

Kürzlich ist RSS (Robotics: Science and Systems) 2024, eine berühmte Konferenz im Bereich Robotik, an der Technischen Universität Delft in den Niederlanden erfolgreich zu Ende gegangen.
Obwohl die Konferenzgröße nicht mit Top-KI-Konferenzen wie NeurIPS und CVPR vergleichbar ist, hat RSS in den letzten Jahren große Fortschritte gemacht, mit fast 900 Teilnehmern in diesem Jahr. 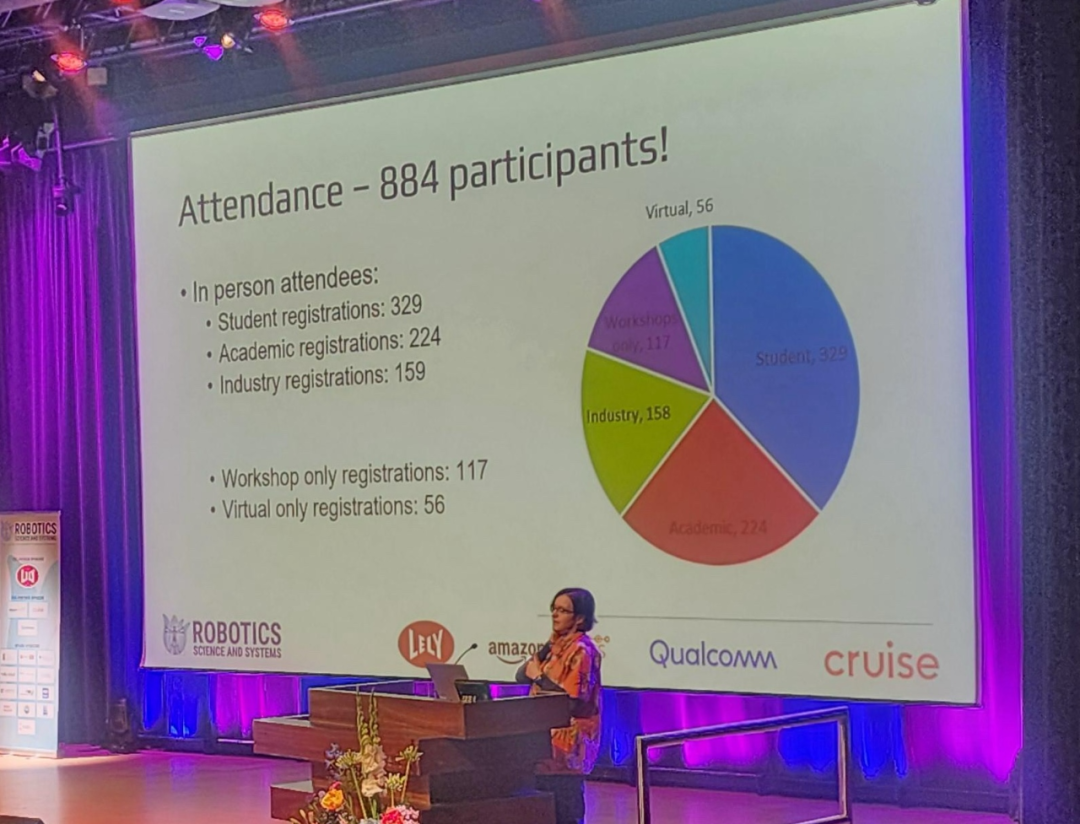
Am letzten Konferenztag wurden gleichzeitig mehrere Auszeichnungen wie Best Paper, Best Student Paper, Best System Paper und Best Demo Paper bekannt gegeben. Darüber hinaus zeichnete die Konferenz auch den „Early Career Spotlight Award“ und den „Time Test Award“ aus.
