

Für KI ist die Mathematikolympiade kein Problem mehr.
Am Donnerstag hat die künstliche Intelligenz von Google DeepMind ein Kunststück vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen.

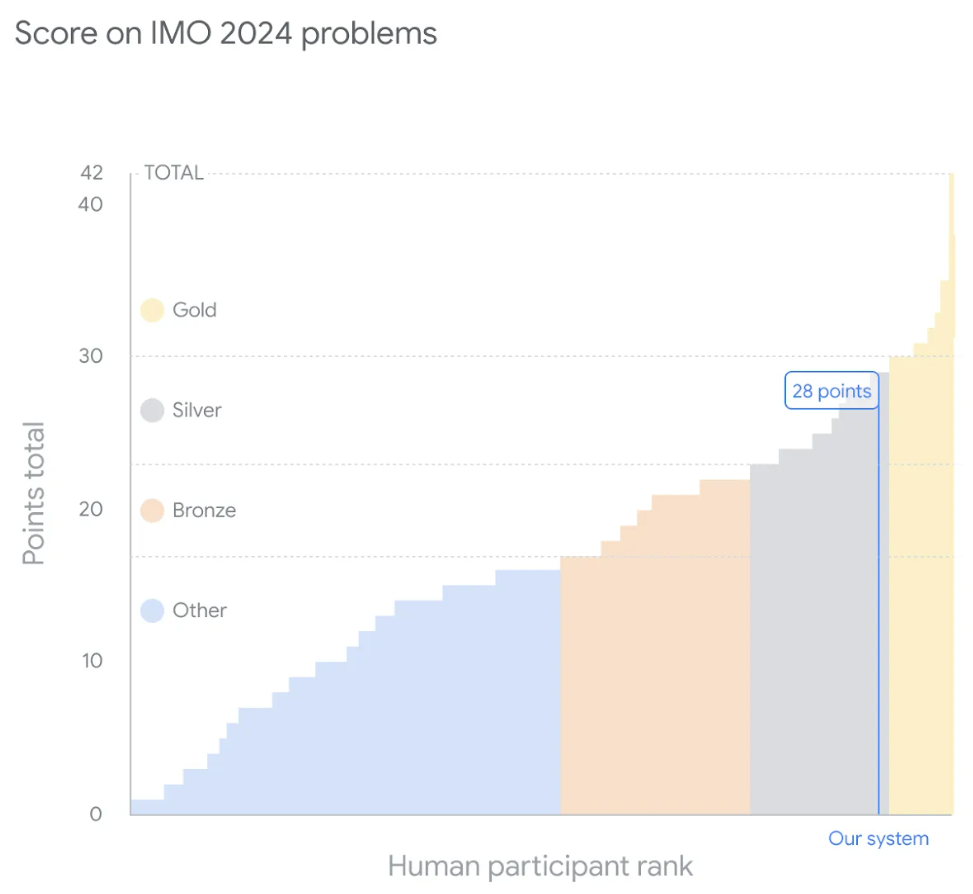
Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte insgesamt sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaille.
Zu Beginn dieses Monats hat der UCLA-Professor Terence Tao gerade die „KI-Matheolympiade“ (AIMO Progress Award) mit einem Preisgeld in Höhe von einer Million Dollar beworben. Unerwarteterweise hat sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert.
Lösen Sie Fragen gleichzeitig auf IMO und stellen Sie die schwierigsten Fragen richtigIMO ist der älteste, größte und prestigeträchtigste Wettbewerb für junge Mathematiker, der seit 1959 jährlich stattfindet. In jüngster Zeit wurde der IMO-Wettbewerb auch weithin als große Herausforderung im Bereich des maschinellen Lernens anerkannt und hat sich zu einem idealen Maßstab für die Messung der fortgeschrittenen mathematischen Denkfähigkeiten von Systemen der künstlichen Intelligenz entwickelt.
Beim diesjährigen IMO-Wettbewerb gelang AlphaProof und AlphaGeometry 2, die vom DeepMind-Team entwickelt wurden, gemeinsam ein Meilenstein.
Daunter ist AlphaProof ein verstärkendes Lernsystem für formales mathematisches Denken, während AlphaGeometry 2 eine verbesserte Version von DeepMinds Geometrielösungssystem AlphaGeometry ist.
Dieser Durchbruch zeigt das Potenzial der künstlichen allgemeinen Intelligenz (AGI) mit fortschrittlichen mathematischen Denkfähigkeiten, um neue Bereiche der Wissenschaft und Technologie zu erschließen.
Wie nimmt das KI-System von DeepMind am IMO-Wettbewerb teil?
