Kernkonzepte
- Primärschlüsselindex / Sekundärindex
- Clustered Index / Non-Clustered Index
- Tabellensuche/Indexabdeckung
- Index-Pushdown
- Zusammengesetzter Index/Präfixübereinstimmung ganz links
- Präfixindex
- Erklären Sie
1. [Indexdefinition]
1. Indexdefinition
Neben den Daten selbst verwaltet das Datenbanksystem auch Datenstrukturen, die bestimmte Suchalgorithmen erfüllen. Diese Strukturen verweisen (zeigen auf) die Daten auf eine bestimmte Art und Weise, sodass erweiterte Suchalgorithmen auf ihnen implementiert werden können. Diese Datenstrukturen sind Indizes.
2. Datenstrukturen von Indizes
- B-Baum / B+-Baum (Die InnoDB-Engine von MySQL verwendet den B+-Baum als Standardindexstruktur)
- HASH-Tabelle
- Sortiertes Array
3. Warum B+ Tree anstelle von B Tree wählen?
- B-Baumstruktur: Datensätze werden in den Baumknoten gespeichert.

- B+-Baumstruktur: Datensätze werden nur in den Blattknoten des Baums gespeichert.
- Unter der Annahme einer Datengröße von 1 KB und einer Indexgröße von 16 B, wobei die Datenbank Datenseiten auf der Festplatte verwendet und die Seitengröße der Standardfestplatte 16 KB beträgt, ergeben dieselben drei E/A-Vorgänge Folgendes:
B-Tree kann 16*16*16=4096 Datensätze abrufen.
B+-Baum kann 1000*1000*1000=1 MilliardeDatensätze abrufen.
2. [Indextypen]
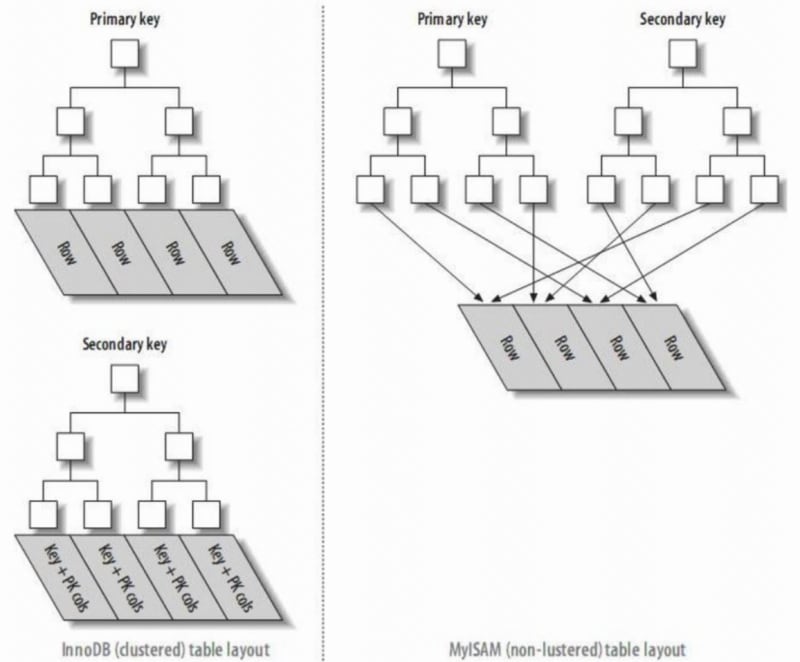
1. Primärschlüsselindex und Sekundärindex
-
Primärschlüsselindex: Die Blattknoten des Index sind Datenzeilen.
-
Sekundärer Index: Die Blattknoten des Index sind KEY-Felder plus Primärschlüsselindex. Daher findet InnoDB bei der Abfrage über einen Sekundärindex zuerst den Primärschlüsselwert und dann den entsprechenden Datenblock über den Primärschlüsselindex.
-
In InnoDB speichert die primäre Indexdatei direkt die Datenzeile, die als Clustered-Index bezeichnet wird, während sekundäre Indizes auf die Primärschlüsselreferenz verweisen.
-
In MyISAM verweisen sowohl Primär- als auch Sekundärindizes auf physische Zeilen (Festplattenpositionen).
