
 Technologie-Peripheriegeräte
KI
PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Technologie-Peripheriegeräte
KI
PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?

Im Jahr 2023 entwickeln sich fast alle Bereiche der KI in beispielloser Geschwindigkeit weiter. Gleichzeitig verschiebt die KI ständig die technologischen Grenzen wichtiger Bereiche wie der verkörperten Intelligenz und des autonomen Fahrens. Wird Transformer angesichts des multimodalen Trends als Mainstream-Architektur für große KI-Modelle ins Wanken geraten? Warum ist die Erforschung großer Modelle auf Basis der MoE-Architektur (Mixture of Experts) zu einem neuen Trend in der Branche geworden? Kann das Large Vision Model (LVM) ein neuer Durchbruch im allgemeinen Sehvermögen werden? ...Aus dem PRO-Mitglieder-Newsletter 2023 dieser Website, der in den letzten sechs Monaten veröffentlicht wurde, haben wir 10 spezielle Interpretationen ausgewählt, die eine detaillierte Analyse der technologischen Trends und industriellen Veränderungen in den oben genannten Bereichen bieten, um Ihnen dabei zu helfen, Ihre Ziele in der Zukunft zu erreichen Jahr vorbereitet sein. Diese Interpretation stammt aus dem Branchennewsletter Week50 2023.

Datum: 12. Dezember
Ereignis: Mistral AI hat das Modell Mixtral 8x7B auf Basis der MoE-Architektur (Mixture-of-Experts, Mix of Experts) als Open Source bereitgestellt und seine Leistung erreichte das Niveau von Llama 2 70B und GPT-3.5" Die Veranstaltung fand statt. Erweiterte Interpretation.
Erklären Sie zunächst, was MoE ist und welche Vor- und Nachteile es hat
1 Konzept:
MoE (Mixture of Experts) ist ein Hybridmodell, das aus mehreren Untermodellen (d. h. Experten) besteht. Jedes Untermodell ist ein lokales Modell, das auf die Verarbeitung einer Teilmenge des Eingaberaums spezialisiert ist. Die Kernidee von MoE besteht darin, mithilfe eines Gating-Netzwerks zu entscheiden, welches Modell anhand der einzelnen Daten trainiert werden soll, wodurch die Interferenz zwischen verschiedenen Modellen verringert wird Arten von Proben.
2. Hauptkomponenten:
Mixed Expert Model Technology (MoE) ist eine Deep-Learning-Technologie, die aus Expertenmodellen und Gated-Modellen besteht und die Verteilung von Aufgaben/Trainingsdaten auf verschiedene Experten realisiert Modelle über das Gated-Netzwerk, sodass sich jedes Modell auf die Aufgaben konzentrieren kann, die es am besten beherrscht, wodurch die Sparsität des Modells erreicht wird.
① Beim Training des Gated-Netzwerks wird jede Stichprobe einem oder mehreren Experten zugewiesen.
② Bei der Schulung des Expertennetzwerks wird jeder Experte geschult, um die Fehler der ihm zugewiesenen Proben zu minimieren.
Der „Vorgänger“ von MoE ist Ensemble Learning. Beim Ensemble-Lernen werden mehrere Modelle (Basislerner) trainiert, um dasselbe Problem zu lösen, und ihre Vorhersagen einfach kombiniert (z. B. durch Abstimmung oder Mittelung). Das Hauptziel des Ensemble-Lernens besteht darin, die Vorhersageleistung durch Reduzierung der Überanpassung und Verbesserung der Generalisierungsfähigkeiten zu verbessern. Zu den gängigen Ensemble-Lernmethoden gehören Bagging, Boosting und Stacking.
4. Historische Quelle des MoE:
① Die Wurzeln des MoE lassen sich auf das Papier „Adaptive Mixture of Local Experts“ aus dem Jahr 1991 zurückführen. Die Idee ähnelt Ensemble-Ansätzen, da sie darauf abzielt, einen Überwachungsprozess für ein System bereitzustellen, das aus verschiedenen Teilnetzwerken besteht, wobei jedes einzelne Netzwerk oder jeder einzelne Experte auf einen anderen Bereich des Eingaberaums spezialisiert ist. Das Gewicht jedes Experten wird über ein geschlossenes Netzwerk bestimmt. Während des Schulungsprozesses werden sowohl Experten als auch Gatekeeper geschult.
