
 Technologie-Peripheriegeräte
KI
Neuer Standard für KI-Bildgebung, nur 1 % der Originaldaten können die beste Leistung erzielen, allgemeines medizinisches Grundmodell veröffentlicht im Nature-Unterjournal
Technologie-Peripheriegeräte
KI
Neuer Standard für KI-Bildgebung, nur 1 % der Originaldaten können die beste Leistung erzielen, allgemeines medizinisches Grundmodell veröffentlicht im Nature-Unterjournal
Neuer Standard für KI-Bildgebung, nur 1 % der Originaldaten können die beste Leistung erzielen, allgemeines medizinisches Grundmodell veröffentlicht im Nature-Unterjournal


Herausgeber |. Kohlblatt
Das groß angelegte vorab trainierte Basismodell hat in nichtmedizinischen Bereichen große Erfolge erzielt. Das Training dieser Modelle erfordert jedoch häufig große, umfassende Datensätze, im Gegensatz zu den kleineren und spezialisierteren Datensätzen, die in der biomedizinischen Bildgebung üblich sind.
Forscher am Fraunhofer-Institut für Digitale Medizin MEVIS in Deutschland haben eine Multitasking-Lernstrategie vorgeschlagen, die die Anzahl der Trainingsaufgaben vom Speicherbedarf trennt.
Sie trainierten ein universelles biomedizinisches vorab trainiertes Modell (UMedPT) auf einer Multitasking-Datenbank, einschließlich Tomographie, Mikroskopie und Röntgenbildern, und verwendeten verschiedene Markierungsstrategien wie Klassifizierung, Segmentierung und Objekterkennung. Das UMedPT-Basismodell übertrifft die vorab trainierten ImageNet-Modelle und früheren STOA-Modelle.
In einer externen unabhängigen Validierung wurde gezeigt, dass mit UMedPT extrahierte Bildgebungsmerkmale einen neuen Standard für die zentrumsübergreifende Übertragbarkeit setzen.
Die Studie trug den Titel „Überwindung der Datenknappheit in der biomedizinischen Bildgebung mit einem grundlegenden Multitask-Modell“ und wurde am 19. Juli 2024 in „Nature Computational Science“ veröffentlicht.

Deep Learning revolutioniert nach und nach die biomedizinische Bildanalyse aufgrund seiner Fähigkeit, nützliche Bilddarstellungen zu lernen und zu extrahieren.
Die allgemeine Methode besteht darin, das Modell anhand eines großen natürlichen Bilddatensatzes (wie ImageNet oder LAION) vorab zu trainieren und es dann für bestimmte Aufgaben zu optimieren oder die vorab trainierten Funktionen direkt zu verwenden. Für die Feinabstimmung sind jedoch mehr Rechenressourcen erforderlich.
Gleichzeitig erfordert der Bereich der biomedizinischen Bildgebung eine große Menge ankommentierter Daten für ein effektives Deep-Learning-Pre-Training, aber solche Daten sind oft knapp.
Multi-Task-Lernen (MTL) bietet eine Lösung für Datenknappheit, indem ein Modell trainiert wird, um mehrere Aufgaben gleichzeitig zu lösen. Es nutzt viele kleine und mittelgroße Datensätze in der biomedizinischen Bildgebung, um Bilddarstellungen vorab zu trainieren, die für alle Aufgaben geeignet sind, und eignet sich für Bereiche mit geringen Datenmengen.
MTL wurde auf vielfältige Weise auf die biomedizinische Bildanalyse angewendet, einschließlich des Trainings aus mehreren kleinen und mittelgroßen Datensätzen für verschiedene Aufgaben und der Verwendung mehrerer Beschriftungstypen auf einem einzelnen Bild, was zeigt, dass gemeinsame Funktionen die Aufgabenleistung verbessern können.
