
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
In den letzten Jahren hat die Anwendung multimodaler großer Sprachmodelle (MLLM) in verschiedenen Bereichen bemerkenswerte Erfolge erzielt. Als zugrunde liegendes Modell für viele nachgelagerte Aufgaben bestehen aktuelle MLLMs jedoch aus dem bekannten Transformer-Netzwerk, das eine weniger effiziente quadratische Rechenkomplexität aufweist. Um die Effizienz solcher Basismodelle zu verbessern, zeigen zahlreiche Experimente, dass: (1) Cobra eine äußerst wettbewerbsfähige Leistung mit den aktuellen hochmodernen Methoden mit hoher Recheneffizienz (z. B. LLaVA-Phi, TinyLLaVA) aufweist und MobileVLM v2) und aufgrund der linearen Sequenzmodellierung von Cobra, die schneller ist. (2) Interessanterweise zeigen die Ergebnisse des anspruchsvollen Vorhersage-Benchmarks für geschlossene Mengen, dass Cobra bei der Überwindung visueller Illusionen und der Beurteilung räumlicher Beziehungen gut abschneidet. (3) Es ist erwähnenswert, dass Cobra eine vergleichbare Leistung wie LLaVA erreicht, selbst wenn die Anzahl der Parameter nur etwa 43 % von LLaVA beträgt. Große Sprachmodelle (LLMs) sind darauf beschränkt, nur über Sprache zu interagieren, was ihre Anpassungsfähigkeit zur Bewältigung vielfältigerer Aufgaben einschränkt. Das multimodale Verständnis ist entscheidend, um die Fähigkeit eines Modells zu verbessern, reale Herausforderungen effektiv zu bewältigen. Daher arbeiten Forscher aktiv daran, große Sprachmodelle zu erweitern, um multimodale Informationsverarbeitungsfunktionen einzubeziehen. Visual-Language Models (VLMs) wie GPT-4, LLaMA-Adapter und LLaVA wurden entwickelt, um die visuellen Verständnisfähigkeiten von LLMs zu verbessern. Frühere Forschungen versuchten jedoch hauptsächlich, effiziente VLMs auf ähnliche Weise zu erhalten, d. h. durch Reduzieren der Parameter des grundlegenden Sprachmodells oder der Anzahl visueller Token, während die aufmerksamkeitsbasierte Transformer-Struktur unverändert blieb. In diesem Artikel wird eine andere Perspektive vorgeschlagen: Durch die direkte Verwendung des Zustandsraummodells (SSM) als Backbone-Netzwerk wird ein MLLM mit linearer Rechenkomplexität erhalten. Darüber hinaus untersucht und untersucht dieser Artikel verschiedene modale Fusionsschemata, um eine effektive multimodale Mamba zu schaffen. In diesem Artikel wird insbesondere das Mamba-Sprachmodell als Basismodell von VLM verwendet, das eine Leistung gezeigt hat, die mit dem Transformer-Sprachmodell konkurrieren kann, jedoch eine höhere Inferenzeffizienz aufweist. Tests zeigen, dass die Inferenzleistung von Cobra drei- bis viermal schneller ist als die von MobileVLM v2 3B und TinyLLaVA 3B mit der gleichen Parametergröße. Selbst im Vergleich zum LLaVA v1.5-Modell (7B-Parameter), das eine viel höhere Anzahl von Parametern aufweist, erreicht Cobra bei mehreren Benchmarks immer noch eine entsprechende Leistung mit etwa 43 % der Anzahl von Parametern.和 Die Hauptbeiträge von DEMO
dieser Artikel von Cobra und LLAVA V1.5 7B sind wie folgt:
- untersucht das Vorhandene multimodilica große Sprachmodelle (MLLMs) basieren häufig auf Transformer-Netzwerken, die eine quadratische Rechenkomplexität aufweisen. Um dieser Ineffizienz entgegenzuwirken, stellt dieser Artikel Cobra vor, ein neuartiges MLLM mit linearer Rechenkomplexität.
