
 Backend-Entwicklung
Python-Tutorial
AdaBoost – Ensemble-Methode, Klassifizierung: Überwachtes maschinelles Lernen
Backend-Entwicklung
Python-Tutorial
AdaBoost – Ensemble-Methode, Klassifizierung: Überwachtes maschinelles Lernen
AdaBoost – Ensemble-Methode, Klassifizierung: Überwachtes maschinelles Lernen

Boosten
Definition und Zweck
Boosting ist eine Ensemble-Lerntechnik, die beim maschinellen Lernen verwendet wird, um die Genauigkeit von Modellen zu verbessern. Es kombiniert mehrere schwache Klassifikatoren (Modelle, die etwas besser abschneiden als zufällige Schätzungen), um einen starken Klassifikator zu erstellen. Der Hauptzweck des Boostens besteht darin, die schwachen Klassifikatoren nacheinander auf die Daten anzuwenden, die von den vorherigen Klassifikatoren gemachten Fehler zu korrigieren und so die Gesamtleistung zu verbessern.
Hauptziele:
- Genauigkeit verbessern: Verbessern Sie die Vorhersagegenauigkeit, indem Sie die Ausgaben mehrerer schwacher Klassifikatoren kombinieren.
- Verzerrung und Varianz reduzieren: Beheben Sie Probleme der Verzerrung und Varianz, um eine bessere Verallgemeinerung des Modells zu erreichen.
- Komplexe Daten verarbeiten: Komplexe Beziehungen in den Daten effektiv modellieren.
AdaBoost (Adaptives Boosting)
Definition und Zweck
AdaBoost, kurz für Adaptive Boosting, ist ein beliebter Boosting-Algorithmus. Es passt die Gewichte falsch klassifizierter Instanzen an, sodass sich nachfolgende Klassifikatoren stärker auf schwierige Fälle konzentrieren können. Der Hauptzweck von AdaBoost besteht darin, die Leistung schwacher Klassifikatoren zu verbessern, indem die schwer zu klassifizierenden Beispiele in jeder Iteration hervorgehoben werden.
Hauptziele:
- Gewichtungsanpassung: Erhöhen Sie die Gewichtung falsch klassifizierter Instanzen, um sicherzustellen, dass sich der nächste Klassifizierer auf sie konzentriert.
- Sequentielles Lernen: Klassifikatoren nacheinander erstellen, wobei jeder neue Klassifikator die Fehler seines Vorgängers korrigiert.
- Verbesserte Leistung: Kombinieren Sie schwache Klassifikatoren, um einen starken Klassifikator mit besserer Vorhersagekraft zu bilden.
So funktioniert AdaBoost
-
Gewichte initialisieren:
- Weisen Sie allen Trainingsinstanzen die gleiche Gewichtung zu. Bei einem Datensatz mit n Instanzen hat jede Instanz eine Gewichtung von 1/n.
-
Train Weak Classifier:
- Trainieren Sie einen schwachen Klassifikator mithilfe des gewichteten Datensatzes.
-
Klassifikatorfehler berechnen:
- Berechnen Sie den Fehler des schwachen Klassifikators, der die Summe der Gewichte falsch klassifizierter Instanzen ist.
-
Klassifikatorgewicht berechnen:
- Berechnen Sie das Gewicht des Klassifikators basierend auf seinem Fehler. Das Gewicht ergibt sich aus: Alpha = 0,5 * log((1 - Fehler) / Fehler)
- Ein geringerer Fehler führt zu einem höheren Klassifikatorgewicht.
-
Gewichtungen von Instanzen aktualisieren:
- Passen Sie die Gewichtungen der Instanzen an. Erhöhen Sie die Gewichtung falsch klassifizierter Instanzen und verringern Sie die Gewichtung korrekt klassifizierter Instanzen.
- Das aktualisierte Gewicht zum Beispiel ist: Gewicht[i] = Gewicht[i] * exp(alpha * (falsch klassifiziert ? 1 : -1))
- Normalisieren Sie die Gewichte, um sicherzustellen, dass sie in der Summe 1 ergeben.
-
Schwache Klassifikatoren kombinieren:
- Der endgültige starke Klassifikator ist eine gewichtete Summe der schwachen Klassifikatoren: Endgültiger Klassifikator = sign(sum(alpha * schwacher_Klassifikator))
- Die Vorzeichenfunktion bestimmt die Klassenbezeichnung basierend auf der Summe.