In der neuesten Forschung führten Forscher des MEVIS-Instituts eine Multi-Task-Trainingsstrategie und eine entsprechende Modellarchitektur ein, um mehrere Datensätze mit unterschiedlichen Etikettentypen für ein groß angelegtes Vortraining zu kombinieren, insbesondere durch das Erlernen vielseitiger Darstellungen über verschiedene Modalitäten hinweg , Krankheiten und Markierungstypen, um der Datenknappheit in der biomedizinischen Bildgebung entgegenzuwirken.
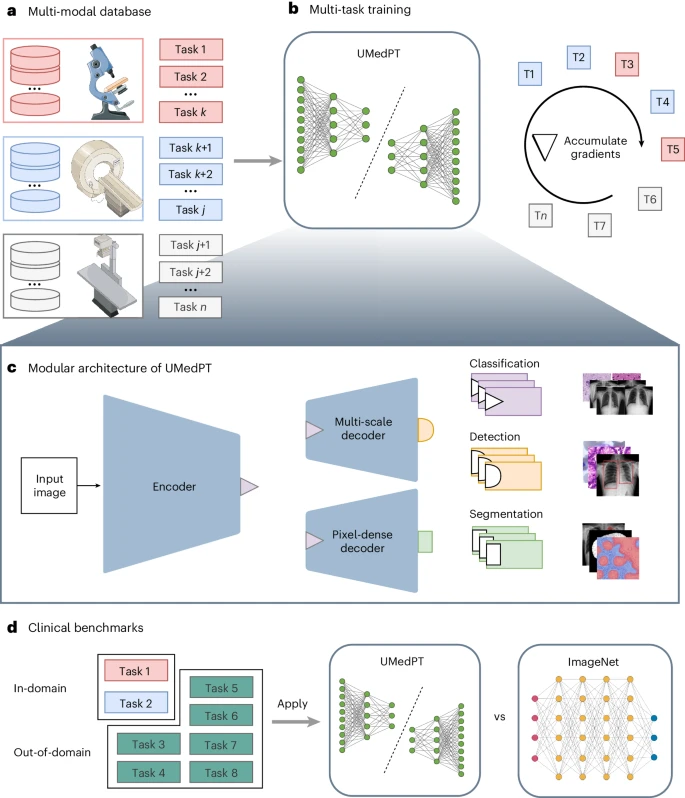
Um die Speicherbeschränkungen zu bewältigen, die beim groß angelegten Lernen mit mehreren Aufgaben auftreten, verwendet diese Methode eine auf Gradientenakkumulation basierende Trainingsschleife, deren Erweiterung durch die Anzahl der Trainingsaufgaben nahezu unbegrenzt ist.
Auf dieser Grundlage trainierten die Forscher ein vollständig überwachtes biomedizinisches Bildgebungs-Grundmodell namens UMedPT unter Verwendung von 17 Aufgaben und ihren Originalanmerkungen.
Das Bild unten zeigt die Architektur des neuronalen Netzwerks des Teams, das aus gemeinsam genutzten Blöcken einschließlich eines Encoders, Segmentierungsdecoders und Lokalisierungsdecoders sowie aufgabenspezifischen Köpfen besteht. Gemeinsam genutzte Blöcke werden so trainiert, dass sie auf alle Aufgaben vor dem Training anwendbar sind und dabei helfen, gemeinsame Funktionen zu extrahieren, während aufgabenspezifische Supervisoren labelspezifische Verlustberechnungen und -vorhersagen übernehmen.
Die gestellten Aufgaben umfassen drei überwachte Etikettentypen: Objekterkennung, Segmentierung und Klassifizierung. Beispielsweise können Klassifizierungsaufgaben binäre Biomarker modellieren, Segmentierungsaufgaben können räumliche Informationen extrahieren und Objekterkennungsaufgaben können zum Trainieren von Biomarkern basierend auf Zellzahlen verwendet werden.
