

Egal aus welcher Stadt Sie kommen, ich glaube, Sie haben Ihren eigenen „Heimatstadt-Dialekt“ im Gedächtnis: Der Wu-Dialekt ist sanft und zart, der Guanzhong-Dialekt ist einfach und dick, der Sichuan-Dialekt ist humorvoll und humorvoll, das Kantonesische ist urig und hemmungslos. ..
In gewissem Sinne ist Dialekt nicht nur eine Sprachgewohnheit, sondern auch eine emotionale Verbindung und eine kulturelle Identität. Viele der neuen Wörter, die uns beim Surfen im Internet begegnen, stammen aus lokalen Dialekten verschiedener Orte.
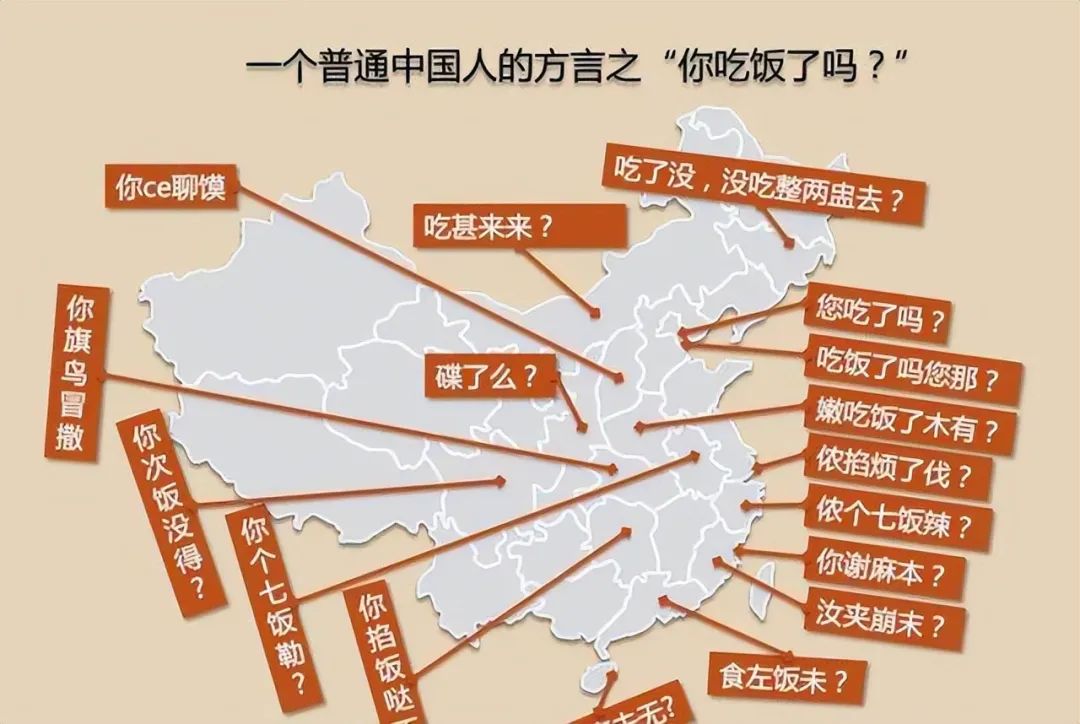
Natürlich ist Dialekt manchmal auch eine „Barriere“ für die Kommunikation.
