freizuschalten, oder es auf einem Heimcomputer mit NVIDIA RTX oder GeForce RTX über Hugging Face Transformers ausprobieren.
Das Obige ist der Score-Datenvergleich zwischen Gemma2, Llama3 und Grok-1.
Tatsächlich sind die Vorteile des Open-Source-9B-Großmodells anhand verschiedener Bewertungsdaten nicht besonders offensichtlich. Das große inländische Modell GLM-4-9B, das vor fast einem Monat von Zhipu AI als Open Source bereitgestellt wurde, bietet noch mehr Vorteile.
Darüber hinaus ist Gemma 2 nicht nur leistungsfähiger, sondern auch einfacher in Arbeitsabläufe integrierbar. Google bietet Entwicklern mehr Möglichkeiten, KI-Lösungen einfacher zu erstellen und bereitzustellen.
- Offen und zugänglich: Wie das ursprüngliche Gemma-Modell ermöglicht Gemma 2 Entwicklern und Forschern, Innovationen zu teilen und zu kommerzialisieren.
- Umfassende Framework-Kompatibilität: Gemma 2 ist mit den wichtigsten KI-Frameworks wie Hugging Face Transformers sowie JAX, PyTorch und TensorFlow kompatibel, die nativ durch Keras 3.0, vLLM, Gemma.cpp, Llama.cpp und Ollama unterstützt werden Einfache Integration in vom Benutzer bevorzugte Tools und Arbeitsabläufe. Darüber hinaus wurde Gemma mit NVIDIA TensorRT-LLM optimiert und kann auf einer beschleunigten NVIDIA-Infrastruktur oder als NVIDIA NIM-Inferenz-Microservice ausgeführt werden. Es wird in Zukunft auch für NVIDIAs NeMo optimiert und kann mithilfe von Keras und Hugging Face optimiert werden. Darüber hinaus verbessert Google aktiv die Feinabstimmungsfunktionen.
- Einfache Bereitstellung: Ab nächsten Monat können Google Cloud-Kunden Gemma 2 problemlos auf Vertex AI bereitstellen und verwalten.
Google bietet außerdem ein neues Gemma-Kochbuch an, eine Reihe praktischer Beispiele und Anleitungen, die Benutzern dabei helfen sollen, ihre eigenen Anwendungen zu erstellen und Gemma-2-Modelle für bestimmte Aufgaben zu optimieren. Link zum Gemma-Kochbuch: https://github.com/google-gemini/gemma-cookbookGleichzeitig stellte Google den Entwicklern auch das auf der I/O-Konferenz angekündigte offizielle Produkt zur Verfügung Der 2-Millionen-Kontextfensterzugriff von Gemini 1.5 Pro, die Codeausführungsfunktionen für die Gemini-API und die Hinzufügung von Gemma 2 in Google AI Studio.
- Im neuesten Blog gab Google bekannt, dass es den 2-Millionen-Token-Kontextfensterzugriff von Gemini 1.5 Pro für alle Entwickler geöffnet hat. Mit zunehmendem Kontextfenster können jedoch auch die Eingabekosten steigen. Um Entwicklern dabei zu helfen, die Kosten für mehrere Eingabeaufforderungsaufgaben mit demselben Token zu senken, hat Google die Kontext-Caching-Funktion in der Gemini-API für Gemini 1.5 Pro und 1.5 Flash mit Bedacht eingeführt.
- Um das Problem zu lösen, dass große Sprachmodelle Code generieren und ausführen müssen, um die Genauigkeit bei der Verarbeitung von Mathematik oder Datenbegründung zu verbessern, hat Google die Codeausführung in Gemini 1.5 Pro und 1.5 Flash aktiviert. Wenn es aktiviert ist, kann das Modell Python-Code dynamisch generieren und ausführen und iterativ aus den Ergebnissen lernen, bis die gewünschte Endausgabe erreicht ist. Die Ausführungs-Sandbox stellt keine Verbindung zum Internet her und wird standardmäßig mit einigen numerischen Bibliotheken geliefert. Entwickler müssen nur auf der Grundlage des Ausgabe-Tokens des Modells abgerechnet werden. Dies ist das erste Mal, dass Google einen Codeausführungsschritt in die Modellfunktion einführt, die heute über die Gemini-API und die erweiterten Einstellungen in Google AI Studio verfügbar ist.