Es ist erwähnenswert, dass die Forschung zu humanoiden Robotern der Tsinghua-Universität und der Beijing Xingdong Era Technology Co., Ltd. den Preis für die beste Arbeit gewonnen hat und der chinesische Wissenschaftler Ji Zhang dieses Mal den Testpreis gewonnen hat.
Das Folgende sind die Informationen zu den Gewinnerpapieren:
Best Demo Paper Award

Papiertitel: Demonstrating CropFollow++: Robust Under-Canopy Navigation with Keypoints
Autor: Arun Narenthiran. Sivakumar , Mateus Valverde Gasparino, Michael McGuire, Vitor Akihiro Hisano Higuti, M. Ugur Akcal, Girish Chowdhary
Institution: UIUC, Earth Sense
Link zum Papier: https://enriquecoronadozu.github.io/rssproceedings2024/rss20/ p023. pdf
In diesem Artikel schlagen die Forscher ein robustes, erfahrungsbasiertes visuelles Navigationssystem für landwirtschaftliche Roboter im Unterfruchtbereich vor, das semantische Schlüsselpunkte verwendet.
Die autonome Navigation unter Pflanzenbeständen ist aufgrund des geringen Reihenabstands der Pflanzen (∼ 0,75 Meter), der verringerten RTK-GPS-Genauigkeit aufgrund von Mehrwegefehlern und des durch übermäßige Störungen verursachten Rauschens durch Lidar-Messungen eine Herausforderung. Eine frühere Arbeit namens CropFollow ging diese Herausforderungen an, indem sie ein lernbasiertes, durchgängiges wahrnehmungsbezogenes visuelles Navigationssystem vorschlug. Dieser Ansatz weist jedoch die folgenden Einschränkungen auf: Mangel an interpretierbaren Darstellungen und mangelnde Sensibilität gegenüber Ausreißervorhersagen während der Okklusion aufgrund unzureichender Konfidenz.
Das System CropFollow++ dieses Artikels stellt eine modulare Wahrnehmungsarchitektur und eine erlernte semantische Schlüsselpunktdarstellung vor. Im Vergleich zu CropFollow ist CropFollow++ modularer, besser interpretierbar und bietet eine größere Sicherheit bei der Erkennung von Verdeckungen. CropFollow++ schnitt bei anspruchsvollen Feldtests in der Spätsaison, die sich jeweils über 1,9 Kilometer erstreckten und 13 gegenüber 33 Kollisionen erforderten, deutlich besser ab als CropFollow. Wir diskutieren auch die wichtigsten Erkenntnisse aus einem groß angelegten Einsatz von CropFollow++ in mehreren Robotern für den Unterfruchtanbau (Gesamtlänge 25 km) unter unterschiedlichen Feldbedingungen.

paper Titel: Demonstrieren agiler Flug von Pixel ohne staatliche Schätzung
authoren: Smail Geles, Leonard Bauerfeld, Angel Romero, Jiaxu Xing, Davide Scaramuzza
paper Link: https: // enriquecoronadozu .github.io/rssproceedings2024/rss20/p082.pdf
Quadcopter-Drohnen gehören zu den wendigsten Flugrobotern. Obwohl einige neuere Forschungen Fortschritte in der lernbasierten Steuerung und Computer Vision erzielt haben, sind autonome Drohnen immer noch auf eine explizite Zustandsschätzung angewiesen. Menschliche Piloten hingegen können sich nur auf Ego-Videostreams verlassen, die von der Bordkamera der Drohne bereitgestellt werden, um die Plattform an ihre Grenzen zu bringen und stabil in unsichtbaren Umgebungen zu fliegen.
