
 Technologie-Peripheriegeräte
KI
Huawei GTS LocMoE+: MoE-Architektur mit hoher Skalierbarkeit und Affinität, geringer Overhead für aktives Routing
Technologie-Peripheriegeräte
KI
Huawei GTS LocMoE+: MoE-Architektur mit hoher Skalierbarkeit und Affinität, geringer Overhead für aktives Routing
Huawei GTS LocMoE+: MoE-Architektur mit hoher Skalierbarkeit und Affinität, geringer Overhead für aktives Routing


Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail zur Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Die Co-Autoren dieses Artikels sind Dr. Li Jing, Sun Zhijie und Dr. Lin Dachao. Die Hauptmitglieder sind vom GTS AI Computing Lab. Zu den Hauptforschungs- und Umsetzungsfeldern gehören LLM-Ausbildung und -Beschleunigung, KI-Ausbildungssicherung und Graph Computing.

Papierlink: https://arxiv.org/pdf/2406.00023



Au début de la formation du modèle, lorsque le la capacité du jeton de routage est insuffisante. Chaque fois que TCR est formé, il a une probabilité de réussite de la formation plus élevée que l'ECR et nécessite une plus grande capacité d'experts pour garantir que le jeton approprié est sélectionné. Dans la phase ultérieure de la formation du modèle, lorsque le routeur a une certaine capacité à allouer correctement les jetons, chaque fois qu'ECR est formé, il a une probabilité de réussite plus élevée que TCR. À ce stade, seule une capacité plus petite est. nécessaire pour sélectionner le jeton approprié.




Das obige ist der detaillierte Inhalt vonHuawei GTS LocMoE+: MoE-Architektur mit hoher Skalierbarkeit und Affinität, geringer Overhead für aktives Routing. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1674
1674
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Der beste Zeitpunkt, um die Huawei Mate 60-Serie, die neue KI-Eliminierung + Image-Upgrade zu kaufen und Herbstaktionen zu genießen
Aug 29, 2024 pm 03:33 PM
Der beste Zeitpunkt, um die Huawei Mate 60-Serie, die neue KI-Eliminierung + Image-Upgrade zu kaufen und Herbstaktionen zu genießen
Aug 29, 2024 pm 03:33 PM
Seitdem die Huawei Mate60-Serie letztes Jahr in den Handel kam, nutze ich persönlich das Mate60Pro als mein Haupttelefon. In fast einem Jahr wurde das Huawei Mate60Pro mehreren OTA-Upgrades unterzogen und das Gesamterlebnis wurde erheblich verbessert, sodass die Menschen das Gefühl haben, immer neu zu sein. So hat beispielsweise die Huawei Mate60-Serie kürzlich noch einmal ein deutliches Upgrade der Bildgebungsfunktionen erhalten. Erstens die neue KI-Eliminierungsfunktion, die Passanten und Schmutz auf intelligente Weise eliminieren und leere Bereiche automatisch ausfüllen kann. Zweitens wurden die Farbgenauigkeit und die Teleschärfe der Hauptkamera erheblich verbessert. Angesichts der Schulanfangssaison hat die Huawei Mate60-Serie auch eine Herbstaktion gestartet: Beim Kauf des Telefons erhalten Sie einen Rabatt von bis zu 800 Yuan, der Startpreis liegt bei nur 4.999 Yuan. Häufig verwendete und oft neue Produkte mit großem Wert
 Yu Chengdong gab bekannt, dass Huaweis Mobiltelefon mit dreifach faltbarem Bildschirm im September vorgestellt wird: Der Preis wird voraussichtlich nicht günstig sein
Aug 20, 2024 am 06:36 AM
Yu Chengdong gab bekannt, dass Huaweis Mobiltelefon mit dreifach faltbarem Bildschirm im September vorgestellt wird: Der Preis wird voraussichtlich nicht günstig sein
Aug 20, 2024 am 06:36 AM
Am 19. August veranstaltete Hongmeng in Shanghai eine Übergabezeremonie für die ersten Xiangjie S9-Besitzer. Huawei-Manager Yu Chengdong war persönlich anwesend und übergab die Fahrzeuge an die Besitzer. Vor Ort fragte ein Autobesitzer, der bereits Wenjie M5, M7 und M9 besaß, Yu Chengdong, wann er das Mobiltelefon mit dreifachem Bildschirm von Huawei kaufen könne, und antwortete, dass es nächsten Monat erhältlich sein würde. Fenyefenye Zuvor waren im Internet echte Aufnahmen von Huaweis Telefon mit dreifachem Display durchgesickert, was weit verbreitete Besorgnis erregte. Auf dem Bild zeigt das neue Telefon von Yu Chengdong eine außergewöhnliche visuelle Wirkung. Sein Bildschirm ist viel größer als der herkömmlicher Mobiltelefone mit Klappbildschirm. Es hat ein einzigartiges Design und ist kein Tablet, aber besser als ein Tablet. Oben auf der linken Seite befindet sich eine zentrale Lochkamera sowie ein undeutlich sichtbares Doppelfaltdesign. Es wird vermutet, dass die Seite des Telefons mit einem Stift ausgestattet ist. Diese Hinweise deuten alle darauf hin
