


Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Bildgenerierung durch Charakterinteraktion bezieht sich auf die Generierung von Bildern, die den Anforderungen an die Textbeschreibung entsprechen. Der Inhalt ist die Interaktion zwischen Personen und Objekten, und das Bild muss so realistisch und semantisch wie möglich sein. In den letzten Jahren haben textgenerierte Bildmodelle erhebliche Fortschritte bei der Generierung realer Bilder gemacht, diese Modelle stehen jedoch immer noch vor Herausforderungen bei der Generierung von Bildern mit hoher Wiedergabetreue, bei denen menschliche Interaktion der Hauptinhalt ist. Die Schwierigkeit ergibt sich hauptsächlich aus zwei Aspekten: Erstens stellt die Komplexität und Vielfalt menschlicher Körperhaltungen eine vernünftige Charaktergenerierung vor Herausforderungen. Zweitens kann die unzuverlässige Generierung interaktiver Grenzbereiche (interaktive semantische Bereiche) zum Scheitern des interaktiven semantischen Ausdrucks von Charakteren führen . unzureichend.
Als Reaktion auf die oben genannten Probleme schlug ein Forschungsteam der Peking-Universität ein körperhaltungs- und interaktionsbewusstes Rahmenwerk zur Bildgenerierung menschlicher Interaktionen (SA-HOI) vor, das die Generierungsqualität menschlicher Körperhaltungen und Informationen zum Interaktionsgrenzbereich als Leitfaden verwendet Durch den Entrauschungsprozess werden vernünftigere und realistischere Bilder der Charakterinteraktion erzeugt. Um die Qualität der erzeugten Bilder umfassend zu bewerten, schlugen sie außerdem einen umfassenden Benchmark für die Bildgenerierung durch menschliche Interaktion vor.

Papierlink: https://proceedings.mlr.press/v235/xu24e.html
Projekthomepage: https://sites.google.com/view/sa-hoi/
Link zum Quellcode: https://github.com/XZPKU/SA-HOI
Lab-Homepage: http://www.wict.pku.edu.cn/mipl
SA-HOI ist A Die semantikbewusste Methode zur Bildgenerierung durch menschliche Interaktion verbessert die Gesamtqualität der Bildgenerierung durch menschliche Interaktion und reduziert bestehende Generierungsprobleme sowohl aufgrund der menschlichen Körperhaltung als auch der interaktiven Semantik. Durch die Kombination der Bildinversionsmethode wird ein iterativer Inversions- und Bildkorrekturprozess generiert, der das erzeugte Bild schrittweise selbst korrigieren und die Qualität verbessern kann.
In der Arbeit schlug das Forschungsteam außerdem den ersten Benchmark zur Bildgenerierung durch menschliche Interaktionen vor, der Mensch-Objekt-, Mensch-Tier- und Mensch-Mensch-Interaktionen abdeckt, und entwickelte gezielte Bewertungsindikatoren für die Bildgenerierung durch menschliche Interaktionen. Umfangreiche Experimente zeigen, dass diese Methode bestehende diffusionsbasierte Bilderzeugungsmethoden sowohl hinsichtlich der Bewertungsmetriken für die Bilderzeugung durch menschliche Interaktion als auch für die herkömmliche Bilderzeugung übertrifft.
