
 Technologie-Peripheriegeräte
KI
TPAMI 2024 |. ProCo: Long-Tail-Kontrast-Lernen unendlicher Kontrastpaare
Technologie-Peripheriegeräte
KI
TPAMI 2024 |. ProCo: Long-Tail-Kontrast-Lernen unendlicher Kontrastpaare
TPAMI 2024 |. ProCo: Long-Tail-Kontrast-Lernen unendlicher Kontrastpaare


Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Du Chaoqun, der Erstautor dieses Artikels, ist ein direkter Doktorand im Jahr 2020 in der Abteilung für Automatisierung der Tsinghua-Universität. Der Tutor ist außerordentlicher Professor Huang Gao. Zuvor erhielt er einen Bachelor of Science vom Fachbereich Physik der Tsinghua-Universität. Zu seinen Forschungsinteressen gehören Modellverallgemeinerung und Robustheitsforschung zu verschiedenen Datenverteilungen, wie z. B. Long-Tail-Lernen, halbüberwachtes Lernen, Transferlernen usw. Veröffentlichte zahlreiche Artikel in erstklassigen internationalen Fachzeitschriften und Konferenzen wie TPAMI und ICML.
Persönliche Homepage: https://andy-du20.github.io
Dieser Artikel stellt einen Artikel der Tsinghua University zur visuellen Long-Tail-Erkennung vor: Probabilistic Contrastive Learning for Long-Tailed Visual Recognition TPAMI 2024 akzeptiert, der Code ist Open Source.
Diese Forschung konzentriert sich hauptsächlich auf die Anwendung des kontrastiven Lernens bei visuellen Erkennungsaufgaben mit langem Schwanz. Sie schlägt eine neue kontrastive Lernmethode mit langem Schwanz vor. Durch die Verbesserung des Kontrastverlusts wird kontrastives Lernen einer unbegrenzten Anzahl von Kontrastpaaren erreicht. Das Problem effektiv lösen. Überwachtes kontrastives Lernen [1] ist inhärent von der Stapelgröße (Speicherbankgröße) abhängig. Zusätzlich zu visuellen Long-Tail-Klassifizierungsaufgaben wurde diese Methode auch mit halbüberwachtem Long-Tail-Lernen, Long-Tail-Objekterkennung und ausgewogenen Datensätzen experimentiert, wodurch erhebliche Leistungsverbesserungen erzielt wurden.

- Papierlink: https://arxiv.org/pdf/2403.06726
- Projektlink: https://github.com/LeapLabTHU/ProCo
Vergleich Der Lernerfolg beim selbstüberwachten Lernen zeigt seine Wirksamkeit beim Erlernen visueller Merkmalsdarstellungen. Der Hauptfaktor, der die kontrastive Lernleistung beeinflusst, ist die Anzahl der „kontrastiven Paare“, die es dem Modell ermöglicht, aus mehr negativen Stichproben zu lernen, was sich in den beiden repräsentativsten Methoden SimCLR [2] und MoCo [3] widerspiegelt Größe der Speicherbank. Bei visuellen Long-Tail-Erkennungsaufgaben führt der Gewinn durch die Erhöhung der Anzahl der Kontrastpaare jedoch aufgrund des „Kategorienungleichgewichts“ zu einem schwerwiegenden „marginalen Verminderungseffekt“. Dies liegt daran, dass die meisten Kontrastpaare aus Kopfkategorien bestehen . Da es sich um Stichproben handelt, ist es schwierig, die Endkategorien abzudecken
.Wenn beispielsweise im Long-Tail-Imagenet-Datensatz die Stapelgröße (Speicherbank) auf die üblichen 4096 und 8192 eingestellt ist, gibt es in jedem Stapel (Speicher) durchschnittlich 212 und 89 Kategorien Bank) bzw. die Stichprobengröße ist kleiner als eins. Daher besteht die Kernidee der ProCo-Methode darin, auf dem Long-Tail-Datensatz die Verteilung jedes Datentyps zu modellieren, Parameter zu schätzen und daraus Stichproben zu ziehen, um kontrastierende Paare zu bilden und sicherzustellen, dass alle Kategorien vorhanden sein können bedeckt. Wenn die Anzahl der Proben gegen unendlich tendiert, kann die erwartete analytische Lösung des Kontrastverlusts außerdem strikt theoretisch abgeleitet werden, sodass sie direkt als Optimierungsziel verwendet werden kann, um eine ineffiziente Abtastung von Kontrastpaaren zu vermeiden und eine unbegrenzte Anzahl von Kontrasten zu erreichen Paare. Vergleichendes Lernen.