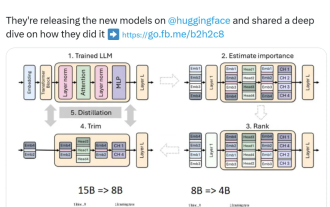 Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Aug 16, 2024 pm 04:42 PM
Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Aug 16, 2024 pm 04:42 PM
Der Aufstieg kleiner Modelle. Letzten Monat veröffentlichte Meta die Modellreihe Llama3.1, zu der das bisher größte Modell von Meta, das 405B-Modell, und zwei kleinere Modelle mit Parameterbeträgen von 70 Milliarden bzw. 8 Milliarden gehören. Llama3.1 gilt als der Beginn einer neuen Ära von Open Source. Obwohl die Modelle der neuen Generation leistungsstark sind, erfordern sie bei der Bereitstellung immer noch große Mengen an Rechenressourcen. Daher hat sich in der Branche ein weiterer Trend herausgebildet, der darin besteht, kleine Sprachmodelle (SLM) zu entwickeln, die bei vielen Sprachaufgaben eine ausreichende Leistung erbringen und zudem sehr kostengünstig in der Bereitstellung sind. Kürzlich haben Untersuchungen von NVIDIA gezeigt, dass durch strukturierte Gewichtsbereinigung in Kombination mit Wissensdestillation nach und nach kleinere Sprachmodelle aus einem zunächst größeren Modell gewonnen werden können. Turing-Preisträger, Meta Chief A
 Huawei wird das Xuanji-Sensorsystem im Bereich Smart Wearables auf den Markt bringen, das den emotionalen Zustand des Benutzers anhand der Herzfrequenz beurteilen kann
Aug 29, 2024 pm 03:30 PM
Huawei wird das Xuanji-Sensorsystem im Bereich Smart Wearables auf den Markt bringen, das den emotionalen Zustand des Benutzers anhand der Herzfrequenz beurteilen kann
Aug 29, 2024 pm 03:30 PM
Kürzlich gab Huawei bekannt, dass es im September ein neues intelligentes tragbares Produkt mit dem Xuanji-Sensorsystem auf den Markt bringen wird, bei dem es sich voraussichtlich um die neueste Smartwatch von Huawei handeln wird. Dieses neue Produkt wird fortschrittliche Funktionen zur Überwachung der emotionalen Gesundheit integrieren. Das Xuanji Perception System bietet Benutzern eine umfassende Gesundheitsbewertung mit seinen sechs Merkmalen – Genauigkeit, Vollständigkeit, Geschwindigkeit, Flexibilität, Offenheit und Skalierbarkeit. Das System nutzt ein Super-Sensing-Modul und optimiert die Mehrkanal-Optikpfad-Architekturtechnologie, wodurch die Überwachungsgenauigkeit grundlegender Indikatoren wie Herzfrequenz, Blutsauerstoff und Atemfrequenz erheblich verbessert wird. Darüber hinaus hat das Xuanji Sensing System auch die Erforschung emotionaler Zustände auf Basis von Herzfrequenzdaten erweitert. Es beschränkt sich nicht nur auf physiologische Indikatoren, sondern kann auch den emotionalen Zustand und das Stressniveau des Benutzers bewerten. Es unterstützt die Überwachung von mehr als 60 Sportarten Gesundheitsindikatoren, die kardiovaskuläre, respiratorische, neurologische, endokrine,
 Apple und Huawei wollten beide ein tastenloses Telefon entwickeln, aber Xiaomi hat es zuerst gemacht?
Aug 29, 2024 pm 03:33 PM
Apple und Huawei wollten beide ein tastenloses Telefon entwickeln, aber Xiaomi hat es zuerst gemacht?
Aug 29, 2024 pm 03:33 PM
Berichten von Smartprix zufolge entwickelt Xiaomi ein tastenloses Mobiltelefon mit dem Codenamen „Suzaku“. Dieser Nachricht zufolge wird dieses Mobiltelefon mit dem Codenamen Zhuque mit einem integrierten Konzept entwickelt, eine Kamera unter dem Bildschirm verwenden und mit einem Qualcomm Snapdragon 8gen4-Prozessor ausgestattet sein. Wenn sich der Plan nicht ändert, wird es wahrscheinlich im Jahr 2025 auf den Markt kommen . Als ich diese Nachricht sah, dachte ich, ich wäre im Jahr 2019 – damals brachte Xiaomi das Mi MIX Alpha-Konzepttelefon heraus und das tastenlose Surround-Screen-Design war ziemlich erstaunlich. Dies ist das erste Mal, dass ich den Charme eines tastenlosen Mobiltelefons sehe. Wenn Sie ein Stück „magisches Glas“ wollen, müssen Sie zuerst die Tasten töten. In „Die Biografie von Steve Jobs“ äußerte Jobs einmal seine Hoffnung, dass das Mobiltelefon wie ein Stück „magisches Glas“ sein könnte.
