Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail zur Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Shuai Xincheng, der erste Autor dieses Artikels, studiert derzeit im FVL-Labor der Fudan-Universität und schloss sein Studium an der Shanghai Jiao Tong University mit ab Bachelortitel. Zu seinen Forschungsschwerpunkten gehören Bild- und Videobearbeitung sowie multimodales Lernen.
Dieser Artikel schlägt einen einheitlichen Rahmen zur Lösung allgemeiner Bearbeitungsaufgaben vor! Kürzlich haben Forscher des FVL-Labors der Fudan-Universität und der Nanyang Technological University multimodale geführte Bildbearbeitungsalgorithmen zusammengefasst und überprüft, die auf großen Modellen mit vinzentinischen Graphen basieren. Die Überprüfung umfasst mehr als 300 relevante Studien, und das neueste untersuchte Modell stammt vom Juni dieses Jahres! Diese Rezension erweitert die Diskussion von Kontrollbedingungen (natürliche Sprache, Bilder, Benutzeroberflächen) und Bearbeitungsaufgaben (Objekt-/Attributmanipulation, räumliche Transformation, Inpainting, Stilübertragung, Bildübersetzung, Subjekt-/Attributanpassung) auf eine neuartigere und umfassendere Diskussion von Bearbeitungsmethoden aus einer allgemeineren Perspektive. Darüber hinaus schlägt dieser Aufsatz ein einheitliches Framework vor, das den Bearbeitungsprozess als Kombination verschiedener Algorithmenfamilien darstellt und die Merkmale verschiedener Kombinationen sowie Anpassungsszenarien durch umfassende qualitative und quantitative Experimente veranschaulicht. Das Framework bietet einen benutzerfreundlichen Designraum, um den unterschiedlichen Bedürfnissen der Benutzer gerecht zu werden, und bietet Forschern eine gewisse Referenz für die Entwicklung neuer Algorithmen. Die Bildbearbeitung dient dazu, ein bestimmtes synthetisches oder reales Bild gemäß den spezifischen Anforderungen des Benutzers zu bearbeiten. Als vielversprechender und herausfordernder Bereich im Bereich der durch künstliche Intelligenz generierten Inhalte (AIGC) wurde die Bildbearbeitung eingehend untersucht. In jüngster Zeit hat das groß angelegte Bild-zu-Infrarot-Diffusionsmodell (T2I) die Entwicklung der Bildbearbeitungstechnologie vorangetrieben. Diese Modelle generieren Bilder auf der Grundlage von Textaufforderungen, demonstrieren erstaunliche generative Fähigkeiten und werden zu einem gängigen Werkzeug für die Bildbearbeitung. Die T2I-basierte Bildbearbeitungsmethode verbessert die Bearbeitungsleistung erheblich und bietet Benutzern eine Schnittstelle zur Inhaltsänderung mithilfe multimodaler Bedingungsführung. Wir bieten einen umfassenden Überblick über multimodal geführte Bildbearbeitungstechniken basierend auf T2I-Diffusionsmodellen. Zunächst definieren wir den Umfang der Bildbearbeitungsaufgaben aus einer allgemeineren Perspektive und beschreiben verschiedene Steuersignale und Bearbeitungsszenarien im Detail. Anschließend schlagen wir ein einheitliches Framework zur Formalisierung des Bearbeitungsprozesses vor und stellen ihn als Kombination zweier Algorithmusfamilien dar. Dieses Framework bietet Benutzern einen Gestaltungsraum, um bestimmte Ziele zu erreichen. Als nächstes führten wir eine eingehende Analyse jeder Komponente innerhalb des Frameworks durch und untersuchten die Eigenschaften und anwendbaren Szenarien verschiedener Kombinationen. Da schulungsbasierte Methoden direkt lernen, Quellbilder Zielbildern zuzuordnen, diskutieren wir diese Methoden separat und stellen Quellbild-Injektionsschemata in verschiedenen Szenarien vor. Darüber hinaus untersuchen wir die Anwendung von 2D-Techniken bei der Videobearbeitung und konzentrieren uns dabei auf die Lösung von Inkonsistenzen zwischen Bildern. Abschließend diskutieren wir auch offene Herausforderungen auf diesem Gebiet und schlagen mögliche zukünftige Forschungsrichtungen vor. 