- Google möchte KI allen Entwicklern zugänglich machen, unabhängig davon, ob sie Gemini-Modelle über API-Schlüssel integrieren oder das offene Modell Gemma 2 verwenden. Um Entwicklern zu helfen, das Gemma-2-Modell in die Hände zu bekommen, stellt das Google-Team es zum Experimentieren in Google AI Studio zur Verfügung.
Das Folgende ist der technische Experimentbericht von Gemma2. Wir können die technischen Details aus mehreren Blickwinkeln eingehend analysieren.
- Papieradresse: https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf
- Blogadresse: https://blog.google/ technology/developers/google-gemma-2/
Ähnlich wie das vorherige Gemma-Modell basiert auch das Gemma 2-Modell auf einer Nur-Decoder-Transformatorarchitektur. Tabelle 1 fasst die Hauptparameter und Architekturoptionen des Modells zusammen. Einige Strukturelemente ähneln der ersten Version des Gemma-Modells, nämlich die Kontextlänge beträgt 8192 Token, die Verwendung von Rotated Position Embedding (RoPE) und die ungefähre GeGLU-Nichtlinearität. Gemma 1 und Gemma 2 weisen einige Unterschiede auf, einschließlich der Verwendung tieferer Netzwerke. Die Hauptunterschiede lassen sich wie folgt zusammenfassen:
- Lokales Schiebefenster und globale Aufmerksamkeit. Das Forschungsteam nutzte in jeder zweiten Schicht abwechselnd die Aufmerksamkeit des lokalen Schiebefensters und die Aufmerksamkeit des globalen Fensters. Die Größe des Schiebefensters der lokalen Aufmerksamkeitsschicht ist auf 4096 Token festgelegt, während die Spanne der globalen Aufmerksamkeitsschicht auf 8192 Token festgelegt ist.
- Logit-Softkappe. Gemäß der Methode von Gemini 1.5 beschränkte das Forschungsteam Logit auf jeder Aufmerksamkeitsebene und der letzten Ebene, sodass der Wert von Logit zwischen −soft_cap und +soft_cap blieb.
- Für die Modelle 9B und 27B legte das Forschungsteam die logarithmische Obergrenze der Aufmerksamkeit auf 50,0 und die endgültige logarithmische Obergrenze auf 30,0 fest. Zum Zeitpunkt der Veröffentlichung ist das Soft-Capping von Attention Logit nicht mit gängigen FlashAttention-Implementierungen kompatibel. Daher wurde diese Funktion aus Bibliotheken entfernt, die FlashAttention verwenden. Das Forschungsteam führte Ablationsexperimente zur Modellgenerierung mit und ohne Attention-Logit-Soft-Capping durch und stellte fest, dass die Generierungsqualität in den meisten Pre-Training- und Post-Evaluierungen nahezu unbeeinflusst blieb. Alle Auswertungen in diesem Dokument verwenden die vollständige Modellarchitektur einschließlich der Soft-Capping-Funktion von Attention Logit. Die Leistung einiger Downstream-Geräte kann durch diese Entfernung jedoch immer noch geringfügig beeinträchtigt werden.
- Verwenden Sie RMSNorm für Postnorm und Vornorm. Um das Training zu stabilisieren, verwendete das Forschungsteam RMSNorm, um die Eingabe und Ausgabe jeder Transformationsunterschicht, Aufmerksamkeitsschicht und Feed-Forward-Schicht zu normalisieren.
- Aufmerksamkeit in Gruppen abfragen. Sowohl das 27B- als auch das 9B-Modell verwenden GQA, num_groups = 2, und ablationsbasierte Experimente zeigen eine verbesserte Inferenzgeschwindigkeit bei gleichzeitiger Beibehaltung der Downstream-Leistung.
