
 Technologie-Peripheriegeräte
KI
Die Universität für Wissenschaft und Technologie Chinas und Huawei Noah haben das Entropiegesetz vorgeschlagen, um den Zusammenhang zwischen der Leistung großer Modelle, der Datenkomprimierungsrate und dem Trainingsverlust aufzudecken.
Technologie-Peripheriegeräte
KI
Die Universität für Wissenschaft und Technologie Chinas und Huawei Noah haben das Entropiegesetz vorgeschlagen, um den Zusammenhang zwischen der Leistung großer Modelle, der Datenkomprimierungsrate und dem Trainingsverlust aufzudecken.
Die Universität für Wissenschaft und Technologie Chinas und Huawei Noah haben das Entropiegesetz vorgeschlagen, um den Zusammenhang zwischen der Leistung großer Modelle, der Datenkomprimierungsrate und dem Trainingsverlust aufzudecken.


Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com China und Huaweis Arche Noah-Labor. Das Team von Professor Chen Enhong beschäftigt sich intensiv mit den Bereichen Data Mining und maschinelles Lernen und hat zahlreiche Artikel in führenden Fachzeitschriften und Konferenzen veröffentlicht, die mehr als 20.000 Mal zitiert wurden. Das Noah's Ark Laboratory ist das Huawei-Labor, das sich mit Grundlagenforschung zu künstlicher Intelligenz beschäftigt. Es verfolgt das Konzept, theoretische Forschung und Anwendungsinnovation gleichermaßen in den Vordergrund zu stellen, und setzt sich für die Förderung technologischer Innovationen und Entwicklungen im Bereich der künstlichen Intelligenz ein.
 Link zum Papier: https://arxiv.org/pdf/2407.06645
Link zum Papier: https://arxiv.org/pdf/2407.06645
Code-Link: https://github.com/USTC-StarTeam/ZIP - O Abbildung 1 tENTropiegesetz
Datenkonsistenz C: Die Konsistenz der Daten spiegelt sich in der Entropie der Wahrscheinlichkeit des nächsten Tokens angesichts der vorherigen Situation wider. Eine höhere Datenkonsistenz führt normalerweise zu einem geringeren Trainingsverlust. Durchschnittliche Datenqualität Q: spiegelt die durchschnittliche Qualität der Daten auf Stichprobenebene wider, die anhand verschiedener objektiver und subjektiver Aspekte gemessen werden kann. - Bei einer bestimmten Menge an Trainingsdaten kann die Modellleistung anhand der oben genannten Faktoren geschätzt werden:
- Bei gleichem Komprimierungsverhältnis bedeutet ein höherer Trainingsverlust eine geringere Datenkonsistenz. Daher ist das vom Modell erlernte effektive Wissen möglicherweise begrenzter. Dies kann verwendet werden, um die Leistung von LLM bei verschiedenen Daten mit ähnlichem Komprimierungsverhältnis und ähnlicher Probenqualität vorherzusagen. Die Anwendung dieser Argumentation in der Praxis werden wir später zeigen.
Trainingsverlust L: Gibt an, ob die Daten für das Modell schwer zu merken sind. Unter demselben Basismodell ist ein hoher Trainingsverlust normalerweise auf das Vorhandensein von Rauschen oder inkonsistenten Informationen im Datensatz zurückzuführen.
Da ein Datensatz mit höherer Homogenität oder besserer Datenkonsistenz vom Modell leichter zu erlernen ist, wird L erwartet in R und C monoton sein. Daher können wir die obige Formel wie folgt umschreiben: 
wobei g' eine Umkehrfunktion ist. Durch die Kombination der obigen drei Gleichungen erhalten wir: 
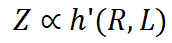
Basierend auf dem Entropiegesetz schlagen wir zwei Schlussfolgerungen vor:
- Wenn C als Konstante betrachtet wird, wird der Trainingsverlust direkt von der Kompressionsrate beeinflusst. Daher wird die Modellleistung durch das Komprimierungsverhältnis gesteuert: Wenn das Datenkomprimierungsverhältnis R höher ist, ist Z normalerweise schlechter, was in unseren Experimenten bestätigt wird.
Unter der Anleitung des Entropiegesetzes haben wir ZIP vorgeschlagen, eine Datenauswahlmethode, um Datenproben anhand der Datenkomprimierungsrate auszuwählen, mit dem Ziel, die zu maximieren Menge effektiver Informationen bei begrenztem Trainingsdatenbudget. Aus Effizienzgründen verwenden wir ein iteratives mehrstufiges Greedy-Paradigma, um Näherungslösungen mit relativ niedrigen Komprimierungsraten effizient zu erhalten. In jeder Iteration verwenden wir zunächst eine globale Auswahlphase, um einen Pool von Kandidatenproben mit niedrigem Komprimierungsverhältnis auszuwählen, um Proben mit hoher Informationsdichte zu finden. Anschließend verwenden wir eine grobkörnige lokale Auswahlstufe, um einen Satz kleinerer Stichproben auszuwählen, die mit den ausgewählten Stichproben die geringste Redundanz aufweisen. Schließlich verwenden wir eine feinkörnige lokale Auswahlstufe, um die Ähnlichkeit zwischen den hinzuzufügenden Proben zu minimieren. Der obige Prozess wird fortgesetzt, bis genügend Daten vorliegen:

Beim Vergleich verschiedener SFT-Datenauswahlalgorithmen zeigt das auf ZIP-Auswahldaten trainierte Modell Vorteile in der Leistung und ist auch in der Effizienz überlegen. Die spezifischen Ergebnisse sind in der folgenden Tabelle aufgeführt:
 Dank der modellunabhängigen und inhaltsunabhängigen Eigenschaften von ZIP kann es auch auf die Datenauswahl in der Präferenzausrichtungsphase angewendet werden. Auch die von ZIP ausgewählten Daten weisen große Vorteile auf. Die spezifischen Ergebnisse sind in der folgenden Tabelle aufgeführt: 2. Experimentelle Überprüfung des Entropiegesetzes des Modells in den vorherigen Trainingsschritten bzw. Es wurden mehrere Beziehungskurven angepasst. Die Ergebnisse sind in den Abbildungen 2 und 3 dargestellt, aus denen wir die enge Korrelation zwischen den drei Faktoren erkennen können. Erstens führen Daten mit niedriger Komprimierungsrate normalerweise zu besseren Modellergebnissen. Dies liegt daran, dass der Lernprozess von LLMs stark mit der Informationskomprimierung zusammenhängt. Wir können uns LLM als Datenkomprimierer vorstellen, sodass Daten mit niedrigerer Komprimierungsrate mehr Daten bedeuten Wissen und damit wertvoller für den Kompressor. Gleichzeitig ist zu beobachten, dass niedrigere Komprimierungsraten in der Regel mit höheren Trainingsverlusten einhergehen. Dies liegt daran, dass Daten, die schwer zu komprimieren sind, mehr Wissen enthalten, was das LLM vor größere Herausforderungen stellt, das darin enthaltene Wissen zu absorbieren.
Dank der modellunabhängigen und inhaltsunabhängigen Eigenschaften von ZIP kann es auch auf die Datenauswahl in der Präferenzausrichtungsphase angewendet werden. Auch die von ZIP ausgewählten Daten weisen große Vorteile auf. Die spezifischen Ergebnisse sind in der folgenden Tabelle aufgeführt: 2. Experimentelle Überprüfung des Entropiegesetzes des Modells in den vorherigen Trainingsschritten bzw. Es wurden mehrere Beziehungskurven angepasst. Die Ergebnisse sind in den Abbildungen 2 und 3 dargestellt, aus denen wir die enge Korrelation zwischen den drei Faktoren erkennen können. Erstens führen Daten mit niedriger Komprimierungsrate normalerweise zu besseren Modellergebnissen. Dies liegt daran, dass der Lernprozess von LLMs stark mit der Informationskomprimierung zusammenhängt. Wir können uns LLM als Datenkomprimierer vorstellen, sodass Daten mit niedrigerer Komprimierungsrate mehr Daten bedeuten Wissen und damit wertvoller für den Kompressor. Gleichzeitig ist zu beobachten, dass niedrigere Komprimierungsraten in der Regel mit höheren Trainingsverlusten einhergehen. Dies liegt daran, dass Daten, die schwer zu komprimieren sind, mehr Wissen enthalten, was das LLM vor größere Herausforderungen stellt, das darin enthaltene Wissen zu absorbieren.

Das obige ist der detaillierte Inhalt vonDie Universität für Wissenschaft und Technologie Chinas und Huawei Noah haben das Entropiegesetz vorgeschlagen, um den Zusammenhang zwischen der Leistung großer Modelle, der Datenkomprimierungsrate und dem Trainingsverlust aufzudecken.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 LLM eignet sich wirklich nicht für die Vorhersage von Zeitreihen. Es nutzt nicht einmal seine Argumentationsfähigkeit.
Jul 15, 2024 pm 03:59 PM
LLM eignet sich wirklich nicht für die Vorhersage von Zeitreihen. Es nutzt nicht einmal seine Argumentationsfähigkeit.
Jul 15, 2024 pm 03:59 PM
Können Sprachmodelle wirklich zur Zeitreihenvorhersage verwendet werden? Gemäß Betteridges Gesetz der Schlagzeilen (jede Schlagzeile, die mit einem Fragezeichen endet, kann mit „Nein“ beantwortet werden) sollte die Antwort „Nein“ lauten. Die Tatsache scheint wahr zu sein: Ein so leistungsstarkes LLM kann mit Zeitreihendaten nicht gut umgehen. Zeitreihen, also Zeitreihen, beziehen sich, wie der Name schon sagt, auf eine Reihe von Datenpunktsequenzen, die in der Reihenfolge ihres Auftretens angeordnet sind. Die Zeitreihenanalyse ist in vielen Bereichen von entscheidender Bedeutung, einschließlich der Vorhersage der Ausbreitung von Krankheiten, Einzelhandelsanalysen, Gesundheitswesen und Finanzen. Im Bereich der Zeitreihenanalyse haben viele Forscher in letzter Zeit untersucht, wie man mithilfe großer Sprachmodelle (LLM) Anomalien in Zeitreihen klassifizieren, vorhersagen und erkennen kann. Diese Arbeiten gehen davon aus, dass Sprachmodelle, die gut mit sequentiellen Abhängigkeiten in Texten umgehen können, auch auf Zeitreihen verallgemeinert werden können.
 Das erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source
Jul 17, 2024 am 02:46 AM
Das erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source
Jul 17, 2024 am 02:46 AM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Einleitung In den letzten Jahren hat die Anwendung multimodaler großer Sprachmodelle (MLLM) in verschiedenen Bereichen bemerkenswerte Erfolge erzielt. Als Grundmodell für viele nachgelagerte Aufgaben besteht aktuelles MLLM jedoch aus dem bekannten Transformer-Netzwerk, das