Einfach ausgedrückt werden diese mathematischen Probleme zunächst manuell in eine formale mathematische Sprache übersetzt, damit das KI-System sie verstehen kann. Beim offiziellen Wettbewerb geben menschliche Teilnehmer ihre Antworten in zwei Sitzungen (zwei Tagen) mit einem Zeitlimit von 4,5 Stunden pro Sitzung ab. Das kombinierte KI-System AlphaProof+AlphaGeometry 2 löste ein Problem in wenigen Minuten, die anderen benötigten jedoch drei Tage. Wenn Sie sich jedoch strikt an die Regeln halten, ist im System von DeepMind eine Zeitüberschreitung aufgetreten. Einige Leute spekulieren, dass dies eine Menge brutaler Gewalt zum Knacken beinhalten könnte.
 Google sagte, AlphaProof habe zwei algebraische Probleme und ein zahlentheoretisches Problem gelöst, indem es die Antworten ermittelt und ihre Richtigkeit bewiesen habe. Dazu gehört das schwierigste Problem des Wettbewerbs, das bei der diesjährigen IMO nur fünf Teilnehmer gelöst haben. Und AlphaGeometry 2 beweist ein Geometrieproblem.
Google sagte, AlphaProof habe zwei algebraische Probleme und ein zahlentheoretisches Problem gelöst, indem es die Antworten ermittelt und ihre Richtigkeit bewiesen habe. Dazu gehört das schwierigste Problem des Wettbewerbs, das bei der diesjährigen IMO nur fünf Teilnehmer gelöst haben. Und AlphaGeometry 2 beweist ein Geometrieproblem.
Die Lösung durch KI: https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/imo-2024-solutions/index.html
IMO-Goldmedaillengewinner und Fields-Medaillengewinner Timothy Gowers und Dr. Joseph Myers, zweifacher IMO-Goldmedaillengewinner und Vorsitzender des IMO 2024 Problem Selection Committee, bewertete die vom kombinierten System bereitgestellten Lösungen gemäß den IMO-Bewertungsregeln.
Jede der sechs Fragen ist 7 Punkte wert, was einer maximalen Gesamtpunktzahl von 42 Punkten entspricht. Das System von DeepMind erhielt eine Endpunktzahl von 28, was bedeutet, dass alle vier gelösten Probleme eine perfekte Punktzahl erhielten – was der höchsten Punktzahl in der Silbermedaillenkategorie entspricht. Die diesjährige Goldmedaille lag bei 29 Punkten, und 58 der 609 Teilnehmer des offiziellen Wettbewerbs gewannen Goldmedaillen.
AlphaProof: eine formale Argumentationsmethode
Im hybriden KI-System von Google handelt es sich bei AlphaProof um ein selbst trainiertes System, das die formale Sprache Lean nutzt, um mathematische Aussagen zu beweisen. Es kombiniert ein vorab trainiertes Sprachmodell mit dem AlphaZero-Algorithmus für verstärktes Lernen.
Unter diesen bieten formale Sprachen wichtige Vorteile für die formale Überprüfung der Richtigkeit mathematischer Argumentationsbeweise. Bisher war dies beim maschinellen Lernen nur begrenzt von Nutzen, da die Menge der von Menschen geschriebenen Daten sehr begrenzt war.
Im Gegensatz dazu haben auf natürlicher Sprache basierende Methoden zwar Zugriff auf größere Datenmengen, erzeugen aber Zwischenschritte und Lösungen, die vernünftig, aber falsch erscheinen.
Google DeepMind schlägt eine Brücke zwischen diesen beiden komplementären Bereichen, indem es das Gemini-Modell verfeinert, um Problemstellungen in natürlicher Sprache automatisch in formale Aussagen zu übersetzen und so eine große Bibliothek formaler Probleme mit unterschiedlichen Schwierigkeitsgraden zu erstellen.
Bei einem mathematischen Problem generiert AlphaProof Kandidatenlösungen und beweist diese dann, indem es nach möglichen Beweisschritten in Lean sucht. Jede gefundene und verifizierte Beweislösung wird verwendet, um das Sprachmodell von AlphaProof zu stärken und seine Fähigkeit zur Lösung nachfolgender anspruchsvollerer Probleme zu verbessern.