Dieser Artikel stellt das erste visionsbasierte Quadrocopter-Drohnensystem vor, das autonom mit hoher Geschwindigkeit durch eine Reihe von Türen navigieren kann und dabei Pixel direkt auf Steuerbefehle abbildet. Wie professionelle Drohnen-Rennfahrer verwendet das System keine expliziten Zustandsschätzungen, sondern nutzt die gleichen Steuerbefehle wie Menschen (kollektiver Schub und Körpergeschwindigkeit). Forscher haben einen agilen Flug mit Geschwindigkeiten von bis zu 40 km/h und Beschleunigungen von bis zu 2 g nachgewiesen. Dies wird durch das Training visionsbasierter Richtlinien durch Reinforcement Learning (RL) erreicht. Durch den Einsatz einer asymmetrischen Akteur-Kritiker-Methode können privilegierte Informationen gewonnen und die Ausbildung erleichtert werden. Um die Rechenkomplexität beim bildbasierten RL-Training zu überwinden, verwenden wir die Innenkanten von Toren als Sensorabstraktionen. Diese einfache, aber leistungsstarke aufgabenrelevante Darstellung kann simuliert werden, ohne dass Bilder während des Trainings gerendert werden müssen. Während des Bereitstellungsprozesses verwendeten die Forscher einen Türdetektor auf Basis von Swin Transformer.
Die Methode in diesem Artikel kann standardmäßige, handelsübliche Hardware verwenden, um einen autonomen agilen Flug zu erreichen. Während sich die Demonstration auf Drohnenrennen konzentrierte, hat der Ansatz Auswirkungen, die über den Wettbewerb hinausgehen, und kann als Grundlage für zukünftige Forschungen zu realen Anwendungen in strukturierten Umgebungen dienen.
Best System Paper Award

Papiertitel: Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, Shuran Song
Institutionen: Stanford University, Columbia University, Toyota Research Institute
Link zum Papier: https://arxiv.org/pdf/2402.10329
Dieser Artikel stellt das Universal Manipulation Interface (UMI) vor, ein Ein Datenerfassungs- und Richtlinienlernrahmen, der von Menschen in freier Wildbahn gezeigte Fähigkeiten direkt in einsetzbare Roboterrichtlinien überträgt. UMI nutzt einen Handgreifer und ein sorgfältiges Schnittstellendesign, um eine tragbare, kostengünstige und informationsreiche Datenerfassung für anspruchsvolle Doppelarm- und dynamische Manipulationsdemonstrationen zu ermöglichen. Um das einsetzbare Richtlinienlernen zu erleichtern, verwendet UMI eine sorgfältig gestaltete Richtlinienschnittstelle mit Inferenzzeitverzögerungsabgleich und Funktionen zur Darstellung relativer Trajektorienaktionen. Die erlernte Richtlinie ist hardwareunabhängig und kann auf mehreren Roboterplattformen eingesetzt werden. Mit diesen Funktionen erschließt das UMI-Framework neue Fähigkeiten zur Robotermanipulation und ermöglicht die Zero-Shot-Generalisierung von dynamischem, zweiarmigem, präzisem Verhalten und Verhalten mit großem Sichtfeld, indem einfach die Trainingsdaten für jede Aufgabe geändert werden. Die Forscher demonstrierten die Vielseitigkeit und Wirksamkeit von UMI durch umfassende Experimente in der realen Welt, bei denen mit UMI Zero RF erlernte Richtlinien auf neue Umgebungen und Objekte übertragen wurden, wenn sie an verschiedenen menschlichen Demonstrationen trainiert wurden.

Papiertitel: Khronos: A Unified Approach for Spatio-Temporal Metric-Semantic SLAM in Dynamic Environments
Autoren: Lukas Schmid, Marcus Abate, Yun Chang, Luca Carlone
Link zum Papier: https://arxiv.org/pdf/2402.13817
Das Wahrnehmen und Verstehen hochdynamischer und sich verändernder Umgebungen sind Schlüsselfähigkeiten für die Roboterautonomie. Während bei der Entwicklung dynamischer SLAM-Methoden, mit denen Roboterposen genau geschätzt werden können, erhebliche Fortschritte erzielt wurden, wurde der Erstellung dichter räumlich-zeitlicher Darstellungen von Roboterumgebungen nicht genügend Aufmerksamkeit geschenkt. Ein detailliertes Verständnis des Szenarios und seiner zeitlichen Entwicklung ist entscheidend für die langfristige Autonomie des Roboters und auch für Aufgaben, die langfristiges Denken erfordern, wie z. B. das effektive Arbeiten in einer Umgebung, die mit Menschen und anderen Agenten geteilt wird unterliegt daher kurz- und langfristigen Einschränkungen. Die Auswirkungen dynamischer Veränderungen.