- Taucht in verschiedene modale Fusionsschemata ein, um die Integration visueller und sprachlicher Informationen im Mamba-Sprachmodell zu optimieren. Durch Experimente untersucht dieser Artikel die Wirksamkeit verschiedener Fusionsstrategien und bestimmt die Methode, die die effektivste multimodale Darstellung erzeugt.
- Es wurden umfangreiche Experimente durchgeführt, um die Leistung von Cobra mit parallelen Studien zu bewerten, die darauf abzielten, die Recheneffizienz des zugrunde liegenden MLLM zu verbessern. Bemerkenswert ist, dass Cobra auch mit weniger Parametern eine vergleichbare Leistung wie LLaVA erreicht, was seine Effizienz unterstreicht.
- Originallink: https://arxiv.org/pdf/2403.14520v2.pdf
- Projektlink: https://sites.google.com/view/cobravlm/
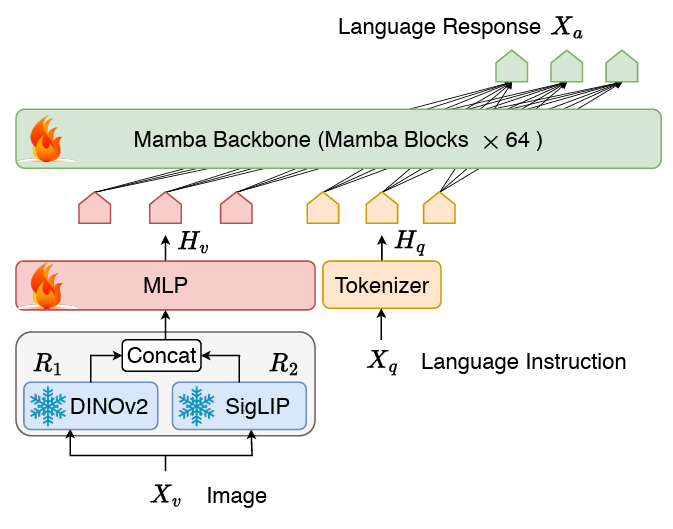
- Papiertitel: Cobra: Erweiterung von Mamba auf ein multimodales großes Sprachmodell für effiziente Inferenz LM-Struktur besteht aus einem Stateful-Projektor und dem LLM-Sprach-Backbone. Der Backbone-Teil von LLM verwendet das vorab trainierte Mamba-Sprachmodell mit 2,8B Parametern, das auf dem SlimPajama-Datensatz mit 600B-Tokens vorab trainiert und mit den Anweisungen der Konversationsdaten feinabgestimmt wurde.网络 Cobra-Netzwerkstrukturdiagramm
Anders als LLAVA usw. verwendet COBRA die visuelle Darstellung der Dinov2- und SIGLIP-Fusion, indem die Ausgabe der beiden visuellen Codierer zusammengefügt wird Semantische Merkmale auf hoher Ebene, die von SigLIP bereitgestellt werden, und die feinkörnigen Bildmerkmale auf niedriger Ebene, die von DINOv2 extrahiert werden. Trainingsschema
Neueste Untersuchungen zeigen, dass für bestehende Trainingsparadigmen, die auf LLaVA basieren (d. h. nur einmal die Vorausrichtungsphase der Projektionsschicht und die Feinabstimmungsphase des LLM-Backbones trainiert werden). In jedem Fall sind Vorausrichtungsschritte möglicherweise unnötig und das fein abgestimmte Modell ist möglicherweise immer noch unzureichend angepasst. Daher verzichtet Cobra auf die Vorausrichtungsphase und führt direkt eine Feinabstimmung des gesamten LLM-Sprach-Backbones und der Projektoren durch. Dieser Feinabstimmungsprozess wurde für zwei Epochen mit Zufallsstichproben an einem kombinierten Datensatz durchgeführt, bestehend aus:
Hybriddatensatz, der in LLaVA v1.5 verwendet wird und insgesamt 655.000 visuelle Multi-Turn-Gespräche enthält, einschließlich akademischer Gespräche VQA-Beispiele sowie visuelle Instruktionsoptimierungsdaten in LLaVA-Instruct und Klartext-Instruktionsoptimierungsdaten in ShareGPT. LVIS-Instruct-4V, das 220.000 Bilder mit visueller Ausrichtung und kontextbezogenen Anweisungen enthält, die von GPT-4V generiert wurden. LRV-Instruct, ein Datensatz mit 400.000 visuellen Anweisungen zu 16 visuellen Sprachaufgaben zur Linderung von Halluzinationsphänomenen.
