

Die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.
Erinnern Sie sich an Stanfords KI-Stadt? Dies ist eine virtuelle Umgebung, die von KI-Forschern in Stanford erstellt wurde. In dieser kleinen Stadt leben, arbeiten, knüpfen und verlieben sich ganz normal 25 KI-Agenten. Jeder Agent hat seine eigene Persönlichkeit und Hintergrundgeschichte. Das Verhalten und das Gedächtnis des Agenten werden durch große Sprachmodelle gesteuert, die die Erfahrungen des Agenten speichern und abrufen und auf der Grundlage dieser Erinnerungen Aktionen planen. (Siehe „Stanfords „virtuelle Stadt“ ist Open Source: 25 KI-Agenten erhellen „Westworld““)
In ähnlicher Weise hat kürzlich eine Gruppe von Forschern des Shanghai Artificial Intelligence Laboratory OpenRobotLab und anderer Institutionen eine Gruppe von Forschern hat auch eine virtuelle Stadt geschaffen. Unter ihnen leben jedoch Roboter und NPCs.  Mit 100.000 interaktiven Szenen und 89 verschiedenen Szenenkategorien ist diese Stadt die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.
Mit 100.000 interaktiven Szenen und 89 verschiedenen Szenenkategorien ist diese Stadt die erste simulierte interaktive 3D-Gesellschaft, die speziell für verschiedene Roboter entwickelt wurde.

Die Autoren gaben an, dass sie diese Umgebung entworfen haben, um das Problem der Datenknappheit im Bereich der verkörperten Intelligenz zu lösen. Wie wir alle wissen, war die Erforschung des Skalierungsgesetzes im Bereich der verkörperten Intelligenz aufgrund der hohen Kosten für die Erhebung realer Daten schwierig. Daher wird das Simulation-to-Real-Paradigma (Sim2Real) zu einem entscheidenden Schritt bei der Erweiterung des verkörperten Modelllernens.
Die virtuelle Umgebung, die sie für Roboter entworfen haben, heißt GRUtopia. Das Projekt umfasst hauptsächlich:
1 Szenendatensatz. Enthält 100.000 interaktive, fein kommentierte Szenen, die frei zu Umgebungen im Stadtmaßstab kombiniert werden können. Im Gegensatz zu früheren Arbeiten, die sich hauptsächlich auf das Zuhause konzentrierten, deckt GRScenes 89 verschiedene Szenenkategorien ab und schließt damit die Lücke in serviceorientierten Umgebungen (in denen Roboter typischerweise zunächst eingesetzt werden).
2. GREinwohner. Hierbei handelt es sich um ein durch ein großes Sprachmodell (LLM) gesteuertes Nicht-Spieler-Charaktersystem (NPC), das für soziale Interaktion, Aufgabengenerierung und Aufgabenzuweisung verantwortlich ist und dadurch soziale Szenarien für verkörperte KI-Anwendungen simuliert.
3. Benchmark GRBench. Es werden verschiedene Roboter unterstützt, der Schwerpunkt liegt jedoch auf Beinrobotern als Hauptagenten, und es werden mittelschwere Aufgaben vorgeschlagen, die Objektlokalisierungsnavigation, soziale Lokalisierungsnavigation und Lokalisierungsmanipulation umfassen.
Die Autoren hoffen, dass diese Arbeit den Mangel an qualitativ hochwertigen Daten in diesem Bereich lindern und eine umfassendere Bewertung der verkörperten KI-Forschung ermöglichen wird.

Papiertitel: GRUtopia: Dream General Robots in a City at Scale
Papieradresse: https://arxiv.org/pdf/2407.10943
Projektadresse: https://github .com/OpenRobotLab/GRUtopia
GRScenes: Vollständig interaktive Umgebungen im großen Maßstab
Um eine Plattform für die Schulung und Bewertung verkörperter Agenten aufzubauen, ist eine vollständig interaktive Umgebung mit verschiedenen Szenen- und Objektressourcen ein Muss. Unverzichtbar. Daher haben die Autoren einen großen synthetischen 3D-Szenendatensatz gesammelt, der verschiedene Objektressourcen als Grundlage der GRUtopia-Plattform enthält.
Vielfältige, realistische Szenen
Aufgrund der begrenzten Anzahl und Kategorie von Open-Source-3D-Szenendaten sammelte der Autor zunächst etwa 100.000 hochwertige synthetische Szenen von Designer-Websites, um verschiedene Szenenprototypen zu erhalten. Anschließend bereinigten sie diese Szenenprototypen, kommentierten sie mit Semantik auf Regions- und Objektebene und kombinierten sie schließlich zu Städten, die als grundlegende Spielwiese des Roboters dienten.