Um dieser Herausforderung zu begegnen, definiert diese Studie das räumlich-zeitliche metrisch-semantische SLAM (SMS)-Problem und schlägt einen Rahmen vor, um das Problem effektiv zu zerlegen und zu lösen. Es wird gezeigt, dass die vorgeschlagene Faktorisierung auf eine natürliche Organisation räumlich-zeitlicher Wahrnehmungssysteme schließen lässt, bei der ein schneller Prozess kurzfristige Dynamiken im aktiven Zeitfenster verfolgt, während ein anderer langsamer Prozess Reaktionen auf langfristige Veränderungen in der Umgebung mithilfe eines Faktordiagramms ausdrückt. Rückschlüsse. Forscher stellen Khronos zur Verfügung, eine effiziente Methode zur raumzeitlichen Wahrnehmung, und zeigen, dass sie bestehende Erklärungen kurzfristiger und langfristiger Dynamiken vereinheitlicht und in der Lage ist, dichte raumzeitliche Karten in Echtzeit zu erstellen.
Die in der Arbeit bereitgestellten Simulationen und tatsächlichen Ergebnisse zeigen, dass die von Khronos erstellte räumlich-zeitliche Karte die zeitlichen Veränderungen der dreidimensionalen Szene genau wiedergeben kann und Khronos die Basislinie in mehreren Indikatoren übertrifft.
Best Student Paper Award

Papiertitel: Dynamic On-Palm Manipulation via Controlled Sliding
Autoren: William Yang, Michael Posa
Institution: University of Pennsylvania
Link zum Papier: https://arxiv.org/pdf/2405.08731
Derzeit konzentriert sich die Forschung zu Robotern, die nicht greifende Aktionen ausführen, hauptsächlich auf statischen Kontakt, um Probleme zu vermeiden, die durch Rutschen verursacht werden können. Wenn jedoch das Problem des „Hand Slip“ grundsätzlich beseitigt wird, also das Gleiten beim Kontakt kontrolliert werden kann, eröffnen sich dem Roboter neue Handlungsfelder.
In diesem Artikel schlagen Forscher eine anspruchsvolle dynamische, nicht greifende Betriebsaufgabe vor, die eine umfassende Betrachtung verschiedener gemischter Kontaktmodi erfordert. Die Forscher nutzten die neueste MPC-Technologie (Implicit Contact Model Predictive Control), um dem Roboter bei der multimodalen Planung zur Erledigung verschiedener Aufgaben zu helfen. Der Artikel untersucht im Detail, wie vereinfachte Modelle für MPC mit Low-Level-Tracking-Controllern integriert werden können und wie implizite Kontakt-MPC an die Anforderungen dynamischer Aufgaben angepasst werden können.

Obwohl Reibungs- und starre Kontaktmodelle bekanntermaßen oft ungenau sind, ist es beeindruckend, dass der Ansatz dieser Arbeit sensibel auf diese Ungenauigkeiten reagieren und die Aufgabe gleichzeitig schnell erledigen kann. Darüber hinaus verwendeten die Forscher keine üblichen Hilfswerkzeuge wie Referenztrajektorien oder Bewegungsprimitive, um den Roboter bei der Erledigung der Aufgabe zu unterstützen, was die Vielseitigkeit der Methode zusätzlich unterstreicht. Dies ist das erste Mal, dass die implizite Kontakt-MPC-Technologie auf dynamische Manipulationsaufgaben im dreidimensionalen Raum angewendet wird.