Allerdings gibt es mehrere Hauptschwierigkeiten bei der Umsetzung der oben genannten Ideen: Wie man die Verteilung jedes Datentyps modelliert.
Wie man die Parameter einer Verteilung effizient schätzt, insbesondere für Tail-Kategorien mit einer kleinen Anzahl von Stichproben.
So stellen Sie sicher, dass die erwartete analytische Lösung des Kontrastverlusts vorliegt und berechnet werden kann.
Tatsächlich können die oben genannten Probleme durch ein einheitliches Wahrscheinlichkeitsmodell gelöst werden, das heißt, eine einfache und effektive Wahrscheinlichkeitsverteilung wird zur Modellierung der charakteristischen Verteilung ausgewählt, sodass die Maximum-Likelihood-Schätzung zur effizienten Schätzung der Parameter von verwendet werden kann die Verteilung und Berechnung. Erwarten Sie eine analytische Lösung für den Kontrastverlust.
Da die Merkmale des kontrastiven Lernens auf der Einheitshypersphäre verteilt sind, besteht eine praktikable Lösung darin, die von Mises-Fisher-Verteilung (vMF) auf der Kugel als Merkmalsverteilung auszuwählen (diese Verteilung ähnelt der Normalverteilung auf der Kugel). . Die Maximum-Likelihood-Schätzung der vMF-Verteilungsparameter verfügt über eine näherungsweise analytische Lösung und basiert nur auf der Momentenstatistik erster Ordnung des Merkmals. Daher können die Parameter der Verteilung effizient geschätzt und die Erwartung eines Kontrastverlusts dadurch streng abgeleitet werden Erzielung des Vergleichs einer unbegrenzten Anzahl von Kontrastpaaren.
그림 1 ProCo 알고리즘은 다양한 배치의 특성을 기반으로 샘플 분포를 추정합니다. 무제한의 샘플을 샘플링함으로써 예상되는 대조 손실에 대한 분석 솔루션을 얻을 수 있으며 지도 대조 학습의 고유한 종속성을 효과적으로 제거할 수 있습니다. 배치 크기(메모리 뱅크) 크기.
방법 세부 사항
다음에서는 분포 가정, 매개변수 추정, 최적화 목표 및 이론적 분석의 네 가지 측면에서 ProCo 방법을 자세히 소개합니다.
분포 가정
앞서 언급했듯이 대조 학습의 기능은 단위 하이퍼스피어로 제한됩니다. 따라서 이러한 특징이 따르는 분포는 von Mises-Fisher(vMF) 분포라고 가정할 수 있으며 그 확률 밀도 함수는 다음과 같습니다. 
여기서 z는 p차원 특징의 단위 벡터이고 I는 수정된 제1종 베셀 함수
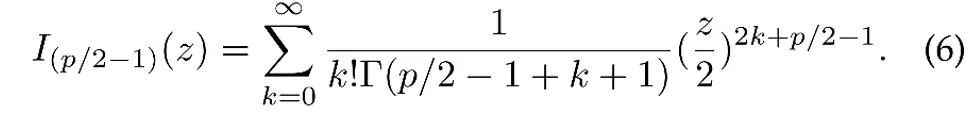
μ는 분포의 평균 방향이고, κ는 분포의 집중도를 제어하는 농도 모수입니다. κ가 더 클 경우 평균 근처에 샘플이 클러스터링되는 정도입니다. κ =0일 때 vMF 분포는 구형으로 변질됩니다.
