Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Dieser Artikel wurde von HMI Lab fertiggestellt. HMI LabAuf der Grundlage der beiden Hauptplattformen des National Engineering Research Center for Video and Visual Technology der Universität Peking und des National Key Laboratory of Multimedia Information Processing beschäftigt sich das Unternehmen seit langem mit der Forschung in Richtung maschinelles Lernen und multimodales Lernen und verkörperte Intelligenz. Der Erstautor dieser Arbeit ist Dr. Liu Jiaming, dessen Forschungsrichtung multimodale verkörperte große Modelle und kontinuierliche Lerntechnologie für die offene Welt sind. Der zweite Autor dieser Arbeit ist Liu Mengzhen, dessen Forschungsrichtung das Vision-Grundmodell und die Robotermanipulation ist. Der Dozent ist Chen Shanghang, ein Forscher an der Fakultät für Informatik der Peking-Universität, ein Doktorvater und ein junger liberaler Wissenschaftler. Er beschäftigt sich mit der Forschung zu multimodalen Großmodellen und verkörperter Intelligenz und hat eine Reihe wichtiger Forschungsergebnisse erzielt. Er hat mehr als 80 Artikel in führenden Fachzeitschriften und Konferenzen für künstliche Intelligenz veröffentlicht und wurde von Google mehr als 9.700 Mal zitiert. Gewann den Best Paper Award von AAAI, der weltweit führenden Konferenz für künstliche Intelligenz, und belegte den ersten Platz bei Trending Research, dem weltweit größten akademischen Quellcode-Repository. Um dem Roboter durchgängige Argumentations- und Manipulationsfähigkeiten zu verleihen, integriert dieser Artikel den visuellen Encoder auf innovative Weise mit einem effizienten Zustandsraum-Sprachmodell, um ein neues multimodales großes RoboMamba-Modell zu erstellen, das ihn in die Lage versetzt, visuell gemeinsam zu sein Wahrnehmungsaufgaben und Roboterfähigkeiten zum logischen Denken bei verwandten Aufgaben und haben eine fortgeschrittene Leistung erzielt. Gleichzeitig wurde in diesem Artikel festgestellt, dass wir RoboMamba durch extrem niedrige Schulungskosten in die Lage versetzen können, mehrere Funktionen zur Vorhersage der Manipulationshaltung zu beherrschen, wenn RoboMamba über starke Argumentationsfähigkeiten verfügt.

Artikel: RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
Artikellink: https://arxiv.org/abs/2406.04339
Projekthomepage: https:// sites.google.com/view/robomamba-web
Github: https://github.com/lmzpai/roboMamba
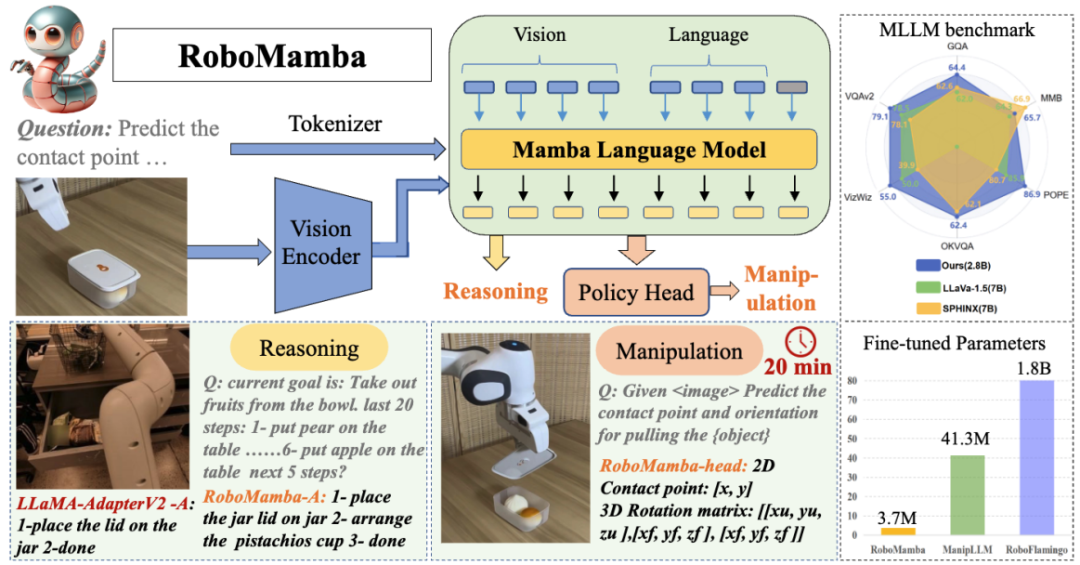
Abbildung 1. Roboterbezogene Funktionen von RoboMamba, einschließlich Aufgabenplanung , schnelle Missionsplanung, langfristige Missionsplanung, Manövrierfähigkeitsbeurteilung, Manövrierfähigkeitsgenerierung, Zukunfts- und Vergangenheitsvorhersage, Endeffektor-Pose-Vorhersage usw. Ein grundlegendes Ziel der Robotermanipulation besteht darin, dem Modell zu ermöglichen, die visuelle Szene zu verstehen und Aktionen auszuführen. Obwohl bestehende multimodale Robotermodelle (MLLM) eine Reihe grundlegender Aufgaben bewältigen können, stehen sie immer noch vor Herausforderungen in zwei Aspekten: 1) Unzureichende Argumentationsfähigkeit zur Bewältigung komplexer Aufgaben; 2) Der Rechenaufwand für die Feinabstimmung und Inferenz von MLLM ist relativ hoch hoch. Ein kürzlich vorgeschlagenes Zustandsraummodell (SSM), nämlich Mamba, besitzt eine lineare Inferenzkomplexität und zeigt gleichzeitig vielversprechende Fähigkeiten bei der Sequenzmodellierung. Davon inspiriert haben wir ein End-to-End-Roboter-MLLM auf den Markt gebracht – RoboMamba, das das Mamba-Modell verwendet, um