Im wirklichen Leben sehen wir oft „Hühner sprechen wie Enten“, die durch Dialekte verursacht werden, wie zum Beispiel diesen: 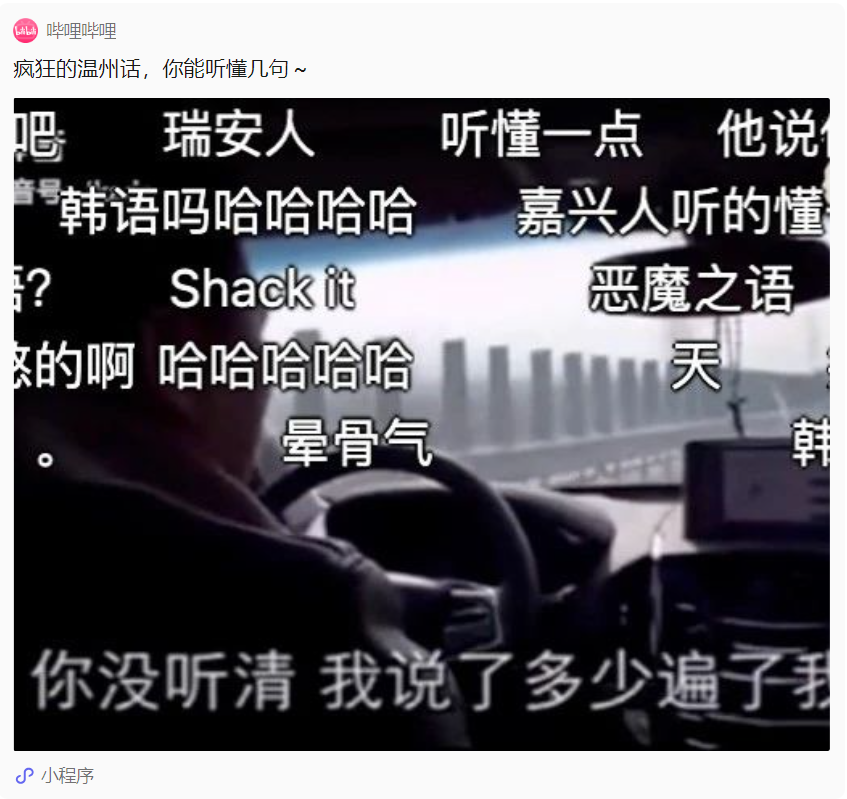
Wenn Sie auf die jüngsten Trends im Technologiekreis achten, wissen Sie, dass der aktuelle KI-Sprachassistent kann bereits erreicht werden Das Niveau der „Echtzeitreaktion“ ist sogar schneller als die menschliche Reaktion. Darüber hinaus ist die KI in der Lage, menschliche Emotionen vollständig zu verstehen und verschiedene Emotionen selbstständig auszudrücken.
Wenn der Sprachassistent auf dieser Grundlage jeden Dialekt erkennen und verstehen kann, kann er Kommunikationsbarrieren vollständig abbauen und mit jeder Gruppe ohne Barrieren kommunizieren.
Tatsächlich hat das schon jemand gemacht: Kürzlich hat das China Telecom Artificial Intelligence Research Institute (TeleAI) das branchenweit erste „Xingchen Super Multi-Dialect Speech Recognition Model“ veröffentlicht, das die freie Mischung von 30 Dialekten unterstützt versteht Kantonesisch, Shanghainisch, Sichuan, Wenzhou und andere lokale Dialekte. Es handelt sich um ein großes Spracherkennungsmodell, das die meisten Dialekte in China unterstützt.
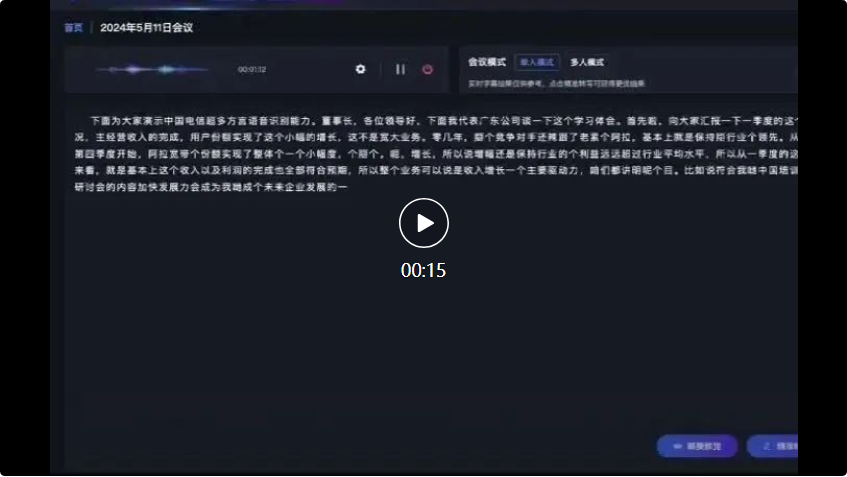
Im folgenden Konferenzszenario beispielsweise erreichte die Erkennungsgenauigkeit des großen Multidialekt-Spracherkennungsmodells von Xingchen angesichts der Eingaben aus mehreren Dialekten das branchenweit führende Niveau.