Der gesamte Datensatz enthält etwa 1,2 Millionen Bilder und entsprechende mehrere Runden von Konversationsdaten sowie Klartext-Konversationsdaten.
Im experimentellen Teil vergleicht dieses Papier das vorgeschlagene Cobra-Modell und das Open-Source-SOTA-VLM-Modell anhand des Basis-Benchmarks und vergleicht es mit Das gleiche Die Größe basiert auf der Antwortgeschwindigkeit des VLM-Modells basierend auf der Transformer-Architektur. Gleichzeitig mit der Generierungsgeschwindigkeit und dem Leistungsvergleich des Diagramms bietet COBRA auch die vier offenen VQA-Aufgaben VQA-V2, GQA, Vizwiz, TextVQA und VSR sowie POPE zwei für eine geschlossene Satzvorhersageaufgabe Die Ergebnisse wurden bei insgesamt 6 Benchmarks verglichen. Der Vergleich der Karte auf dem Benchmark und anderen Open-Source-Modellen
Qualitativer Test
Darüber hinaus gibt Cobra auch zwei VQA-Beispiele an, um die Cobra im Objekt des Objekts qualitativ zu veranschaulichen. Überlegenheit in der Fähigkeit, räumliche Beziehungen zu erkennen und Modellillusionen zu reduzieren.和 Figure COBRA und andere Basismodelle bei der Beurteilung räumlicher Objektbeziehungen 和 Abbildung Cobra und andere Basismodelle im Beispiel der visuellen Illusion
In den Beispielen erhalten Llava V1.5 und Mobilevlm eine Fehlerantwort, während COBRA dies tut. Eine genaue Beschreibung wurde insbesondere im zweiten Fall gegeben. Cobra erkannte genau, dass das Bild aus der Simulationsumgebung des Roboters stammte.
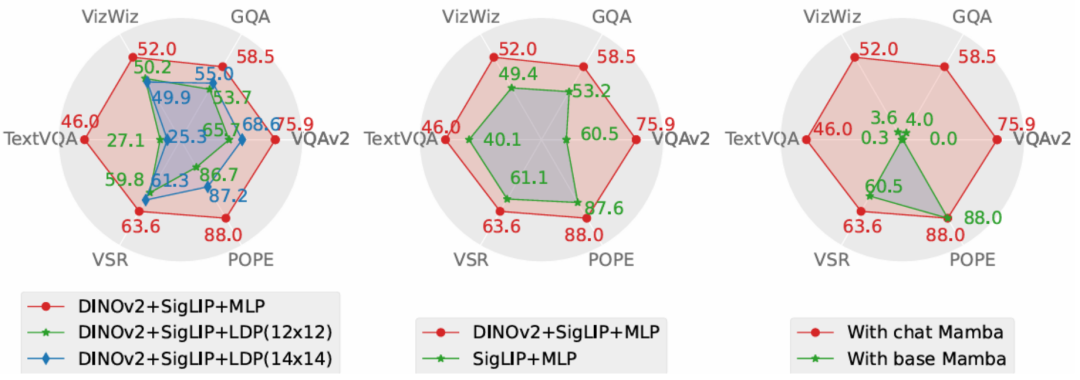
Dieser Artikel führt eine Ablationsforschung zu der von Cobra übernommenen Lösung aus den beiden Dimensionen Leistung und Erzeugungsgeschwindigkeit durch. Der Versuchsplan sieht Ablationsexperimente am Projektor, am visuellen Encoder und am LLM-Sprachrückgrat vor. Der Leistungsvergleich der Leistung des Diagrammablationsexperiments zeigt, dass die Ablationsexperimente des Projektteils des Projektors zeigen, dass die Wirkung des in diesem Artikel verwendeten MLP-Projektors deutlich besser ist als die, die der Reduzierung der Anzahl visueller Token auf das LDP gewidmet ist Da die Sequenzverarbeitungsgeschwindigkeit und die Rechenkomplexität von Cobra gleichzeitig besser sind als bei Transformer, hat das LDP-Modul keinen offensichtlichen Vorteil in der Generierungsgeschwindigkeit. Daher wird das Mamba-Klassenmodell verwendet, um die Anzahl der visuellen Token zu reduzieren durch Einbußen bei der Genauigkeit. Der Probenehmer ist möglicherweise nicht erforderlich.和 Abbildung COBRA und andere Modelle im Bereich des Generierungsgeschwindigkeitsvergleichs