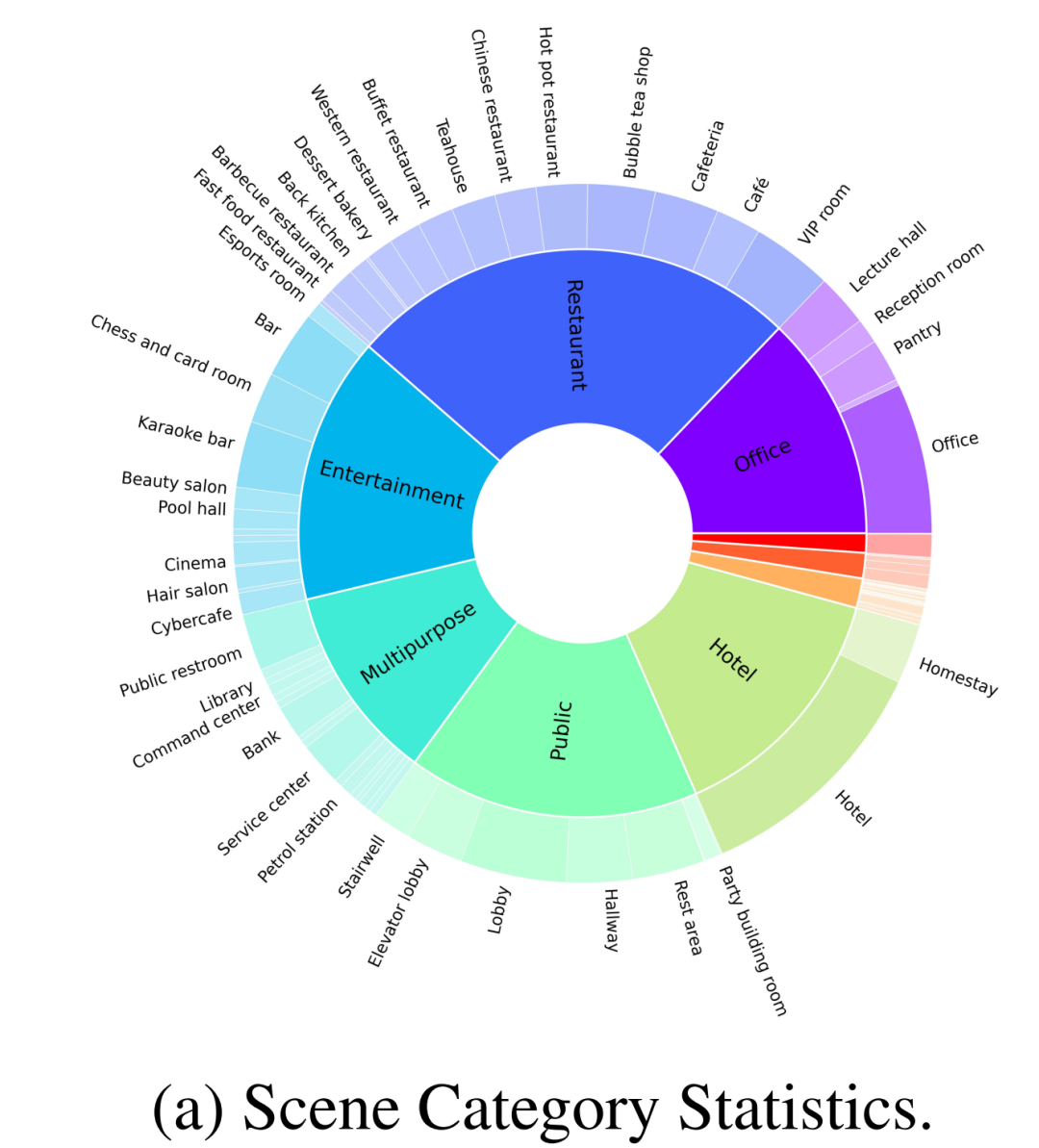
Wie in Abbildung 2-(a) gezeigt, enthält der vom Autor erstellte Datensatz zusätzlich zu gewöhnlichen Heimszenen auch 30 % anderer Szenenkategorien, wie z. B. Restaurants, Büros, öffentliche Orte, Hotels, Unterhaltung, usw. Die Autoren überprüften zunächst 100 fein kommentierte Szenen aus einem umfangreichen Datensatz für das Open-Source-Benchmarking. Diese 100 Szenen umfassen 70 Heimszenen und 30 Geschäftsszenen, wobei die Heimszene aus umfassenden Gemeinschaftsbereichen und anderen unterschiedlichen Bereichen besteht und die Geschäftsszenen gängige Typen wie Krankenhäuser, Supermärkte, Restaurants, Schulen, Bibliotheken und Büros abdecken.
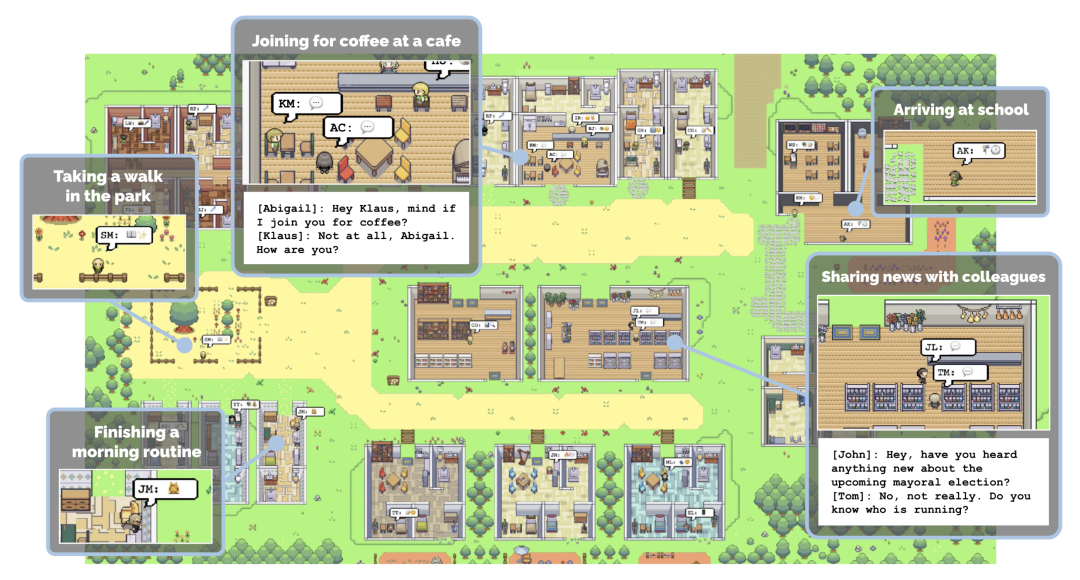
Darüber hinaus hat der Autor auch mit mehreren professionellen Designern zusammengearbeitet, um Objekte entsprechend den menschlichen Lebensgewohnheiten zuzuordnen, um diese Szenen realistischer zu gestalten, wie in Abbildung 1 dargestellt, was in früheren Arbeiten normalerweise ignoriert wird.