Zuerst sprach der Vertreter des Unternehmens aus Guangdong auf Kantonesisch: 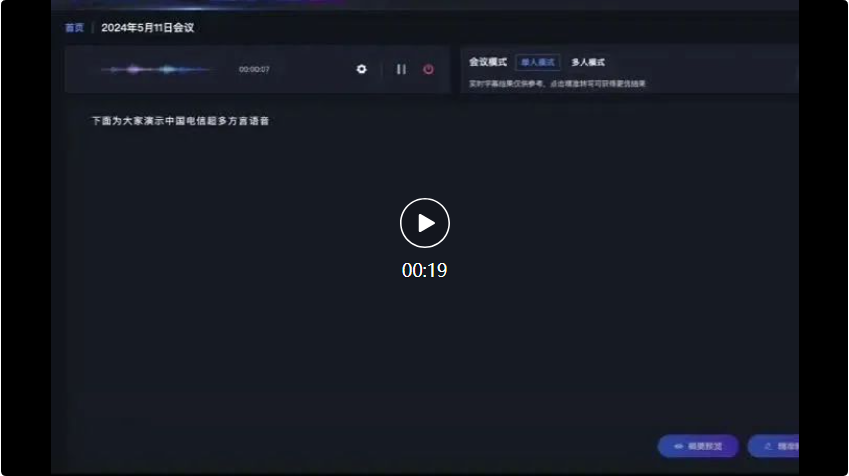
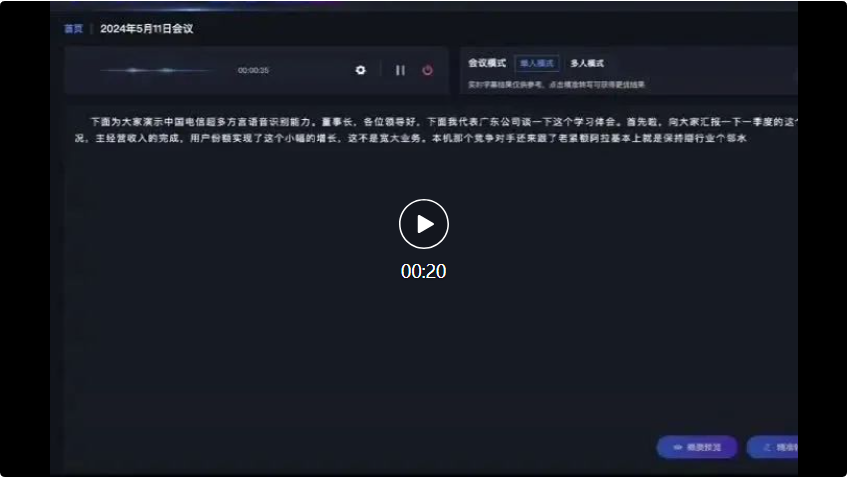 Im anschließenden Dialog zwischen Sichuan-Dialekt und Shanxi-Dialekt, Xingchens großem Multidialekt-Spracherkennungsmodell kann auch Folgendes genau erkennen und in Textaufzeichnungen umwandeln:
Im anschließenden Dialog zwischen Sichuan-Dialekt und Shanxi-Dialekt, Xingchens großem Multidialekt-Spracherkennungsmodell kann auch Folgendes genau erkennen und in Textaufzeichnungen umwandeln: 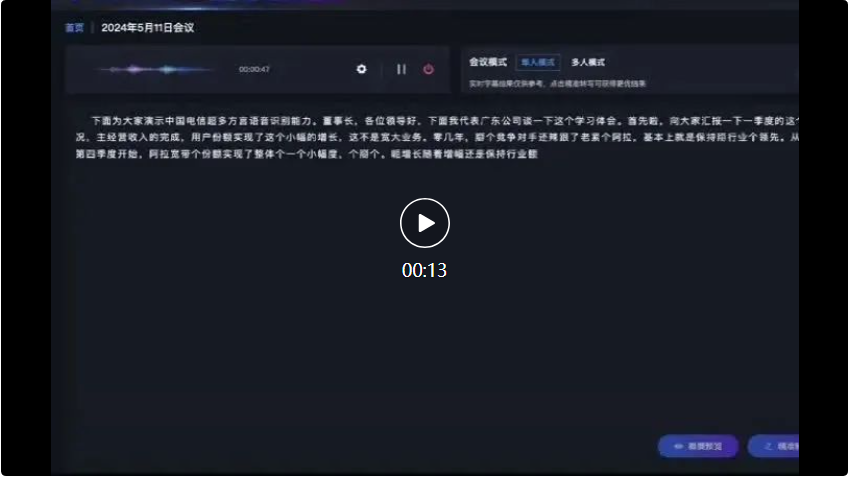
Jeder, der schon einmal mit einem Sprachassistenten gesprochen hat, weiß, dass die Genauigkeit der Spracherkennung für Mandarin recht gut ist, aber bei starken Akzenten oder Dialekten ist die Erkennung schwächer Die Genauigkeit wird erheblich sinken oder sogar „die Krone auf den Hut setzen“.