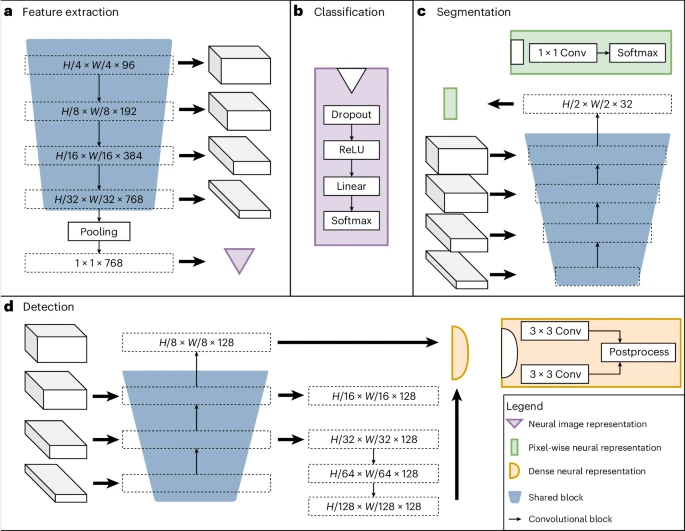
Abbildung: Architektur von UMedPT. (Quelle: Paper)
UMedPT erreicht oder übertrifft vorab trainierte ImageNet-Netzwerke sowohl bei domäneninternen als auch bei domänenexternen Aufgaben durchgängig oder übertrifft sie, während bei direkter Anwendung der Bilddarstellung (Einfrieren) und Feinabstimmungseinstellungen eine starke Leistung mit weniger Trainingsdaten aufrechterhalten wird.
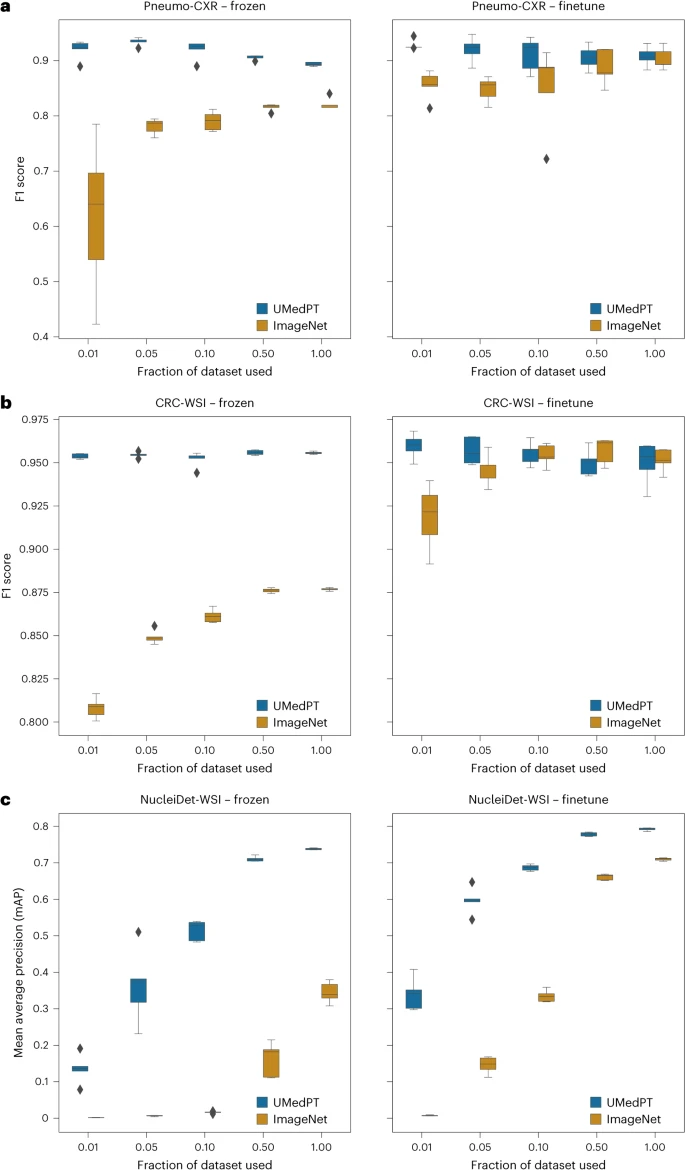
Abbildung: Ergebnisse von Aufgaben innerhalb der Domäne. (Quelle: Papier)
Für Klassifizierungsaufgaben im Zusammenhang mit vorab trainierten Datenbanken ist UMedPT in der Lage, die beste Leistung der ImageNet-Basislinie bei allen Konfigurationen zu erreichen, indem es nur 1 % der ursprünglichen Trainingsdaten verwendet. Dieses Modell erzielt mit eingefrorenen Encodern eine höhere Leistung als das Modell mit Feinabstimmung.
