

Stellen Sie sich vor, wenn ein Roboter Ihre Bedürfnisse verstehen und hart arbeiten könnte, um sie zu erfüllen, wäre das nicht großartig?
Wenn Sie möchten, dass Ihnen ein Roboter hilft, müssen Sie normalerweise einen präziseren Befehl geben, aber die tatsächliche Umsetzung des Befehls ist möglicherweise nicht ideal. Wenn wir die reale Umgebung betrachten und der Roboter aufgefordert wird, ein bestimmtes Element zu finden, existiert das Element möglicherweise nicht tatsächlich in der aktuellen Umgebung und der Roboter kann es trotzdem nicht finden. Ist es jedoch möglich, dass es ein anderes Element in der Umgebung gibt? was mit dem Benutzer zusammenhängt? Hat der angeforderte Artikel ähnliche Funktionen und kann er auch die Bedürfnisse des Benutzers erfüllen? Dies ist der Vorteil der Verwendung von „Anforderungen“ als Aufgabenanweisungen.
Kürzlich hat das Team der Peking-Universität Dong Hao eine neue Navigationsaufgabe vorgeschlagen – Demand-driven Navigation (DDN), wurde von NeurIPS 2023 angenommen. Bei dieser Aufgabe muss der Roboter auf der Grundlage einer vom Benutzer gegebenen Bedarfsanweisung Artikel finden, die den Bedürfnissen des Benutzers entsprechen. Gleichzeitig schlug das Team von Dong Hao auch vor, die Attributeigenschaften von Artikeln auf der Grundlage von Nachfrageanweisungen zu lernen, was die Erfolgsquote des Roboters bei der Suche nach Artikeln effektiv verbesserte.

Papieradresse: https://arxiv.org/pdf/2309.08138.pdf
Projekthomepage: https://sites.google.com/view/demand-driven-navigation/home 
Benutzer müssen nur Anweisungen geben, die auf ihren eigenen Bedürfnissen basieren, ohne zu berücksichtigen, was sich in der Szene befindet.