② Zwischen 2010 und 2015 trugen zwei verschiedene Forschungsbereiche zur Weiterentwicklung von MoE bei:
Einer sind Experten als Komponenten: In einem traditionellen MoE-Aufbau besteht das gesamte System aus einem geschlossenen Netzwerk und mehreren Experten. MoEs als ganze Modelle wurden in Support-Vektor-Maschinen, Gaußschen Prozessen und anderen Methoden untersucht. Die Arbeit „Learning Factored Representations in a Deep Mixture of Experts“ untersucht die Möglichkeit von MoEs als Komponenten tieferer Netzwerke. Dadurch kann das Modell gleichzeitig groß und effizient sein.
Das andere ist die bedingte Berechnung: Herkömmliche Netzwerke verarbeiten alle Eingabedaten über jede Ebene. Während dieser Zeit untersuchte Yoshua Bengio Möglichkeiten, Komponenten basierend auf Eingabe-Tokens dynamisch zu aktivieren oder zu deaktivieren.
③ Infolgedessen begannen die Menschen, Expertenmischungsmodelle im Kontext der Verarbeitung natürlicher Sprache zu erforschen. In dem Artikel „Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer“ wurde es durch die Einführung von Sparsity auf ein 137B LSTM erweitert, wodurch schnelles Denken in großem Maßstab erreicht wurde.
Warum verdienen MoE-basierte große Modelle Aufmerksamkeit?1. Im Allgemeinen wird die Erweiterung des Modellmaßstabs zu einem erheblichen Anstieg der Trainingskosten führen, und die Begrenzung der Rechenressourcen ist zu einem Engpass für das intensive Modelltraining in großem Maßstab geworden. Um dieses Problem zu lösen, wird eine Deep-Learning-Modellarchitektur vorgeschlagen, die auf dünn besetzten MoE-Schichten basiert.
2. Das Sparse Mixed Expert Model (MoE) ist eine spezielle neuronale Netzwerkarchitektur, die lernbare Parameter zu großen Sprachmodellen (LLM) hinzufügen kann, ohne die Inferenzkosten zu erhöhen, während Instruction Tuning eine Technik zum Trainieren von LLM ist, um Anweisungen zu befolgen .
3. Die Kombination der MoE+-Anweisungs-Feinabstimmungstechnologie kann die Leistung von Sprachmodellen erheblich verbessern. Im Juli 2023 veröffentlichten Forscher von Google, der UC Berkeley, dem MIT und anderen Institutionen das Papier „Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models“, das bewies, dass das hybride Expertenmodell (MoE) und die Instruction Tuning Die Kombination kann die Leistung großer Sprachmodelle (LLM) erheblich verbessern.
① Konkret verwendeten die Forscher Sparse-Activation-MoE in einem Satz fein abgestimmter Sparse-Hybrid-Expertenmodelle FLAN-MOE und ersetzten die Feedforward-Komponente der Transformer-Schicht durch die MoE-Schicht, um eine bessere Modellkapazität und Rechenleistung zu bieten ; Zweitens: Feinabstimmung von FLAN-MOE basierend auf dem FLAN-Sammeldatensatz.
② Basierend auf der oben genannten Methode untersuchten die Forscher die direkte Feinabstimmung einer einzelnen Downstream-Aufgabe ohne Befehlsoptimierung, die kontextbezogene Wenig-Schuss- oder Zero-Shot-Verallgemeinerung der Downstream-Aufgabe nach der Befehlsoptimierung und die anschließende Befehlsoptimierung Wir verfeinern eine einzelne Downstream-Aufgabe weiter und vergleichen die Leistungsunterschiede von LLM unter den drei experimentellen Einstellungen.
③ Experimentelle Ergebnisse zeigen, dass MoE-Modelle ohne den Einsatz von Befehlsoptimierung oft schlechter abschneiden als dichte Modelle mit vergleichbarer Rechenleistung. Aber in Kombination mit direktiver Abstimmung ändern sich die Dinge. Das anweisungsabgestimmte MoE-Modell (Flan-MoE) übertrifft das größere dichte Modell bei mehreren Aufgaben, obwohl das MoE-Modell nur ein Drittel so rechenintensiv ist wie das dichte Modell. Im Vergleich zu dichten Modellen. MoE-Modelle erzielen durch die Optimierung der Anweisungen deutliche Leistungssteigerungen. Wenn also Recheneffizienz und Leistung berücksichtigt werden, wird MoE zu einem leistungsstarken Werkzeug für das Training großer Sprachmodelle.