Google bietet einen kurzen Überblick über den Vortrainingsteil, der sich von Gemma 1 unterscheidet. Sie trainierten Gemma 2 27B mit 13 Billionen Token, hauptsächlich englischen Daten, trainierten das 9B-Modell mit 8 Billionen Token und trainierten das 2,6B-Modell mit 2 Billionen Token. Diese Token stammen aus verschiedenen Datenquellen, darunter Webdokumente, Code und wissenschaftliche Artikel. Das Modell ist weder multimodal, noch ist es speziell für mehrsprachige Fähigkeiten auf dem neuesten Stand der Technik trainiert. Der endgültige Datenmix wird durch eine Ablationsstudie ähnlich Gemini 1.0 bestimmt. Das Forschungsteam verwendet TPUv4, TPUv5e und TPUv5p für das Modelltraining. Die Details sind in Tabelle 3 unten aufgeführt. Nach dem Training optimiert Google das vorab trainierte Modell in ein an Anweisungen abgestimmtes Modell.
- Wenden Sie zunächst die überwachte Feinabstimmung (SFT) auf eine Mischung aus Klartext, reiner englischer Synthese und künstlich generierten Prompt-Response-Paaren an.
- Dann wird auf diesen Modellen Verstärkungslernen basierend auf dem Belohnungsmodell (RLHF) angewendet. Das Belohnungsmodell wird auf tokenbasierten, rein englischen Präferenzdaten trainiert, und die Strategie verwendet dieselbe Eingabeaufforderung wie die SFT-Stufe.
- Verbessern Sie abschließend die Gesamtleistung, indem Sie die in jeder Phase erhaltenen Modelle mitteln. Die endgültigen Datenmischungs- und Post-Training-Methoden, einschließlich abgestimmter Hyperparameter, werden auf der Grundlage der Minimierung von Modellrisiken im Zusammenhang mit Sicherheit und Halluzinationen bei gleichzeitiger Erhöhung des Modellnutzens ausgewählt.