Einführung in die Methode
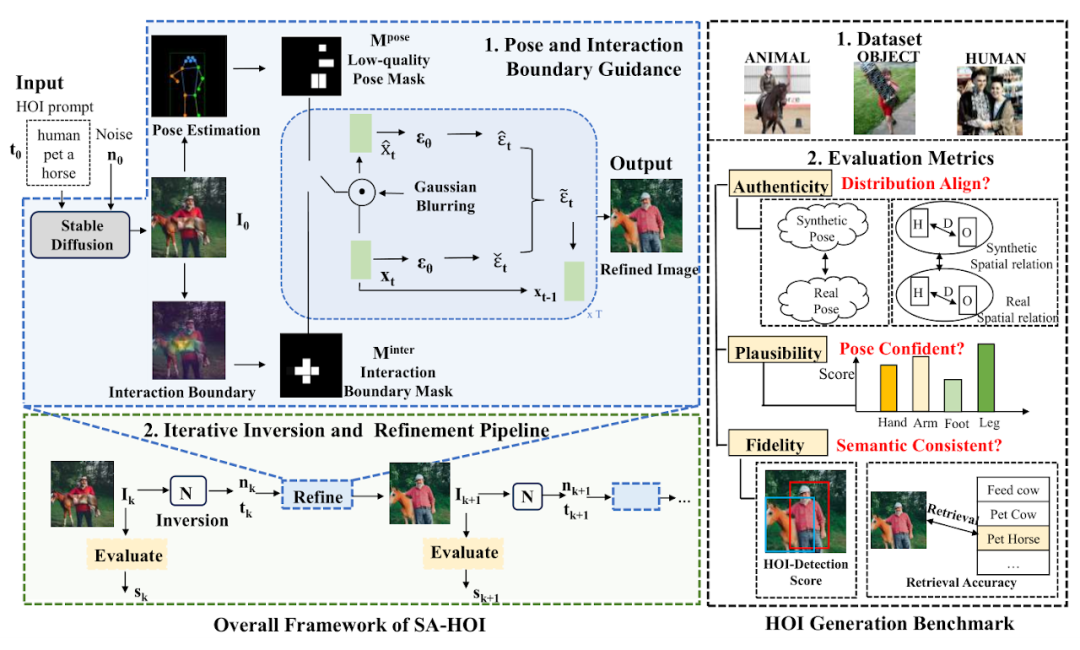
Methodeneinführung Haltung und interaktive Anleitung(Pose and Interaction Guidance, PIG) und
Iterative Inversion and Refinement Pipeline(Iterative Inversion and Refinement Pipeline, IIR). In PIG wird für eine gegebene Zeicheninteraktionstextbeschreibung Für die interaktive Anleitung wird das Segmentierungsmodell verwendet, um den Interaktionsgrenzbereich zu lokalisieren, Schlüsselpunkte Der Pseudocode der Posen- und Interaktionsgesteuerten Abtastung ist in Abbildung 2 dargestellt. In jedem Entrauschungsschritt erhalten wir zunächst das vorhergesagte Rauschen ϵt und die Zwischenrekonstruktion ϵt, wie im stabilen Diffusionsmodell (Stabile Diffusion) entworfen. Anschließend wenden wir die Gaußsche Unschärfe G an, um die verschlechterten latenten Merkmale und zu erhalten, und führen anschließend die Informationen in den entsprechenden latenten Merkmalen in den Entrauschungsprozess ein. Wobei wobei ϕt der Schwellenwert ist, der die Maske zum Zeitpunkt t generiert. In ähnlicher Weise verwendet der Autor des Artikels zur interaktiven Anleitung das Segmentierungsmodell, um den Außenkonturpunkt O des Objekts und den Gelenkpunkt C des menschlichen Körpers zu erhalten, berechnet die Abstandsmatrix D zwischen der Person und dem Objekt und tastet die Schlüsselpunkte ab Interaktionsgrenze Iterativer Inversions- und Bildkorrekturprozess 為了即時獲取生成影像的品質評估,論文作者引入品質評估器 Q,用於作為迭代式 操作的指導。對於第 k 輪的圖像 然而,這樣的噪聲不是現成可得的,為此引入圖像反演方法 透過比較前後迭代輪次中的質量分數,可以判斷是否要繼續進行最佳化:當 人物互動影像產生基準 為了更好地評估生成的人物交互圖像質量,論文作者為人物交互生成量身定制了幾個測評標準,從可靠性(Authenticity)、可行性(Plausibility) 和保真度(Fidelity) 的角度全面評估生成影像。在可靠性上,論文作者引入姿勢分佈距離和人 - 物體距離分佈,評估生成結果和真實圖像是否接近:生成結果在分佈意義上越接近真實圖像,就說明品質越好。可行性上,採用計算姿勢置信度分數來衡量產生人體關節的可信度和合理性。在保真度上,採用人物互動偵測任務,以及圖文檢索任務評估產生影像與輸入文字之間的語意一致性。 與現有方法的對比實驗結果如表 1 和表 2 所示,分別對比了人物交互影像產生指標和常規影像產生指標上的表現。 實驗結果表明,該論文中的方法在人體生成質量,交互語義表達,人物交互距離,人體姿態分佈,整體圖像質量等多個維度的測評上都優於現有模型。 此外,論文作者還進行了主觀評測,邀請眾多用戶從人體質量,物體外觀,交互語義和整體質量等多個角度進行評分,實驗結果證明SA-HOI 的方法在各個角度都更符合人類審美。 表 3:與現有方法的主觀評測結果 圖 4:作用中對接一個結果視覺化相比與原始資料一樣為視覺化。 參考文獻: [1] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent0. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, June 2022 . uggingface .co/CompVis/stable-diffusion-v1-4. [3] Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X, J., Pang, J., Cao, Y., Xiong, Y., Li, X, J., Pang, J., Cao, Y., Xiong, Y., Li, X, J., Pang, J., Cao, Y., Xiong, Y., Li, X, J., Pang, X. ., Sun, S., Feng, W., Liu, Z., Xu, J., Zhang, Z., Cheng, D., Zhu, C., Cheng, T., Zhao, Q., Li , B., Lu, X., Zhu, R., Wu, Y., Dai, J., Wang, J., Shi, J., Ouyang, W., Loy, C. C., and Lin, D. MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019. [4] Ron Mokady, Anidtz, Kullfir Abman, Kofir Abt. text inversion for editing real images using guided diffusion models. arXiv preprint arXiv:2211.09794, 2022. arXiv:2211.09794, 2022. , Jiaxuan Wang, and Jia Deng. HICO: A benchmark for recognizing human-object interactions in images. In Proceedings of the IEEE International Conference on Computer Vision, 2015. und Rauschen