Um dieses Problem zu lösen, besteht das traditionelle Spracherkennungsmodell darin, für jeden Dialekt ein separates Dialektmodell zu trainieren. Dies führt dazu, dass mehrere Dialektmodelle hinter derselben Anwendung verwaltet werden müssen und es unmöglich ist, mehrere Dialekte durch eines zu erkennen Modell. Letzteres ist jedoch genau das, was in realen Szenarien am meisten benötigt wird.
China Telecom, das sich intensiv mit dem Sprachbereich beschäftigt, hat beschlossen, diesen Vorschlag in Frage zu stellen: ein „universelleres“ großes Spracherkennungsmodell zu entwickeln.
Mehr als 30 Dialekte, wie bekommt man das große Vorbild?
Es ist nicht so einfach wie gedacht, ein großes Modell mehr als 30 Dialekte auf einmal lernen zu lassen – die Herausforderungen bestehen auch in Bezug auf Daten, Algorithmen und Rechenleistung.
Einerseits ist der Effekt des alleinigen Trainings eines Dialektmodells ohne Verwendung der gemeinsamen Informationen in anderen Dialektdaten aufgrund der geringen Menge an Dialektdaten oft unbefriedigend.
Nach jahrelanger Erfahrung im Sprachbereich hat TeleAI eine hochwertige Dialektdatenbank mit mehr als 30 Arten und mehr als 300.000 Stunden aufgebaut. Die Dialektdatenbank steht in Bezug auf Umfang und hohe Qualität an der Spitze der Branche. Hochwertige Sprachdaten sind für Forscher ein großes Plus, da sie es Modellen ermöglichen, Dialekte effizienter und systematischer zu organisieren und zusammenzufassen. Längerfristig ist der Aufbau einer hochwertigen Dialektdatenbank auch die Grundlage für Dialektschutz und Dialektforschung.
Eine weitere Herausforderung stellt die Spracherkennungstechnologie dar. Ein neues Ziel, das die Branche derzeit verfolgt, ist es, Nutzer dazu zu bringen, mit großen Models so natürlich zu sprechen wie mit Familienmitgliedern, ohne bewusst auf Mandarin umschalten zu müssen, ohne die Lautstärke zu erhöhen oder die Sprechgeschwindigkeit zu verlangsamen.
Unter der Leitung von Li Xuelong, CTO von China Telecom und Direktor des Artificial Intelligence Research Institute, entwickelte TeleAI unabhängig das groß angelegte Xingchen-Spracherkennungsmodell. Das Team leistete Pionierarbeit für den gemeinsamen Trainingsalgorithmus „Destillation + Expansion“, der das Problem des Zusammenbruchs vor dem Training unter extrem großen Multiszenario-Datensätzen und großen Parameterbedingungen löste und ein stabiles Training des 80-Schichten-Modells erreichte . Gleichzeitig unterstützt ein einzelnes Modell durch extrem umfangreiches Sprachvortraining und gemeinsame Modellierung mehrerer Dialekte die freie gemischte Spracherkennung von 30 Dialekten.

Das große Spracherkennungsmodell von Xingchen ist auch das branchenweit erste große Open-Source-Spracherkennungsmodell, das auf der diskreten Sprachdarstellung basiert Die Schlussfolgerung wird um das Dutzendfache reduziert.
Mit seiner absolut führenden Leistung hat das große Spracherkennungsmodell von Xingchen bereits mehrere internationale Meisterschaften in maßgeblichen Wettbewerben gewonnen.