Roboter-Argumentations- und Aktionsfähigkeiten bereitzustellen und gleichzeitig effiziente Feinabstimmungs- und Argumentationsfunktionen beizubehalten. Konkret integrieren wir zunächst den visuellen Encoder in Mamba, um durch gemeinsames Training visuelle Daten mit Spracheinbettungen abzugleichen und unserem Modell visuellen gesunden Menschenverstand und roboterbezogene Denkfähigkeiten zu verleihen. Um die Fähigkeiten von RoboMamba zur Vorhersage der Manipulationshaltung weiter zu verbessern, untersuchen wir eine effiziente Feinabstimmungsstrategie, die nur einen einfachen Policy Head verwendet. Wir haben festgestellt, dass RoboMamba, sobald es über ausreichende Denkfähigkeiten verfügt, mehrere operative Fähigkeiten mit sehr wenigen Feinabstimmungsparametern (0,1 % des Modells) und Feinabstimmungszeit (20 Minuten) beherrschen kann. In Experimenten zeigte RoboMamba hervorragende Denkfähigkeiten bei allgemeinen und robotischen Bewertungsbenchmarks, wie in Abbildung 2 dargestellt. Gleichzeitig demonstriert unser Modell beeindruckende Fähigkeiten zur Vorhersage der Manipulationshaltung in Simulationen und realen Experimenten mit bis zu siebenmal höheren Inferenzgeschwindigkeiten als bestehende Roboter-MLLMs.
Abbildung 2. Übersicht: Robomamba ist ein effizientes multimodales großes Robotermodell mit leistungsstarken Denk- und Bedienungsfähigkeiten. RoboMamba-2.8B erreicht bei allgemeinen MLLM-Benchmarks eine konkurrenzfähige Inferenzleistung mit anderen 7B-MLLMs und demonstriert gleichzeitig weitreichende Inferenzfähigkeiten bei Roboteraufgaben. Anschließend haben wir eine äußerst effiziente Feinabstimmungsstrategie eingeführt, um RoboMamba die Fähigkeit zu geben, Manipulationsposen vorherzusagen, und die Feinabstimmung eines einfachen Strategiekopfes dauert nur 20 Minuten. Die Hauptbeiträge dieses Artikels sind wie folgt zusammengefasst: Modell des Roboters RoboMamba, das über visuellen gesunden Menschenverstand und umfassende Denkfähigkeiten im Zusammenhang mit Robotern verfügt. Um RoboMamba mit Posenvorhersagefunktionen für die Endeffektormanipulation auszustatten, haben wir eine effiziente Feinabstimmungsstrategie mithilfe eines einfachen Policy Head untersucht. Wir haben herausgefunden, dass RoboMamba, sobald es über ausreichende Denkfähigkeiten verfügt, Fähigkeiten zur Manipulation von Posenvorhersagen zu sehr geringen Kosten beherrschen kann.
In unseren umfangreichen Experimenten schneidet RoboMamba bei allgemeinen und robotischen Inferenzbewertungsbenchmarks gut ab und zeigt beeindruckende Posenvorhersageergebnisse in Simulatoren und Experimenten in der realen Welt.
Forschungshintergrund
- Die Datenskalierung hat die Entwicklung der Forschung zu großen Sprachmodellen (LLMs) erheblich vorangetrieben und erhebliche Argumentations- und Generalisierungsfähigkeiten im Fortschritt der Verarbeitung natürlicher Sprache (NLP) demonstriert. Um multimodale Informationen zu verstehen, entstanden multimodale Large Language Models (MLLMs), die LLMs die Möglichkeit geben, visuellen Anweisungen zu folgen und Szenen zu verstehen. Inspiriert durch die leistungsstarken Fähigkeiten von MLLMs in Allzweckumgebungen zielen aktuelle Forschungsarbeiten darauf ab, MLLMs auf den Bereich der Roboterbedienung anzuwenden. Einige Forschungsanstrengungen ermöglichen es Robotern, natürliche Sprache und visuelle Szenen zu verstehen und automatisch Missionspläne zu erstellen. Andere Forschungsarbeiten nutzen die inhärenten Fähigkeiten von MLLMs, um es ihnen zu ermöglichen, Betriebspositionen vorherzusagen.