Beispiel für AdaBoost (Binäre Klassifizierung).
AdaBoost, kurz für Adaptive Boosting, ist eine Ensemble-Technik, die mehrere schwache Klassifikatoren kombiniert, um einen starken Klassifikator zu erstellen. Dieses Beispiel zeigt, wie Sie AdaBoost für die binäre Klassifizierung mithilfe synthetischer Daten implementieren, die Leistung des Modells bewerten und die Entscheidungsgrenze visualisieren.
Beispiel für einen Python-Code
1. Bibliotheken importieren
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
Dieser Block importiert die notwendigen Bibliotheken für Datenmanipulation, Darstellung und maschinelles Lernen.
2. Beispieldaten generieren
np.random.seed(42) # For reproducibility # Generate synthetic data for 2 classes n_samples = 1000 n_samples_per_class = n_samples // 2 # Class 0: Centered around (-1, -1) X0 = np.random.randn(n_samples_per_class, 2) * 0.7 + [-1, -1] # Class 1: Centered around (1, 1) X1 = np.random.randn(n_samples_per_class, 2) * 0.7 + [1, 1] # Combine the data X = np.vstack([X0, X1]) y = np.hstack([np.zeros(n_samples_per_class), np.ones(n_samples_per_class)]) # Shuffle the dataset shuffle_idx = np.random.permutation(n_samples) X, y = X[shuffle_idx], y[shuffle_idx]
Dieser Block generiert synthetische Daten mit zwei Funktionen, wobei die Zielvariable y basierend auf dem Klassenzentrum definiert wird und ein binäres Klassifizierungsszenario simuliert.
3. Teilen Sie den Datensatz auf
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Dieser Block teilt den Datensatz zur Modellbewertung in Trainings- und Testsätze auf.
4. Erstellen und trainieren Sie den AdaBoost-Klassifikator
base_estimator = DecisionTreeClassifier(max_depth=1) # Decision stump model = AdaBoostClassifier(estimator=base_estimator, n_estimators=3, random_state=42) model.fit(X_train, y_train)
Dieser Block initialisiert das AdaBoost-Modell mit einem Entscheidungsstumpf als Basisschätzer und trainiert es mithilfe des Trainingsdatensatzes.
5. Machen Sie Vorhersagen
y_pred = model.predict(X_test)
Dieser Block verwendet das trainierte Modell, um Vorhersagen zum Testsatz zu treffen.
6. Bewerten Sie das Modell
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
print("\nConfusion Matrix:")
print(conf_matrix)
print("\nClassification Report:")
print(class_report)
Ausgabe:
Accuracy: 0.9400
Confusion Matrix:
[[96 8]
[ 4 92]]
Classification Report:
precision recall f1-score support
0.0 0.96 0.92 0.94 104
1.0 0.92 0.96 0.94 96
accuracy 0.94 200
macro avg 0.94 0.94 0.94 200
weighted avg 0.94 0.94 0.94 200
Dieser Block berechnet und druckt die Genauigkeit, die Verwirrungsmatrix und den Klassifizierungsbericht und bietet Einblicke in die Leistung des Modells.
7. Visualisieren Sie die Entscheidungsgrenze
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z, alpha=0.4, cmap='RdYlBu')
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, cmap='RdYlBu', edgecolor='black')
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("AdaBoost Binary Classification")
plt.colorbar(scatter)
plt.show()
This block visualizes the decision boundary created by the AdaBoost model, illustrating how the model separates the two classes in the feature space.
Output:

This structured approach demonstrates how to implement and evaluate AdaBoost for binary classification tasks, providing a clear understanding of its capabilities. The visualization of the decision boundary aids in interpreting the model's predictions.
AdaBoost (Multiclass Classification) Example
AdaBoost is an ensemble learning technique that combines multiple weak classifiers to create a strong classifier. This example demonstrates how to implement AdaBoost for multiclass classification using synthetic data, evaluate the model's performance, and visualize the decision boundary for five classes.
Python Code Example
1. Import Libraries
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
This block imports the necessary libraries for data manipulation, plotting, and machine learning.
