Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Das Autorenteam dieses Artikels kommt vom Social Computing and Information Retrieval Research Center des Harbin Institute of Technology. Zheng Zihao, Zhang Zihan, Wang Zexin, Fu Rui Ji, Liu Ming, Wang Zhongyuan, Qin Bing. Die Erkennung multimodaler benannter Entitäten als grundlegende und Schlüsselaufgabe beim Aufbau multimodaler Wissensgraphen erfordert von Forschern die Integration mehrerer modaler Informationen, um benannte Entitäten genau aus Text zu extrahieren. Obwohl frühere Forschungen Integrationsmethoden multimodaler Darstellungen auf verschiedenen Ebenen untersucht haben, reichen diese immer noch nicht aus, um diese multimodalen Darstellungen zu verschmelzen, um umfassende Kontextinformationen bereitzustellen und dadurch die Leistung der Erkennung multimodaler benannter Entitäten zu verbessern. In diesem Artikel schlägt das Forschungsteam DPE-MNER vor, ein innovatives iteratives Argumentationsgerüst, das der Strategie „Zerlegen, Priorisieren, Eliminieren“ folgt und verschiedene multimodale Darstellungen dynamisch integriert. Dieses Framework zerlegt die Fusion multimodaler Darstellungen geschickt in hierarchische und miteinander verbundene Fusionsschichten und vereinfacht so den Verarbeitungsprozess erheblich. Bei der Integration multimodaler Informationen legte das Team besonderen Wert auf progressive Übergänge von „einfach zu komplex“ und „von Makro zu Mikro“. Darüber hinaus schließt das Forschungsteam durch die explizite Modellierung modalübergreifender Korrelationen effektiv irrelevante Informationen aus, die MNER-Vorhersagen irreführen könnten. Durch umfangreiche Experimente mit zwei öffentlichen Datensätzen hat sich die Methode des Forschungsteams als erheblich wirksam bei der Verbesserung der Genauigkeit und Effizienz der multimodalen Erkennung benannter Entitäten erwiesen. Dieser Artikel ist einer der zehn besten Paper-Kandidaten unter 1558 angenommenen Papers für LREC-COLING 2024. 
- Papierlink: https://www.php.cn/link/4b4984066015df12cfc4e8f6d60b7147
 Ein Beispiel für die multimodale Erkennung benannter Entitäten. Das Forschungsteam demonstrierte eine Vielzahl multimodaler Darstellungen, die für Entscheidungen zur Erkennung benannter Entitäten nützlich sein können. Menschen verarbeiten diese Informationen typischerweise iterativ mental. Um dieses Problem anzugehen, ließ sich das Forschungsteam vom Bereich der „Lösung komplexer Probleme“ inspirieren (Sternberg und Frensch, 1992). Dieser Bereich konzentriert sich auf die Untersuchung von Methoden und Strategien, die von Menschen und Computern verwendet werden, um Probleme mit mehreren Variablen, Unsicherheit und hoher Komplexität zu lösen. Erstens glauben sie, dass Menschen bei komplexen Problemen im Allgemeinen einen iterativen Ansatz verfolgen. Wie in der Abbildung gezeigt, verwendet das Forschungsteam bei der Behandlung von MNER tatsächlich einen iterativen Prozess. Zweitens nutzen Menschen spezifische Strategien, um diese Probleme zu vereinfachen, wie etwa das Zerlegen, Priorisieren und Eliminieren irrelevanter Faktoren.