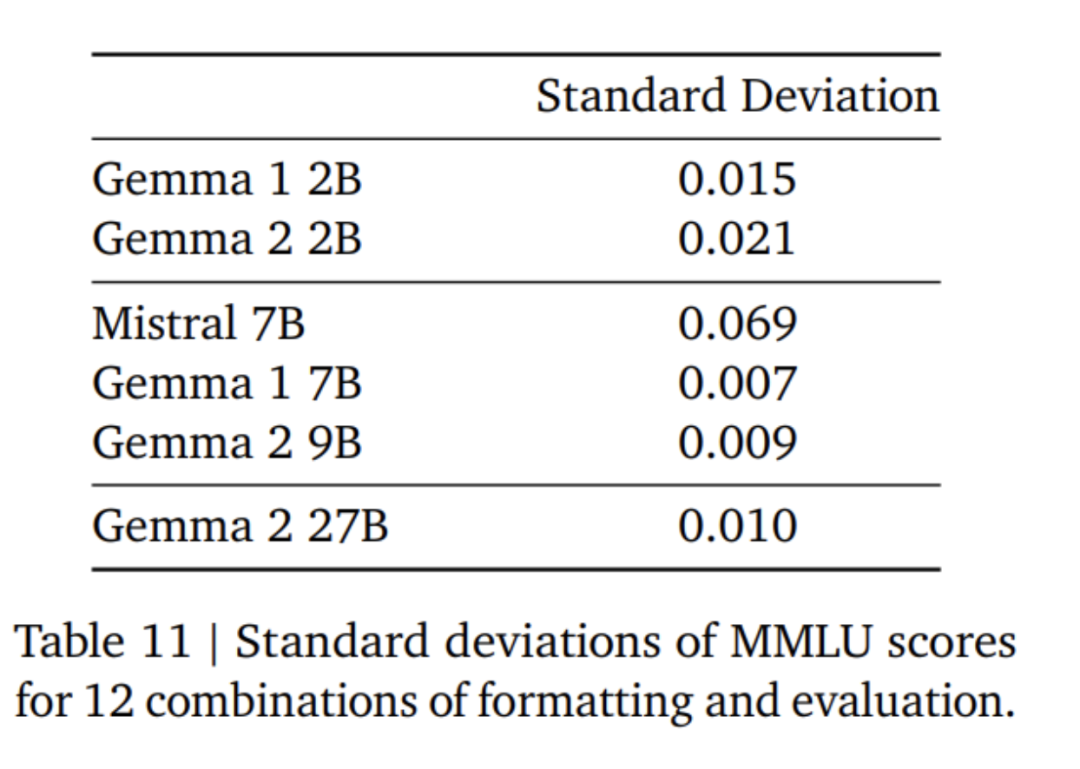
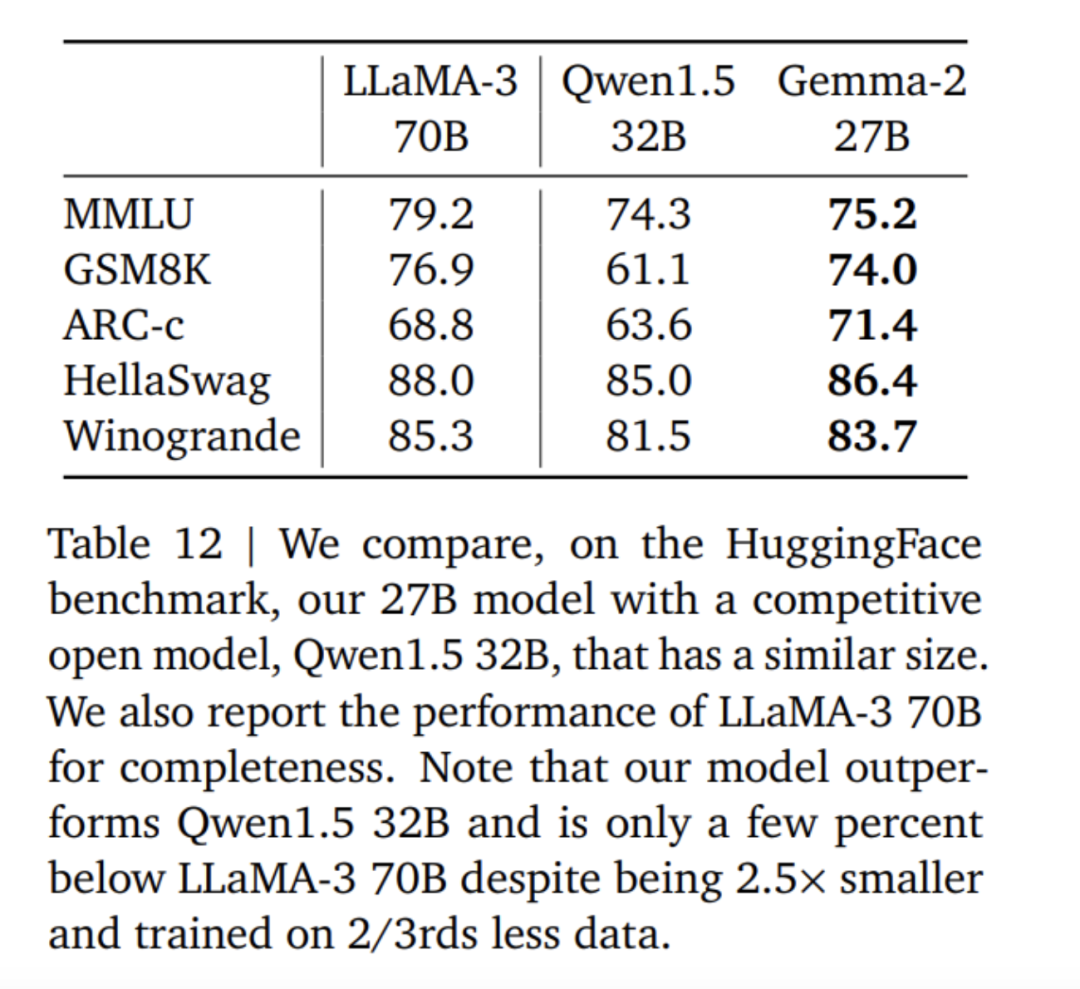
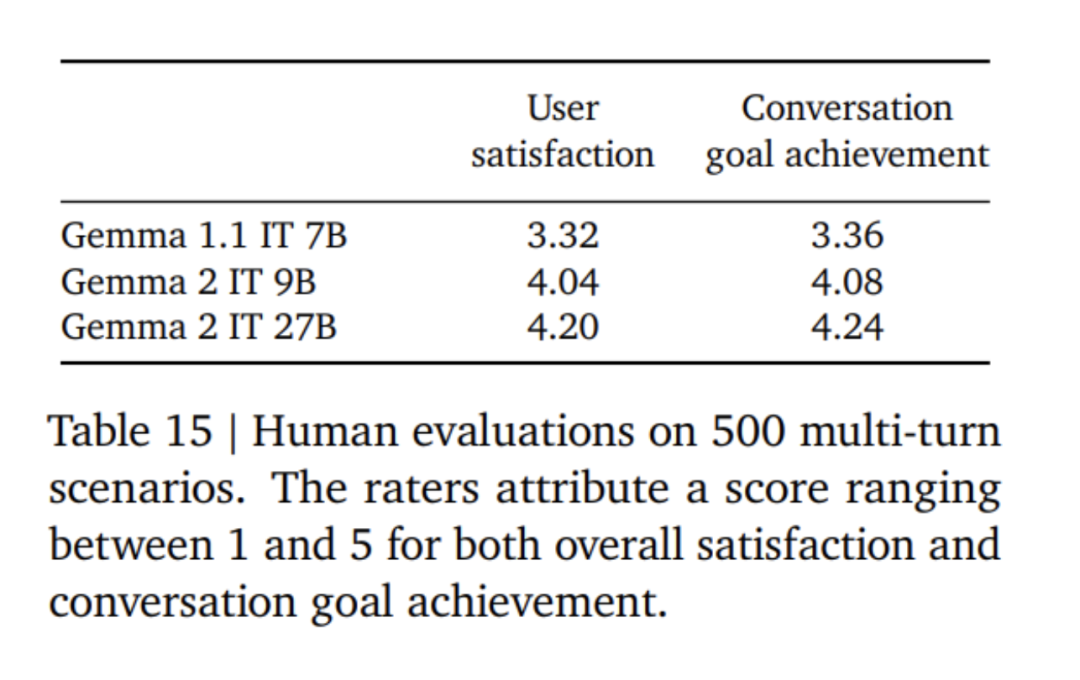
Die Feinabstimmung des Gemma 2-Modells verwendet einen anderen Formatmodus als das Gemma 1-Modell. Google verwendet dasselbe Kontrolltoken wie in Tabelle 4 beschrieben, und eine Beispielkonversation finden Sie in Tabelle 5. Experimente und AuswertungIn Tabelle 6 lässt sich feststellen, dass die Verfeinerung der Ergebnisse eines größeren Modells die Leistung im Vergleich zum Training von Grund auf verbessert. Es ist zu beachten, dass 500 B-Tokens das Zehnfache der optimalen Anzahl berechneter Token für das 2,6 B-Modell sind. Das Forschungsteam führte eine Destillation vom 7B-Modell durch, um ein ähnliches Verhältnis wie bei der Destillation vom 27B-Modell zum 9B-Modell beizubehalten. In Tabelle 7 misst das Google-Team die Auswirkung der Destillation mit zunehmender Modellgröße. Es ist zu beobachten, dass dieser Gewinn mit zunehmender Modellgröße bestehen bleibt. In diesem Ablationsexperiment behielt das Forschungsteam die Größe des Lehrermodells bei 7B und trainierte kleinere Modelle, um die Lücke zwischen der endgültigen Größe des Lehrer- und Schülermodells zu simulieren. Darüber hinaus berücksichtigte Google die Auswirkungen von Änderungen des Eingabeaufforderungs-/Bewertungsformats und maß die Leistungsvarianz auf MMLU, wie in Tabelle 11 dargestellt. Das