Die Verwendung von Bedürfnissen als Anweisungen kann die Wahrscheinlichkeit erhöhen, dass Benutzerbedürfnisse erfüllt werden. Wenn Sie beispielsweise „Durst“ haben, haben die Aufforderung an den Roboter, „Tee“ zu finden, und die Aufforderung an den Roboter, „Gegenstände zu finden, die Ihren Durst stillen können“, im letzteren Fall offensichtlich einen größeren Anwendungsbereich.
Anforderungen, die in natürlicher Sprache beschrieben werden, haben einen größeren Beschreibungsraum und können präzisere und präzisere Anforderungen stellen.
Um einen solchen Roboter zu trainieren, ist es notwendig, eine Zuordnungsbeziehung zwischen Bedarfsanweisungen und Elementen herzustellen, damit die Umgebung Trainingssignale geben kann. Um die Kosten zu senken, schlug das Team von Dong Hao eine „halbautomatische“ Generierungsmethode vor, die auf einem großen Sprachmodell basiert: Verwenden Sie zunächst GPT-3.5, um Bedürfnisse zu generieren, die durch in der Szene vorhandene Elemente erfüllt werden können, und filtern Sie diese dann manuell heraus die den Anforderungen nicht genügen.
Wenn man bedenkt, dass Artikel, die die gleichen Bedürfnisse erfüllen können, ähnliche Attribute haben, scheint der Roboter in der Lage zu sein, diese Attributmerkmale zum Finden von Artikeln zu verwenden, wenn die Eigenschaften der Attribute solcher Artikel erlernt werden können. Beispielsweise sollten für die Anforderung „Ich habe Durst“ die erforderlichen Artikel das Attribut „Durst löschen“ haben und „Saft“ und „Tee“ beide dieses Attribut haben. Hierbei ist zu beachten, dass ein Gegenstand bei unterschiedlichen Bedürfnissen unterschiedliche Eigenschaften aufweisen kann. Beispielsweise kann „Wasser“ sowohl die Eigenschaft „Kleidung reinigen“ (unter der Anforderung „Kleidung waschen“) als auch die Eigenschaft „Kleidung waschen“ aufweisen. Durst löschen“ (unter der Voraussetzung „Ich habe Durst“).
Attribut-Lernphase
Wie kann man dem Modell also die Bedürfnisse „Durst löschen“ und „Kleidung reinigen“ verständlich machen? Es ist ein relativ stabiler gesunder Menschenverstand, die Attribute zu notieren, die Elemente unter bestimmten Anforderungen anzeigen. In den letzten Jahren, mit dem allmählichen Aufstieg großer Sprachmodelle (LLM), ist das von LLM demonstrierte Verständnis des gesunden Menschenverstandes der menschlichen Gesellschaft erstaunlich. Deshalb beschloss das Team der Peking-Universität Dong Hao, diesen gesunden Menschenverstand vom LLM zu lernen. Sie baten LLM zunächst, viele Nachfrageanweisungen zu generieren (in der Abbildung „Language-grounding Demand“ (LGD) genannt) und fragten dann LLM, welche Elemente diese Nachfrageanweisungen erfüllen können (in der Abbildung „Language-grounding Object“ (LGO) genannt).
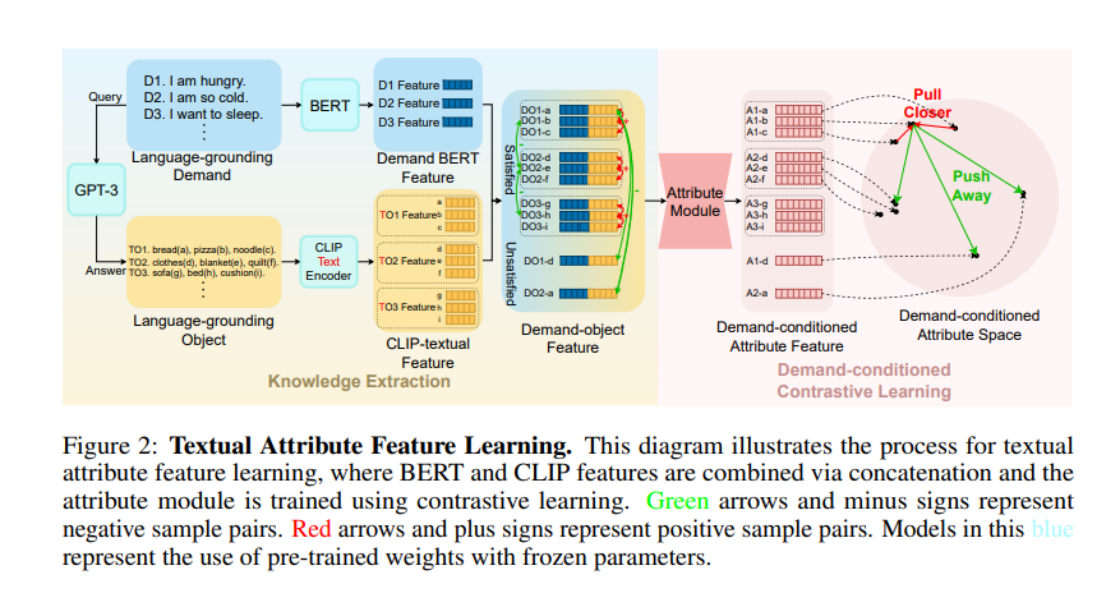
Hier ist zu beachten, dass das Präfix „Language-grounding“ betont, dass diese Nachfrage/Objekte von LLM bezogen werden können und nicht von einem bestimmten Szenario abhängt. „World-grounding“ in der folgenden Abbildung betont diese Nachfrage/Objekte eng in eine bestimmte Umgebung integriert (z. B. ProcThor, Replica und andere Szenendatensätze).
Um dann die Eigenschaften von LGO unter LGD zu erhalten, verwendeten die Autoren BERT zum Codieren von LGD, CLIP-Text-Encoder zum Codieren von LGO und fügten sie dann zusammen, um Demand-Object-Features zu erhalten. Die Autoren stellten fest, dass bei der Einführung der Attribute von Elementen zu Beginn eine „Ähnlichkeit“ bestand, nutzten diese Ähnlichkeit, um „positive und negative Stichproben“ zu definieren, und nutzten dann kontrastives Lernen, um die „Elementattribute“ zu trainieren. Insbesondere für zwei gespleißte Nachfrageobjekt-Features: Wenn die den beiden Features entsprechenden Elemente dieselben Anforderungen erfüllen können, sind die beiden Features positive Stichproben voneinander (z. B. sowohl Element a als auch Element b im Bild). kann die Anforderung D1 erfüllen, dann sind DO1-a und DO1-b positive Proben voneinander; alle anderen Spleißungen sind negative Proben voneinander. Nachdem die Autoren die Demand-Object-Features in ein Attributmodul der TransformerEncoder-Architektur eingegeben hatten, trainierten sie mit InfoNCE Loss.
Navigationsstrategie-Lernphase
Durch vergleichendes Lernen hat das Attributmodul den von LLM bereitgestellten gesunden Menschenverstand erlernt. In der Navigationsstrategie-Lernphase werden die Parameter des Attributmoduls direkt importiert, und dann wird der A*-Algorithmus importiert durch Nachahmungslernen gelernt. Zu einem bestimmten Zeitpunkt verwendet der Autor das DETR-Modell, um die Elemente im aktuellen Sichtfeld zu segmentieren, um das Welterdungsobjekt zu erhalten, das dann von CLIP-Visual-Endocer codiert wird. Andere Prozesse ähneln der Attributlernphase. Schließlich werden die BERT-Funktionen, globalen Bildfunktionen und Attributfunktionen der erforderlichen Anweisungen gespleißt, in ein Transformer-Modell eingespeist und schließlich eine Aktion ausgegeben.