Papiertitel: Agile But Safe: Learning Collision-Free High-Speed Legged Locomotion
Autoren: Tairan He, Chong Zhang, Wenli Xiao, Guanqi He, Changliu Liu, Guanya Shi
Institution: CMU, ETH Zürich, Schweiz
Link zum Papier: https://arxiv.org/pdf/2401.17583
Wenn vierbeinige Roboter durch unübersichtliche Umgebungen reisen, müssen sie sowohl Flexibilität als auch Sicherheit bieten. Sie müssen in der Lage sein, Aufgaben schnell zu erledigen und dabei Kollisionen mit Personen oder Hindernissen zu vermeiden. Die bestehende Forschung konzentriert sich jedoch oft nur auf einen Aspekt: Entweder wird aus Sicherheitsgründen eine konservative Steuerung mit einer Geschwindigkeit von nicht mehr als 1,0 m/s entworfen, oder man strebt nach Flexibilität, ignoriert aber das Problem potenziell tödlicher Kollisionen.
Dieses Papier schlägt ein Kontrollrahmenwerk namens „Agile and Secure“ vor. Dieser Rahmen ermöglicht es vierbeinigen Robotern, Hindernissen und Menschen sicher auszuweichen und gleichzeitig ihre Flexibilität zu bewahren, wodurch ein kollisionsfreies Gehen erreicht wird.
ABS umfasst zwei Sätze von Strategien: Eine besteht darin, dem Roboter beizubringen, flexibel und flink zwischen Hindernissen zu wechseln, und die andere darin, dem Roboter beizubringen, wie er sich schnell erholen kann, wenn er auf ein Problem stößt, um sicherzustellen, dass der Roboter nicht herunterfällt oder etwas treffen. Die beiden Strategien ergänzen sich.
Im ABS-System wird der Strategiewechsel durch ein Kollisionsvermeidungs-Wertenetzwerk gesteuert, das auf der Theorie der lernenden Steuerung basiert. Dieses Netzwerk bestimmt nicht nur, wann die Strategie gewechselt werden muss, sondern stellt auch eine Zielfunktion für die Wiederherstellungsstrategie bereit und stellt sicher, dass der Roboter im geschlossenen Regelsystem immer sicher bleibt. Auf diese Weise können Roboter flexibel auf verschiedene Situationen in komplexen Umgebungen reagieren.
Um diese Strategien und Netzwerke zu trainieren, haben Forscher umfangreiche Schulungen in Simulationsumgebungen durchgeführt, darunter agile Strategien, Wertnetzwerke zur Kollisionsvermeidung, Wiederherstellungsstrategien und Netzwerke zur Darstellung externer Wahrnehmung usw. Diese trainierten Module können direkt auf die reale Welt angewendet werden. Mit den eigenen Wahrnehmungs- und Rechenfähigkeiten des Roboters kann er schnell und sicher handeln, egal ob er sich drinnen oder in einem begrenzten Außenbereich befindet, egal ob er auf unbewegliche oder bewegliche Hindernisse trifft ABS-Rahmen.
Wenn Sie weitere Einzelheiten erfahren möchten, können Sie sich die vorherige Einleitung zu diesem Dokument auf dieser Website ansehen. 