Gemma 2B-Modell ist größeren Modellen in puncto Formatrobustheit etwas unterlegen. Bemerkenswert ist, dass der Mistral 7B hinsichtlich der Robustheit deutlich hinter den Modellen der Gemma-Serie zurückbleibt. Das Forschungsteam bewertete auch die Leistung des 27B-Modells, das auf 13 Billionen Token (ohne Destillation) trainiert wurde, und verglich es mit dem ähnlich großen Qwen1.5 34B-Modell und dem 2,5-mal größeren LLaMA-3 70B. Die Leistung Die Modelle der HuggingFace-Evaluierungssuite wurden verglichen und die Evaluierungsergebnisse sind in Tabelle 12 aufgeführt. Die Models wurden anhand ihres Rankings auf der HuggingFace-Bestenliste ausgewählt. Insgesamt schneidet das Modell Gemma-2 27B in seiner Größenklasse am besten ab und kann sogar mit größeren Modellen mithalten, deren Training länger dauert. Die Gemma-2 27B- und 9B-Befehlsfeinabstimmungsmodelle wurden in der Chatbot Arena von menschlichen Bewertern blind im Vergleich zu anderen SOTA-Modellen bewertet. Das Forschungsteam gibt die ELO-Werte in Abbildung 1 an. Darüber hinaus bewertete das Forschungsteam die Multi-Turn-Dialogfähigkeiten der Modelle Gemma 1.1 7B, Gemma 2 9B und 27B, indem es menschliche Bewerter mit den Modellen sprechen ließ und bestimmte Szenarien zum Testen befolgte. Google verwendet einen vielfältigen Bestand von 500 Szenarien, die jeweils eine Reihe von Anforderungen an das Modell beschreiben, darunter Brainstorming, Planerstellung oder das Erlernen von etwas Neuem. Die durchschnittliche Anzahl der Benutzerinteraktionen beträgt 