Ein Beispiel für die multimodale Erkennung benannter Entitäten. Das Forschungsteam demonstrierte eine Vielzahl multimodaler Darstellungen, die für Entscheidungen zur Erkennung benannter Entitäten nützlich sein können. Menschen verarbeiten diese Informationen typischerweise iterativ mental. Um dieses Problem anzugehen, ließ sich das Forschungsteam vom Bereich der „Lösung komplexer Probleme“ inspirieren (Sternberg und Frensch, 1992). Dieser Bereich konzentriert sich auf die Untersuchung von Methoden und Strategien, die von Menschen und Computern verwendet werden, um Probleme mit mehreren Variablen, Unsicherheit und hoher Komplexität zu lösen. Erstens glauben sie, dass Menschen bei komplexen Problemen im Allgemeinen einen iterativen Ansatz verfolgen. Wie in der Abbildung gezeigt, verwendet das Forschungsteam bei der Behandlung von MNER tatsächlich einen iterativen Prozess. Zweitens nutzen Menschen spezifische Strategien, um diese Probleme zu vereinfachen, wie etwa das Zerlegen, Priorisieren und Eliminieren irrelevanter Faktoren.
Das Forschungsteam ist davon überzeugt, dass die Behandlung der multimodalen Named Entity Recognition (MNER) als iterativer Prozess der Integration multimodaler Informationen und der Verwendung dieser Strategien für MNER-Aufgaben sehr gut geeignet ist. Im Vergleich zu einstufigen Methoden können mehrstufige Methoden umfassendere vielfältige multimodale Darstellungen im Prozess der iterativen Optimierung der Ergebnisse der Named Entity Recognition (NER) nutzen.
Darüber hinaus eignen sich diese drei Strategien sehr gut für die Integration mehrerer Darstellungen in multimodalen NER:
Die Zerlegungsstrategie ermutigt uns, die Fusion multimodaler Darstellungen in kleinere, Leicht zu handhabende Einheiten, die in der Lage sind, multimodale Interaktionen auf verschiedenen Granularitätsebenen zu untersuchen. Die Priorisierungsstrategie empfiehlt die Integration multimodaler Informationen in der Reihenfolge „leicht bis schwer“ und „grob bis fein“; diese progressive Integration trägt zur schrittweisen Optimierung von MNER-Vorhersagen bei. Dadurch kann das Modell die Aufmerksamkeit schrittweise von einfachen, aber groben Informationen auf komplexe, aber präzise Details verlagern. Die Strategie zur Eliminierung von Irrelevanz inspiriert uns dazu, irrelevante Informationen in verschiedenen multimodalen Darstellungen explizit zu überprüfen und auszuschließen. Dies kann irrelevante Informationen eliminieren, die sich auf die MNER-Leistung auswirken können.
Methode
Das Forschungsteam entwarf ein iteratives multimodales Entitätsextraktionsframework, das mehrere multimodale Funktionen dynamisch zusammenführt, einschließlich eines iterativen Prozesses und eines Vorhersagenetzwerks. Iterative Modellierung MNERDas Forschungsteam folgte dem Diffusionsmodell, um Objekterkennung, visuelle Ausrichtung und Extraktion von Textentitäten als iterativen Entrauschungsprozess zu modellieren, und nutzte das Diffusionsmodell auch, um die Extraktion multimodaler Entitäten zu kombinieren wird als iterativer Prozess modelliert. Das Modell initialisiert zunächst zufällig eine Reihe von Entitätsintervallen  und verwendet ein Vorhersagenetzwerk, um multimodale Merkmale zu codieren, um sie während des Entrauschungsprozesses iterativ zu entrauschen, um die richtigen Entitätsintervalle
und verwendet ein Vorhersagenetzwerk, um multimodale Merkmale zu codieren, um sie während des Entrauschungsprozesses iterativ zu entrauschen, um die richtigen Entitätsintervalle  im Text zu erhalten. Wie in der Abbildung gezeigt, erhielt das Forschungsteam insgesamt drei granulare Darstellungen im Text
im Text zu erhalten. Wie in der Abbildung gezeigt, erhielt das Forschungsteam insgesamt drei granulare Darstellungen im Text 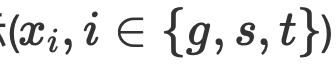 , zwei Granularitäten und zwei Schwierigkeiten im Bild (sie glauben, dass das übereinstimmte). Darstellungen sind einfache Darstellungen, falsch ausgerichtete Darstellungen sind schwierige Darstellungen)