Interaktive Objekte mit Anmerkungen auf Teilebene
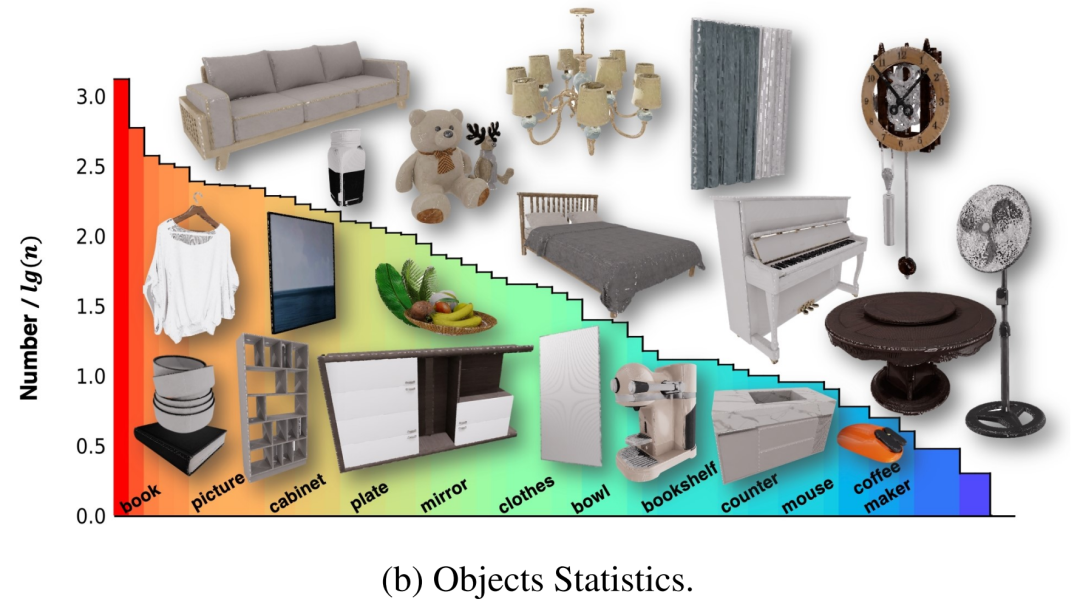
Diese Szenen enthielten ursprünglich mehrere 3D-Objekte, einige davon wurden jedoch nicht intern modelliert, sodass der Roboter nicht für die Interaktion mit diesen Objekten trainiert werden konnte. Um dieses Problem zu lösen, arbeiteten die Autoren mit einem Team von Fachleuten zusammen, um diese Assets zu modifizieren und vollständige Objekte zu erstellen, die es ihnen ermöglichten, auf physikalisch glaubwürdige Weise zu interagieren. Um umfassendere Informationen bereitzustellen, die es Agenten ermöglichen, mit diesen Assets zu interagieren, haben die Autoren den interaktiven Teilen aller Objekte in NVIDIA Omniverse außerdem fein abgestufte Teilbezeichnungen in Form eines X hinzugefügt. Schließlich enthalten die 100 Szenen 2956 interaktive Objekte und 22001 nicht interaktive Objekte in 96 Kategorien, und ihre Verteilung ist in Abbildung 2-(b) dargestellt.
Hierarchische multimodale Annotation
Um schließlich eine multimodale Interaktion verkörperter Agenten mit der Umgebung und dem NPC zu erreichen, müssen diese Szenen und Objekte auch sprachlich annotiert werden. Im Gegensatz zu früheren multimodalen 3D-Szenendatensätzen, die sich nur auf die Objektebene oder Beziehungen zwischen Objekten konzentrierten, berücksichtigten die Autoren auch unterschiedliche Granularitäten von Szenenelementen, beispielsweise die Beziehung zwischen Objekten und Regionen. Angesichts des Fehlens von Regionsbezeichnungen entwarfen die Autoren zunächst eine Benutzeroberfläche, um Regionen mit Polygonen in einer Vogelperspektive der Szene zu kommentieren, die dann Objekt-Region-Beziehungen in die sprachliche Annotation einbeziehen könnte. Für jedes Objekt veranlassen sie einen leistungsstarken VLM (z. B. GPT-4v) mit gerenderten Multi-View-Bildern, um Anmerkungen zu initialisieren, die dann von Menschen überprüft werden. Die resultierenden linguistischen Anmerkungen bilden die Grundlage für nachfolgende verkörperte Aufgaben zur Benchmark-Generierung.