Zum Beispiel liegt im ASR-Track (Automatic Speech Recognition, Automatic Speech Recognition) der Interspeech 2024 Discrete Speech Unit Modeling Challenge, der maßgeblichen internationalen Sprachkonferenz, das Xingchen-Spracherkennungs-Großmodellteam vor der Johns Hopkins University, Card Well -Renommierte Universitäten und Unternehmen im In- und Ausland, darunter die Mellon University und NVIDIA, gewannen auf einen Schlag die Bahnmeisterschaft.
Die vom Team in diesem Wettbewerb vorgeschlagene Systemlösung ist sehr charakteristisch: Sie verwendet während des Trainings ein „dreistufiges“ Design, einschließlich der Strategie zur Anpassung der Darstellung des Front-End-Modells vor dem Training (Frontend-Modell), der Darstellungsextraktion und des Diskretisierungsprozesses (Dsicrete Token Process) und der Trainingsprozess für mehrsprachige Erkennungsmodelle (Discrete ASR Model), während in der Inferenzphase nur die beiden letztgenannten Prozesse verwendet werden.
Die Darstellungsdiskretisierungsmethode ermöglicht es dem Modell, aufgabenbezogene Informationen in der Sprache beizubehalten und gleichzeitig andere irrelevante Informationen zu entfernen, um den Zweck der Reduzierung der Sprachinferenzübertragungsbitrate, der Reduzierung der Speichernutzung und der Verbesserung der Trainingseffizienz zu erreichen. Es bietet auch mögliche Lösungen für die Sprache werden in den Richtungen einheitliche Modellkonstruktion, multimodale Modellmodellierung und Sprecher-Privatsphärenschutz für mehrere Aufgaben (wie ASR, TTS, Sprechererkennung usw.) bereitgestellt.
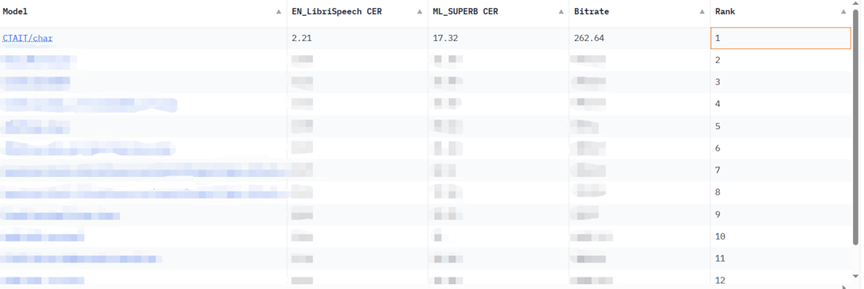
Bei der KeSpeech-Aufgabe, einem in der Branche bekannten Spracherkennungsdatensatz für mehrere Dialekte, brach das große Spracherkennungsmodell von Xingchen den Rekord um 20 % über dem vorherigen besten Ergebnis und erreichte eine Wortgenauigkeit von 92,97 %. Bei der vom NIST (National Institute of Standards and Technology) durchgeführten ressourcenarmen kantonesischen Telefon-Babel-Spracherkennungsaufgabe erzielte das Xingchen-Spracherkennungs-Großmodell ebenfalls die besten Ergebnisse in der Branche.
In Bezug auf häufige Herausforderungen bei der Rechenleistung hat das Forschungs- und Entwicklungsteam des großen Xingchen-Spracherkennungsmodells auch Vorteile. China Telecom ist der erste inländische Betreiber, der in den Bereich Cloud Computing einsteigt, und verfügt über eine große Anzahl von Kerntechnologien für den Aufbau und die Planung der Rechenleistung. Darüber hinaus hat China Telecom nacheinander mehrere öffentliche intelligente Rechenzentren in Betrieb genommen, die den Anforderungen großer Modellschulungen gerecht werden, wie das Beijing-Tianjin-Hebei Intelligent Computing Center und das Central-South Intelligent Computing Center.