2. Generate Sample Data with 5 Classes
np.random.seed(42) # For reproducibility
n_samples = 2500 # Total number of samples
n_samples_per_class = n_samples // 5 # Ensure this is exactly n_samples // 5
# Class 0: Centered around (-2, -2)
X0 = np.random.randn(n_samples_per_class, 2) * 0.5 + [-2, -2]
# Class 1: Centered around (0, -2)
X1 = np.random.randn(n_samples_per_class, 2) * 0.5 + [0, -2]
# Class 2: Centered around (2, -2)
X2 = np.random.randn(n_samples_per_class, 2) * 0.5 + [2, -2]
# Class 3: Centered around (-1, 2)
X3 = np.random.randn(n_samples_per_class, 2) * 0.5 + [-1, 2]
# Class 4: Centered around (1, 2)
X4 = np.random.randn(n_samples_per_class, 2) * 0.5 + [1, 2]
# Combine the data
X = np.vstack([X0, X1, X2, X3, X4])
y = np.hstack([np.zeros(n_samples_per_class),
np.ones(n_samples_per_class),
np.full(n_samples_per_class, 2),
np.full(n_samples_per_class, 3),
np.full(n_samples_per_class, 4)])
# Shuffle the dataset
shuffle_idx = np.random.permutation(n_samples)
X, y = X[shuffle_idx], y[shuffle_idx]
This block generates synthetic data for five classes located in different regions of the feature space.
3. Split the Dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
This block splits the dataset into training and testing sets for model evaluation.
4. Create and Train the AdaBoost Classifier
base_estimator = DecisionTreeClassifier(max_depth=1) # Decision stump model = AdaBoostClassifier(estimator=base_estimator, n_estimators=10, random_state=42) model.fit(X_train, y_train)
This block initializes the AdaBoost classifier with a weak learner (decision stump) and trains it using the training dataset.
5. Make Predictions
y_pred = model.predict(X_test)
This block uses the trained model to make predictions on the test set.
6. Evaluate the Model
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
print("\nConfusion Matrix:")
print(conf_matrix)
print("\nClassification Report:")
print(class_report)
Output:
Accuracy: 0.9540
Confusion Matrix:
[[ 97 2 0 0 0]
[ 0 92 3 0 0]
[ 0 4 92 0 0]
[ 0 0 0 86 14]
[ 0 0 0 0 110]]
Classification Report:
precision recall f1-score support
0.0 1.00 0.98 0.99 99
1.0 0.94 0.97 0.95 95
2.0 0.97 0.96 0.96 96
3.0 1.00 0.86 0.92 100
4.0 0.89 1.00 0.94 110
accuracy 0.95 500
macro avg 0.96 0.95 0.95 500
weighted avg 0.96 0.95 0.95 500
This block calculates and prints the accuracy, confusion matrix, and classification report, providing insights into the model's performance.
7. Visualize the Decision Boundary
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(12, 10))
plt.contourf(xx, yy, Z, alpha=0.4, cmap='viridis')
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', edgecolor='black')
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("AdaBoost Multiclass Classification (5 Classes)")
plt.colorbar(scatter)
plt.show()
This block visualizes the decision boundaries created by the AdaBoost classifier, illustrating how the model separates the five classes in the feature space.
Output:
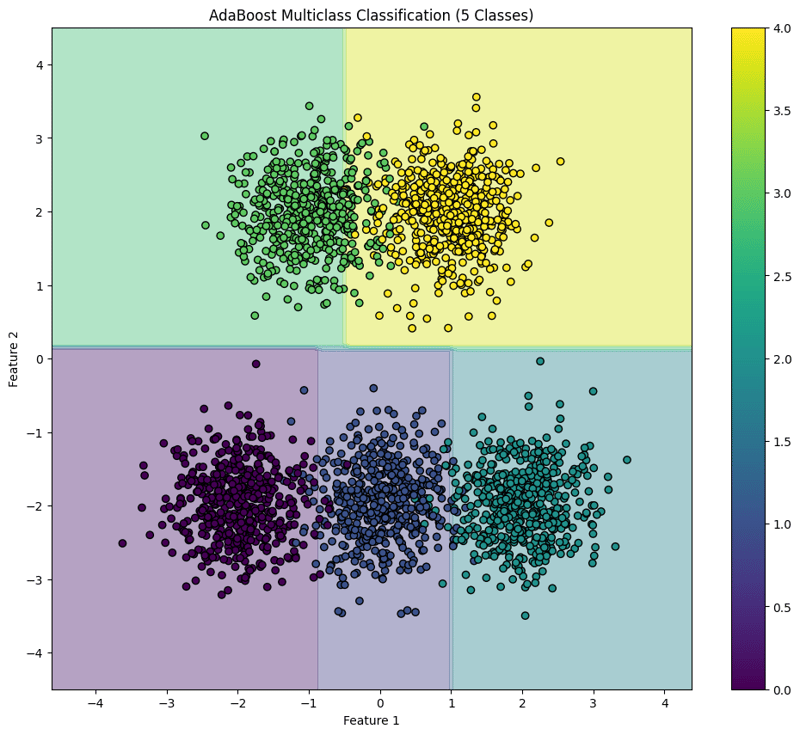
This structured approach demonstrates how to implement and evaluate AdaBoost for multiclass classification tasks, providing a clear understanding of its capabilities and the effectiveness of visualizing decision boundaries.