, zwei Granularitäten und zwei Schwierigkeiten im Bild (sie glauben, dass das übereinstimmte). Darstellungen sind einfache Darstellungen, falsch ausgerichtete Darstellungen sind schwierige Darstellungen) 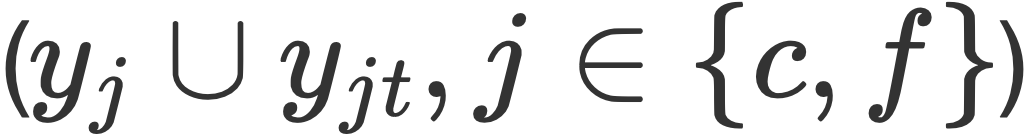 . Das Vorhersagenetzwerk AMRN des Teams umfasst ein Kodierungsnetzwerk (DMMF) und ein Dekodierungsnetzwerk (MER). Der Entwurf des Vorhersagenetzwerks basiert auf den drei zuvor genannten Strategien. Wie in der Abbildung gezeigt, ist das Codierungsnetzwerk ein hierarchisches Fusionsnetzwerk, das mehrere multimodale Merkmale in einem hierarchischen Prozess zusammenführt und zerlegt. Der Bottom-up-Prozess besteht darin, zunächst die Bildmerkmale mit derselben Granularität und unterschiedlichem Schwierigkeitsgrad in die Textmerkmale $x_i$ jeder Granularität zu integrieren und dann die Bildmerkmale $Y$ unterschiedlicher Granularität in die Textmerkmale jeder Granularität zu integrieren und schließlich die verschiedenen Granularitätsmerkmale $Y$ in die Textmerkmale
. Das Vorhersagenetzwerk AMRN des Teams umfasst ein Kodierungsnetzwerk (DMMF) und ein Dekodierungsnetzwerk (MER). Der Entwurf des Vorhersagenetzwerks basiert auf den drei zuvor genannten Strategien. Wie in der Abbildung gezeigt, ist das Codierungsnetzwerk ein hierarchisches Fusionsnetzwerk, das mehrere multimodale Merkmale in einem hierarchischen Prozess zusammenführt und zerlegt. Der Bottom-up-Prozess besteht darin, zunächst die Bildmerkmale mit derselben Granularität und unterschiedlichem Schwierigkeitsgrad in die Textmerkmale $x_i$ jeder Granularität zu integrieren und dann die Bildmerkmale $Y$ unterschiedlicher Granularität in die Textmerkmale jeder Granularität zu integrieren und schließlich die verschiedenen Granularitätsmerkmale $Y$ in die Textmerkmale 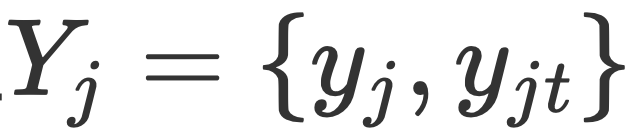 jeder Granularität integrieren. Die Bildmerkmale
jeder Granularität integrieren. Die Bildmerkmale  Y und die Textmerkmale X werden zusammengeführt, um die endgültige multimodale Darstellung zu erhalten. Eingabe in das Decodierungsnetzwerk zur Decodierung, und das Decodierungsnetzwerk erhält neue Intervalle und den Entitätstyp jedes Intervalls. Grundlegende Fusion. Diese Ebene des Forschungsteams integriert Bildmerkmale einer bestimmten Körnigkeit in Textmerkmale einer bestimmten Körnigkeit. Gemäß dem Diffusionsprozess kann das Forschungsteam einen Planer erhalten, der den Status der aktuellen Iteration widerspiegeln kann, was auch der Schlüssel zur Einführung von „Priorität“ ist. Basierend auf diesem Planer verschmolz das Forschungsteam Bildmerkmale unterschiedlicher Schwierigkeiten, um die - und -Korrelation
Y und die Textmerkmale X werden zusammengeführt, um die endgültige multimodale Darstellung zu erhalten. Eingabe in das Decodierungsnetzwerk zur Decodierung, und das Decodierungsnetzwerk erhält neue Intervalle und den Entitätstyp jedes Intervalls. Grundlegende Fusion. Diese Ebene des Forschungsteams integriert Bildmerkmale einer bestimmten Körnigkeit in Textmerkmale einer bestimmten Körnigkeit. Gemäß dem Diffusionsprozess kann das Forschungsteam einen Planer erhalten, der den Status der aktuellen Iteration widerspiegeln kann, was auch der Schlüssel zur Einführung von „Priorität“ ist. Basierend auf diesem Planer verschmolz das Forschungsteam Bildmerkmale unterschiedlicher Schwierigkeiten, um die - und -Korrelation  rel
rel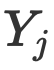 zu erhalten, die zur Eliminierung irrelevanter Informationen verwendet wird. Schließlich wird ein Engpasstransformator basierend auf dieser Korrelation verwendet, um und zu verschmelzen, und eine multimodale Bild- und Textfusionsdarstellung mit einer bestimmten Granularität wird erhalten.