Der Roboterbetrieb umfasst die Interaktion mit Objekten in einer dynamischen Umgebung und erfordert menschenähnliche Denkfähigkeiten, um die semantischen Informationen der Szene zu verstehen, sowie leistungsstarke Fähigkeiten zur Manipulation der Pose zur Vorhersage. Obwohl bestehende roboterbasierte MLLMs eine Reihe grundlegender Aufgaben bewältigen können, stehen sie dennoch in zweierlei Hinsicht vor Herausforderungen. 1) Erstens wurde festgestellt, dass die Argumentationsfähigkeit vortrainierter MLLMs in Robotikszenarien unzureichend ist. Wie in Abbildung 2
dargestellt, führt dieser Mangel zu Herausforderungen, wenn fein abgestimmte robotische MLLMs auf komplexe Argumentationsaufgaben stoßen. 2) Zweitens wird die Feinabstimmung von MLLMs und deren Verwendung zur Generierung von Roboterbetriebsaktionen aufgrund der hohen Rechenkomplexität bestehender MLLM-Aufmerksamkeitsmechanismen höhere Rechenkosten verursachen. Um ein Gleichgewicht zwischen Denkfähigkeit und Effizienz herzustellen, sind im Bereich NLP mehrere Studien entstanden. Insbesondere stellt Mamba das innovative Selective State Space Model (SSM) vor, das kontextbewusstes Denken erleichtert und gleichzeitig die lineare Komplexität beibehält. Inspiriert davon stellten wir eine Frage: „Können wir ein effizientes Roboter-MLLM entwickeln, das nicht nur über starke Denkfähigkeiten verfügt, sondern auch auf sehr wirtschaftliche Weise Roboterbedienungsfähigkeiten erwirbt?“ RoboMamba 1. Hintergrundwissen
, ausgedrückt als
.Begründungsantworten enthalten oft separate Unteraufgaben für eine Frage . Wenn Sie beispielsweise mit einem Planungsproblem wie „Wie räume ich den Tisch ab?“ konfrontiert sind, umfassen die Antworten normalerweise Schritte wie „Schritt 1: Heben Sie den Gegenstand auf“ und „Schritt 2: Legen Sie den Gegenstand in die Kiste.“ Für die Aktionsvorhersage verwenden wir einen effizienten und einfachen Richtlinienkopf π, um Aktionen vorherzusagen . In Anlehnung an frühere Arbeiten verwenden wir 6-DoF, um die Endeffektor-Pose des Franka Emika Panda-Roboterarms auszudrücken. Zu den 6 Freiheitsgraden gehören die Endeffektorposition , die die dreidimensionalen Koordinaten darstellt, und die Richtung , die die Rotationsmatrix darstellt. Beim Training für eine Greifaufgabe fügen wir den Greifzustand zur Posenvorhersage hinzu und ermöglichen so eine 7-DoF-Steuerung.
In diesem Artikel wird Mamba als großes Sprachmodell ausgewählt. Mamba besteht aus vielen Mamba-Blöcken, die kritischste Komponente ist SSM. SSM basiert auf einem kontinuierlichen System, das eine 1D-Eingabesequenz durch versteckte Zustände in eine 1D-Ausgabesequenz projiziert. SSM besteht aus drei Schlüsselparametern: Zustandsmatrix , Eingabematrix und Ausgabematrix . Das SSM kann wie folgt ausgedrückt werden:
Rezente SSMs (z. B. Mamba) werden als diskrete kontinuierliche Systeme unter Verwendung eines Zeitskalenparameters Δ konstruiert. Dieser Parameter wandelt die kontinuierlichen Parameter A und B in diskrete Parameter und um. Die Diskretisierung verwendet die Erhaltungsmethode nullter Ordnung, die wie folgt definiert ist:
Mamba führt einen selektiven Scanmechanismus (S6) ein, um seine SSM-Operation in jedem Mamba-Block zu gestalten. SSM-Parameter wurden für eine bessere inhaltsbezogene Schlussfolgerung auf aktualisiert. Die Details des Mamba-Blocks sind in Abbildung 3 unten dargestellt. 2. Struktur des RoboMamba-Modells
Abbildung 3. Robomamba-Gesamtrahmen. RoboMamba projiziert Bilder über visuelle Encoder und Projektionsebenen in den Spracheinbettungsraum von Mamba, die dann mit Text-Tokens verkettet und in das Mamba-Modell eingespeist werden. Um die Position und Ausrichtung des Endeffektors vorherzusagen, führen wir einen einfachen MLP-Richtlinienkopf ein und verwenden eine Pooling-Operation, um globale Token aus Sprachausgabetoken als Eingabe zu generieren. RoboMambas Trainingsstrategie. Beim Modelltraining unterteilen wir den Trainingsprozess in zwei Phasen. In Stufe 1 führen wir ein abgestimmtes Vortraining (Stufe 1.1) und ein Instruktions-Co-Training (Stufe 1.2) ein, um RoboMamba mit gesundem Menschenverstand und roboterbezogenen Denkfähigkeiten auszustatten. In Stufe 2 schlagen wir eine Feinabstimmung des Roboterbetriebs vor, um RoboMamba effizient mit Low-Level-Bedienfähigkeiten auszustatten. Um RoboMamba mit visuellen Argumentations- und Betriebsfähigkeiten auszustatten, haben wir eine effiziente MLLM-Architektur aufgebaut, die auf vorab trainierten großen Sprachmodellen (LLMs) und Visionsmodellen basiert. Wie in Abbildung 3 oben gezeigt, verwenden wir den visuellen Encoder CLIP, um visuelle Merkmale