



Auf dieser Grundlage hat NetEase Fuxi basierend auf dem großen Modell des Bild- und Textverständnisses weitere Innovationen entwickelt und eine modalübergreifende Abrufmethode vorgeschlagen, die auf der Auswahl und Rekonstruktion wichtiger lokaler Informationen basiert, um das Problem des Bildtextes in bestimmten Feldern zu lösen Für multimodale Agenten bilden Interaktionsfragen die technische Grundlage.
Das Folgende ist eine Zusammenfassung der ausgewählten Beiträge:
„Selection and Reconstruction of Key Locals: A Novel Specific Domain Image-Text Retrieval Method“
Selection and Reconstruction of Key Local Information: A Novel Specific Domain Image and Text Retrieval Methode
Schlüsselwörter: wichtige lokale Informationen, feinkörnig, interpretierbar
Beteiligte Bereiche: Visual Language Pre-Training (VLP), Cross-Modal Image and Text Retrieval (CMITR)
In den letzten Jahren wurde mit der Visual Language Pre- Training (Vision – Mit dem Aufkommen von Language Pretraining (VLP)-Modellen wurden erhebliche Fortschritte im Bereich des Cross-Modal Image-Text Retrieval (CMITR) erzielt. Obwohl VLP-Modelle wie CLIP bei domänenallgemeinen CMITR-Aufgaben eine gute Leistung erbringen, ist ihre Leistung beim Specific Domain Image-Text Retrieval (SDITR) oft unzureichend. Dies liegt daran, dass eine bestimmte Domäne häufig einzigartige Datenmerkmale aufweist, die sie von der allgemeinen Domäne unterscheiden.
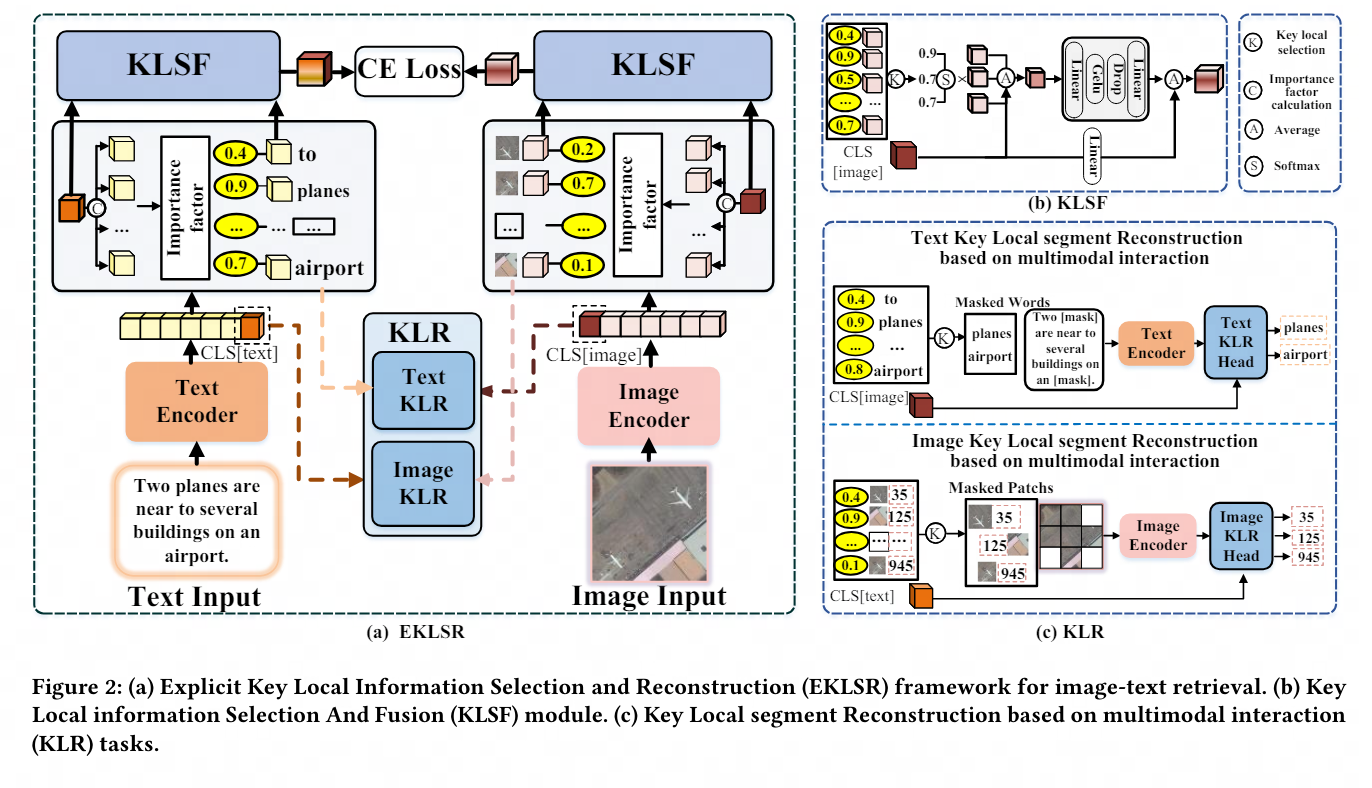
In einem bestimmten Bereich können Bilder ein hohes Maß an visueller Ähnlichkeit zwischen ihnen aufweisen, während sich semantische Unterschiede tendenziell auf wichtige lokale Details konzentrieren, wie z. B. bestimmte Objektbereiche im Bild oder bedeutungsvolle Wörter im Text. Selbst kleine Änderungen in diesen lokalen Segmenten können erhebliche Auswirkungen auf den gesamten Inhalt haben und die Bedeutung dieser wichtigen lokalen Informationen unterstreichen. Daher erfordert SDITR, dass sich das Modell auf wichtige lokale Informationsfragmente konzentriert, um den Ausdruck von Bild- und Textmerkmalen in einem gemeinsamen Darstellungsraum zu verbessern und dadurch die Ausrichtungsgenauigkeit zwischen Bildern und Text zu verbessern.