GRResidents3D-Umgebung generative NPCs
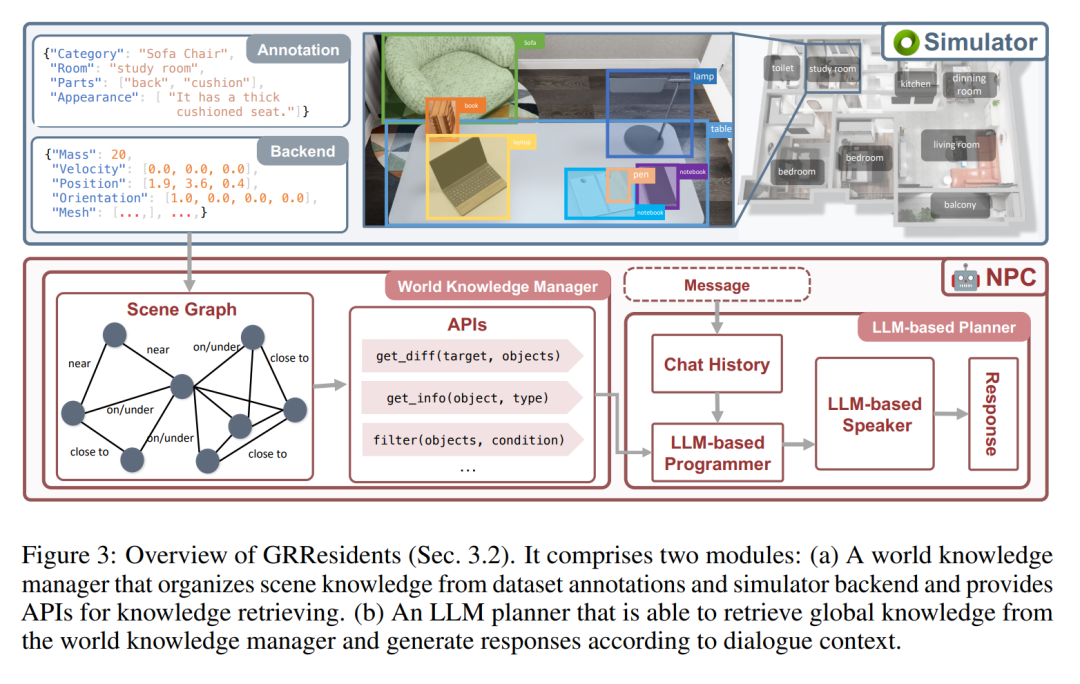
In GRUtopia verleiht der Autor der Welt soziale Fähigkeiten, indem er einige „Bewohner“ (d. h. generative NPCs, die von LLM gesteuert werden) einbettet, um soziale Interaktionen in städtischen Umgebungen zu simulieren. Dieses NPC-System trägt den Namen GRResidents. Eine der größten Herausforderungen beim Aufbau realistischer virtueller Charaktere in 3D-Szenen ist die Integration von 3D-Wahrnehmungsfunktionen. Virtuelle Charaktere können jedoch problemlos auf Szenenanmerkungen und den internen Zustand der simulierten Welt zugreifen, was leistungsstarke Wahrnehmungsfähigkeiten ermöglicht. Zu diesem Zweck haben die Autoren einen World Knowledge Manager (WKM) entworfen, um dynamisches Wissen über Echtzeit-Weltzustände zu verwalten und den Zugriff über eine Reihe von Datenschnittstellen zu ermöglichen. Mit WKM können NPCs das erforderliche Wissen abrufen und durch parametrisierte Funktionsaufrufe eine feinkörnige Objekterdung durchführen, die den Kern ihrer Empfindungsfähigkeiten bildet.
World Knowledge Manager (WKM)
Die Hauptaufgabe von WKM besteht darin, das Wissen über virtuelle Umgebungen kontinuierlich zu verwalten und NPCs erweitertes Szenenwissen bereitzustellen. Konkret ruft WKM hierarchische Anmerkungen und Szenenwissen aus dem Datensatz bzw. dem Simulator-Backend ab und erstellt einen Szenengraphen als Szenendarstellung, wobei jeder Knoten eine Objektinstanz darstellt und Kanten räumliche Beziehungen zwischen Objekten darstellen. Die Autoren übernehmen die in Sr3D definierten räumlichen Beziehungen als relationalen Raum. WKM behält dieses Szenendiagramm bei jedem Simulationsschritt bei. Darüber hinaus bietet WKM auch drei Kerndatenschnittstellen zum Extrahieren von Wissen aus Szenendiagrammen:
1, find_diff (Ziel, Objekte): vergleicht den Unterschied zwischen dem Zielobjekt und einer Reihe anderer Objekte;
2, get_info (Objekt, Typ): Objektwissen entsprechend dem erforderlichen Attributtyp abrufen;
3. Filtern (Objekte, Bedingung): Objekte nach Bedingungen filtern.
LLM-Planer
Das Entscheidungsmodul von NPC ist ein LLM-basierter Planer, der aus drei Teilen besteht (Abbildung 3): einem Speichermodul, das zum Speichern des Chat-Verlaufs zwischen NPC und anderen Agenten verwendet wird; von WKM, um Szenenwissen abzufragen; und ein LLM-Sprecher wird verwendet, um den Chat-Verlauf und das abgefragte Wissen zu verarbeiten, um Antworten zu generieren. Wenn ein NPC eine Nachricht empfängt, speichert er die Nachricht zunächst im Speicher und leitet dann den aktualisierten Verlauf an den LLM-Programmierer weiter. Anschließend ruft der Programmierer wiederholt die Datenschnittstelle auf, um das notwendige Szenenwissen abzufragen. Schließlich werden das Wissen und die Geschichte an den LLM-Sprecher gesendet, der eine Antwort generiert.