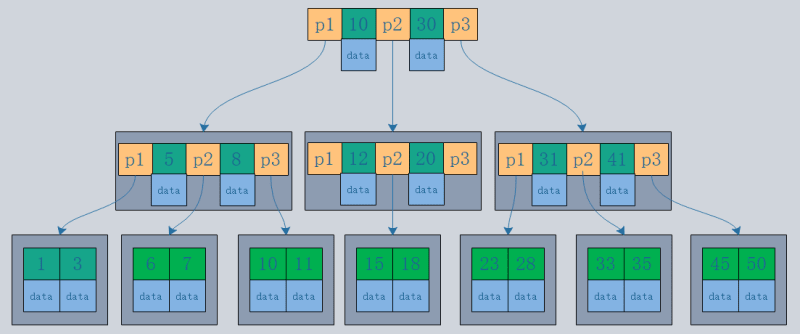
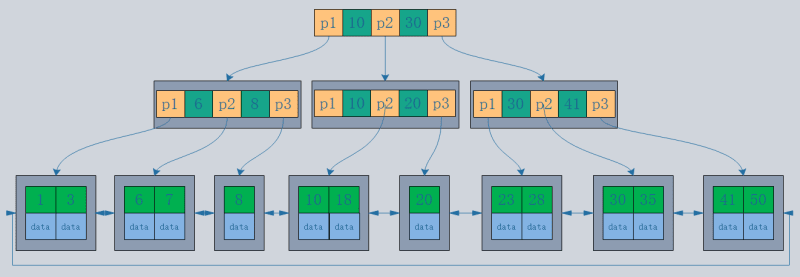
2. Clustered Index und Non-Clustered Index
- Ein Clustered-Index organisiert die tatsächlichen Daten auf der Festplatte neu, um sie nach einem oder mehreren angegebenen Spaltenwerten zu sortieren. Das Merkmal besteht darin, dass die Speicherreihenfolge der Daten und die Indexreihenfolge konsistent sind. Im Allgemeinen erstellt der Primärschlüssel standardmäßig einen Clustered-Index, und eine Tabelle lässt nur einen Clustered-Index zu (Grund: Daten können nur in einer Reihenfolge gespeichert werden). Wie im Bild gezeigt, sind die Primär- und Sekundärindizes von InnoDB Clustered-Indizes.
- Im Vergleich dazu, dass die Blattknoten eines Clustered-Index Datensätze sind, sind die Blattknoten eines Nicht-Clustered-Index Zeiger auf die Datensätze. Der größte Unterschied besteht darin, dass die Reihenfolge der Datensätze nicht mit der Indexreihenfolge übereinstimmt.
3. Vor- und Nachteile des Clustered Index
- Vorteil: Beim Abfragen von Einträgen nach Primärschlüssel muss keine Tabellensuche durchgeführt werden (die Daten befinden sich unter dem Primärschlüsselknoten).
- Nachteil: Bei unregelmäßiger Dateneinfügung kann es häufig zu Seitenteilungen kommen.
3. [Erweiterte Indexkonzepte]
1. Tabellensuche
Das Konzept der Tabellensuche beinhaltet den Unterschied zwischen Primärschlüsselindex- und Nicht-Primärschlüssel-Indexabfragen.
- Wenn die Abfrage „select * from T“ mit ID=500 ist, eine Primärschlüsselabfrage muss nur den ID-Baum durchsuchen.
- Wenn die Abfrage „select * from T“ ist, wobei k=5 ist, muss eine Nicht-Primärschlüssel-Indexabfrage zuerst den k-Indexbaum durchsuchen, um den ID-Wert 500 zu erhalten, und dann den ID-Indexbaum erneut durchsuchen.
- Der Vorgang des Übergangs vom Nicht-Primärschlüsselindex zurück zum Primärschlüsselindex wird als Tabellensuche bezeichnet.
Abfragen, die auf Nicht-Primärschlüsselindizes basieren, erfordern das Scannen eines zusätzlichen Indexbaums. Daher sollten wir versuchen, Primärschlüsselabfragen in Anwendungen zu verwenden. Da die Blattknoten des Nicht-Primärschlüssel-Indexbaums Primärschlüsselwerte speichern, ist es aus Sicht des Speicherplatzes ratsam, die Primärschlüsselfelder so kurz wie möglich zu halten. Auf diese Weise sind die Blattknoten des Nicht-Primärschlüssel-Indexbaums kleiner und der Nicht-Primärschlüssel-Index nimmt weniger Platz ein. Im Allgemeinen wird empfohlen, einen Primärschlüssel mit automatischer Inkrementierung zu erstellen, um den von Nicht-Primärschlüsselindizes belegten Platz zu minimieren.
2. Indexabdeckung
- Wenn eine WHERE-Klauselbedingung ein Nicht-Primärschlüsselindex ist, erst die Abfrage den Primärschlüsselindex über den Nicht-Primärschlüsselindex (der Primärschlüssel befindet sich an den Blattknoten des Nicht-Primärschlüssels). Schlüsselindex-Suchbaum) und suchen Sie dann den Abfrageinhalt über den Primärschlüsselindex. In diesem Prozess wird die Rückkehr zum Primärschlüssel-Indexbaum als Tabellensuche bezeichnet.