zu erhalten, die zur Eliminierung irrelevanter Informationen verwendet wird. Schließlich wird ein Engpasstransformator basierend auf dieser Korrelation verwendet, um und zu verschmelzen, und eine multimodale Bild- und Textfusionsdarstellung mit einer bestimmten Granularität wird erhalten. 

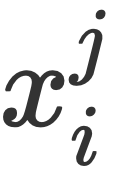 Mid-Layer-Fusion.Das Forschungsteam auf dieser Ebene verschmilzt Bildmerkmale unterschiedlicher Körnigkeit mit Textmerkmalen einer bestimmten Körnigkeit, also Fusion
Mid-Layer-Fusion.Das Forschungsteam auf dieser Ebene verschmilzt Bildmerkmale unterschiedlicher Körnigkeit mit Textmerkmalen einer bestimmten Körnigkeit, also Fusion . Auf dieser Ebene verwenden wir einen Scheduler, um Bildmerkmale unterschiedlicher Granularität dynamisch zu verschmelzen, um eine multimodale Textdarstellung einer bestimmten Granularität zu erhalten
. Auf dieser Ebene verwenden wir einen Scheduler, um Bildmerkmale unterschiedlicher Granularität dynamisch zu verschmelzen, um eine multimodale Textdarstellung einer bestimmten Granularität zu erhalten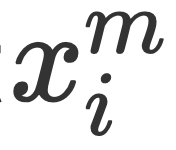 . Top-Fusion. Das Forschungsteam auf dieser Ebene verschmilzt multimodale Textdarstellungen
. Top-Fusion. Das Forschungsteam auf dieser Ebene verschmilzt multimodale Textdarstellungen  unterschiedlicher Granularität zu Intervalldarstellungen, um eine vollständige multimodale Textdarstellung
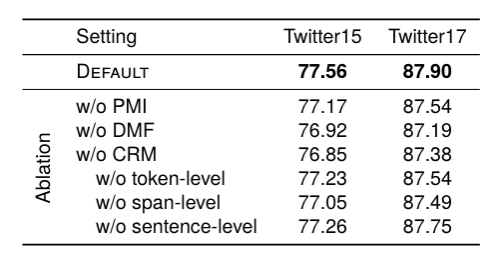
unterschiedlicher Granularität zu Intervalldarstellungen, um eine vollständige multimodale Textdarstellung 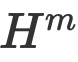 zu erhalten, die zur Vorhersage in das Decodierungsnetzwerk eingegeben wird. Experimentelle ErgebnisseDas Autorenteam verglich einige typische Methoden von MNER. Experimentelle Ergebnisse zeigen, dass diese Methode bei zwei häufig verwendeten Datensätzen die beste Leistung erzielt. Die Forscher entfernten die Priorisierungs-, Hierarchie- und Eliminierungsdesigns in unserem Artikel, um die Modellleistung zu beobachten. Die Ergebnisse zeigten, dass das Entfernen jedes Designs zu einer Leistungsverschlechterung führte. Vergleich mit statischen Feature-Fusion-MethodenSie verglichen einige typische statische multimodale Fusionsmethoden, wie Max-Pooling, Average-Pooling, MLP-basierte und MoE-basierte Methoden. Die Ergebnisse zeigen, dass ihr vorgeschlagenes dynamisches Fusions-Framework die beste Leistung erzielen kann.