- Papiertitel: A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
- Publikationseinheit: Fudan University FVL Laboratory, Nanyang Technological University
- Papieradresse: https://arxiv . org/abs/2406.14555
- Projektadresse: https://github.com/xinchengshuai/Awesome-Image-Editing
1.1 Im wirklichen Leben besteht ein zunehmender Bedarf an kontrollierbaren, hochwertigen intelligenten Bildbearbeitungswerkzeugen. Daher ist es notwendig, die Methoden und technischen Eigenschaften in dieser Richtung systematisch zusammenzufassen und zu vergleichen. 1.2, die aktuellen Bearbeitungsalgorithmen und zugehörigen Überprüfungen beschränken das Bearbeitungsszenario auf die Beibehaltung der meisten semantischen Informationen auf niedriger Ebene im Bild, die nicht mit der Bearbeitung zusammenhängen. Aus diesem Grund ist es notwendig, den Umfang der Bearbeitungsaufgabe zu erweitern und diskutieren Sie die Bearbeitung aus einer allgemeineren Perspektive. 1.3 Aufgrund der Vielfalt der Bedürfnisse und Szenarien ist es notwendig, den Bearbeitungsprozess in einem einheitlichen Rahmen zu formalisieren und den Benutzern einen Gestaltungsraum zur Anpassung an unterschiedliche Bearbeitungsziele zu bieten. 2. Wie unterscheiden sich die Rezensions-Highlights von der aktuellen redaktionellen Rezension? 2.1 Die Definition und der Umfang der Diskussion über Bearbeitungsaufgaben. Im Vergleich zu vorhandenen Algorithmen und früheren Bearbeitungsüberprüfungen definiert dieser Artikel die Bildbearbeitungsaufgabe umfassender. Konkret unterteilt dieser Artikel Bearbeitungsaufgaben in inhaltsbewusste und inhaltsfreie Szenengruppen. Die Szenen in der inhaltsbewussten Gruppe sind die Hauptaufgaben, die in der vorherigen Literatur diskutiert wurden. Ihre Gemeinsamkeit besteht darin, einige semantische Merkmale auf niedriger Ebene im Bild beizubehalten, z. B. die Bearbeitung des Pixelinhalts irrelevanter Bereiche oder der Bildstruktur. Darüber hinaus haben wir Pionierarbeit bei der Aufnahme von Anpassungsaufgaben in die inhaltsfreie Szenariogruppe geleistet und dabei diese Art von Aufgabe, die eine Semantik auf hoher Ebene (z. B. Subjektidentitätsinformationen oder andere feinkörnige Attribute) beibehält, als Ergänzung zu regulären Bearbeitungsszenarien verwendet . Auffüllen. V Abbildung 1. Die verschiedenen von Survey diskutierten Bearbeitungsszenen
2.2 Der einheitliche Rahmen allgemeiner Bearbeitungsalgorithmen. Aufgrund der Vielfalt der Bearbeitungsszenarien können bestehende Algorithmen nicht alle Anforderungen gut lösen. Daher formalisieren wir den bestehenden Bearbeitungsprozess in einem einheitlichen Rahmen, ausgedrückt als Kombination zweier Algorithmenfamilien. Darüber hinaus haben wir auch die Eigenschaften und Anpassungsszenarien verschiedener Kombinationen durch qualitative und quantitative Experimente analysiert und den Benutzern einen guten Gestaltungsspielraum für die Anpassung an unterschiedliche Bearbeitungsziele geboten. Gleichzeitig bietet dieses Framework den Forschern auch eine bessere Referenz zum Entwerfen von Algorithmen mit besserer Leistung.