Es ist erwähnenswert, dass die Autoren CLIP-Text-Encoder in der Attribut-Lernphase und in der Navigationsrichtlinien-Lernphase CLIP-Visual-Encoder verwendet haben. Hier werden die leistungsstarken visuellen und Textausrichtungsfähigkeiten des CLIP-Modells geschickt genutzt, um den von LLM gelernten gesunden Menschenverstand in jedem Zeitschritt auf die Vision zu übertragen.
Experimentelle Ergebnisse
Das Experiment wurde mit dem AI2Thor-Simulator und ProcThor-Datensätzen durchgeführt. Die experimentellen Ergebnisse zeigen, dass diese Methode deutlich besser ist als frühere Varianten verschiedener visueller Elementnavigationsalgorithmen und Algorithmen, die von großen Sprachmodellen unterstützt werden.

VTN ist ein Navigationsalgorithmus mit geschlossenem Vokabular, der Navigationsaufgaben nur für voreingestellte Elemente ausführen kann. Die Autoren haben einige Variationen seines Algorithmus vorgenommen. Unabhängig davon, ob die BERT-Funktionen der erforderlichen Anweisungen oder die GPT-Analyseergebnisse der Anweisungen als Eingabe verwendet werden, sind die Ergebnisse des Algorithmus nicht sehr ideal. Beim Wechsel zu ZSON, einem Navigationsalgorithmus mit offenem Vokabular, können verschiedene Varianten von ZSON aufgrund des schlechten Ausrichtungseffekts von CLIP zwischen Bedarfsanweisungen und Bildern nicht gut funktionieren. Einige auf heuristischer Suche + LLM basierende Algorithmen weisen jedoch aufgrund des großen Szenenbereichs des Procthor-Datensatzes eine geringe Explorationseffizienz auf und ihre Erfolgsquote ist nicht sehr hoch. Reine LLM-Algorithmen wie GPT-3-Prompt und MiniGPT-4 weisen schlechte Argumentationsfähigkeiten für unsichtbare Orte in der Szene auf, was dazu führt, dass Elemente, die den Anforderungen entsprechen, nicht effizient entdeckt werden können.
Ablationsexperimente zeigen, dass das Attributmodul die Navigationserfolgsrate erheblich verbessert. Die Autoren zeigen, dass das t-SNE-Diagramm gut zeigt, dass das Attributmodul die Attributmerkmale von Elementen durch nachfragebedingtes kontrastives Lernen erfolgreich lernt. Nach dem Ersetzen der Attributmodularchitektur durch MLP sank die Leistung, was darauf hindeutet, dass die TransformerEncoder-Architektur besser für die Erfassung von Attributmerkmalen geeignet ist. BERT kann die Eigenschaften erforderlicher Anweisungen gut extrahieren, was die Verallgemeinerung unsichtbarer Anweisungen verbessert.