- Wenn jedoch unser Abfrageinhalt der Primärschlüsselwert ist, können wir das Abfrageergebnis direkt ohne Tabellensuche bereitstellen. Mit anderen Worten: Der Nicht-Primärschlüsselindex hat unsere Abfrageanforderung in dieser Abfrage bereits „abgedeckt“, daher wird er als abdeckender Index bezeichnet.
-
Ein abdeckender Index kann Abfrageergebnisse direkt vom Hilfsindex abrufen, ohne in der Tabelle nach dem Primärindex zu suchen, wodurch die Anzahl der Suchvorgänge reduziert (kein Wechsel vom Hilfsindexbaum zum Clustered-Indexbaum erforderlich) oder reduziert wird E/A-Vorgänge (der Hilfsindexbaum kann mehr Knoten gleichzeitig von der Festplatte laden) und dadurch die Leistung verbessern.
3. Zusammengesetzter Index
Ein zusammengesetzter Index bezieht sich auf die Indizierung mehrerer Spalten einer Tabelle.
Szenario 1:
Ein zusammengesetzter Index (a, b) wird sortiert nach a, b (zuerst sortiert nach a, wenn a gleich ist, dann sortiert nach b). Daher können die folgenden Anweisungen den zusammengesetzten Index direkt verwenden, um Ergebnisse zu erhalten (tatsächlich wird das Präfixprinzip ganz links verwendet):
- wählen Sie … aus xxx, wobei a=xxx;
- wählen Sie … aus xxx, wobei a=xxx, sortieren nach b;
Die folgenden Anweisungen können keine zusammengesetzten Abfragen verwenden:
- wählen Sie … aus xxx, wobei b=xxx;
Szenario 2:
Für einen zusammengesetzten Index (a, b, c) können die folgenden Anweisungen direkt Ergebnisse über den zusammengesetzten Index erhalten:
- wählen Sie … aus xxx, wobei a=xxx, sortieren nach b;
- wählen Sie … aus xxx, wobei a=xxx und b=xxx, sortiert nach c;
Die folgenden Anweisungen können den zusammengesetzten Index nicht verwenden und erfordern einen Dateisortierungsvorgang:
- wählen Sie … aus xxx, wobei a=xxx, sortieren nach c;
Zusammenfassung:
Am Beispiel des zusammengesetzten Indexes (a, b, c) ist die Erstellung eines solchen Indexes gleichbedeutend mit der Erstellung der Indizes a, ab und abc.Es ist sicherlich von Vorteil, wenn ein Index drei Indizes ersetzt. da jeder zusätzliche Index den Overhead der Schreibvorgänge und die Speicherplatznutzung erhöht.
4. Prinzip des Präfixes ganz links
- Aus dem obigen Beispiel für einen zusammengesetzten Index können wir das Prinzip des Präfixes ganz links verstehen.
-
Nicht nur die vollständige Definition des Index. Solange er das Präfix ganz links erfüllt, kann er zum Beschleunigen des Abrufs verwendet werden. Dieses Präfix ganz links kann aus den N Feldern ganz links des zusammengesetzten Index oder den M Zeichen ganz links des Zeichenfolgenindex bestehen. Verwenden Sie das Prinzip des „Präfix ganz links“ des Index, um Datensätze zu finden und redundante Indexdefinitionen zu vermeiden.
- Daher ist es beim Definieren zusammengesetzter Indizes wichtig, basierend auf dem Prinzip des ganz linken Präfixes, die Feldreihenfolge innerhalb des Index zu berücksichtigen! Das Bewertungskriterium ist die Wiederverwendbarkeit des Index. Wenn beispielsweise bereits ein Index für (a, b) vorhanden ist, besteht im Allgemeinen keine Notwendigkeit, einen separaten Index für a zu erstellen.
5. Index-Pushdown
MySQL 5.6 führte die Index-Pushdown-Optimierung ein, die Datensätze herausfiltern kann, die die Bedingungen basierend auf den im Index enthaltenen Feldern während der Indexdurchquerung nicht erfüllen, wodurch die Anzahl der Tabellensuchen reduziert wird.
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key',
`age` int(11) NOT NULL DEFAULT '0',
`name` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
Nach dem Login kopieren
-
SELECT * vom Benutzer, dessen Name wie „Chen%“ lautet. Präfixprinzip ganz links, Treffer idx_name_age index
-
SELECT * vom Benutzer mit Namen wie „Chen%“ und Alter=20
- Vor Version 5.6 wurden zuerst zwei Datensätze basierend auf dem Namensindex abgeglichen (wobei die Bedingung „Alter=20“ an dieser Stelle ignoriert wurde), die entsprechenden zwei IDs gesucht, Tabellensuchen durchgeführt und dann basierend auf Alter=20 gefiltert.