2.3 Umfang der Diskussion. Wir haben mehr als 300 verwandte Artikel recherchiert und die Anwendung verschiedener Arten von Steuersignalen in verschiedenen Szenarien systematisch und umfassend erläutert. Für schulungsbasierte Bearbeitungsmethoden bietet dieser Artikel auch Strategien zum Einfügen von Quellbildern in T2I-Modelle in verschiedenen Szenarien. Darüber hinaus haben wir auch die Anwendung der Bildbearbeitungstechnologie im Videobereich besprochen, damit die Leser den Zusammenhang zwischen Bearbeitungsalgorithmen in verschiedenen Bereichen schnell verstehen können. 3. Ein einheitliches Framework für allgemeine Bearbeitungsalgorithmen
Abbildung 2. Einheitlicher Rahmen allgemeiner Bearbeitungsalgorithmen Rahmenwerk umfasst zwei Algorithmusfamilien, Inversionsalgorithmus und Bearbeitungsalgorithmus. . 3.1 Inversionsalgorithmus. Der Inversionsalgorithmus kodiert den Quellbildsatz in einen bestimmten Merkmals- oder Parameterraum, erhält die entsprechende Darstellung (Inversionshinweis) und verwendet die entsprechende Quelltextbeschreibung als Kennung des Quellbilds. Einschließlich zwei Arten von Inversionsalgorithmen: stimmungsbasiert und vorwärtsbasiert. Es kann wie folgt formalisiert werden: Tuning-basierte InversionDer Quellbildsatz wird durch den ursprünglichen Diffusionstrainingsprozess in die Generationsverteilung des Diffusionsmodells implantiert. Der Formalisierungsprozess ist:
wobei der eingeführte lernbare Parameter ist und . Vorwärtsbasierte Inversion wird verwendet, um das Rauschen in einem bestimmten Vorwärtspfad () im umgekehrten Prozess () des Diffusionsmodells wiederherzustellen. Der Formalisierungsprozess ist:
wobei der in der Methode eingeführte Parameter ist, der zur Minimierung von verwendet wird, wobei . 3.2.Bearbeitungsalgorithmus. Der Bearbeitungsalgorithmus generiert das endgültige Bearbeitungsergebnis basierend auf und dem multimodalen Führungssatz . Bearbeitungsalgorithmen, einschließlich aufmerksamkeitsbasierter, mischungsbasierter, punktebasierter und optimierungsbasierter. Es kann wie folgt formalisiert werden:
Insbesondere führt für jeden Schritt des umgekehrten Prozesses die folgenden Operationen aus:
wobei die Operationen in den Eingriff des Bearbeitungsalgorithmus in die Diffusionsmodellabtastung darstellen Prozess , der verwendet wird, um die Konsistenz des bearbeiteten Bildes mit dem Quellbildsatz sicherzustellen und die visuelle Transformation widerzuspiegeln, die durch die Leitbedingungen in festgelegt ist. Konkret behandeln wir den eingriffsfreien Bearbeitungsprozess als eine normale Version des Bearbeitungsalgorithmus. Es ist formalisiert als:
Der formale Prozess der
Aufmerksamkeitsbasierten Bearbeitung: Der formale Prozess der
Überblendungsbasierte Bearbeitung: Der formale Prozess der
Ergebnisbasierte Bearbeitung:
Optimierungsbasierte Bearbeitung Der Formalisierungsprozess von :
3.3 Trainingsbasierte Bearbeitungsmethode. Im Gegensatz zu trainingsfreien Methoden lernen trainingsbasierte Algorithmen direkt die Zuordnung von Quellbildsätzen zu bearbeiteten Bildern in aufgabenspezifischen Datensätzen. Diese Art von Algorithmus kann als Erweiterung der optimierungsbasierten Inversion angesehen werden, die das Quellbild durch zusätzliche eingeführte Parameter in eine generative Verteilung kodiert. Bei dieser Art von Algorithmus kommt es vor allem darauf an, wie das Quellbild in das T2I-Modell eingefügt wird. Im Folgenden finden Sie Injektionsschemata für verschiedene Bearbeitungsszenarien. Inhaltsorientiertes Aufgabeninjektionsschema: Abbildung 3. Injektionsschema inhaltsfreier Aufgaben
4. Anwendung des einheitlichen Frameworks bei multimodalen Bearbeitungsaufgaben Dieser Artikel veranschaulicht die Anwendung jeder Kombination bei multimodalen Bearbeitungsaufgaben durch qualitative Experimente:
Abbildung 4. Über aufmerksamkeitsbasierte Bearbeitungsanwendung der Algorithmuskombination von Anwendung der AlgorithmuskombinationO Abbildung 6. Anwendung der Algorithmuskombination der punktuellen Bearbeitung Eine detaillierte Analyse finden Sie im Originalpapier.