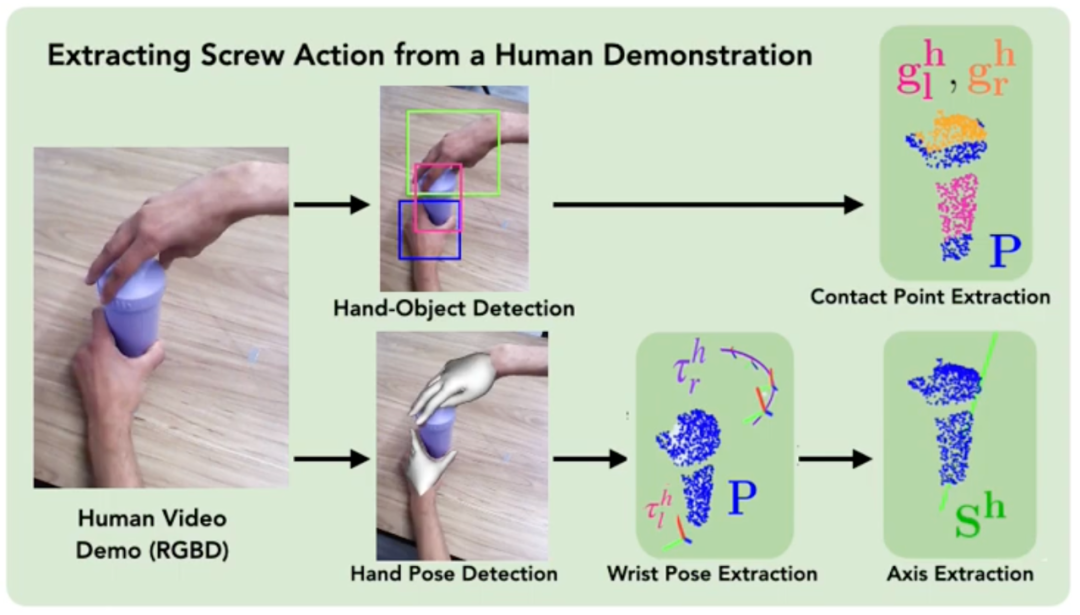
Papiertitel: ScrewMimic: Bimanual Imitation from Human Videos with Screw Space Projection
Autoren: Arpit Bahety, Priyanka Mandikal, Ben Abbatematteo, Roberto Martín-Martín
Methodendiagramm, die die humanoide Fortbewegung vorantreiben: Beherrschung herausfordernder Terrains mit demoinieren Weltrundmodell Learning Institution: Beijing Xingdong Era Technology Co., Ltd., Tsinghua-Universität
Paper link: https://enriquecoronadozu.github.io/rssproceedings2024/rss20/p058.pdf
Current technology can only allow humanoid robots to walk on flat ground and such simple terrain. However, it is still difficult to let them move freely in complex environments, such as real outdoor scenes. In this paper, researchers propose a new method called denoising world model learning (DWL).
DWL is an end-to-end reinforcement learning framework for motion control of humanoid robots. This framework enables the robot to adapt to a variety of uneven and challenging terrains, such as snow, slopes, and stairs. It is worth mentioning that these robots only need one learning process and can handle diverse terrain challenges in the real world without additional special training.

This research was jointly completed by Beijing Xingdong Era Technology Co., Ltd. and Tsinghua University. Founded in 2023, Xingdong Era is a technology company incubated by Tsinghua University's Cross-Information Research Institute that develops embodied intelligence and general humanoid robot technologies and products. The founder is Chen Jianyu, assistant professor and doctoral supervisor at Tsinghua University's Cross-Information Research Institute, focusing on The cutting-edge application of general artificial intelligence (AGI) is committed to the development of universal humanoid robots that can adapt to a wide range of fields, multiple scenarios, and high intelligence.