Experimente
Der Autor führte Experimente zu Objektreferenz, Spracherdung und objektzentrierter Qualitätssicherung durch, um zu beweisen, dass der NPC im Artikel Objektbeschreibungen generieren, Objekte anhand von Beschreibungen lokalisieren und intelligente Objekte bereitstellen kann. Der Körper stellt Objekte bereit Information. Zu den NPC-Backend-LLMs in diesen Experimenten gehören GPT-4o, InternLM2-Chat-20B und Llama-3-70BInstruct.
Wie in Abbildung 4 dargestellt, verwendeten die Autoren im Referenzexperiment eine Human-in-the-Loop-Bewertung. Der NPC wählt zufällig ein Objekt aus und beschreibt es, und der menschliche Annotator wählt ein Objekt basierend auf der Beschreibung aus. Eine Referenz ist erfolgreich, wenn der menschliche Annotator das richtige Objekt finden kann, das der Beschreibung entspricht. Bei Erdungsexperimenten spielte GPT-4o die Rolle eines menschlichen Kommentators und lieferte eine Beschreibung eines Objekts, das dann vom NPC positioniert wurde. Die Erdung ist erfolgreich, wenn der NPC das entsprechende Objekt finden kann.
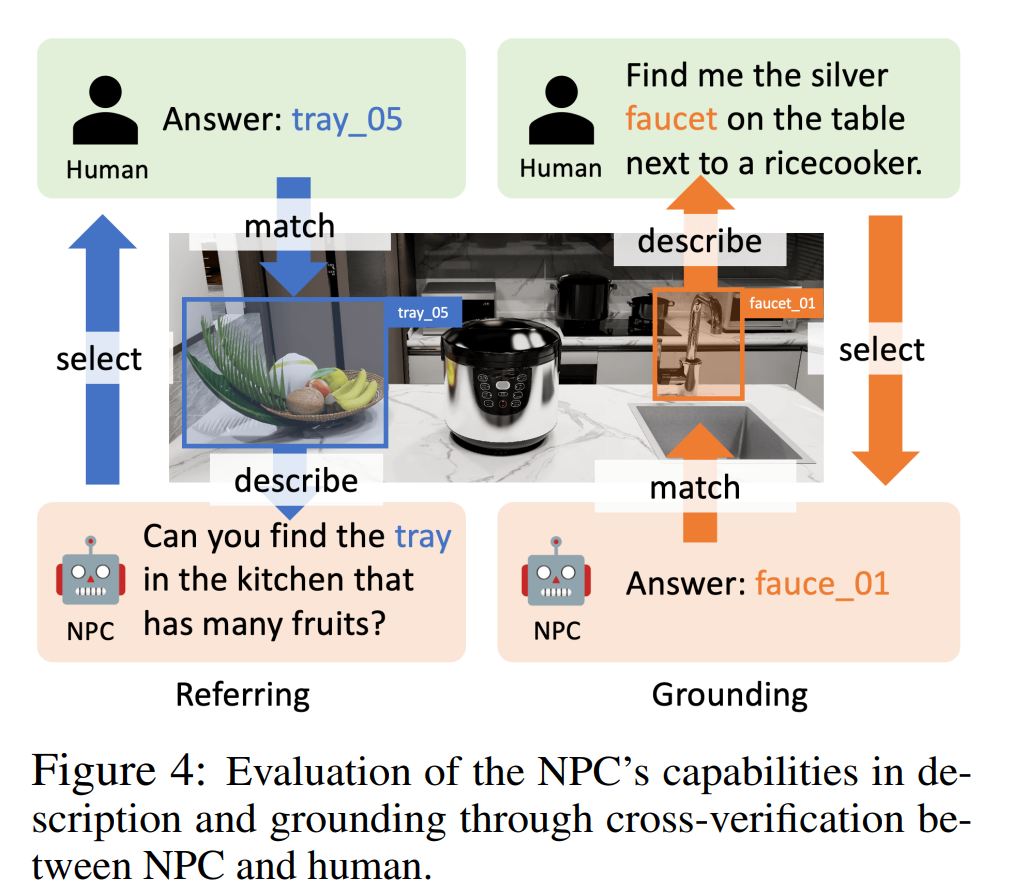
Die Erfolgsraten (Referenzierung und Erdung) in Tabelle 2 zeigen, dass die Genauigkeitsraten verschiedener LLMs 95,9 %–100 % bzw. 83,3 %–93,2 % betragen, was bestätigt, dass unser NPC-Framework auf verschiedene LLMs verweisen kann. und Erdungsgenauigkeit.
In einem objektzentrierten QA-Experiment bewerteten die Autoren die Fähigkeit des NPCs, dem Agenten durch Beantwortung von Fragen in einer Navigationsaufgabe Informationen auf Objektebene bereitzustellen. Sie entwarfen eine Pipeline zur Generierung objektzentrierter Navigationsdiagramme, die reale Szenarien simulieren. In diesen Szenarien stellt der Agent dem NPC Fragen, um Informationen zu erhalten, und ergreift auf der Grundlage der Antworten Maßnahmen. Bei einer Agentenfrage bewerten die Autoren den NPC anhand der semantischen Ähnlichkeit zwischen seiner Antwort und der tatsächlichen Antwort. Die in Tabelle 2 (QA) aufgeführten Gesamtbewertungen zeigen, dass NPCs präzise und nützliche Navigationsunterstützung leisten können.