為訓練 AlphaProof,Google DeepMind 在 IMO 比賽前幾週內證明或反證明了涵蓋廣泛難度與主題的數百萬個數學問題。比賽期間也應用了訓練 loop,以強化自生成競賽題變體的證明,直到找到完整的解決方案。
 AlphaProof 強化學習訓練 loop 過程資訊圖:約一百萬個非形式化數學問題被形式化網路翻譯成形式化數學語言。然後,求解器網路搜尋問題的證明或反證,透過 AlphaZero 演算法逐步訓練自己解決更具挑戰性的問題。
AlphaProof 強化學習訓練 loop 過程資訊圖:約一百萬個非形式化數學問題被形式化網路翻譯成形式化數學語言。然後,求解器網路搜尋問題的證明或反證,透過 AlphaZero 演算法逐步訓練自己解決更具挑戰性的問題。
更具競爭力的 AlphaGeometry 2
AlphaGeometry 2 是今年登上《自然》雜誌的數學 AI AlphaGeometry 的重大改進版本。它是一個神經 - 符號混合系統,其中的語言模型基於 Gemini,並在比其前身多一個數量級的合成資料上從頭開始訓練。這有助於該模型解決更具挑戰性的幾何問題,包括有關物體運動以及角度、比例或距離方程式的問題。
AlphaGeometry 2 採用的符號引擎比上一代產品快兩個數量級。當遇到新問題時,新穎的知識共享機制可實現不同搜尋樹的高階組合,以解決更複雜的問題。
在今年的比賽之前,AlphaGeometry 2 可以解決過去 25 年中所有 IMO 幾何歷史問題的 83%,而其前身的解決率僅為 53%。在 IMO 2024 中,AlphaGeometry 2 在收到問題 4 的形式化後 19 秒內就解決了它。
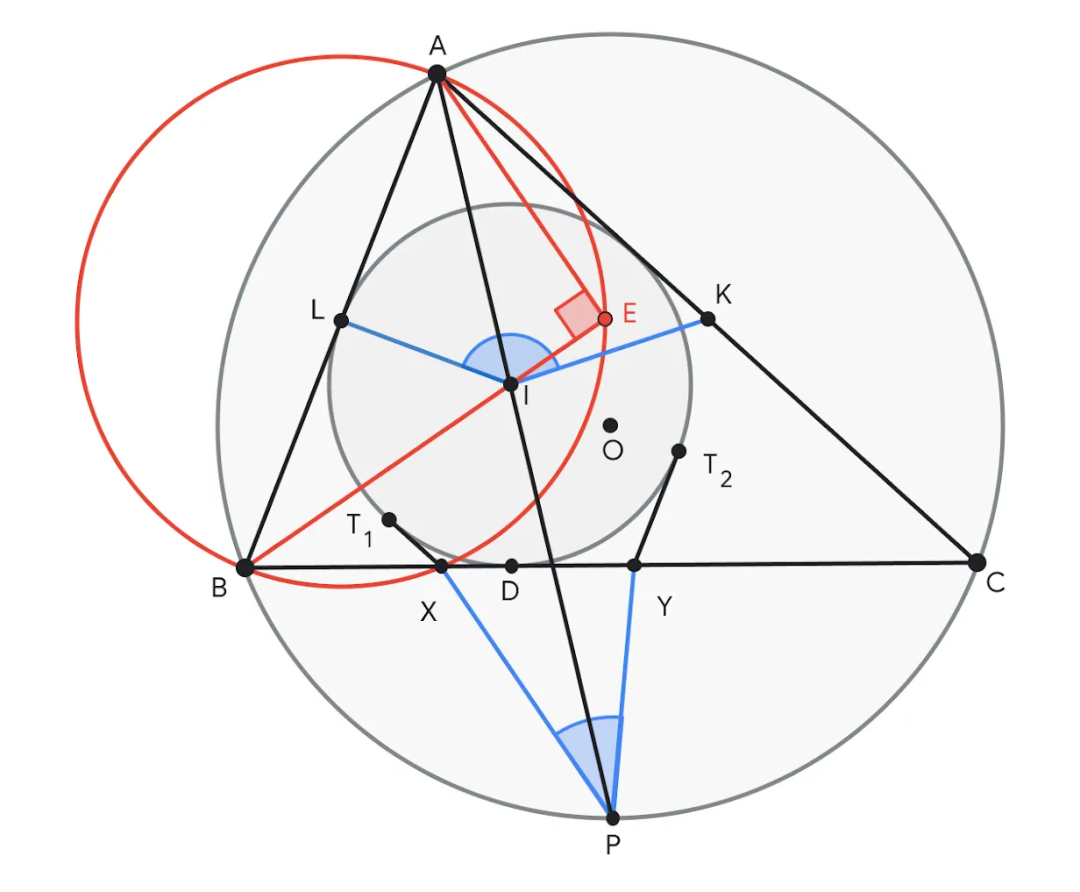
問題 4 的範例,要求證明∠KIL 與∠XPY 的和等於 180°。 AlphaGeometry 2 提議在直線 BI 上建構點 E,使得∠AEB = 90°。點 E 有助於賦予線段 AB 中點 L 以意義,從而創建許多對相似三角形,如 ABE ~ YBI 和 ALE ~ IPC,以證明結論。
谷歌 DeepMind 也報告說,作為 IMO 工作的一部分,研究人員還試驗了一種基於 Gemini 和一種最新的自然語言推理系統,希望實現高級的問題解決能力。該系統不需要將問題翻譯成正式語言,並且可以與其他 AI 系統結合。在今年的 IMO 賽題的測試中「顯示出了巨大的潛力」。
谷歌正在繼續探索推進數學推理的 AI 方法,並計劃很快發布有關 AlphaProof 的更多技術細節。
我們對未來充滿期待,數學家們將使用AI 工具探索假設,嘗試大膽的新方法來解決長期存在的問題,并快速完成耗時的證明元素——而像Gemini 這樣的AI 系統將在數學和更廣泛的推理方面變得更加強大。
研究團隊
Google表示,新研究得到了國際數學奧林匹克研究團隊
谷歌表示,新研究得到了國際數學奧林匹克組織的支持,此外: AlphaProof 的開發由Thomas Hubert、Rishi Mehta 和Laurent Sartran 領導;主要貢獻者包括Hussain Masoom、Aja Huain、Aja Huain Miklós Z. Horváth、Tom Zahavy、Vivek Veeriah、Eric Wieser、Jessica Yung、Lei Yu、Yannick Schroecker、Julian Schrittwieser、Ottavia Bertolli、Borja Ibarz、Edward Lockhart、Edward Hughes、Mark Rowland 和Grace Margand。
AlphaProof 的開發由Thomas Hubert、Rishi Mehta 和Laurent Sartran 領導;主要貢獻者包括Hussain Masoom、Aja Huain、Aja Huain Miklós Z. Horváth、Tom Zahavy、Vivek Veeriah、Eric Wieser、Jessica Yung、Lei Yu、Yannick Schroecker、Julian Schrittwieser、Ottavia Bertolli、Borja Ibarz、Edward Lockhart、Edward Hughes、Mark Rowland 和Grace Margand。