aus dem Eingabebild I zu extrahieren, wobei B und N die Stapelgröße bzw. die Anzahl der Token darstellen. Im Gegensatz zu neueren MLLMs verwenden wir keine visuellen Encoder-Ensemble-Techniken, die mehrere Backbone-Netzwerke (z. B. DINOv2, CLIP-ConvNeXt, CLIP-ViT) zur Extraktion von Bildmerkmalen verwenden. Durch die Integration entstehen zusätzliche Rechenkosten, was die Praktikabilität von robotischem MLLM in der realen Welt erheblich beeinträchtigt. Daher zeigen wir, dass einfaches und unkompliziertes Modelldesign auch leistungsstarke Inferenzfähigkeiten erreichen kann, wenn hochwertige Daten und geeignete Trainingsstrategien kombiniert werden. Damit das LLM visuelle Merkmale versteht, verwenden wir ein mehrschichtiges Perzeptron (MLP), um den visuellen Encoder mit dem LLM zu verbinden. Mit diesem einfachen modalübergreifenden Konnektor kann RoboMamba visuelle Informationen in einen Spracheinbettungsraum umwandeln . Bitte beachten Sie, dass die Modelleffizienz im Bereich der Robotik von entscheidender Bedeutung ist, da Roboter schnell auf menschliche Anweisungen reagieren müssen. Daher wählen wir Mamba aufgrund seiner kontextbewussten Argumentationsfähigkeiten und linearen Rechenkomplexität als unser großes Sprachmodell. Textaufforderungen werden mithilfe eines vorab trainierten Tokenizers in einen Einbettungsraum codiert, dann mit visuellen Token verkettet (Katze) und in Mamba eingespeist. Wir nutzen die leistungsstarke Sequenzmodellierung von Mamba, um multimodale Informationen zu verstehen und effektive Trainingsstrategien zu verwenden, um visuelle Denkfähigkeiten zu entwickeln (wie im nächsten Abschnitt beschrieben). Das Ausgabetoken () wird dann dekodiert (det), um eine Antwort in natürlicher Sprache zu generieren . Der Vorwärtsprozess des Modells kann wie folgt ausgedrückt werden:
3.RoboMamba allgemeines Seh- und Roboter-DenkvermögenstrainingNach dem Aufbau der RoboMamba-Architektur besteht das nächste Ziel darin, unser Modell zu trainieren, um allgemeines visuelles Denken und roboterbezogene Denkfähigkeiten zu erlernen. Wie in Abbildung 3 dargestellt, unterteilen wir das Training der Stufe 1 in zwei Unterschritte: Ausrichtungs-Vorschulung (Stufe 1.1) und Instruktions-Co-Training (Stufe 1.2). Im Gegensatz zu früheren MLLM-Trainingsmethoden ist es unser Ziel, RoboMamba in die Lage zu versetzen, allgemeine Seh- und Robotikszenarien zu verstehen. Da der Bereich der Robotik viele komplexe und neuartige Aufgaben umfasst, erfordert RoboMamba stärkere Generalisierungsfähigkeiten. Daher haben wir in Stufe 1.2 eine Co-Training-Strategie eingeführt, um übergeordnete Roboterdaten (z. B. Missionsplanung) mit allgemeinen Anweisungsdaten zu kombinieren. Wir stellen fest, dass Co-Training nicht nur zu besser verallgemeinerbaren Roboterrichtlinien führt, sondern aufgrund komplexer Argumentationsaufgaben in Roboterdaten auch zu verbesserten Denkfähigkeiten für allgemeine Szenarien führt. Die Trainingsdetails sind wie folgt: - Stufe 1.1: Ausrichtungs-Vortraining.
Wir verwenden einen LLaVA-gefilterten 558k-Bild-Text-gepaarten Datensatz für die modalübergreifende Ausrichtung. Wie in Abbildung 3 dargestellt, frieren wir die Parameter des CLIP-Encoders und des Mamba-Sprachmodells ein und aktualisieren nur die Projektionsebene. Auf diese Weise können wir Bildmerkmale mit vorab trainierten Mamba-Worteinbettungen ausrichten. - Stufe 1.2: Befehl zum gemeinsamen Training.
In dieser Phase verfolgen wir zunächst frühere MLLM-Arbeiten zur allgemeinen Datenerfassung für visuelle Anweisungen. Wir verwenden den 655K LLaVA Hybrid Instruction Dataset und den 400K LRV-Instruct Dataset, um das Befolgen visueller Anweisungen bzw. die Linderung von Halluzinationen zu erlernen. Es ist wichtig zu beachten, dass die Linderung von Halluzinationen in Roboterszenarien eine wichtige Rolle spielt, da robotisches MLLM Missionspläne erstellen muss, die auf realen Szenarien und nicht auf imaginären Szenarien basieren. Bestehende MLLMs antworten beispielsweise formelhaft auf „Öffnen Sie die Mikrowelle“, indem sie sagen: „Schritt 1: Finden Sie den Griff“, aber viele Mikrowellenherde haben keine Griffe. Als nächstes kombinieren wir den 800.000 RoboVQA-Datensatz, um hochrangige Roboterfähigkeiten zu erlernen, wie z. B. die Planung von Langstreckenmissionen, die Beurteilung der Manövrierfähigkeit, die Generierung der Manövrierfähigkeit, Vorhersagen für die Zukunft und die Vergangenheit usw. Während des Co-Trainings, wie in Abbildung 3 dargestellt, frieren wir die Parameter des CLIP-Encoders ein und optimieren die Projektionsebene und Mamba für den 1,8 m großen zusammengeführten Datensatz. Alle Ausgaben des Mamba-Sprachmodells werden mithilfe eines Kreuzentropieverlusts überwacht. 