GRBench: Ein Benchmark zur Bewertung verkörperter Agenten
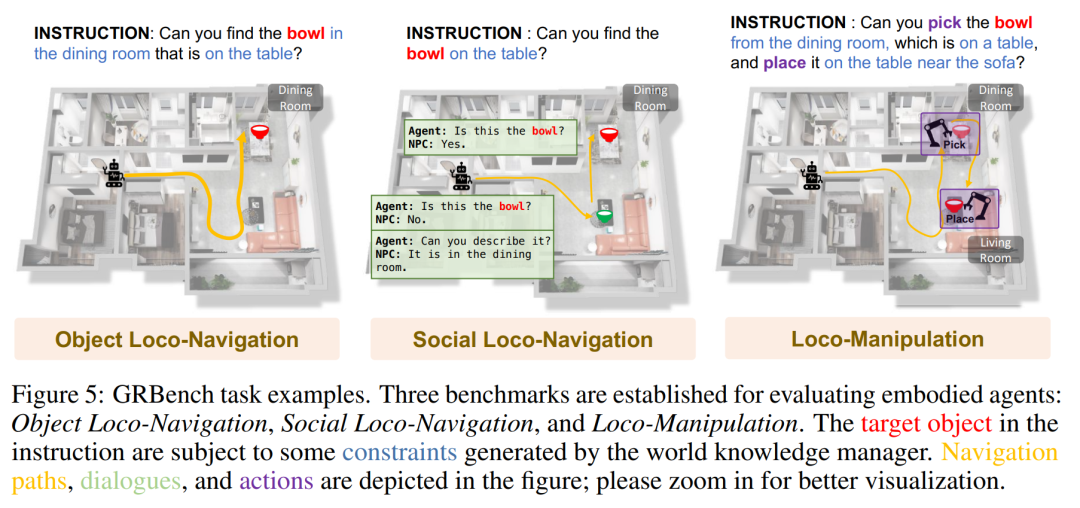
GRBench ist ein umfassendes Bewertungstool zur Bewertung der Fähigkeiten von Roboteragenten. Um die Fähigkeit von Roboteragenten zur Bewältigung alltäglicher Aufgaben zu bewerten, umfasst GRBench drei Benchmarks: Objektlokalisierungsnavigation, soziale Lokalisierungsnavigation und Lokalisierungsoperationen. Der Schwierigkeitsgrad dieser Benchmarks nimmt nach und nach zu und die Anforderungen an die Fähigkeiten des Roboters steigen entsprechend.
Aufgrund der hervorragenden Fähigkeit des auf Beinen stehenden Roboters, Gelände zu durchqueren, priorisiert der Autor ihn als Hauptagent. In groß angelegten Szenarien ist es für aktuelle Algorithmen jedoch schwierig, gleichzeitig Wahrnehmung, Planung und Steuerung auf niedriger Ebene durchzuführen und zufriedenstellende Ergebnisse zu erzielen.
Der jüngste Fortschritt von GRBench hat die Machbarkeit des Trainings hochpräziser Richtlinien für einzelne Fähigkeiten in der Simulation bewiesen. Inspiriert davon wird sich die erste Version von GRBench auf Aufgaben auf hoher Ebene konzentrieren und lernbasierte Steuerungsstrategien als APIs bereitstellen, z wie Gehen und Pick-and-Place. Dadurch bietet ihr Benchmark eine realistischere physische Umgebung und schließt die Lücke zwischen Simulation und der realen Welt.
Das Bild unten zeigt einige Beispiele für Aufgaben von GRBench.
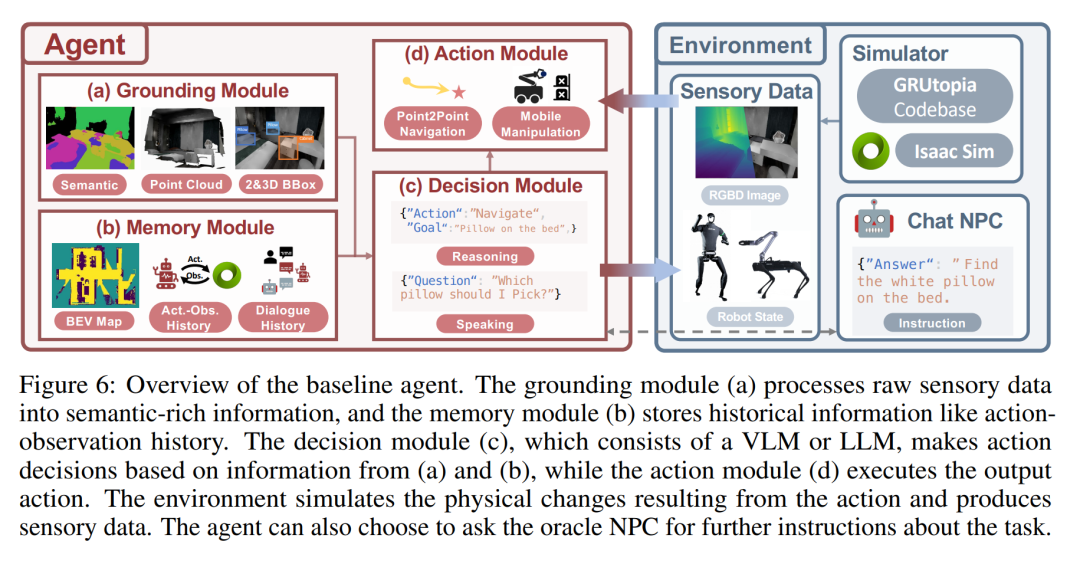
Die folgende Abbildung ist eine Übersicht über den Basisagenten. Das Erdungsmodul (a) verarbeitet sensorische Rohdaten in semantisch reichhaltige Informationen, und das Speichermodul (b) speichert historische Informationen wie den Aktionsbeobachtungsverlauf. Das Entscheidungsmodul (c) besteht aus einem VLM oder LLM und trifft Aktionsentscheidungen basierend auf den Informationen aus (a) und (b), während das Aktionsmodul (d) die Ausgabeaktionen ausführt. Die Umgebung simuliert die durch die Aktion hervorgerufenen physischen Veränderungen und generiert sensorische Daten. Der Agent kann den Berater-NPC um weitere Anweisungen zu dieser Aufgabe bitten.