Die Ablationsergebnisse des visuellen Encoder-Teils zeigen, dass die Fusion von Dinov2-Funktionen die Leistung von COBRA effektiv verbessert. Im Sprach-Backbone-Experiment war das Mamba-Sprachmodell ohne Feinabstimmung der Anweisungen überhaupt nicht in der Lage, im offenen Frage-Antwort-Test vernünftige Antworten zu geben, während das feinabgestimmte Mamba-Sprachmodell bei verschiedenen Aufgaben eine beachtliche Leistung erzielen kann.
Fazit
Dieses Papier schlägt Cobra vor, das den Effizienzengpass bestehender multimodaler Sprachmodelle im großen Maßstab löst, die auf Transformer-Netzwerken mit quadratischer Rechenkomplexität basieren. In diesem Artikel wird die Kombination von Sprachmodellen mit linearer Rechenkomplexität und multimodaler Eingabe untersucht. Im Hinblick auf die Verschmelzung visueller und sprachlicher Informationen optimiert dieser Artikel erfolgreich die interne Informationsintegration des Mamba-Sprachmodells und erreicht durch eingehende Forschung zu verschiedenen Modalfusionsschemata eine effektivere multimodale Darstellung. Experimente zeigen, dass Cobra nicht nur die Recheneffizienz erheblich verbessert, sondern auch in der Leistung mit fortgeschrittenen Modellen wie LLaVA vergleichbar ist, insbesondere bei der Überwindung visueller Illusionen und der Beurteilung räumlicher Beziehungen. Es reduziert sogar die Anzahl der Parameter erheblich. Dies eröffnet neue Möglichkeiten für den zukünftigen Einsatz leistungsstarker KI-Modelle in Umgebungen, die eine Hochfrequenzverarbeitung visueller Informationen erfordern, wie beispielsweise die visionsbasierte Roboter-Feedback-Steuerung.
Das obige ist der detaillierte Inhalt vonDas erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!






 Gründe, warum die Homepage nicht geändert werden kann
Gründe, warum die Homepage nicht geändert werden kann
 So lösen Sie das Problem der fehlenden Steam_api.dll
So lösen Sie das Problem der fehlenden Steam_api.dll
 Notebook mit zwei Grafikkarten
Notebook mit zwei Grafikkarten
 So importieren Sie ein altes Telefon von einem Huawei-Mobiltelefon in ein neues Telefon
So importieren Sie ein altes Telefon von einem Huawei-Mobiltelefon in ein neues Telefon
 Was ist Löwenzahn?
Was ist Löwenzahn?
 Python-Zeitstempel
Python-Zeitstempel
 Wo Sie Douyin-Live-Wiederholungen sehen können
Wo Sie Douyin-Live-Wiederholungen sehen können
 Was sind Endgeräte?
Was sind Endgeräte?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