매개변수 추정
위의 분포 가정을 기반으로 데이터 특징의 전체 분포는 혼합 vMF 분포이며, 여기서 각 범주는 vMF 분포에 해당합니다.

여기서 매개변수  는 훈련 세트의 카테고리 y의 빈도에 해당하는 각 카테고리의 사전 확률을 나타냅니다. 특징 분포의 평균 벡터
는 훈련 세트의 카테고리 y의 빈도에 해당하는 각 카테고리의 사전 확률을 나타냅니다. 특징 분포의 평균 벡터  및 집중 매개변수
및 집중 매개변수  는 최대 우도 추정을 통해 추정됩니다.
는 최대 우도 추정을 통해 추정됩니다.
N개의 독립 단위 벡터가 카테고리 y의 vMF 분포에서 샘플링되었다고 가정하면 평균 방향 및 농도 매개변수의 최대 우도 추정(대략)[4]은 다음 방정식을 만족합니다.
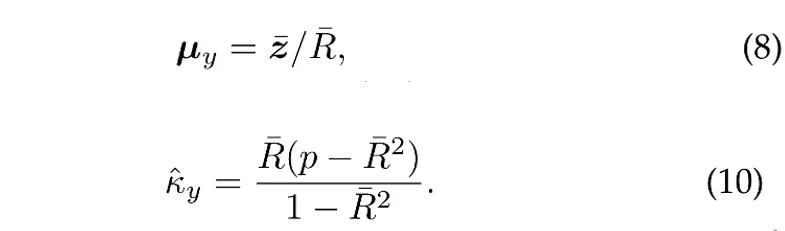
여기서  는 샘플입니다. 평균,
는 샘플입니다. 평균,  은 표본 평균의 계수 길이입니다. 또한, ProCo는 과거 표본을 활용하기 위해 꼬리 카테고리의 매개변수를 효과적으로 추정할 수 있는 온라인 추정 방법을 채택합니다.
은 표본 평균의 계수 길이입니다. 또한, ProCo는 과거 표본을 활용하기 위해 꼬리 카테고리의 매개변수를 효과적으로 추정할 수 있는 온라인 추정 방법을 채택합니다.
최적화 목표
추정된 매개변수를 기반으로 하는 간단한 접근 방식은 혼합 vMF 분포에서 샘플링하여 대조 쌍을 구성하는 것입니다. 그러나 각 훈련 반복에서 vMF 분포에서 많은 수의 샘플을 샘플링하는 것은 비효율적입니다. 따라서 본 연구에서는 이론적으로 샘플 수를 무한대로 확장하고, 예상 대비 손실 함수의 분석적 해를 엄격하게 도출하여 최적화 목표로 삼았다.

훈련 과정에서 추가 기능 분기(이 최적화 목표를 기반으로 한 표현 학습)를 도입함으로써 이 분기는 분류 분기와 함께 훈련될 수 있으며 추론 시 분류 분기만 필요하므로 증가하지 않습니다. 비용. 두 가지 손실의 가중합을 최종 최적화 목표로 사용하고 실험에서는 α=1로 설정합니다. 최종적으로 ProCo 알고리즘의 전체 과정은 다음과 같습니다. 이론적 분석
 ProCo 방법의 유효성을 이론적으로 검증하기 위해 연구진은 일반화 오류 한계와 초과 위험 한계를 분석했습니다. 분석을 단순화하기 위해 여기서는 y∈{-1,+1}이라는 두 가지 범주만 있다고 가정합니다. 분석 결과 일반화 오류 경계는 주로 훈련 샘플 수와 데이터 분산에 의해 제어되는 것으로 나타났습니다. 이 결과는 관련 연구[6][7]의 이론적 분석과 일치하여 ProCo 손실이 추가 요인을 도입하지 않고 일반화 오류 한계를 증가시키지 않는다는 것을 보장하며 이론적으로 이 방법의 효율성을 보장합니다.