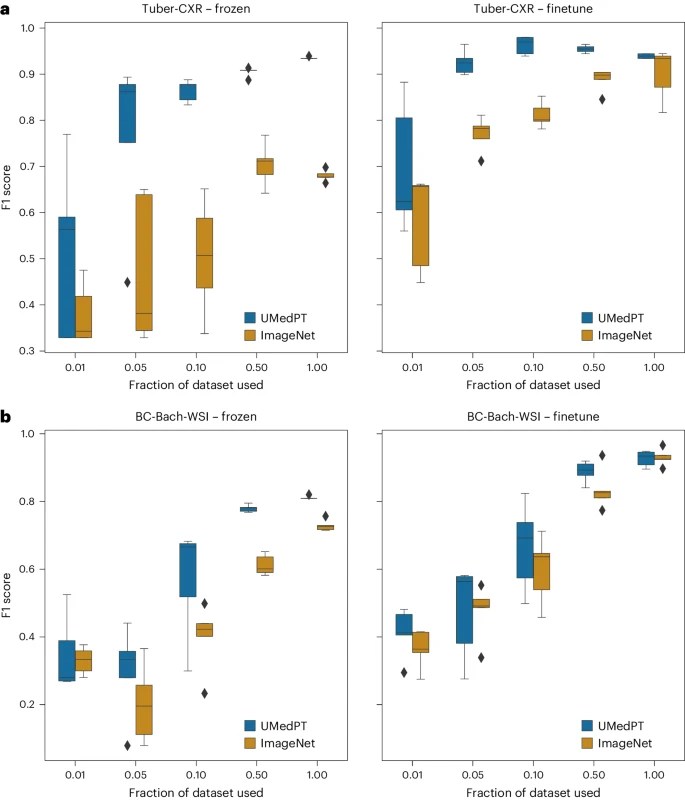
Abbildung: Ergebnisse für Aufgaben außerhalb der Domäne (Quelle: Papier)
Für Aufgaben außerhalb der Domäne ist UMedPT in der Lage, die Leistung von ImageNet mit nur 50 % oder weniger Daten zu erreichen, selbst mit Fein- Tuning angewendet.
Darüber hinaus verglichen die Forscher die Leistung von UMedPT mit Ergebnissen aus der Literatur. Bei Verwendung der eingefrorenen Encoderkonfiguration übertraf UMedPT bei den meisten Aufgaben die externen Referenzergebnisse. In dieser Einstellung übertrifft es auch die durchschnittliche Fläche unter der Kurve (AUC) in der MedMNIST-Datenbank 16.
Es ist erwähnenswert, dass die Aufgaben, bei denen die eingefrorene Anwendung von UMedPT die Referenzergebnisse nicht übertraf, außerhalb des Bereichs lagen (BC-Bach-WSI für die Brustkrebsklassifizierung und ZNS-MRT für die Diagnose von ZNS-Tumoren). Durch Feinabstimmung übertrifft das Vortraining mit UMedPT bei allen Aufgaben externe Referenzergebnisse.