8,4. Schließlich wurde festgestellt, dass die Benutzer im Vergleich zu Gemma 1.1 die Dialogzufriedenheit und die Dialogzielerreichungsrate des Gemma 2-Modells als deutlich höher bewerteten (siehe Tabelle 15). Darüber hinaus ist das Gemma 2-Modell besser in der Lage, qualitativ hochwertige Antworten vom Beginn des Gesprächs bis zu den folgenden Runden aufrechtzuerhalten als das Gemma 1.1 7B-Modell. Für weitere Einzelheiten lesen Sie bitte das Originalpapier. Das obige ist der detaillierte Inhalt vonGoogles „aufrichtige Arbeit', Open-Source-9B- und 27B-Versionen von Gemma2, mit Schwerpunkt auf Effizienz und Wirtschaftlichkeit!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!














 So öffnen Sie die Win11-Systemsteuerung
So öffnen Sie die Win11-Systemsteuerung
 Der Unterschied zwischen Pascal-Sprache und C-Sprache
Der Unterschied zwischen Pascal-Sprache und C-Sprache
 Fil-Währungspreis Echtzeitpreis
Fil-Währungspreis Echtzeitpreis
 Mehrere Möglichkeiten zur Datenerfassung
Mehrere Möglichkeiten zur Datenerfassung
 Verwendung von Versprechen
Verwendung von Versprechen
 Welche virtuellen Währungen könnten im Jahr 2024 stark ansteigen?
Welche virtuellen Währungen könnten im Jahr 2024 stark ansteigen?
 Der Unterschied zwischen MS Office und WPS Office
Der Unterschied zwischen MS Office und WPS Office
 Was ist Python-Programmierung?
Was ist Python-Programmierung?
 Handelsplattform für virtuelle Währungen
Handelsplattform für virtuelle Währungen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