ProCo 방법의 유효성을 이론적으로 검증하기 위해 연구진은 일반화 오류 한계와 초과 위험 한계를 분석했습니다. 분석을 단순화하기 위해 여기서는 y∈{-1,+1}이라는 두 가지 범주만 있다고 가정합니다. 분석 결과 일반화 오류 경계는 주로 훈련 샘플 수와 데이터 분산에 의해 제어되는 것으로 나타났습니다. 이 결과는 관련 연구[6][7]의 이론적 분석과 일치하여 ProCo 손실이 추가 요인을 도입하지 않고 일반화 오류 한계를 증가시키지 않는다는 것을 보장하며 이론적으로 이 방법의 효율성을 보장합니다.
또한 이 방법은 특성 분포 및 매개변수 추정에 대한 특정 가정에 의존합니다. 이러한 매개변수가 모델 성능에 미치는 영향을 평가하기 위해 연구진은 추정된 매개변수를 사용하여 예상되는 위험과 실제 분포에 있는 베이즈 최적 위험 사이의 편차를 측정하는 ProCo 손실의 초과 위험 한계도 분석했습니다. 매개변수.

이는 ProCo 손실의 초과 위험이 주로 매개변수 추정 오류의 1차 항에 의해 제어된다는 것을 보여줍니다.
실험 결과
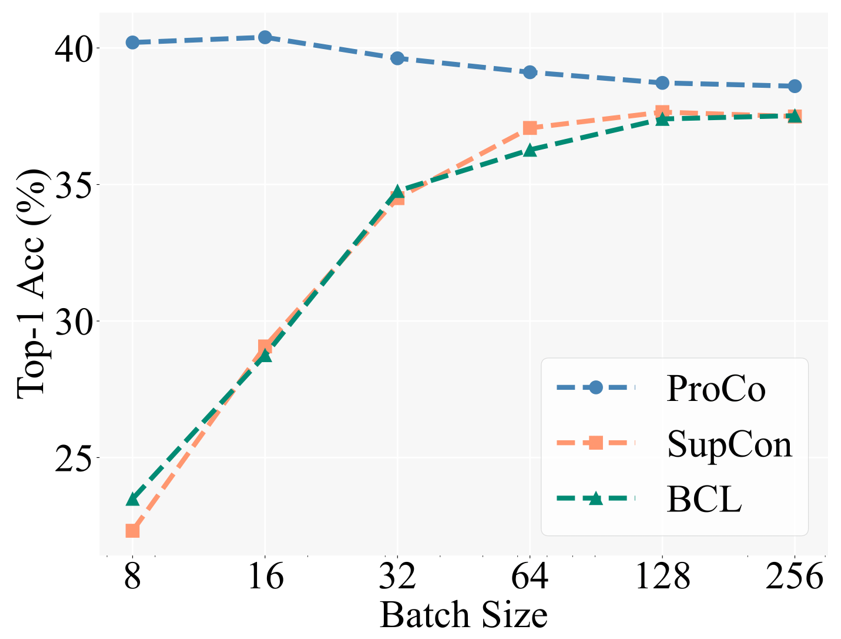
핵심 동기를 검증하기 위해 연구자들은 먼저 다양한 배치 크기에서 다양한 대조 학습 방법의 성능을 비교했습니다. Baseline에는 롱테일 인식 작업에서 SCL을 기반으로 한 향상된 방법인 BCL(Balanced Contrastive Learning)이 포함되어 있습니다. 특정 실험 설정은 지도 학습(SCL)의 2단계 훈련 전략을 따릅니다. 즉, 먼저 표현 학습 훈련에 대비 손실만 사용한 다음 동결 백본을 사용하여 테스트하기 위해 선형 분류기를 훈련합니다.
아래 그림은 CIFAR100-LT(IF100) 데이터 세트에 대한 실험 결과를 보여줍니다. BCL 및 SupCon의 성능은 배치 크기에 따라 분명히 제한되지만 ProCo는 기능을 도입하여 SupCon이 배치 크기에 미치는 영향을 효과적으로 제거합니다. 각 카테고리의 의존성을 분산시켜 다양한 배치 크기에서 최고의 성능을 달성합니다.