4. Dieses Mal verwendet das veröffentlichte Mixtral 8x7B-Modell auch ein spärliches gemischtes Expertennetzwerk.
① Mixtral 8x7B ist ein reines Decoder-Modell. Das Feedforward-Modul wählt aus 8 verschiedenen Parametersätzen aus. In jeder Schicht des Netzwerks wählt das Router-Netzwerk für jedes Token zwei der acht Gruppen (Experten) aus, um das Token zu verarbeiten und ihre Ausgaben zu aggregieren.
② Das Mixtral 8x7B-Modell erreicht oder übertrifft Llama 2 70B und GPT3.5 bei den meisten Benchmarks, mit 6-mal schnelleren Inferenzgeschwindigkeiten.
Wichtige Vorteile von MoE: Was ist Sparsity?
1. In herkömmlichen dichten Modellen muss jede Eingabe im vollständigen Modell berechnet werden. Beim Sparse-Mixed-Expert-Modell werden bei der Verarbeitung von Eingabedaten nur wenige Expertenmodelle aktiviert und verwendet, während sich die meisten Expertenmodelle in einem inaktiven Zustand befinden. Und Sparsity ist ein wichtiger Aspekt des Mixed-Experten Modellvorteile sind auch der Schlüssel zur Verbesserung der Effizienz von Modelltrainings- und Inferenzprozessen

Das obige ist der detaillierte Inhalt vonPRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Aug 07, 2024 pm 07:08 PM
PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Aug 07, 2024 pm 07:08 PM
Im Jahr 2023 entwickeln sich fast alle Bereiche der KI in beispielloser Geschwindigkeit weiter. Gleichzeitig verschiebt die KI ständig die technologischen Grenzen wichtiger Bereiche wie der verkörperten Intelligenz und des autonomen Fahrens. Wird der Status von Transformer als Mainstream-Architektur großer KI-Modelle durch den multimodalen Trend erschüttert? Warum ist die Erforschung großer Modelle auf Basis der MoE-Architektur (Mixture of Experts) zu einem neuen Trend in der Branche geworden? Können Large Vision Models (LVM) ein neuer Durchbruch im allgemeinen Sehvermögen sein? ...Aus dem PRO-Mitglieder-Newsletter 2023 dieser Website, der in den letzten sechs Monaten veröffentlicht wurde, haben wir 10 spezielle Interpretationen ausgewählt, die eine detaillierte Analyse der technologischen Trends und industriellen Veränderungen in den oben genannten Bereichen bieten, um Ihnen dabei zu helfen, Ihre Ziele in der Zukunft zu erreichen Jahr vorbereitet sein. Diese Interpretation stammt aus Week50 2023
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
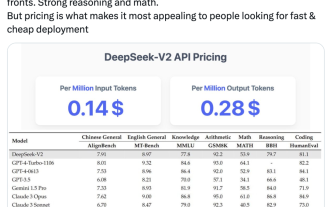 Inländische Open-Source-MoE-Indikatoren explodieren: GPT-4-Level-Fähigkeiten, API-Preis beträgt nur ein Prozent
May 07, 2024 pm 05:34 PM
Inländische Open-Source-MoE-Indikatoren explodieren: GPT-4-Level-Fähigkeiten, API-Preis beträgt nur ein Prozent
May 07, 2024 pm 05:34 PM
Das neueste groß angelegte inländische Open-Source-MoE-Modell erfreute sich gleich nach seinem Debüt großer Beliebtheit. Die Leistung von DeepSeek-V2 erreicht GPT-4-Niveau, es ist jedoch Open Source, kostenlos für die kommerzielle Nutzung und der API-Preis beträgt nur ein Prozent von GPT-4-Turbo. Daher löste es sofort nach seiner Veröffentlichung viele Diskussionen aus. Den veröffentlichten Leistungsindikatoren zufolge übertreffen die umfassenden chinesischen Fähigkeiten von DeepSeekV2 die vieler Open-Source-Modelle. Gleichzeitig befinden sich auch Closed-Source-Modelle wie GPT-4Turbo und Wenkuai 4.0 auf der ersten Stufe. Die umfassenden Englischkenntnisse liegen ebenfalls auf der gleichen ersten Stufe wie LLaMA3-70B und übertreffen Mixtral8x22B, das ebenfalls ein MoE ist. Es zeigt auch gute Leistungen in den Bereichen Wissen, Mathematik, logisches Denken, Programmieren usw. Und unterstützt 128K-Kontext. Stellen Sie sich das vor