 Zum ersten Mal seit Jahrzehnten wurden Fortschritte erzielt, die Lehrlinge Tao Zhexuan und Zhao Yufei lösten kombinatorische Mathematikprobleme
Aug 15, 2024 pm 05:04 PM
Zum ersten Mal seit Jahrzehnten wurden Fortschritte erzielt, die Lehrlinge Tao Zhexuan und Zhao Yufei lösten kombinatorische Mathematikprobleme
Aug 15, 2024 pm 05:04 PM
Kürzlich wurden erstmals Fortschritte bei einem seit Jahrzehnten ungelösten mathematischen Rätsel erzielt. Treiber dieses Fortschritts sind James Leng, ein Doktorand an der UCLA, Ashwin Sah, ein Doktorand in Mathematik am MIT, und Mehtaab Sawhney, ein Assistenzprofessor an der Columbia University. Unter ihnen studierte James Leng bei dem berühmten Mathematiker Terence Tao und Ashwin Sah bei dem Meister der diskreten Mathematik Zhao Yufei. Papieradresse: https://arxiv.org/pdf/2402.17995 Um den Durchbruch zu verstehen, der in dieser Forschung erzielt wurde, müssen wir mit arithmetischen Progressionen beginnen. Die Summe der ersten n Terme einer arithmetischen Folge wird als arithmetische Reihe, auch Rechenreihe genannt, bezeichnet. Im Jahr 1936 gründete der Mathematiker Paul Erdő
 Neue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN
Sep 02, 2024 pm 01:41 PM
Neue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN
Sep 02, 2024 pm 01:41 PM
Der Schlüssel zum großen Erfolg von Transformer im Bereich Deep Learning ist der Aufmerksamkeitsmechanismus. Der Aufmerksamkeitsmechanismus ermöglicht es dem Transformer-basierten Modell, sich auf die Teile zu konzentrieren, die mit der Eingabesequenz zusammenhängen, und so ein besseres Kontextverständnis zu erreichen. Der Nachteil des Aufmerksamkeitsmechanismus besteht jedoch darin, dass der Rechenaufwand hoch ist, der quadratisch mit der Eingabegröße zunimmt, was es für den Transformer schwierig macht, sehr lange Texte zu verarbeiten. Vor einiger Zeit hat das Aufkommen von Mamba diese Situation durchbrochen und kann mit zunehmender Kontextlänge eine lineare Erweiterung erreichen. Mit der Veröffentlichung von Mamba können diese Zustandsraummodelle (SSM) Transformer in kleinen und mittleren Maßstäben erreichen oder sogar übertreffen und dabei die Ordnung aufrechterhalten.
 Der Preis des Mate 60 wird um 800 Yuan reduziert, und der Preis des Pura 70 wird um 1.000 Yuan reduziert: Warten Sie einfach, bis Huawei Mate 70 herausbringt!
Aug 16, 2024 pm 03:45 PM
Der Preis des Mate 60 wird um 800 Yuan reduziert, und der Preis des Pura 70 wird um 1.000 Yuan reduziert: Warten Sie einfach, bis Huawei Mate 70 herausbringt!
Aug 16, 2024 pm 03:45 PM
Laut Nachrichten vom 16. August wird für aktuelle Huawei-Handys bereits intensiv daran gearbeitet, den Weg für die Einführung neuer Modelle freizumachen, sodass jeder gesehen hat, wie die Preise für die Mate60-Serie und die Pura70-Serie nacheinander gesenkt wurden. Nachdem Huawei am 15. August offiziell Preissenkungen für die Mate60-Serie ankündigte, haben die neuesten Modelle der beiden Flaggschiff-Serien von Huawei die Preisanpassungen abgeschlossen. Im Juli dieses Jahres gab Huawei offiziell bekannt, dass die Huawei Pura70-Serie zum Verkauf angeboten wird, wobei die Preise um bis zu 1.000 Yuan gesenkt werden sollen. Unter anderem hat Huawei Pura70 einen direkten Rabatt von 500 Yuan, mit einem Startpreis von 4999 Yuan; Huawei Pura70 Beidou Satellite News Edition hat einen direkten Rabatt von 500 Yuan, mit einem Startpreis von 5099 Yuan; 800 Yuan, mit einem Startpreis von 5699 Yuan;