4. Training zur Feinabstimmung der Manipulationsfähigkeit von RoboMamba . Bestehende MLLM-basierte Roboterbetriebsmethoden erfordern eine Aktualisierung der Projektionsschicht und des gesamten LLM während der Feinabstimmungsphase des Betriebs. Obwohl dieses Paradigma dem Modell Fähigkeiten zur Vorhersage von Aktionsposen verleihen kann, zerstört es auch die inhärenten Fähigkeiten von MLLM und erfordert eine große Menge an Trainingsressourcen. Um diese Herausforderungen anzugehen, schlagen wir eine effiziente Feinabstimmungsstrategie vor, wie in Abbildung 3 dargestellt. Wir frieren alle Parameter von RoboMamba ein und führen einen einfachen Richtlinienkopf ein, um Mambas Ausgabetoken zu modellieren. Der Richtlinienkopf enthält zwei MLPs, die jeweils die Position und Richtung des Endeffektors lernen und insgesamt 0,1 % der gesamten Modellparameter belegen. Gemäß der vorherigen Arbeit where2act lautet die Verlustformel für Position und Richtung wie folgt:
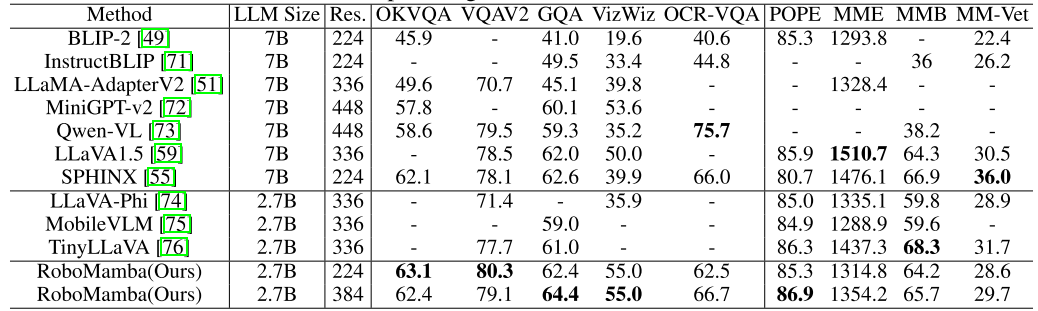
wobei N die Anzahl der Trainingsmuster darstellt und Tr (A) die Spur der Matrix A darstellt. RoboMamba sagt nur die 2D-Position (x, y) des Kontaktpixels im Bild voraus und wandelt es dann mithilfe von Tiefeninformationen in den 3D-Raum um. Um diese Feinabstimmungsstrategie zu bewerten, haben wir mithilfe von SAPIEN-Simulationen einen Datensatz mit 10.000 Endeffektor-Posenvorhersagen generiert. Nach der operativen Feinabstimmung haben wir festgestellt, dass RoboMamba, sobald es über ausreichende Denkfähigkeiten verfügt, durch äußerst effiziente Feinabstimmung Fähigkeiten zur Posenvorhersage erwerben kann. Aufgrund der minimalen Anzahl an Feinabstimmungsparametern (7 MB) und des effizienten Modelldesigns können wir in nur 20 Minuten neue betriebliche Fähigkeiten erlernen. Dieses Ergebnis unterstreicht die Bedeutung der Denkfähigkeit beim Erlernen operativer Fähigkeiten und schlägt eine neue Perspektive vor: Wir können MLLMs effizient mit operativen Fähigkeiten ausstatten, ohne ihre inhärenten Denkfähigkeiten zu beeinträchtigen. Schließlich kann RoboMamba Sprachantworten für gesunden Menschenverstand und roboterbezogenes Denken sowie einen Richtlinienkopf für die Vorhersage von Aktionsposen verwenden. 1. Bewertung der allgemeinen Denkfähigkeit (MLLM-Benchmarks) A, OCRVQA , VizWiz, POPE, MME, MMBench und MM-Vet.Darüber hinaus haben wir die roboterbezogenen Denkfähigkeiten von RoboMamba auch direkt anhand des 18.000-Verifizierungsdatensatzes von RoboVQA bewertet und dabei Roboteraufgaben wie Aufgabenplanung, veranlasste Aufgabenplanung, langfristige Aufgabenplanung, Manövrierfähigkeitsbeurteilung und Manövrierfähigkeit sowie frühere Beschreibungen abgedeckt Zukunftsprognose usw. Om Tabelle 1. Vergleich von Robomamba und dem bestehenden MLLMS bei mehreren Benchmarks.
Wie in Tabelle 1 gezeigt, vergleichen wir RoboMamba mit früherem State-of-the-Art (SOTA) MLLM auf gängiger VQA und aktuellen MLLM-Benchmarks. Erstens stellen wir fest, dass RoboMamba bei allen VQA-Benchmarks mit nur 2,7 Milliarden Sprachmodellen zufriedenstellende Ergebnisse erzielt. Die Ergebnisse zeigen, dass das einfache strukturelle Design effektiv ist. Ein abgestimmtes Pre-Training und Instruktions-Co-Training verbessern die Inferenzfähigkeiten von MLLM erheblich. Beispielsweise wird die räumliche Erkennungsleistung von RoboMamba beim GQA-Benchmark durch die Einführung großer Mengen an Roboterdaten in der kollaborativen Trainingsphase verbessert. In der Zwischenzeit haben wir unseren RoboMamba auch anhand des kürzlich vorgeschlagenen MLLM-Benchmarks getestet. Im Vergleich zu früheren MLLMs stellen wir fest, dass unser Modell bei allen Benchmarks wettbewerbsfähige Ergebnisse erzielt. Obwohl die Leistung von RoboMamba immer noch geringer ist als die des hochmodernen 7B MLLM (z. B. LLaVA1.5 und SPHINX), priorisieren wir den kleineren und schnelleren Mamba-2.7B, um die Effizienz des Robotermodells auszugleichen. In der Zukunft planen wir, RoboMamba-7B für ressourcenunabhängige Szenarien zu entwickeln. 