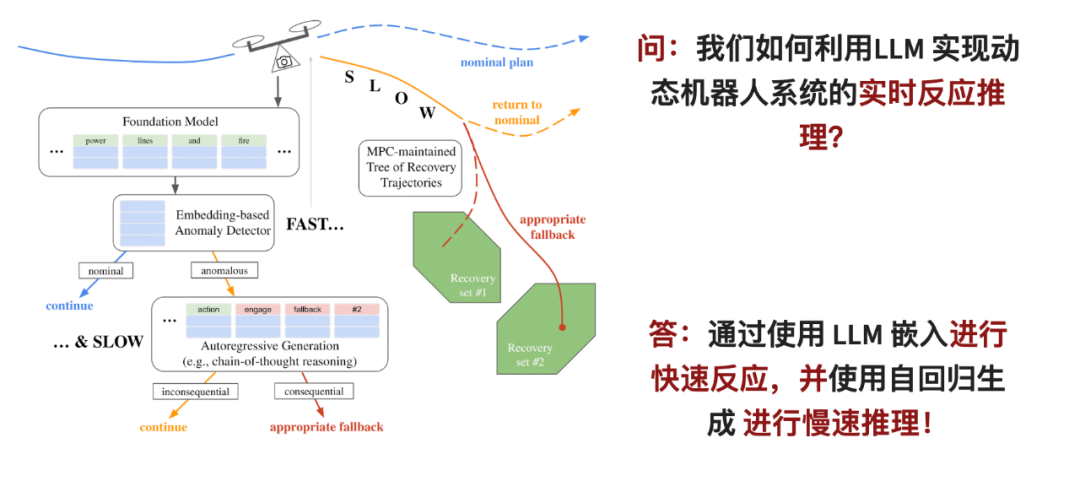
Paper title: Real-Time Anomaly Detection and Reactive Planning with Large Language Models
Authors: Rohan Sinha, Amine Elhafsi, Christopher Agia, Matt Foutter, Edward Schmerling, Marco Pavone
Institution :Stanford University
Paper link: https://arxiv.org/pdf/2407.08735
Large Language Models (LLM), with zero-shot generalization capabilities, which makes them promising for detection and exclusion robots Techniques for system out-of-distribution failure. However, for large-scale language models to really work, two problems need to be solved: first, LLM requires a lot of computing resources to be applied online; second, LLM's judgment needs to be integrated into the robot's safety control system.
In this paper, the researchers proposed a two-stage reasoning framework: for the first stage, they designed a fast anomaly detector that can quickly analyze the observations of the robot in the understanding space of LLM; If problems are found, the next alternative selection stage is entered. At this stage, the inference capabilities of LLM are used to perform a more in-depth analysis.
The stage entered corresponds to the branch point in the model predictive control strategy, which can track and evaluate different alternative plans simultaneously to solve the latency problem of slow reasoners. Once the system detects any anomaly or problem, this strategy will be activated immediately to ensure that the robot's actions are safe.
The fast anomaly classifier in this paper outperforms autoregressive inference using state-of-the-art GPT models, even when using relatively small language models. This enables the real-time monitor proposed in the paper to improve the reliability of dynamic robots under limited resources and time, such as in quadcopters and driverless cars.

Paper title: Configuration Space Distance Fields for Manipulation Planning
Author: Yiming Li, Xuemin Chi, Amirreza Razmjoo, Sylvain Calinon
Institution: Switzerland I DIAP Institute, Lausanne, Switzerland Federal Institute of Technology, Zhejiang University
Paper link: https://arxiv.org/pdf/2406.01137
Signed distance field (SDF) is a popular implicit shape representation in robotics, which provides Geometric information about objects and obstacles and can be easily combined with control, optimization and learning techniques. SDF is generally used to represent distances in task space, which corresponds to the concept of distance perceived by humans in the 3D world.
In the field of robotics, SDF is often used to represent the angle of each joint of the robot. Researchers usually know which areas in the robot's joint angle space are safe, that is, the robot's joints can rotate to these areas without collision. However, they do not often express these safe areas in terms of distance fields.
In this paper, the researchers propose the potential of using an SDF to optimize the robot configuration space, which they call the Configuration Space Distance Field (CDF for short). Similar to using SDF, CDF provides efficient joint angle distance lookups and direct access to derivatives (joint angular velocities). Usually, robot planning is divided into two steps: first, see how far the action is from the target in the task space, and then use inverse kinematics to calculate how the joints rotate. But CDF combines these two steps into one step and solves the problem directly in the joint space of the robot, which is simpler and more efficient. In the paper, the researchers proposed an efficient algorithm to calculate and fuse CDF, which can be extended to any scenario.