Basierend auf diesen Vorteilen wurde Xingchens großes Multidialekt-Spracherkennungsmodell geboren, das das Dilemma überwindet, dass ein einzelnes Modell nur einen bestimmten einzelnen Dialekt erkennen kann. In mehreren Benchmark-Tests hat das große Super-Multidialekt-Spracherkennungsmodell von Xingchen äußerst hervorragende Fähigkeiten gezeigt:
im großen Modell Das Benutzererlebnis von Sprachassistenten, intelligenten Geräten und Kundendienstsystemen, die vor dem Aufkommen der Technologie weit verbreitet waren, hängt in hohem Maße von der Genauigkeit des Spracherkennungssystems ab. Viele Hersteller im In- und Ausland arbeiten an diesem Weg, aber jeder wird auch feststellen, dass außerhalb der Mainstream-Sprachen chinesischen Dialekten mit Hunderten Millionen Nutzern nicht die gebührende Aufmerksamkeit geschenkt wurde und ihr Szenenwert stark unterschätzt wurde.
Langfristig können die Multidialektfähigkeiten des groß angelegten Multidialekt-Spracherkennungsmodells von Xingchen in einer Vielzahl sozialer Lebensszenarien wertvoll sein. Am Beispiel des Smart Cockpit-Szenarios mit einer hohen Häufigkeit der Sprachinteraktion kann Xingchens großes Spracherkennungsmodell für mehrere Dialekte, das in verschiedenen Dialekten gut ist, es dem System ermöglichen, Spracheingaben in verschiedenen Dialekten genauer zu erkennen und zu transkribieren. Ein interaktives Erlebnis, insbesondere in Bereichen, in denen häufig Dialekte verwendet werden, kann Missverständnisse reduzieren, die durch „Hühner, die mit Enten sprechen“ verursacht werden.
Aus der Perspektive der emotionalen Kameradschaft kann das Verständnis und die Beherrschung großer Dialektmodelle die Kameradschaftsqualität von Gesprächsroboterprodukten erheblich verbessern und das Problem älterer Menschen und anderer Gruppen, die Mandarin nicht beherrschen, effektiv lösen Zugriff auf Informationsdienste. Genau wie die Handlung im Science-Fiction-Film „Her“ kann KI den Menschen eine hochwertige Pflege bieten, die über zwischenmenschliche Beziehungen in der realen Welt hinausgeht. 
Derzeit hat Xingchens großes Multidialekt-Spracherkennungsmodell mit der Integration in verschiedene Branchen begonnen und erforscht aktiv neue Anwendungsszenarien. Beispielsweise wurde das groß angelegte Multidialekt-Spracherkennungsmodell von Xingchen im intelligenten Kundendienstsystem Wanhao von China Telecom in Fujian, Jiangxi, Guangxi, Peking, der Inneren Mongolei und anderen Orten getestet, nachdem auf das groß angelegte Multidialektmodell von Xingchen zugegriffen wurde Spracherkennungsmodell, Wanhao Intelligenter Kundenservice versteht 30 Dialekte in Sekunden und bearbeitet durchschnittlich etwa 2 Millionen Anrufe pro Tag; die intelligente Kundenservice-Plattform Yisheng ist mit den Sprachverständnis- und Analysefunktionen der Super-Multidialekt-Sprache von Xingchen verbunden Erkennungsmodell, das eine vollständige Abdeckung in 31 Provinzen erreicht und täglich 1,25 Millionen Kundendienstanrufe bearbeiten kann.
Für China Telecom gibt es einen weiteren sehr wichtigen Ausgangspunkt: Wenn vor 2023 über Großmodelltechnologie gesprochen wird, wird der Gemeinwohlwert kaum noch erwähnt. Aber im Jahr 2024 wird dieser Wert zunehmend „gesehen“. Der Einsatz großer Modelltechnologie wird den Schutz der Dialektkultur erheblich fördern. Von den mehr als 130 Sprachen unseres Landes haben 68 weniger als 10.000 Sprecher, 48 weniger als 5.000 Sprecher, 25 weniger als 1.000 Sprecher und einige Sprachen haben nur ein Dutzend oder sogar wenige Sprecher. kann sprechen. Die Beteiligung großer Sprachmodelle kann dazu beitragen, gefährdete Dialekte aufzuzeichnen und zu schützen sowie die Vererbung und das Erlernen von Dialekten zu fördern. Bei historischen Dokumenten und Archiven, die eine große Menge an Dialektinhalten enthalten, können Dialekt-Großmodelle auch bei der Digitalisierung und Organisation helfen, um den Verlust des kulturellen Erbes zu verhindern.„Voice Assistant“ ist vollständig geöffnet
Wie kann China Telecom den Kampf um die Implementierung großer Modelle anführen?