2. Bewertung der Denkfähigkeit von Robotern (RoboVQA-Benchmark) Wir wählen LLaMA-AdapterV2 als Basislinie, da es das Basismodell für das aktuelle SOTA-Roboter-MLLM (ManipLLM) ist. Für einen fairen Vergleich haben wir die vorab trainierten LLaMA-AdapterV2-Parameter geladen und sie mithilfe der offiziellen Feinabstimmungsmethode für Anweisungen auf dem RoboVQA-Trainingssatz für zwei Epochen verfeinert. Wie in Abbildung 4 a dargestellt, erreicht RoboMamba eine überlegene Leistung zwischen BLEU-1 und BLEU-4. Die Ergebnisse zeigen, dass unser Modell über fortgeschrittene roboterbezogene Denkfähigkeiten verfügt und bestätigen die Wirksamkeit unserer Trainingsstrategie. Neben einer höheren Genauigkeit erreicht unser Modell bis zu siebenmal schnellere Inferenzgeschwindigkeiten als LLaMA-AdapterV2 und ManipLLM, was auf die inhaltsbewussten Inferenzfähigkeiten und die Effizienz des Mamba-Sprachmodells zurückzuführen ist. Abbildung 4. Vergleich der roboterbezogenen Argumentation bei RoboVQA. 3. Bewertung der Robotermanipulationsfähigkeit (SAPIEN) Vor dem Vergleich reproduzieren wir alle Basislinien und trainieren sie anhand des von uns gesammelten Datensatzes. Für UMPNet führen wir Operationen an vorhergesagten Kontaktpunkten durch, die senkrecht zur Objektoberfläche ausgerichtet sind. Flowbot3D sagt die Bewegungsrichtung in der Punktwolke voraus, wählt den größten Fluss als Interaktionspunkt und verwendet die Flussrichtung, um die Richtung des Endeffektors darzustellen. RoboFlamingo und ManipLLM laden die Pre-Training-Parameter von OpenFlamingo bzw. LLaMA-AdapterV2 und folgen ihren jeweiligen Feinabstimmungs- und Modellaktualisierungsstrategien. Wie in Tabelle 2 gezeigt, erreicht unser RoboMamba im Vergleich zum vorherigen SOTA ManipLLM eine Verbesserung von 7,0 % in der sichtbaren Kategorie und 2,0 % in der unsichtbaren Kategorie. Im Hinblick auf die Effizienz aktualisiert RoboFlamingo 35,5 % (1,8 Milliarden) der Modellparameter, ManipLLM aktualisiert Adapter in LLM (41,3 Millionen), die 0,5 % der Modellparameter enthalten, während unser fein abgestimmter Richtlinienkopf (3,7 Millionen) nur Modellparameter von 0,1 berücksichtigt %. RoboMamba aktualisiert 10x weniger Parameter als frühere MLLM-basierte Methoden und leitet gleichzeitig 7x schneller ab. Die Ergebnisse zeigen, dass unser RoboMamba nicht nur über starke Denkfähigkeiten verfügt, sondern auch Manipulationsfähigkeiten auf kostengünstige Weise erlangen kann. Tabelle 2. Vergleich der Erfolgsraten zwischen Robomamba und anderen Baselines
Wie in Abbildung 4 dargestellt, visualisieren wir die Inferenzergebnisse von RoboMamba in verschiedenen nachgelagerten Roboteraufgaben. Im Hinblick auf die Aufgabenplanung hat RoboMamba im Vergleich zu LLaMA-AdapterV2 aufgrund seiner leistungsstarken Argumentationsfähigkeiten genauere und längerfristige Planungsfähigkeiten bewiesen. Für einen fairen Vergleich optimieren wir auch den Basis-LLaMA-AdapterV2 im RoboVQA-Datensatz. Zur Vorhersage der Manipulationshaltung verwendeten wir einen Roboterarm von Franka Emika, um mit verschiedenen Haushaltsgegenständen zu interagieren. Wir projizieren die von RoboMamba vorhergesagte 3D-Pose auf ein 2D-Bild und verwenden dabei rote Punkte zur Darstellung von Kontaktpunkten und Endeffektoren zur Darstellung von Richtungen, wie in der unteren rechten Ecke der Abbildung dargestellt.
Das obige ist der detaillierte Inhalt vonDie Peking-Universität stellt neues multimodales Robotermodell vor! Effiziente Argumentation und Operationen für allgemeine und Roboterszenarien. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!





 für eine Frage
für eine Frage  . Wenn Sie beispielsweise mit einem Planungsproblem wie „Wie räume ich den Tisch ab?“ konfrontiert sind, umfassen die Antworten normalerweise Schritte wie „Schritt 1: Heben Sie den Gegenstand auf“ und „Schritt 2: Legen Sie den Gegenstand in die Kiste.“ Für die Aktionsvorhersage verwenden wir einen effizienten und einfachen Richtlinienkopf π, um Aktionen vorherzusagen
. Wenn Sie beispielsweise mit einem Planungsproblem wie „Wie räume ich den Tisch ab?“ konfrontiert sind, umfassen die Antworten normalerweise Schritte wie „Schritt 1: Heben Sie den Gegenstand auf“ und „Schritt 2: Legen Sie den Gegenstand in die Kiste.“ Für die Aktionsvorhersage verwenden wir einen effizienten und einfachen Richtlinienkopf π, um Aktionen vorherzusagen  . In Anlehnung an frühere Arbeiten verwenden wir 6-DoF, um die Endeffektor-Pose des Franka Emika Panda-Roboterarms auszudrücken. Zu den 6 Freiheitsgraden gehören die Endeffektorposition
. In Anlehnung an frühere Arbeiten verwenden wir 6-DoF, um die Endeffektor-Pose des Franka Emika Panda-Roboterarms auszudrücken. Zu den 6 Freiheitsgraden gehören die Endeffektorposition 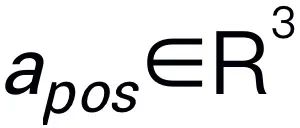 , die die dreidimensionalen Koordinaten darstellt, und die Richtung
, die die dreidimensionalen Koordinaten darstellt, und die Richtung  , die die Rotationsmatrix darstellt. Beim Training für eine Greifaufgabe fügen wir den Greifzustand zur Posenvorhersage hinzu und ermöglichen so eine 7-DoF-Steuerung.