Quantitative Bewertungsergebnisse
Der Autor führte in drei Benchmark-Tests eine vergleichende Analyse großer modellgetriebener Agenten-Frameworks unter verschiedenen großen Modell-Backends durch. Wie in Tabelle 4 gezeigt, stellten sie fest, dass die Leistung der Zufallsstrategie nahe bei 0 lag, was darauf hindeutet, dass ihre Aufgabe nicht einfach war. Sie beobachteten in allen drei Benchmarks eine deutlich bessere Gesamtleistung, wenn ein relativ überlegenes großes Modell als Backend verwendet wurde. Erwähnenswert ist, dass sie beobachteten, dass Qwen im Dialog eine bessere Leistung als GPT-4o erbrachte (siehe Tabelle 5).
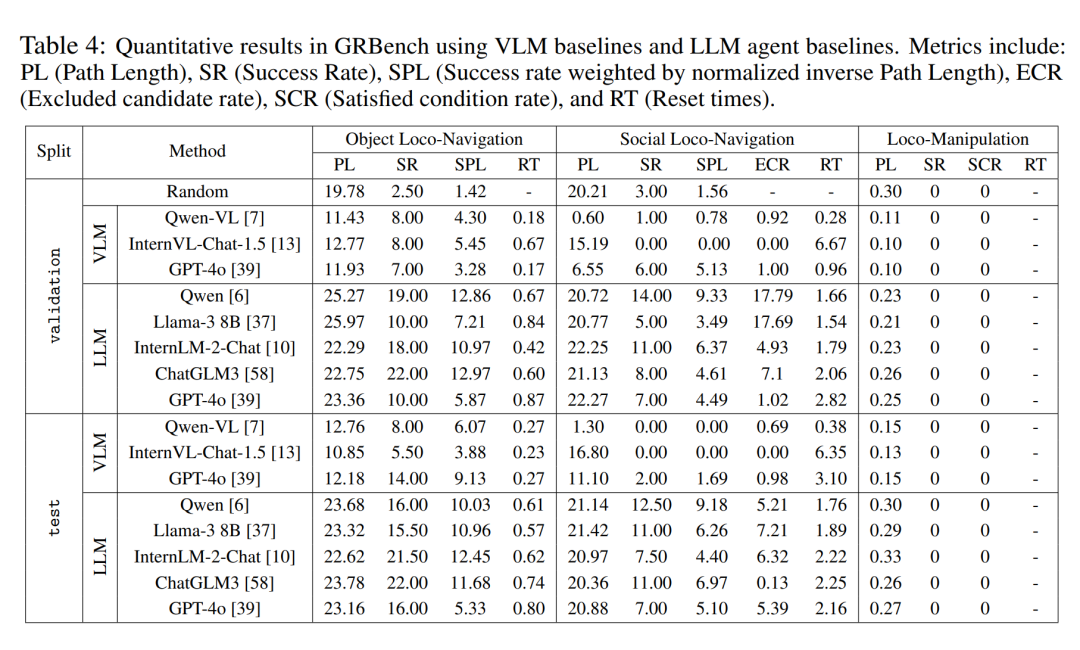

Darüber hinaus zeigt das in diesem Artikel vorgeschlagene Agenten-Framework im Vergleich zur direkten Verwendung multimodaler großer Modelle zur Entscheidungsfindung offensichtliche Überlegenheit. Dies zeigt, dass selbst aktuellen hochmodernen multimodalen Großmodellen starke Generalisierungsfähigkeiten für reale verkörperte Aufgaben fehlen. Die Methode in diesem Artikel weist jedoch auch erhebliches Verbesserungspotenzial auf. Dies zeigt, dass selbst eine seit vielen Jahren untersuchte Aufgabe wie die Navigation noch lange nicht vollständig gelöst ist, wenn eine Aufgabenstellung eingeführt wird, die näher an der realen Welt liegt.