Das obige ist der detaillierte Inhalt vonAdaBoost – Ensemble-Methode, Klassifizierung: Überwachtes maschinelles Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1670
1670
 14
1428
52
1329
25
1276
29
1256
24
14
1428
52
1329
25
1276
29
1256
24

 Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python ist leichter zu lernen und zu verwenden, während C leistungsfähiger, aber komplexer ist. 1. Python -Syntax ist prägnant und für Anfänger geeignet. Durch die dynamische Tippen und die automatische Speicherverwaltung können Sie die Verwendung einfach zu verwenden, kann jedoch zur Laufzeitfehler führen. 2.C bietet Steuerung und erweiterte Funktionen auf niedrigem Niveau, geeignet für Hochleistungsanwendungen, hat jedoch einen hohen Lernschwellenwert und erfordert manuellem Speicher und Typensicherheitsmanagement.
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python ist in der Entwicklungseffizienz besser als C, aber C ist in der Ausführungsleistung höher. 1. Pythons prägnante Syntax und reiche Bibliotheken verbessern die Entwicklungseffizienz. 2. Die Kompilierungsmerkmale von Compilation und die Hardwarekontrolle verbessern die Ausführungsleistung. Bei einer Auswahl müssen Sie die Entwicklungsgeschwindigkeit und die Ausführungseffizienz basierend auf den Projektanforderungen abwägen.
 Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Ist es genug, um Python für zwei Stunden am Tag zu lernen? Es hängt von Ihren Zielen und Lernmethoden ab. 1) Entwickeln Sie einen klaren Lernplan, 2) Wählen Sie geeignete Lernressourcen und -methoden aus, 3) praktizieren und prüfen und konsolidieren Sie praktische Praxis und Überprüfung und konsolidieren Sie und Sie können die Grundkenntnisse und die erweiterten Funktionen von Python während dieser Zeit nach und nach beherrschen.
 Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python und C haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1) Python ist aufgrund seiner prägnanten Syntax und der dynamischen Typisierung für die schnelle Entwicklung und Datenverarbeitung geeignet. 2) C ist aufgrund seiner statischen Tipp- und manuellen Speicherverwaltung für hohe Leistung und Systemprogrammierung geeignet.
 Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
PythonlistsarePartThestandardlibrary, whilearraysarenot.listarebuilt-in, vielseitig und UNDUSEDFORSPORINGECollections, während dieArrayRay-thearrayModulei und loses und loses und losesaluseduetolimitedFunctionality.
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Zu den wichtigsten Anwendungen von Python in der Webentwicklung gehören die Verwendung von Django- und Flask -Frameworks, API -Entwicklung, Datenanalyse und Visualisierung, maschinelles Lernen und KI sowie Leistungsoptimierung. 1. Django und Flask Framework: Django eignet sich für die schnelle Entwicklung komplexer Anwendungen, und Flask eignet sich für kleine oder hochmobile Projekte. 2. API -Entwicklung: Verwenden Sie Flask oder Djangorestframework, um RESTFUFFUPI zu erstellen. 3. Datenanalyse und Visualisierung: Verwenden Sie Python, um Daten zu verarbeiten und über die Webschnittstelle anzuzeigen. 4. Maschinelles Lernen und KI: Python wird verwendet, um intelligente Webanwendungen zu erstellen. 5. Leistungsoptimierung: optimiert durch asynchrones Programmieren, Caching und Code