 其中,Aja Huang、Julian Schrittwieser、Yannick Schroecker 等成員也是 8 年前(2016 年)AlphaGo 論文的核心成員。 8 年前,他們基於強化學習打造的 AlphaGo 而聲名大噪。 8 年後,強化學習在 AlphaProof 中再次大放異彩。有人在朋友圈感嘆說:RL is so back!
其中,Aja Huang、Julian Schrittwieser、Yannick Schroecker 等成員也是 8 年前(2016 年)AlphaGo 論文的核心成員。 8 年前,他們基於強化學習打造的 AlphaGo 而聲名大噪。 8 年後,強化學習在 AlphaProof 中再次大放異彩。有人在朋友圈感嘆說:RL is so back!
 AlphaGeometry 2 和自然語言推理工作由 Thang Luong 領導。 AlphaGeometry 2 的開發由 Trieu Trinh 和 Yuri Chervonyi 領導,Mirek Olšák、Xiaomeng Yang、Hoang Nguyen、Junehyuk Jung、Dawsen Hwang 和 Marcelo Menegali 做出了重要貢獻。
AlphaGeometry 2 和自然語言推理工作由 Thang Luong 領導。 AlphaGeometry 2 的開發由 Trieu Trinh 和 Yuri Chervonyi 領導,Mirek Olšák、Xiaomeng Yang、Hoang Nguyen、Junehyuk Jung、Dawsen Hwang 和 Marcelo Menegali 做出了重要貢獻。
此外,David Silver、Quoc Le、哈薩比斯和 Pushmeet Kohli 負責協調和管理整個專案。
參考內容:
🎜https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/🎜🎜Das obige ist der detaillierte Inhalt vonGoogle AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist das Format von caj
Was ist das Format von caj
 So installieren Sie ein Linux-System
So installieren Sie ein Linux-System
 Was sind die Unterschiede zwischen Weblogic und Tomcat?
Was sind die Unterschiede zwischen Weblogic und Tomcat?
 vscode führt die C-Sprache aus
vscode führt die C-Sprache aus
 So lösen Sie verstümmelte chinesische Tomcat-Zeichen
So lösen Sie verstümmelte chinesische Tomcat-Zeichen
 Der Unterschied zwischen leichtgewichtigen Anwendungsservern und Cloud-Servern
Der Unterschied zwischen leichtgewichtigen Anwendungsservern und Cloud-Servern
 Welche Software ist Xiaohongshu?
Welche Software ist Xiaohongshu?
 So schließen Sie Secure Boot
So schließen Sie Secure Boot








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