Dieses Thema untersucht die Anwendung von Pre-Training-Modellen für visuelle Sprache bei Bild-Text-Abrufaufgaben in bestimmten Bereichen und untersucht das Problem der lokalen Merkmalsnutzung bei Bild-Text-Abrufaufgaben in bestimmten Bereichen. Der Hauptbeitrag besteht darin, eine Methode zur Nutzung diskriminierender, feinkörniger lokaler Informationen vorzuschlagen, um die Ausrichtung von Bildern und Text in einem gemeinsamen Darstellungsraum zu optimieren.
Zu diesem Zweck entwerfen wir einen expliziten Rahmen für die Auswahl und Rekonstruktion wichtiger lokaler Informationen sowie eine Strategie für die Rekonstruktion wichtiger lokaler Segmente, die auf multimodaler Interaktion basiert. Diese Methoden nutzen diskriminierende, feinkörnige lokale Informationen effektiv und verbessern dadurch das Bild erheblich und sind umfassend und ausreichend Experimente zur Qualität der Textausrichtung im gemeinsamen Raum zeigen den Fortschritt und die Wirksamkeit der vorgeschlagenen Strategie.
Besonderer Dank geht an das IPIU-Labor der Xi'an University of Electronic Science and Technology für seine starke Unterstützung und seinen wichtigen Forschungsbeitrag zu diesem Papier.

Das obige ist der detaillierte Inhalt vonACM MM2024 | Die multimodale Forschung von NetEase Fuxi erlangte erneut internationale Anerkennung und förderte neue Durchbrüche im modalübergreifenden Verständnis in bestimmten Bereichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Kostenloser Quellcode für persönliche Websites
Kostenloser Quellcode für persönliche Websites
 Was bedeutet Open-Source-Code?
Was bedeutet Open-Source-Code?
 Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
Virtuelle Mobiltelefonnummer, um den Bestätigungscode zu erhalten
 Welche mobilen Betriebssysteme gibt es?
Welche mobilen Betriebssysteme gibt es?
 Lösung dafür, dass die Ordnereigenschaften von Win7 keine Registerkartenseite freigeben
Lösung dafür, dass die Ordnereigenschaften von Win7 keine Registerkartenseite freigeben
 Checken Sie den virtuellen Standort auf DingTalk ein
Checken Sie den virtuellen Standort auf DingTalk ein








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