Abbildung: Die Datenmenge, die UMedPT benötigt, um bei Aufgaben in verschiedenen Bildgebungsbereichen eine hochmoderne Leistung zu erzielen. (Quelle: Papier)
Als Grundlage für zukünftige Entwicklungen in datenarmen Bereichen eröffnet UMedPT die Aussicht auf Deep-Learning-Anwendungen in medizinischen Bereichen, in denen das Sammeln großer Datenmengen eine besondere Herausforderung darstellt, wie etwa seltene Krankheiten und pädiatrische Bildgebung.
Link zum Papier:https://www.nature.com/articles/s43588-024-00662-z
Verwandter Inhalt:https://www.nature.com/articles/s43588-024-00658- 9
Das obige ist der detaillierte Inhalt vonNeuer Standard für KI-Bildgebung, nur 1 % der Originaldaten können die beste Leistung erzielen, allgemeines medizinisches Grundmodell veröffentlicht im Nature-Unterjournal. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1664
1664
 14
1423
52
1321
25
1269
29
1249
24
14
1423
52
1321
25
1269
29
1249
24

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Aug 07, 2024 pm 07:08 PM
PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Aug 07, 2024 pm 07:08 PM
Im Jahr 2023 entwickeln sich fast alle Bereiche der KI in beispielloser Geschwindigkeit weiter. Gleichzeitig verschiebt die KI ständig die technologischen Grenzen wichtiger Bereiche wie der verkörperten Intelligenz und des autonomen Fahrens. Wird der Status von Transformer als Mainstream-Architektur großer KI-Modelle durch den multimodalen Trend erschüttert? Warum ist die Erforschung großer Modelle auf Basis der MoE-Architektur (Mixture of Experts) zu einem neuen Trend in der Branche geworden? Können Large Vision Models (LVM) ein neuer Durchbruch im allgemeinen Sehvermögen sein? ...Aus dem PRO-Mitglieder-Newsletter 2023 dieser Website, der in den letzten sechs Monaten veröffentlicht wurde, haben wir 10 spezielle Interpretationen ausgewählt, die eine detaillierte Analyse der technologischen Trends und industriellen Veränderungen in den oben genannten Bereichen bieten, um Ihnen dabei zu helfen, Ihre Ziele in der Zukunft zu erreichen Jahr vorbereitet sein. Diese Interpretation stammt aus Week50 2023
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Die Genauigkeitsrate erreicht 60,8 %. Das auf Transformer basierende Modell zur Vorhersage der chemischen Retrosynthese wurde in der Unterzeitschrift „Nature' veröffentlicht
Aug 06, 2024 pm 07:34 PM
Die Genauigkeitsrate erreicht 60,8 %. Das auf Transformer basierende Modell zur Vorhersage der chemischen Retrosynthese wurde in der Unterzeitschrift „Nature' veröffentlicht
Aug 06, 2024 pm 07:34 PM
Herausgeber | KX-Retrosynthese ist eine entscheidende Aufgabe in der Arzneimittelforschung und organischen Synthese, und KI wird zunehmend eingesetzt, um den Prozess zu beschleunigen. Bestehende KI-Methoden weisen eine unbefriedigende Leistung und eine begrenzte Vielfalt auf. In der Praxis verursachen chemische Reaktionen häufig lokale molekulare Veränderungen mit erheblichen Überschneidungen zwischen Reaktanten und Produkten. Davon inspiriert schlug das Team von Hou Tingjun an der Zhejiang-Universität vor, die einstufige retrosynthetische Vorhersage als eine Aufgabe zur Bearbeitung molekularer Ketten neu zu definieren und dabei die Zielmolekülkette iterativ zu verfeinern, um Vorläuferverbindungen zu erzeugen. Außerdem wird ein bearbeitungsbasiertes retrosynthetisches Modell EditRetro vorgeschlagen, mit dem qualitativ hochwertige und vielfältige Vorhersagen erzielt werden können. Umfangreiche Experimente zeigen, dass das Modell beim Standard-Benchmark-Datensatz USPTO-50 K eine hervorragende Leistung mit einer Top-1-Genauigkeit von 60,8 % erzielt.