5. Vergleich verschiedener Kombinationen in textgesteuerten BearbeitungsszenarienFür gängige textgesteuerte Bearbeitungsaufgaben wurden in diesem Artikel mehrere anspruchsvolle qualitative Experimente entworfen, um die für verschiedene Kombinationen geeigneten Bearbeitungsszenarien zu veranschaulichen. Darüber hinaus werden in diesem Artikel auch hochwertige und schwierige Datensätze gesammelt, um die Leistung fortschrittlicher Algorithmen in verschiedenen Kombinationen in verschiedenen Szenarien quantitativ zu veranschaulichen. Für inhaltsbewusste Aufgaben berücksichtigen wir hauptsächlich Objektoperationen (Hinzufügen/Löschen/Ersetzen), Attributänderungen und Stilmigration. Insbesondere berücksichtigen wir anspruchsvolle experimentelle Settings: 1. Multiobjektive Bearbeitung. 2. Anwendungsfälle, die einen größeren Einfluss auf das semantische Layout von Bildern haben. Wir sammeln auch hochwertige Bilder dieser komplexen Szenen und führen einen umfassenden quantitativen Vergleich modernster Algorithmen in verschiedenen Kombinationen durch. Abbildung 8. Der qualitative Vergleich jeder Kombination in der Content-AWARE-Mission. Von links nach rechts werden die Ergebnisse analysiert. Weitere experimentelle Ergebnisse finden Sie in den Originalarbeiten. Bei inhaltsfreien Aufgaben berücksichtigen wir vor allem themenbezogene Individualaufgaben. Und berücksichtigt eine Vielzahl von Szenarien, wie z. B. sich ändernde Hintergründe, die Interaktion mit Objekten, Verhaltensänderungen und Stiländerungen. Wir haben außerdem eine große Anzahl von Textleitfadenvorlagen definiert und eine quantitative Analyse der Gesamtleistung jeder Methode durchgeführt. Zu c Abbildung 9. Der qualitative Vergleich jeder Kombination in der Inhaltsfreie Mission Von links nach rechts werden die Ergebnisse analysiert und weitere experimentelle Ergebnisse finden Sie im Originalpapier. 6. Richtungen, die in Zukunft erforscht werden könnenDarüber hinaus bietet dieser Artikel auch einige Analysen zu zukünftigen Forschungsrichtungen. Als Beispiel nehmen wir hier die Herausforderungen, denen sich inhaltsbewusste Aufgaben und inhaltsfreie Aufgaben gegenübersehen. 6.1. Herausforderungen inhaltsbewusster Aufgaben. Für die Herausforderung inhaltsbewusster Bearbeitungsaufgaben können bestehende Methoden nicht mehrere Bearbeitungsszenarien und Steuersignale gleichzeitig bewältigen. Diese Einschränkung zwingt Anwendungen dazu, geeignete Backend-Algorithmen zwischen verschiedenen Aufgaben zu wechseln. Darüber hinaus sind einige fortgeschrittene Methoden nicht benutzerfreundlich. Bei einigen Methoden muss der Benutzer wichtige Parameter anpassen, um optimale Ergebnisse zu erzielen, während andere mühsame Eingaben wie Quell- und Zielhinweise oder Hilfsmasken erfordern.