They also proposed a corresponding neural CDF representation using multilayer perceptrons (MLPs) to obtain a compact and continuous representation, improving computational efficiency. The paper provides some specific examples to demonstrate the effect of CDF, such as letting the robot avoid obstacles on a plane, and letting a 7-axis robot Franka complete some action planning tasks. These examples illustrate the effectiveness of CDF.机 The robotic arm of the CDF method is made of a raising box task.

Early professional SPOTLIGHT Conference also selected the Early Professional Spotlight Award. This winner is Stefan Leutenegger. It is the navigation of robots in potentially unknown environments.
Stefan Leutenegger is an assistant professor (tenure-track) at the School of Computing, Information and Technology (CIT) at the Technical University of Munich (TUM), and works with the Munich Institute for Robotics and Machine Intelligence (MIRMI) and the Munich Institute for Data Science ( MDSI) is associated with the Munich Center for Machine Learning (MCML) and was a member of the Dyson Robotics Laboratory. The Smart Robot Laboratory (SRL) he leads is dedicated to research at the intersection of perception, mobile robots, drones and machine learning. Additionally, Stefan is a visiting lecturer at the Department of Computing at Imperial College London.
He co-founded SLAMcore, a spin-out company targeting the commercialization of positioning and mapping solutions for robots and drones. Stefan received his bachelor's and master's degrees in mechanical engineering from ETH Zurich and received his PhD in 2014 with a thesis on "Unmanned Solar Aircraft: Design and Algorithms for Efficient and Robust Autonomous Operation".
 Test of Time Award
Test of Time Award
Paper link: https://www.ri.cmu.edu/pub_files/2014/7/Ji_LidarMapping_RSS2014_v8.pdf
This ten-year-old paper proposes a method to utilize 6-DOF movement of double A real-time method for odometry and mapping of axial lidar odometry data. The reason this problem is difficult to solve is that the ranging data are received at different times, and errors in motion estimation can lead to misregistration of the resulting point cloud. Coherent 3D maps can be built by offline batch methods, often using loop closure to correct for drift over time. The method in this paper does not require high-precision ranging or inertial measurement, and can achieve low drift and low computational complexity.
The key to achieving this level of performance is to split the complex simultaneous positioning and mapping problem into two algorithms to optimize a large number of variables simultaneously. One algorithm performs ranging at high frequency but low fidelity to estimate lidar speed; the other algorithm operates at an order of magnitude lower frequency for fine matching and registration of point clouds. The combination of these two algorithms enables the method to draw in real time. The researchers evaluated it through extensive experiments and the KITTI speed benchmark, and the results showed that the method can achieve the SOTA accuracy level of offline batch methods. 
Das obige ist der detaillierte Inhalt vonAuf der Top-Robotikkonferenz RSS 2024 gewann Chinas Forschung zu humanoiden Robotern den Best Paper Award. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Methode zur Erstellung von Intouch-Berichten
Methode zur Erstellung von Intouch-Berichten
 Eigenschaften des Netzwerks
Eigenschaften des Netzwerks
 DSP-Anwendungsbereiche
DSP-Anwendungsbereiche
 So lösen Sie das Problem, dass Teamviewer keine Verbindung herstellen kann
So lösen Sie das Problem, dass Teamviewer keine Verbindung herstellen kann
 So löschen Sie ein Verzeichnis unter LINUX
So löschen Sie ein Verzeichnis unter LINUX
 Der Unterschied zwischen zufällig und pseudozufällig
Der Unterschied zwischen zufällig und pseudozufällig
 So öffnen Sie JAR-Dateien
So öffnen Sie JAR-Dateien
 Welche Währung ist U-Coin?
Welche Währung ist U-Coin?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