- Nach Version 5.6 wird Index-Pushdown eingeführt. Nach dem Abgleich von zwei Datensätzen basierend auf dem Namen wird die Bedingung „Alter = 20“ nicht ignoriert, bevor Tabellensuchen durchgeführt werden, und die Filterung basiert auf dem Alter vor der Tabellensuche. Dieser Index-Pushdown kann die Anzahl der Tabellensuchen reduzieren und die Abfrageleistung verbessern.
6. Präfixindex
Wenn ein Index eine lange Zeichenfolge ist, kann er viel Speicher beanspruchen und langsam sein. In diesem Fall können Präfixindizes verwendet werden. Anstatt den gesamten Wert zu indizieren, indizieren wir die ersten paar Zeichen, um Platz zu sparen und eine gute Leistung zu erzielen. Der Präfixindex verwendet die ersten paar Buchstaben des Index. Um jedoch die Indexduplizierungsrate zu reduzieren, müssen wir die Einzigartigkeit des Präfixindex bewerten.
- Berechnen Sie zunächst das Eindeutigkeitsverhältnis des aktuellen Zeichenfolgenfelds: Wählen Sie 1,0*Anzahl(eindeutiger Name)/Anzahl(*) aus dem Test aus
- Berechnen Sie dann das Eindeutigkeitsverhältnis für verschiedene Präfixe:
-
Wählen Sie 1.0*count(distinct left(name,1))/count(*) aus dem Test für das erste Zeichen des Namens als Präfixindex
-
Wählen Sie 1.0*count(distinct left(name,2))/count(*) from test für die ersten beiden Zeichen des Namens als Präfixindex
- ...
- Wenn left(str, n) nicht signifikant ansteigt, wählen Sie n als Grenzwert für den Präfixindex.
- Erstellen Sie den Index alter table test add key(name(n));
4. [Indizes anzeigen]
Wie sehen wir die Indizes nach dem Hinzufügen? Oder wie können wir Fehler beheben, wenn Anweisungen langsam ausgeführt werden?
Explain wird häufig verwendet, um zu überprüfen, ob ein Index effektiv ist.
Nachdem Sie das Protokoll für langsame Abfragen erhalten haben, beobachten Sie, welche Anweisungen langsam sind. Fügen Sie „explain“ vor der Anweisung hinzu und führen Sie sie erneut aus. Explain setzt ein Flag für die Abfrage, wodurch Informationen zu jedem Schritt im Ausführungsplan zurückgegeben werden, anstatt die Anweisung auszuführen. Es werden eine oder mehrere Informationszeilen zurückgegeben, die jeden Teil des Ausführungsplans und die Ausführung zeigen bestellen.
Wichtige Felder, die von EXPLAIN zurückgegeben werden:
-
Typ: Zeigt die Suchmethode an (vollständiger Tabellenscan oder Indexscan)
- Schlüssel: Das verwendete Indexfeld, null, wenn nicht verwendet
Explain's Typfeld:
- ALLE: Vollständiger Tabellenscan
- Index: Vollständiger Index-Scan
- Bereich: Indexbereichsscan
- ref: Nicht-eindeutiger Index-Scan
- eq_ref: Eindeutiger Index-Scan
Das obige ist der detaillierte Inhalt vonMySQL-Datenbankindex für Anfänger erklärt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


 So lösen Sie das Problem, dass die Datei msxml6.dll fehlt
So lösen Sie das Problem, dass die Datei msxml6.dll fehlt
 Was sind Umgebungsvariablen?
Was sind Umgebungsvariablen?
 Das neueste Ranking der Snapdragon-Prozessoren
Das neueste Ranking der Snapdragon-Prozessoren
 Einführung in den Inhalt der Java-Kerntechnologie
Einführung in den Inhalt der Java-Kerntechnologie
 So passen Sie die Helligkeit des Computerbildschirms an
So passen Sie die Helligkeit des Computerbildschirms an
 Was soll ich tun, wenn der Docker-Container nicht auf das externe Netzwerk zugreifen kann?
Was soll ich tun, wenn der Docker-Container nicht auf das externe Netzwerk zugreifen kann?
 Lösung für MySQL-Fehler 1171
Lösung für MySQL-Fehler 1171
 Offizielle Okex-Website
Offizielle Okex-Website








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