6.2. Inhaltsfreie Aufgabenherausforderung. Für inhaltsfreie Bearbeitungsaufgaben erfordern bestehende Methoden beim Testen langwierige Abstimmungsprozesse und leiden unter Überanpassungsproblemen. Einige Studien zielen darauf ab, dieses Problem zu lindern, indem einige wenige Parameter optimiert oder Modelle von Grund auf trainiert werden. Allerdings gehen ihnen oft Details verloren, die das Thema individualisieren, oder sie zeigen eine schlechte Verallgemeinerungsfähigkeit. Darüber hinaus sind aktuelle Methoden auch nicht in der Lage, abstrakte Konzepte aus einer kleinen Anzahl von Bildern zu extrahieren, und sie können die gewünschten Konzepte nicht vollständig von anderen visuellen Elementen trennen.
Um mehr über die Forschungsrichtung zu erfahren, können Sie sich die Originalarbeit ansehen. Das obige ist der detaillierte Inhalt vonMehr als 300 verwandte Studien, die neuesten Übersichtsartikel zur multimodalen Bildbearbeitung der Fudan-Universität und der Nanyang Technological University. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!





 und Bearbeitungsalgorithmus.
und Bearbeitungsalgorithmus. 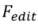 .
. 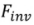 kodiert den Quellbildsatz
kodiert den Quellbildsatz 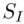 in einen bestimmten Merkmals- oder Parameterraum, erhält die entsprechende Darstellung
in einen bestimmten Merkmals- oder Parameterraum, erhält die entsprechende Darstellung 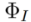 (Inversionshinweis) und verwendet die entsprechende Quelltextbeschreibung
(Inversionshinweis) und verwendet die entsprechende Quelltextbeschreibung 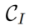 als Kennung des Quellbilds. Einschließlich zwei Arten von Inversionsalgorithmen: stimmungsbasiert
als Kennung des Quellbilds. Einschließlich zwei Arten von Inversionsalgorithmen: stimmungsbasiert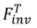 und vorwärtsbasiert
und vorwärtsbasiert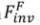 . Es kann wie folgt formalisiert werden:
. Es kann wie folgt formalisiert werden:  Tuning-basierte Inversion
Tuning-basierte Inversion Der Quellbildsatz wird durch den ursprünglichen Diffusionstrainingsprozess in die Generationsverteilung des Diffusionsmodells implantiert. Der Formalisierungsprozess ist:
Der Quellbildsatz wird durch den ursprünglichen Diffusionstrainingsprozess in die Generationsverteilung des Diffusionsmodells implantiert. Der Formalisierungsprozess ist: 
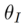 der eingeführte lernbare Parameter ist und
der eingeführte lernbare Parameter ist und 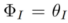 .
. 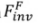 wird verwendet, um das Rauschen in einem bestimmten Vorwärtspfad (
wird verwendet, um das Rauschen in einem bestimmten Vorwärtspfad (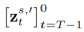 ) im umgekehrten Prozess (
) im umgekehrten Prozess (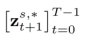 ) des Diffusionsmodells wiederherzustellen. Der Formalisierungsprozess ist:
) des Diffusionsmodells wiederherzustellen. Der Formalisierungsprozess ist: 
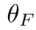 der in der Methode eingeführte Parameter ist, der zur Minimierung von
der in der Methode eingeführte Parameter ist, der zur Minimierung von 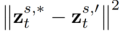 verwendet wird, wobei
verwendet wird, wobei 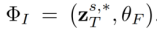 .