또한 연구원들은 롱테일 인식 작업, 롱테일 준지도 학습, 롱테일 객체 감지 및 균형 잡힌 데이터 세트에 대한 실험도 수행했습니다. 여기서는 주로 대규모 롱테일 데이터 세트 Imagenet-LT 및 iNaturalist2018에 대한 실험 결과를 보여줍니다. 첫째, 90세대의 훈련 일정에서 대조 학습을 개선하는 유사한 방법과 비교하여 ProCo는 두 개의 데이터 세트와 두 개의 백본에서 최소 1%의 성능 향상을 보였습니다.

다음 결과는 ProCo가 400 epoch 일정에서 더 긴 훈련 일정을 통해 이점을 얻을 수 있음을 추가로 보여줍니다. ProCo는 iNaturalist2018 데이터 세트에서 SOTA 성능을 달성했으며 다른 A가 아닌 조합과도 경쟁할 수 있음을 확인했습니다. 증류(NCL) 및 기타 방법을 포함한 대조 학습 방법. "시각적 표현의 대조 학습을 위한 간단한 프레임워크." PMLR에 관한 국제 회의, 2020.

- S . Sra, "von Mises-fisher 분포의 매개변수 근사에 대한 짧은 참고 사항: 및 is(x)의 빠른 구현", 계산 통계, 2012.
-
J. Zhu, et al. "긴 꼬리 시각적 인식을 위한 균형 잡힌 대조 학습", CVPR, 2022. - W. Jitkrittum, et al. "ELM: 긴 꼬리 학습을 위한 임베딩 및 로짓 마진," arXiv 사전 인쇄, 2022.
- A. K. Menon, et al. "로짓 조정을 통한 롱테일 학습", ICLR, 2021.
Das obige ist der detaillierte Inhalt vonTPAMI 2024 |. ProCo: Long-Tail-Kontrast-Lernen unendlicher Kontrastpaare. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 LLM eignet sich wirklich nicht für die Vorhersage von Zeitreihen. Es nutzt nicht einmal seine Argumentationsfähigkeit.
Jul 15, 2024 pm 03:59 PM
LLM eignet sich wirklich nicht für die Vorhersage von Zeitreihen. Es nutzt nicht einmal seine Argumentationsfähigkeit.
Jul 15, 2024 pm 03:59 PM
Können Sprachmodelle wirklich zur Zeitreihenvorhersage verwendet werden? Gemäß Betteridges Gesetz der Schlagzeilen (jede Schlagzeile, die mit einem Fragezeichen endet, kann mit „Nein“ beantwortet werden) sollte die Antwort „Nein“ lauten. Die Tatsache scheint wahr zu sein: Ein so leistungsstarkes LLM kann mit Zeitreihendaten nicht gut umgehen. Zeitreihen, also Zeitreihen, beziehen sich, wie der Name schon sagt, auf eine Reihe von Datenpunktsequenzen, die in der Reihenfolge ihres Auftretens angeordnet sind. Die Zeitreihenanalyse ist in vielen Bereichen von entscheidender Bedeutung, einschließlich der Vorhersage der Ausbreitung von Krankheiten, Einzelhandelsanalysen, Gesundheitswesen und Finanzen. Im Bereich der Zeitreihenanalyse haben viele Forscher in letzter Zeit untersucht, wie man mithilfe großer Sprachmodelle (LLM) Anomalien in Zeitreihen klassifizieren, vorhersagen und erkennen kann. Diese Arbeiten gehen davon aus, dass Sprachmodelle, die gut mit sequentiellen Abhängigkeiten in Texten umgehen können, auch auf Zeitreihen verallgemeinert werden können.
 Das erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source
Jul 17, 2024 am 02:46 AM
Das erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source
Jul 17, 2024 am 02:46 AM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Einleitung In den letzten Jahren hat die Anwendung multimodaler großer Sprachmodelle (MLLM) in verschiedenen Bereichen bemerkenswerte Erfolge erzielt. Als Grundmodell für viele nachgelagerte Aufgaben besteht aktuelles MLLM jedoch aus dem bekannten Transformer-Netzwerk, das