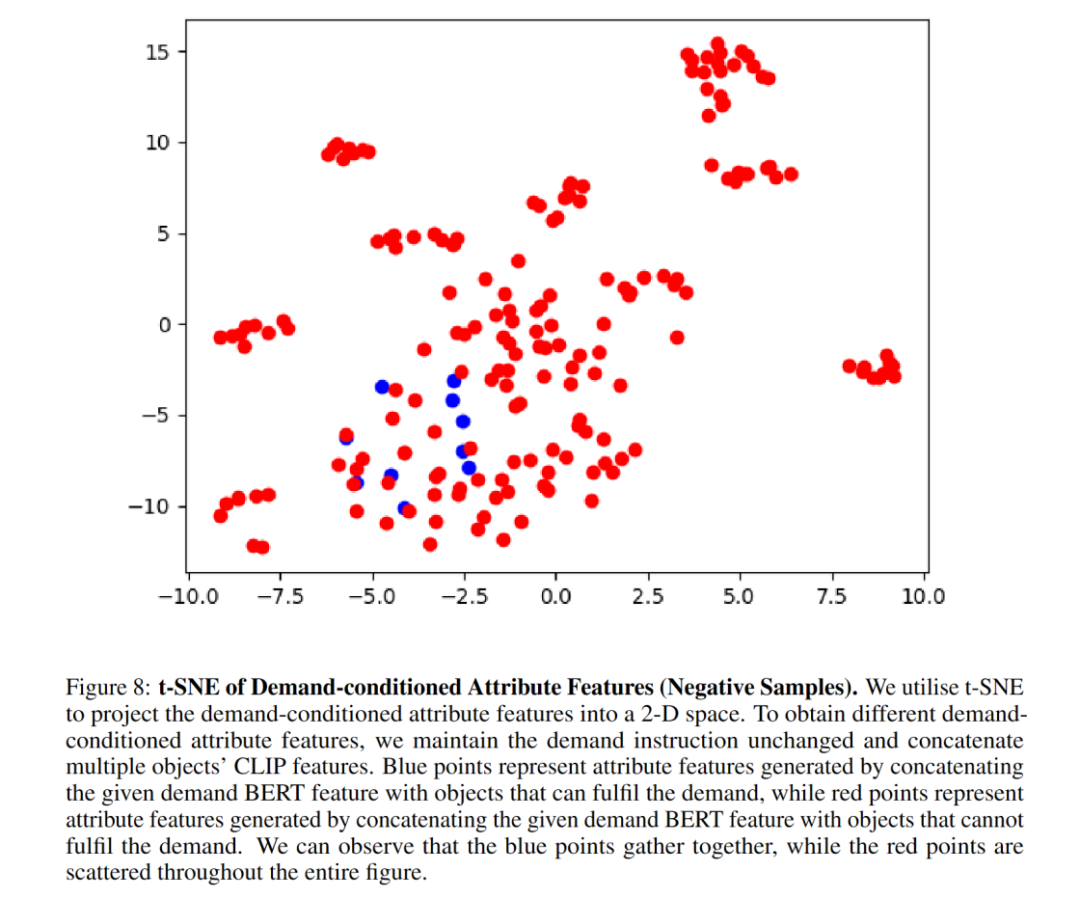
Hier einige Visualisierungen: 



Der entsprechende Autor dieser Studie, Dr. Dong Hao, ist derzeit Assistenzprofessor am Frontier Computing Research Center in Peking Als Doktorvater und Jugendwissenschaftler und Geisteswissenschaftler der Universität gründete und leitete er 2019 das Hyperplane Lab der Peking University. Er hat mehr als 40 Artikel auf führenden internationalen Konferenzen/Zeitschriften wie NeurIPS, ICLR, CVPR und ICCV veröffentlicht , ECCV usw. Google Scholar Es wurde mehr als 4.700 Mal zitiert und hat den ACM MM Best Open Source Software Award und den OpenI Outstanding Project Award gewonnen. Darüber hinaus war er viele Male als Field Chairman und stellvertretendes Redaktionsmitglied bei führenden internationalen Konferenzen wie NeurIPS, CVPR, AAAI und ICRA tätig, führte eine Reihe nationaler und provinzieller Projekte durch und leitete die New Generation des Ministeriums für Wissenschaft und Technologie Großprojekt Künstliche Intelligenz 2030.

Der Erstautor der Arbeit, Wang Hongzhen, ist derzeit Doktorand im zweiten Jahr an der Fakultät für Informatik der Universität Peking. Seine Forschungsinteressen konzentrieren sich auf Robotik, Computer Vision und Psychologie. Er hofft, von den Aspekten des menschlichen Verhaltens, der Kognition und der Motivation ausgehen zu können, um die Verbindung zwischen Menschen und Robotern in Einklang zu bringen. Links
Das obige ist der detaillierte Inhalt vonDas Embodied-Intelligence-Team der Peking-Universität schlägt eine bedarfsgesteuerte Navigation vor, um menschliche Bedürfnisse in Einklang zu bringen und Roboter effizienter zu machen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So löschen Sie eine Datenbank
So löschen Sie eine Datenbank
 Detaillierte Erläuterung der Quarzkonfigurationsdatei
Detaillierte Erläuterung der Quarzkonfigurationsdatei
 Was tun, wenn die CPU-Auslastung zu hoch ist?
Was tun, wenn die CPU-Auslastung zu hoch ist?
 Bitcoin-Handelsplattform
Bitcoin-Handelsplattform
 So überprüfen Sie die Mac-Adresse
So überprüfen Sie die Mac-Adresse
 Methode zur Wiederherstellung der Oracle-Datenbank
Methode zur Wiederherstellung der Oracle-Datenbank
 Die Rolle der mathematischen Funktion in der C-Sprache
Die Rolle der mathematischen Funktion in der C-Sprache
 Verwendung von while
Verwendung von while








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



