

Ich bin kürzlich auf den Ju Data Engineering Newsletter von Julien Hurault zum Multi-Engine-Datenstapel gestoßen. Die Idee ist einfach; Wir möchten unseren Code problemlos über jedes Backend portieren und gleichzeitig die Flexibilität behalten, unsere Pipeline zu erweitern, wenn neue Backends und Funktionen entwickelt werden. Dies umfasst mindestens die folgenden übergeordneten Arbeitsabläufe:
In diesem Beitrag befassen wir uns damit, wie wir die Multi-Engine-Pipeline aus einer Programmiersprache implementieren können; Anstelle von SQL schlagen wir die Verwendung einer Dataframe-API vor, die sowohl für interaktive als auch für Batch-Anwendungsfälle verwendet werden kann. Konkret zeigen wir, wie wir unsere Pipeline in kleinere Teile aufteilen und diese über DuckDB, Pandas und Snowflake ausführen. Wir diskutieren auch die Vorteile eines Multi-Engine-Datenstapels und beleuchten neue Trends in diesem Bereich.
Der in diesem Beitrag implementierte Code ist auf GitHub verfügbar^[Um Repo schnell auszuprobieren, stelle ich auch einen Nix-Flake zur Verfügung]. Das Nachschlagewerk im Newsletter mit Originalumsetzung finden Sie hier.
Die Multi-Engine-Datenstack-Pipeline funktioniert wie folgt: Einige Daten landen in einem S3-Bucket, werden vorverarbeitet, um etwaige Duplikate zu entfernen, und dann in eine Snowflake-Tabelle geladen, wo sie mit ML oder Snowflake-spezifischen Funktionen weiter transformiert werden^[Bitte beachten Sie Wir gehen nicht auf die Implementierung der Dinge ein, die in Snowflake möglich sein könnten, und gehen davon aus, dass dies eine Voraussetzung für den Workflow ist.] Die Pipeline nimmt Aufträge als Parkettdateien entgegen, die am Zielort gespeichert, vorverarbeitet und dann am Staging-Standort in einem S3-Bucket gespeichert werden. Die Staging-Daten werden dann in Snowflake geladen, um nachgelagerte BI-Tools damit zu verbinden. Die Pipeline wird durch SQL DBT mit einem Modell für jedes Backend zusammengebunden und der Newsletter wählt Dagster als Orchestrierungstool.
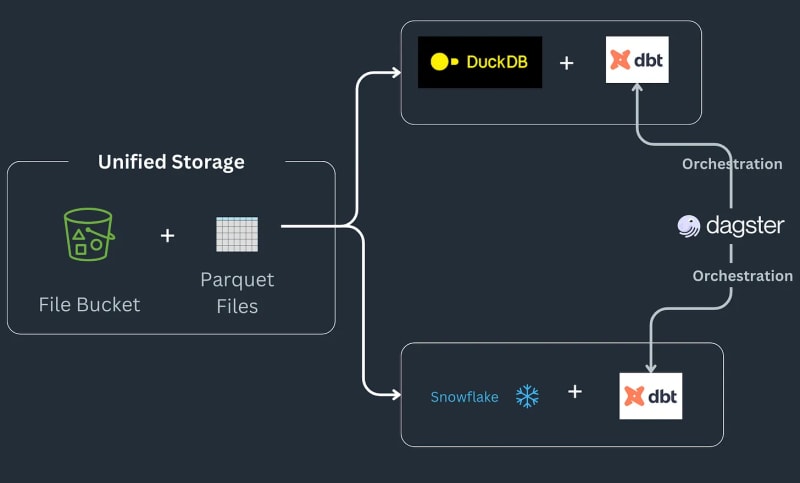
Heute werden wir uns damit befassen, wie wir unseren Pandas-Code in Ibis-Ausdrücke konvertieren können, indem wir das vollständige Beispiel für Julien Huraults Multi-Engine-Stack-Beispiel 1 reproduzieren. Anstatt dbt-Modelle und SQL zu verwenden, verwenden wir ibis und etwas Python, um SQL-Engines aus einer Shell zu kompilieren und zu orchestrieren. Indem wir unseren Code als Ibis-Ausdrücke umschreiben, können wir unsere Datenpipelines deklarativ mit verzögerter Ausführung erstellen. Darüber hinaus unterstützt Ibis über 20 Backends, sodass wir einmal Code schreiben und unsere ibis.exprs auf mehrere Backends portieren können. Zur weiteren Vereinfachung überlassen wir die von Dagster bereitgestellte Planung und Aufgabenorchestrierung2 dem Leser.