Der Kampf um große Modelle dauert bereits seit anderthalb Jahren an. Derzeit herrscht in der Branche Konsens: Da die Kosten für die Inferenz großer Modelle erheblich sinken, läuten die Leute eine Periode des Durchbruchs für große Modellanwendungen ein. Unter den vielen großen Modellspielern im In- und Ausland ist China Telecom ein ganz besonderer Anbieter. In dieser neuen Phase haben Betreiber wie China Telecom im Vergleich zu den uns bekannten Technologieunternehmen mehr Vorteile in Bezug auf Ressourcen und Geschäft. Einerseits verfügen die Betreiber über reichlich Netzwerk- und Rechenressourcen, und relativ gesehen sind die Schulungs- und Inferenzkosten niedriger. Gerade beim Bau großer Modelle ist es einfacher, Maßstabsvorteile zu nutzen. Andererseits verfügt China Telecom über einen großen Kundenstamm und umfangreiche 2C-, 2H- und 2B-Informationsdienstleistungsunternehmen, die die Implementierung großer Modelle künstlicher Intelligenz in verschiedenen Bereichen schnell vorantreiben und neue Wirtschaftswachstumspunkte schaffen können. Diese Vorteile motivieren Betreiber, verstärkt in den Bereich der künstlichen Intelligenz zu investieren und den technologischen Fortschritt voranzutreiben. Unter den inländischen Betreibern ist China Telecomder erste Anbieter im Bereich KI und verfolgt den Entwicklungspfad der technologischen Innovation sowie der unabhängigen Forschung und Entwicklung von Kernkompetenzen. Seit letztem Jahr haben die großen Modelle von China Telecom vom semantischen Großmodell von Xingchen über das multimodale Großmodell von Xingchen bis zum Großmodell der Spracherkennung von Xingchen stets eine schnelle Iteration beibehalten und das vollständige Modell von Semantik, Sprache, Vision und Multimodalität vervollständigt . Dynamisches großes Modelllayout.
 Was den traditionellen Eindruck zentraler Unternehmen noch mehr widerlegt, ist, dass China Telecom auch ein Schwergewichtsakteur im Bereich großer Open-Source-Modelle ist. In diesem Jahr hat TeleAI nacheinander 7B-, 12B- und 52B-Sternsemantik-Großmodelle als Open-Source-Modelle veröffentlicht. Noch in diesem Jahr wird auch das große semantische Modell von Hunderten Milliarden Sternen offiziell als Open Source verfügbar sein.
Was den traditionellen Eindruck zentraler Unternehmen noch mehr widerlegt, ist, dass China Telecom auch ein Schwergewichtsakteur im Bereich großer Open-Source-Modelle ist. In diesem Jahr hat TeleAI nacheinander 7B-, 12B- und 52B-Sternsemantik-Großmodelle als Open-Source-Modelle veröffentlicht. Noch in diesem Jahr wird auch das große semantische Modell von Hunderten Milliarden Sternen offiziell als Open Source verfügbar sein.
Wenn wir den technologischen Entwicklungstrend der künstlichen Intelligenz in den letzten Jahren verfolgen, können wir sehen, dass Sprache bei der Verwirklichung allgemeiner künstlicher Intelligenz ein wichtiger Teil und die Spracherkennung ein sehr wichtiger Teil davon ist.
Aber wir sind uns auch darüber im Klaren, dass die Reife der Sprachsynthesetechnologie der Schlüssel zur Neugestaltung verschiedener Sprachassistentenszenarien sein wird. Es versteht sich, dass TeleAI gleichzeitig auch ein großes übernatürliches Spracherzeugungsmodell entwickelt hat, das die Personifizierung realer macht und eine Sprachwiedergabe ohne Abtastung und Anthropomorphismus-Ausrichtung GPT-4o erreicht, was weitere Durchbrüche bei der Spracherkennung und -erzeugung auf Anwendungsebene erzielen und die Universalität beschleunigen wird Landeanwendung für KI-Sprachassistenten.
Freuen Sie sich auf einen so vielseitigen chinesischen Sprachassistenten? 
Das obige ist der detaillierte Inhalt vonNach der Umstellung auf mehr als 30 Dialekte haben wir den Test des großen Sprachmodells von China Telecom nicht bestanden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