zu erhalten, die zur Vorhersage in das Decodierungsnetzwerk eingegeben wird. Experimentelle ErgebnisseDas Autorenteam verglich einige typische Methoden von MNER. Experimentelle Ergebnisse zeigen, dass diese Methode bei zwei häufig verwendeten Datensätzen die beste Leistung erzielt. Die Forscher entfernten die Priorisierungs-, Hierarchie- und Eliminierungsdesigns in unserem Artikel, um die Modellleistung zu beobachten. Die Ergebnisse zeigten, dass das Entfernen jedes Designs zu einer Leistungsverschlechterung führte. Vergleich mit statischen Feature-Fusion-MethodenSie verglichen einige typische statische multimodale Fusionsmethoden, wie Max-Pooling, Average-Pooling, MLP-basierte und MoE-basierte Methoden. Die Ergebnisse zeigen, dass ihr vorgeschlagenes dynamisches Fusions-Framework die beste Leistung erzielen kann.

Das Forschungsteam wählte zwei repräsentative Proben aus, um den iterativen Prozess zu veranschaulichen. Es ist ersichtlich, dass im ersten Iterationsschritt die Typen von Zeitquadrat und Würfeln falsch vorhergesagt wurden, sie jedoch basierend auf den wichtigen Merkmalshinweisen im Bild iterativ auf den richtigen Entitätstyp korrigiert wurden. 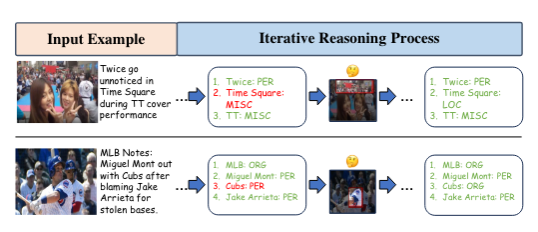 Dieses Papier zielt darauf ab, das Potenzial verschiedener multimodaler Darstellungen im Bereich der multimodalen Erkennung benannter Entitäten (MNER) voll auszuschöpfen, um hervorragende Erkennungsergebnisse zu erzielen. Zu diesem Zweck haben die Autoren ein innovatives Framework für iteratives Denken entworfen und vorgeschlagen: DPE-MNER. DPE-MNER vereinfacht den Integrationsprozess dieser umfangreichen und vielfältigen multimodalen Darstellungen auf clevere Weise, indem es die MNER-Aufgabe in mehrere Phasen zerlegt. In diesem iterativen Prozess erreichen multimodale Darstellungen eine dynamische Fusion und Integration auf der Grundlage der Strategie der „Zerlegung, Priorisierung und Eliminierung“. Durch eine Reihe strenger experimenteller Überprüfungen konnte das Forschungsteam die bemerkenswerten Effekte und die überlegene Leistung des DPE-MNER-Frameworks vollständig demonstrieren. [1] Knowledge Graphs Meet Multi-Modal Learning: Comprehensive Survey, arxiv[2] Zerlegen, Priorisieren und Eliminieren: Dynamisch Verbündeter bei der Integration von Diversem Representations for Multi-modal Named Entity Recognition, 2024, Gemeinsame Internationale Konferenz über Computerlinguistik, Sprachressourcen und Evaluation[3] Komplexe Problemlösung: Prinzipien und Mechanismen, 1992, American Journal of Psycholog [4] DiffusionNER: Grenzdiffusion für die Erkennung benannter Entitäten, ACL23 [5] DiffusionDet: Diffusionsmodell für die Objekterkennung, ICCV23[6] Sprachgesteuertes Diffusionsmodell für Visual. Ground ing , arxiv23