Hier sind die Kernkonzepte des Multi-Engine-Datenstapels, wie in Juliens Newsletter beschrieben:
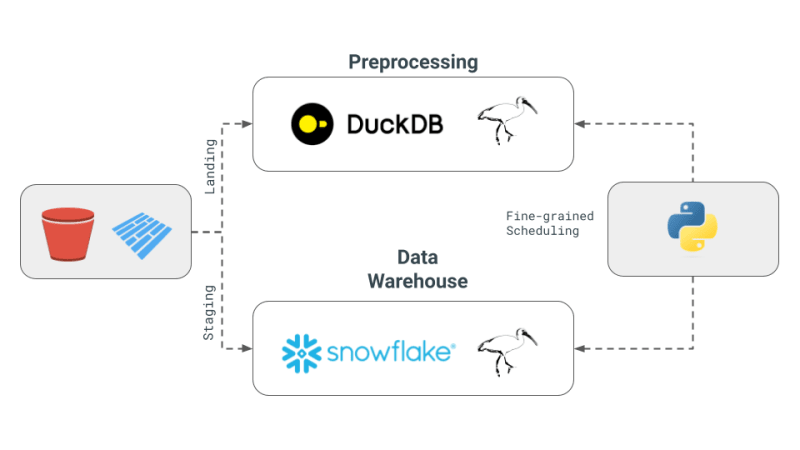
Während die obige Pipeline gut für ETL und ELT geeignet ist, möchten wir manchmal die Leistungsfähigkeit einer vollständigen Programmiersprache anstelle einer Abfragesprache wie SQL, z. B. Debuggen, Testen, komplexe UDFs usw. Für wissenschaftliche Untersuchungen ist interaktives Rechnen unerlässlich, da Datenwissenschaftler ihren Code schnell iterieren, die Ergebnisse visualisieren und Entscheidungen auf der Grundlage der Daten treffen müssen.
DataFrames sind eine solche Datenstruktur: DataFrames werden verwendet, um geordnete Daten zu verarbeiten und auf interaktive Weise Rechenoperationen darauf anzuwenden. Sie bieten die Flexibilität, große Datenmengen mit Operationen im SQL-Stil verarbeiten zu können, bieten aber auch eine Steuerung auf niedrigerer Ebene, um Änderungen auf Zellebene wie in Excel-Tabellen zu bearbeiten. Typischerweise wird erwartet, dass alle Daten im Speicher verarbeitet werden und normalerweise in den Speicher passen. Darüber hinaus erleichtern DataFrames den einfachen Wechsel zwischen verzögerten/Batch- und interaktiven Modi.
DataFrames zeichnen sich dadurch aus, dass sie Benutzern die Anwendung benutzerdefinierter Funktionen ermöglichen und einen Benutzer von den Einschränkungen von SQL befreien, d. h. Sie können jetzt Code wiederverwenden, Ihre Vorgänge testen und relationale Maschinen einfach für komplexe Vorgänge erweitern. DataFrames erleichtern auch den schnellen Übergang von der tabellarischen Darstellung von Daten zu Arrays und Tensoren, die von Bibliotheken für maschinelles Lernen erwartet werden.
Spezialisierte und prozessbegleitende Datenbanken, z.B. DuckDB für OLAP3 verwischt die Grenze zwischen einer Remote-Schwergewichtsdatenbank wie Snowflake und einer ergonomischen Bibliothek wie Pandas. Wir glauben, dass dies eine Gelegenheit ist, DataFrames die Verarbeitung von Daten zu ermöglichen, die größer als der Speicher sind, und gleichzeitig die Interaktivitätserwartungen und das Entwicklergefühl einer lokalen Python-Shell beizubehalten, sodass sich Daten, die größer als der Speicher sind, klein anfühlen.
Unsere Umsetzung konzentriert sich auf die 4 zuvor vorgestellten Konzepte:

Pandas ist die Quintessenz der DataFrame-Bibliothek und bietet möglicherweise die einfachste Möglichkeit, den oben genannten Workflow zu implementieren. Zunächst generieren wir Zufallsdaten aus der Umsetzung im Newsletter.
#| echo: false
import pandas as pd
from multi_engine_stack_ibis.generator import generate_random_data
generate_random_data("landing/orders.parquet")
df = pd.read_parquet("landing/orders.parquet")
deduped = df.drop_duplicates(["order_id", "dt"])
Die Pandas-Implementierung hat einen zwingenden Stil und ist so konzipiert, dass die Daten in den Speicher passen. Die Pandas-API ist mit all ihren Nuancen schwer bis hin zu SQL zu kompilieren und befindet sich größtenteils an einem besonderen Ort, an dem sie Python-Visualisierung, Plotten, maschinelles Lernen, KI und komplexe Verarbeitungsbibliotheken vereint.
pt.write_pandas(
conn,
deduped,
table_name="T_ORDERS",
auto_create_table=True,
quote_identifiers=False,
table_type="temporary"
)
Nach der Deduplizierung mit Pandas-Operatoren sind wir bereit, die Daten an Snowflake zu senden. Snowflake verfügt über eine Methode namens write_pandas, die für unseren Anwendungsfall nützlich ist.