, die die Rotationsmatrix darstellt. Beim Training für eine Greifaufgabe fügen wir den Greifzustand zur Posenvorhersage hinzu und ermöglichen so eine 7-DoF-Steuerung. 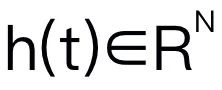 durch versteckte Zustände
durch versteckte Zustände 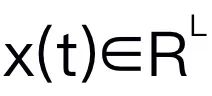 in eine 1D-Ausgabesequenz
in eine 1D-Ausgabesequenz  projiziert. SSM besteht aus drei Schlüsselparametern: Zustandsmatrix
projiziert. SSM besteht aus drei Schlüsselparametern: Zustandsmatrix  , Eingabematrix
, Eingabematrix  und Ausgabematrix
und Ausgabematrix  . Das SSM kann wie folgt ausgedrückt werden:
. Das SSM kann wie folgt ausgedrückt werden: 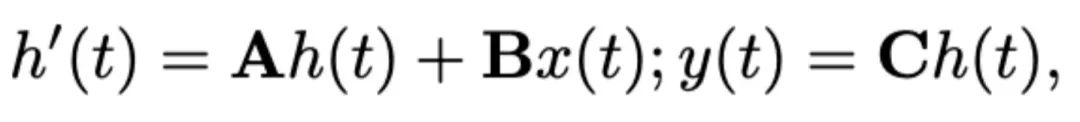
 und
und  um. Die Diskretisierung verwendet die Erhaltungsmethode nullter Ordnung, die wie folgt definiert ist:
um. Die Diskretisierung verwendet die Erhaltungsmethode nullter Ordnung, die wie folgt definiert ist: 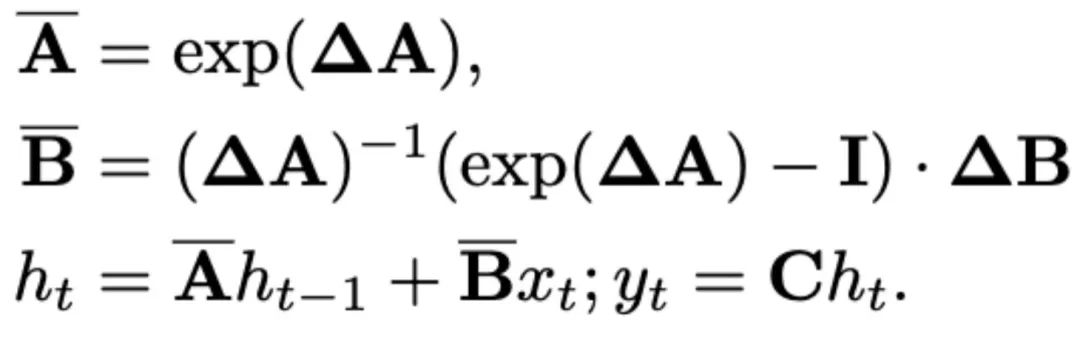
 aktualisiert. Die Details des Mamba-Blocks sind in Abbildung 3 unten dargestellt.
aktualisiert. Die Details des Mamba-Blocks sind in Abbildung 3 unten dargestellt. 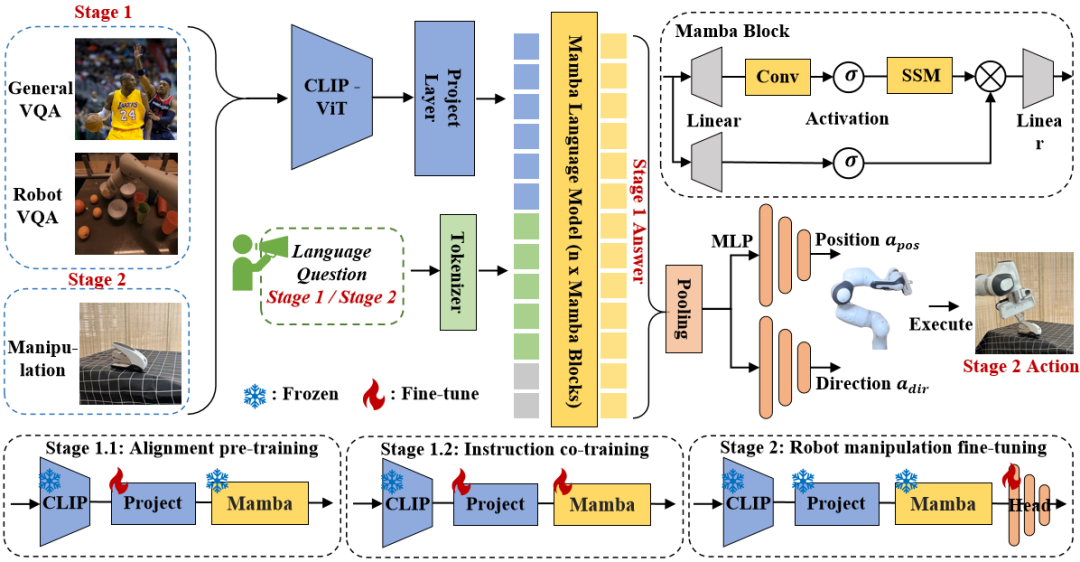
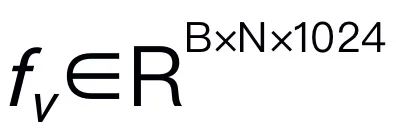 aus dem Eingabebild I zu extrahieren, wobei B und N die Stapelgröße bzw. die Anzahl der Token darstellen. Im Gegensatz zu neueren MLLMs verwenden wir keine visuellen Encoder-Ensemble-Techniken, die mehrere Backbone-Netzwerke (z. B. DINOv2, CLIP-ConvNeXt, CLIP-ViT) zur Extraktion von Bildmerkmalen verwenden. Durch die Integration entstehen zusätzliche Rechenkosten, was die Praktikabilität von robotischem MLLM in der realen Welt erheblich beeinträchtigt. Daher zeigen wir, dass einfaches und unkompliziertes Modelldesign auch leistungsstarke Inferenzfähigkeiten erreichen kann, wenn hochwertige Daten und geeignete Trainingsstrategien kombiniert werden. Damit das LLM visuelle Merkmale versteht, verwenden wir ein mehrschichtiges Perzeptron (MLP), um den visuellen Encoder mit dem LLM zu verbinden. Mit diesem einfachen modalübergreifenden Konnektor kann RoboMamba visuelle Informationen in einen Spracheinbettungsraum umwandeln