Dieses Papier zielt darauf ab, das Potenzial verschiedener multimodaler Darstellungen im Bereich der multimodalen Erkennung benannter Entitäten (MNER) voll auszuschöpfen, um hervorragende Erkennungsergebnisse zu erzielen. Zu diesem Zweck haben die Autoren ein innovatives Framework für iteratives Denken entworfen und vorgeschlagen: DPE-MNER. DPE-MNER vereinfacht den Integrationsprozess dieser umfangreichen und vielfältigen multimodalen Darstellungen auf clevere Weise, indem es die MNER-Aufgabe in mehrere Phasen zerlegt. In diesem iterativen Prozess erreichen multimodale Darstellungen eine dynamische Fusion und Integration auf der Grundlage der Strategie der „Zerlegung, Priorisierung und Eliminierung“. Durch eine Reihe strenger experimenteller Überprüfungen konnte das Forschungsteam die bemerkenswerten Effekte und die überlegene Leistung des DPE-MNER-Frameworks vollständig demonstrieren. [1] Knowledge Graphs Meet Multi-Modal Learning: Comprehensive Survey, arxiv[2] Zerlegen, Priorisieren und Eliminieren: Dynamisch Verbündeter bei der Integration von Diversem Representations for Multi-modal Named Entity Recognition, 2024, Gemeinsame Internationale Konferenz über Computerlinguistik, Sprachressourcen und Evaluation[3] Komplexe Problemlösung: Prinzipien und Mechanismen, 1992, American Journal of Psycholog [4] DiffusionNER: Grenzdiffusion für die Erkennung benannter Entitäten, ACL23 [5] DiffusionDet: Diffusionsmodell für die Objekterkennung, ICCV23[6] Sprachgesteuertes Diffusionsmodell für Visual. Ground ing , arxiv23Das obige ist der detaillierte Inhalt vonDas Harbin Institute of Technology schlägt ein innovatives iteratives Argumentationssystem (DPE-MNER) vor, das das Potenzial der multimodalen Darstellung voll ausschöpft. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




 . Auf dieser Ebene verwenden wir einen Scheduler, um Bildmerkmale unterschiedlicher Granularität dynamisch zu verschmelzen, um eine multimodale Textdarstellung einer bestimmten Granularität zu erhalten
. Auf dieser Ebene verwenden wir einen Scheduler, um Bildmerkmale unterschiedlicher Granularität dynamisch zu verschmelzen, um eine multimodale Textdarstellung einer bestimmten Granularität zu erhalten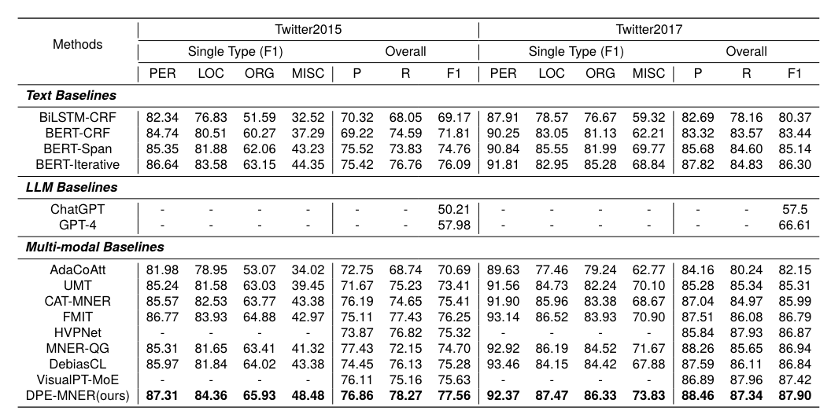
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