Qualitative Bewertungsergebnisse
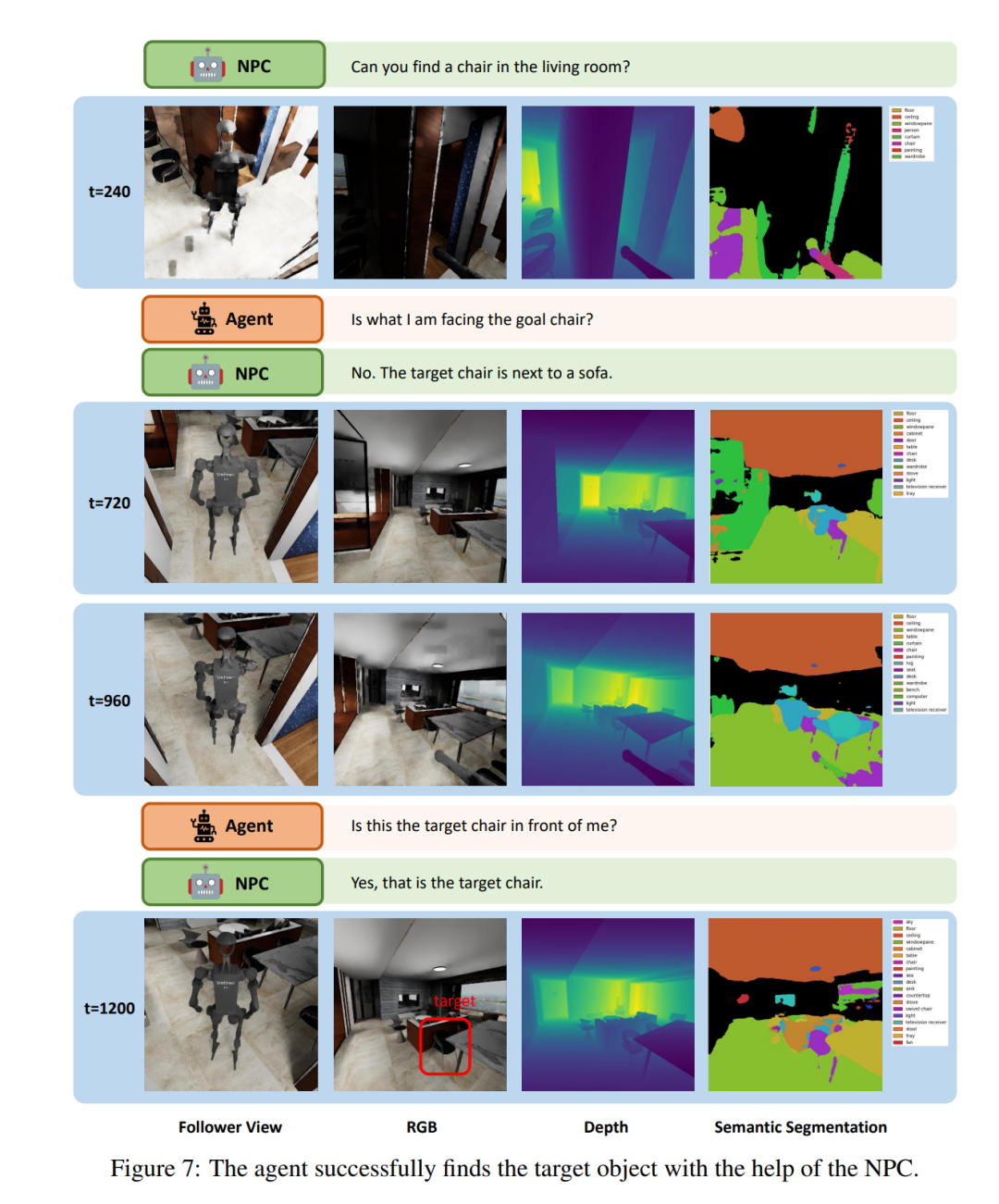
Abbildung 7 zeigt ein kleines Fragment, das der LLM-Agent in der Aufgabe „Social Loco-Navigation“ ausführt, um zu veranschaulichen, wie der Agent mit NPCs interagiert. Der Agent kann bis zu dreimal mit dem NPC sprechen, um weitere Aufgabeninformationen abzufragen. Bei t = 240 navigiert der Agent zu einem Stuhl und fragt den NPC, ob dieser Stuhl der Zielstuhl ist. Der NPC stellt dann periphere Informationen über das Ziel bereit, um Mehrdeutigkeiten zu reduzieren. Mit Hilfe des NPC gelang es dem Agenten, den Zielstuhl durch einen Interaktionsprozess, der dem menschlichen Verhalten ähnelt, erfolgreich zu identifizieren. Dies zeigt, dass die NPCs in diesem Artikel natürliche soziale Interaktionen für die Untersuchung der Mensch-Roboter-Interaktion und -Zusammenarbeit bereitstellen können.
Das obige ist der detaillierte Inhalt vonDie Roboterversion von „Stanford Town' ist da, speziell für die verkörperte Intelligenzforschung gebaut. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Methode zum Öffnen der Bereichsberechtigung
Methode zum Öffnen der Bereichsberechtigung
 Was sind nicht relationale Datenbanken?
Was sind nicht relationale Datenbanken?
 Der Unterschied zwischen Ankern und Zielen
Der Unterschied zwischen Ankern und Zielen
 Was ist der Unterschied zwischen Leerzeichen voller Breite und Leerzeichen halber Breite?
Was ist der Unterschied zwischen Leerzeichen voller Breite und Leerzeichen halber Breite?
 Konfiguration der JDK-Umgebungsvariablen
Konfiguration der JDK-Umgebungsvariablen
 SQL-Anweisung zum Sichern der Datenbank
SQL-Anweisung zum Sichern der Datenbank
 Was tun, wenn CSS nicht geladen werden kann?
Was tun, wenn CSS nicht geladen werden kann?
 Welche Tipps gibt es für die Verwendung von Dezender?
Welche Tipps gibt es für die Verwendung von Dezender?
 Die acht am häufigsten verwendeten Funktionen in Excel
Die acht am häufigsten verwendeten Funktionen in Excel








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