Eine Einschränkung von Pandas besteht darin, dass es über eine eigene API verfügt, die sich nicht ganz auf die relationale Algebra abbilden lässt. Ibis ist eine solche Bibliothek, die buchstäblich von Leuten erstellt wurde, die Pandas entwickelt haben, um ein vernünftiges Ausdruckssystem bereitzustellen, das auf mehrere SQL-Backends abgebildet werden kann. Ibis lässt sich vom dplyr R-Paket inspirieren, um ein neues Ausdruckssystem zu erstellen, das problemlos auf die relationale Algebra zurückgeführt und somit in SQL kompiliert werden kann. Der Stil ist außerdem deklarativ und ermöglicht es uns, Optimierungen im Datenbankstil auf den gesamten logischen Plan oder den Ausdruck anzuwenden. Ibis ist eine Schlüsselkomponente für die Ermöglichung der Zusammensetzbarkeit, wie im hervorragenden zusammensetzbaren Kodex hervorgehoben.
#| echo: false
import pathlib
import ibis
import ibis.backends.pandas.executor
import ibis.expr.types.relations
from ibis import _
from multi_engine_stack_ibis.generator import generate_random_data
from multi_engine_stack_ibis.utils import (MyExecutor, checkpoint_parquet,
create_table_snowflake,
replace_unbound)
from multi_engine_stack_ibis.connections import make_ibis_snowflake_connection
ibis.backends.pandas.executor.PandasExecutor = MyExecutor
setattr(ibis.expr.types.relations.Table, "checkpoint_parquet", checkpoint_parquet)
setattr(
ibis.expr.types.relations.Table,
"create_table_snowflake",
create_table_snowflake,
)
ibis.set_backend("pandas")
p_staging = pathlib.Path("staging/staging.parquet")
p_landing = pathlib.Path("landing/orders.parquet")
snow_backend = make_ibis_snowflake_connection(database="MULTI_ENGINE", schema="PUBLIC", warehouse="COMPUTE_WH")
expr = (
ibis.read_parquet(p_landing)
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt]))
.filter(_.row_number == 0)
.checkpoint_parquet(p_staging)
.create_table_snowflake("T_ORDERS")
)
expr
Ibis Expression druckt sich als Plan aus, der dem traditionellen logischen Plan in Datenbanken ähnelt. Ein logischer Plan ist ein Baum relationaler Algebraoperatoren, der die durchzuführende Berechnung beschreibt. Dieser Plan wird dann vom Abfrageoptimierer optimiert und in einen physischen Plan umgewandelt, der vom Abfrageausführer ausgeführt wird. Ibis-Ausdrücke ähneln logischen Plänen darin, dass sie die auszuführende Berechnung beschreiben, aber nicht sofort ausgeführt werden. Stattdessen werden sie in SQL kompiliert und bei Bedarf im Backend ausgeführt. Logical Plan weist im Allgemeinen eine höhere Granularität auf als ein DAG, der von einem Task-Scheduling-Framework wie Dask erstellt wird. Theoretisch könnte dieser Plan bis auf Dasks DAG zusammengestellt werden.
While pandas is embedded and is just a pip install away, it still has much documented limitations with plenty of performance improvements left on the table. This is where the recent embedded databases like DuckDB fill the gap of packing the full punch of a SQL engine, with all of its optimizations and benefiting from years of research that is as easy to import as is pandas. In this world, at minimum we can delegate all relational and SQL parts of our pipeline in pandas to DuckDB and only get the processed data ready for complex user defined Python.
Now, we are ready to take our Ibisified code and compile our expression above to execute on arbitrary engines, to truly realize the write-once-run-anywhere paradigm: We have successfully decoupled our compute engine with the expression system describing our computation.
Let's break our expression above into smaller parts and have them run across DuckDB, pandas and Snowflake. Note that we are not doing anything once the data lands in Snowflake and just show that we can select the data. Instead, we are leaving that up to the user's imagination what is possible with Snowflake native features.
Notice our expression above is bound to the pandas backend. First, lets create an UnboundTable expression to not have to depend on a backend when writing our expressions.