. 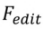 generiert das endgültige Bearbeitungsergebnis
generiert das endgültige Bearbeitungsergebnis 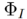 basierend auf
basierend auf 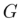 und dem multimodalen Führungssatz
und dem multimodalen Führungssatz 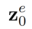 . Bearbeitungsalgorithmen, einschließlich aufmerksamkeitsbasierter
. Bearbeitungsalgorithmen, einschließlich aufmerksamkeitsbasierter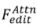 , mischungsbasierter
, mischungsbasierter , punktebasierter
, punktebasierter und optimierungsbasierter
und optimierungsbasierter . Es kann wie folgt formalisiert werden:
. Es kann wie folgt formalisiert werden: 
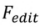 für jeden Schritt des umgekehrten Prozesses die folgenden Operationen aus:
für jeden Schritt des umgekehrten Prozesses die folgenden Operationen aus: 
 den Eingriff des Bearbeitungsalgorithmus in die Diffusionsmodellabtastung darstellen Prozess
den Eingriff des Bearbeitungsalgorithmus in die Diffusionsmodellabtastung darstellen Prozess  , der verwendet wird, um die Konsistenz des bearbeiteten Bildes
, der verwendet wird, um die Konsistenz des bearbeiteten Bildes  mit dem Quellbildsatz
mit dem Quellbildsatz  sicherzustellen und die visuelle Transformation widerzuspiegeln, die durch die Leitbedingungen in
sicherzustellen und die visuelle Transformation widerzuspiegeln, die durch die Leitbedingungen in 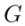 festgelegt ist.
festgelegt ist.  . Es ist formalisiert als:
. Es ist formalisiert als: 
 : Der formale Prozess der
: Der formale Prozess der 
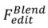 : Der formale Prozess der
: Der formale Prozess der 
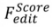 :
: 
 :
: 


 Eine detaillierte Analyse finden Sie im Originalpapier.
Eine detaillierte Analyse finden Sie im Originalpapier. 
 Für gängige textgesteuerte Bearbeitungsaufgaben wurden in diesem Artikel mehrere anspruchsvolle qualitative Experimente entworfen, um die für verschiedene Kombinationen geeigneten Bearbeitungsszenarien zu veranschaulichen. Darüber hinaus werden in diesem Artikel auch hochwertige und schwierige Datensätze gesammelt, um die Leistung fortschrittlicher Algorithmen in verschiedenen Kombinationen in verschiedenen Szenarien quantitativ zu veranschaulichen.
Für gängige textgesteuerte Bearbeitungsaufgaben wurden in diesem Artikel mehrere anspruchsvolle qualitative Experimente entworfen, um die für verschiedene Kombinationen geeigneten Bearbeitungsszenarien zu veranschaulichen. Darüber hinaus werden in diesem Artikel auch hochwertige und schwierige Datensätze gesammelt, um die Leistung fortschrittlicher Algorithmen in verschiedenen Kombinationen in verschiedenen Szenarien quantitativ zu veranschaulichen. 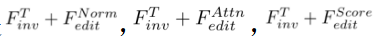
 Schauen Sie sich die zehn Kryptowährungen an, in die sich eine Investition lohnt
Schauen Sie sich die zehn Kryptowährungen an, in die sich eine Investition lohnt
 So starten Sie den SVN-Dienst
So starten Sie den SVN-Dienst
 So fügen Sie ein Video in HTML ein
So fügen Sie ein Video in HTML ein
 So stellen Sie versehentlich gelöschte Dateien wieder her
So stellen Sie versehentlich gelöschte Dateien wieder her
 Die Bedeutung des Titels in HTML
Die Bedeutung des Titels in HTML
 Was sind die Java-Workflow-Engines?
Was sind die Java-Workflow-Engines?
 Benennen Sie die APK-Software um
Benennen Sie die APK-Software um
 Was soll ich tun, wenn beim Einschalten des Computers englische Buchstaben angezeigt werden und der Computer nicht eingeschaltet werden kann?
Was soll ich tun, wenn beim Einschalten des Computers englische Buchstaben angezeigt werden und der Computer nicht eingeschaltet werden kann?
 So ändern Sie das CAD-Layout von Weiß auf Schwarz
So ändern Sie das CAD-Layout von Weiß auf Schwarz








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