aus dem Eingabebild I zu extrahieren, wobei B und N die Stapelgröße bzw. die Anzahl der Token darstellen. Im Gegensatz zu neueren MLLMs verwenden wir keine visuellen Encoder-Ensemble-Techniken, die mehrere Backbone-Netzwerke (z. B. DINOv2, CLIP-ConvNeXt, CLIP-ViT) zur Extraktion von Bildmerkmalen verwenden. Durch die Integration entstehen zusätzliche Rechenkosten, was die Praktikabilität von robotischem MLLM in der realen Welt erheblich beeinträchtigt. Daher zeigen wir, dass einfaches und unkompliziertes Modelldesign auch leistungsstarke Inferenzfähigkeiten erreichen kann, wenn hochwertige Daten und geeignete Trainingsstrategien kombiniert werden. Damit das LLM visuelle Merkmale versteht, verwenden wir ein mehrschichtiges Perzeptron (MLP), um den visuellen Encoder mit dem LLM zu verbinden. Mit diesem einfachen modalübergreifenden Konnektor kann RoboMamba visuelle Informationen in einen Spracheinbettungsraum umwandeln 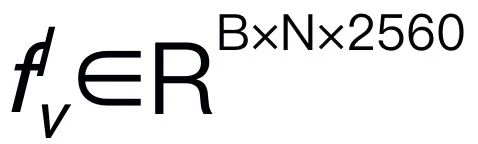 .
. 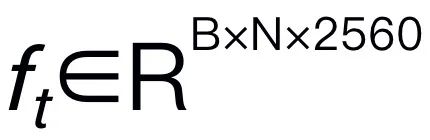 codiert, dann mit visuellen Token verkettet (Katze) und in Mamba eingespeist. Wir nutzen die leistungsstarke Sequenzmodellierung von Mamba, um multimodale Informationen zu verstehen und effektive Trainingsstrategien zu verwenden, um visuelle Denkfähigkeiten zu entwickeln (wie im nächsten Abschnitt beschrieben). Das Ausgabetoken (
codiert, dann mit visuellen Token verkettet (Katze) und in Mamba eingespeist. Wir nutzen die leistungsstarke Sequenzmodellierung von Mamba, um multimodale Informationen zu verstehen und effektive Trainingsstrategien zu verwenden, um visuelle Denkfähigkeiten zu entwickeln (wie im nächsten Abschnitt beschrieben). Das Ausgabetoken (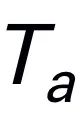 ) wird dann dekodiert (det), um eine Antwort in natürlicher Sprache zu generieren
) wird dann dekodiert (det), um eine Antwort in natürlicher Sprache zu generieren 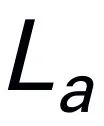 . Der Vorwärtsprozess des Modells kann wie folgt ausgedrückt werden:
. Der Vorwärtsprozess des Modells kann wie folgt ausgedrückt werden: 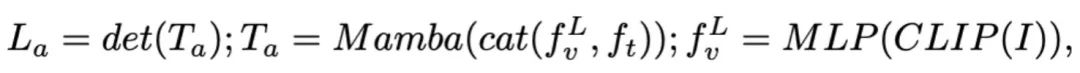



 So lösen Sie das Problem, dass die Datei msxml6.dll fehlt
So lösen Sie das Problem, dass die Datei msxml6.dll fehlt
 Verwendung von Telnet-Befehlen
Verwendung von Telnet-Befehlen
 cad2012 Seriennummer und Schlüsselübergabe
cad2012 Seriennummer und Schlüsselübergabe
 phpstudie
phpstudie
 So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
So kopieren Sie eine Excel-Tabelle, um sie auf die gleiche Größe wie das Original zu bringen
 Häufig verwendete Codes in der HTML-Sprache
Häufig verwendete Codes in der HTML-Sprache
 Was sind die Haupttechnologien von Firewalls?
Was sind die Haupttechnologien von Firewalls?
 So beheben Sie einen Analysefehler
So beheben Sie einen Analysefehler








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