schema = {
"user_id": "int64",
"dt": "timestamp",
"order_id": "string",
"quantity": "int64",
"purchase_price": "float64",
"sku": "string",
"row_number": "int64",
}
first_expr_for = (
ibis.table(schema, name="orders")
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt])
)
.filter(_.row_number == 0)
)
first_expr_for
Next, we replace the UnboundTable expression with the DuckDB backend and execute it with to_parquet method4. This step is covered by the checkpoint_parquet operator that we added to pandas backend above. Here is an excellent blog that discusses inserting data into Snowflake from any Ibis backend with to_pyarrow functionality.
data = pd.read_parquet("landing/orders.parquet")
duck_backend = ibis.duckdb.connect()
duck_backend.con.execute("CREATE TABLE orders as SELECT * from data")
bind_to_duckdb = replace_unbound(first_expr_for, duck_backend)
bind_to_duckdb.to_parquet(p_staging)
to_sql = ibis.to_sql(bind_to_duckdb)
print(to_sql)
Once the above step creates the de-duplicated table, we can then send data to Snowflake using the pandas backend. This functionality is covered by create_table_snowflake operator that we added to pandas backend above.
second_expr_for = ibis.table(schema, name="T_ORDERS") # nothing special just a reading the data from orders table
snow_backend.create_table("T_ORDERS", schema=second_expr_for.schema(), temp=True)
pandas_backend = ibis.pandas.connect({"T_ORDERS": pd.read_parquet(p_staging)})
snow_backend.insert("T_ORDERS", pandas_backend.to_pyarrow(second_expr_for))
Finally, we can select the data from the Snowflake table to verify that the data has been loaded successfully.
third_expr_for = ibis.table(schema, name="T_ORDERS") # add you Snowflake ML functions here third_expr_for
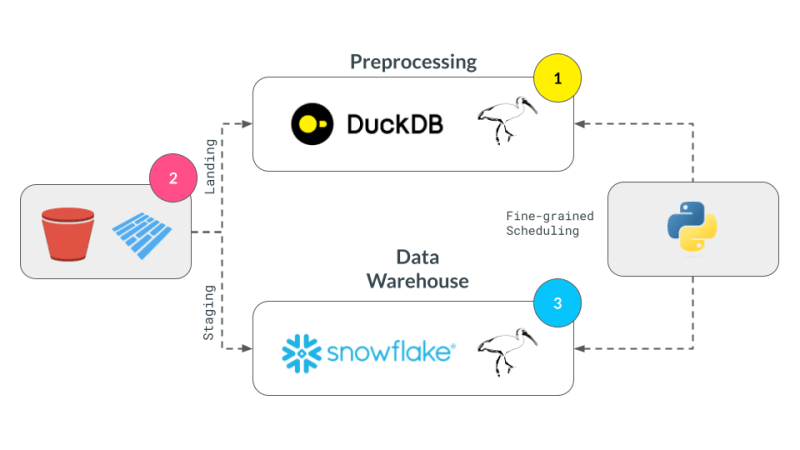
We successfully broke up our computation in pieces, albeit manually, and executed them across DuckDB, pandas, and Snowflake. This demonstrates the flexibility and power of a multi-engine data stack, allowing users to leverage the strengths of different engines to optimize their data processing pipelines.
I'd like to thank Neal Richardson, Dan Lovell and Daniel Mesejo for providing the initial feedback on the post. I highly appreciate the early review and encouragement by Wes McKinney.
In this post, we have primarily focused on v0 of the multi-engine data stack. In the latest version, Apache Iceberg is included as a storage and data format layer. NYC Taxi data is used instead of the random Orders data treated in this and v0 of the posts. ↩
Orchestration Vs fine-grained scheduling: ↩
Some of the examples of in-process databases is described in this post extending DuckDB example above to newer purpose built databases like LanceDB and KuzuDB. ↩
The Ibis docs use backend.to_pandas(expr) commands to bind and run the expression in the same go. Instead, we use replace_unbound method to show a generic way to just compile the expression and not execute it to said backend. This is just for illustration purposes. All the code below, uses the backend.to_pyarrow methods from here on. ↩
Das obige ist der detaillierte Inhalt vonDeklarativer Multi-Engine-Datenstapel mit Ibis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 RGB in hexadezimales RGB umwandeln
RGB in hexadezimales RGB umwandeln
 Was beinhalten E-Commerce-Plattformen?
Was beinhalten E-Commerce-Plattformen?
 orientdb
orientdb
 So beheben Sie den Fehler 0xc000409
So beheben Sie den Fehler 0xc000409
 Audiokomprimierung
Audiokomprimierung
 Was sind die CSS3-Gradienteneigenschaften?
Was sind die CSS3-Gradienteneigenschaften?
 Es gibt mehrere Möglichkeiten, die CSS-Position zu positionieren
Es gibt mehrere Möglichkeiten, die CSS-Position zu positionieren
 Wie man mit virtueller Währung handelt
Wie man mit virtueller Währung handelt
 So wechseln Sie die Einstellungen zwischen Huawei-Dual-Systemen
So wechseln Sie die Einstellungen zwischen Huawei-Dual-Systemen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