und Rauschen  zunächst ein stabiles Diffusionsmodell (Stabile Diffusion [2]) verwendet, um
zunächst ein stabiles Diffusionsmodell (Stabile Diffusion [2]) verwendet, um  als Anfangsbild zu generieren, und ein Posendetektor [3] wird verwendet, um das zu erhalten Gelenkpositionen des menschlichen Körpers
als Anfangsbild zu generieren, und ein Posendetektor [3] wird verwendet, um das zu erhalten Gelenkpositionen des menschlichen Körpers  und der entsprechende Konfidenzwert
und der entsprechende Konfidenzwert  , um eine Posenmaske
, um eine Posenmaske  zu erstellen, die Posenbereiche mit geringer Qualität hervorhebt.
zu erstellen, die Posenbereiche mit geringer Qualität hervorhebt.  und entsprechende Konfidenzwerte
und entsprechende Konfidenzwerte  zu erhalten und den Interaktionsbereich in der Interaktionsmaske
zu erhalten und den Interaktionsbereich in der Interaktionsmaske  hervorzuheben, um den semantischen Ausdruck der Interaktionsgrenze zu verbessern. Für jeden Entrauschungsschritt werden
hervorzuheben, um den semantischen Ausdruck der Interaktionsgrenze zu verbessern. Für jeden Entrauschungsschritt werden  und
und  als Einschränkungen verwendet, um diese hervorgehobenen Bereiche zu korrigieren und dadurch die in diesen Bereichen bestehenden Erzeugungsprobleme zu reduzieren. Darüber hinaus wird IIR mit dem Bildinversionsmodell N kombiniert, um das Rauschen n und die Einbettung t der Textbeschreibung aus dem Bild zu extrahieren, das einer weiteren Korrektur bedarf, und dann mit PIG die nächste Korrektur am Bild durchzuführen und die Qualität zu verwenden Bewerter Q, um die Qualität des korrigierten Bildes zu bewerten und -Operationen zu verwenden, um die Bildqualität schrittweise zu verbessern. 🎙
als Einschränkungen verwendet, um diese hervorgehobenen Bereiche zu korrigieren und dadurch die in diesen Bereichen bestehenden Erzeugungsprobleme zu reduzieren. Darüber hinaus wird IIR mit dem Bildinversionsmodell N kombiniert, um das Rauschen n und die Einbettung t der Textbeschreibung aus dem Bild zu extrahieren, das einer weiteren Korrektur bedarf, und dann mit PIG die nächste Korrektur am Bild durchzuführen und die Qualität zu verwenden Bewerter Q, um die Qualität des korrigierten Bildes zu bewerten und -Operationen zu verwenden, um die Bildqualität schrittweise zu verbessern. 🎙  und
und  werden verwendet, um
werden verwendet, um  und
und  zu generieren und Bereiche mit geringer Posenqualität in
zu generieren und Bereiche mit geringer Posenqualität in  und
und  hervorzuheben, um das Modell so zu steuern, dass die Verzerrungserzeugung in diesen Bereichen reduziert wird. Um das Modell bei der Verbesserung von Bereichen mit geringer Qualität anzuleiten, werden Bereiche mit niedrigem Pose-Score durch die folgende Formel hervorgehoben:
hervorzuheben, um das Modell so zu steuern, dass die Verzerrungserzeugung in diesen Bereichen reduziert wird. Um das Modell bei der Verbesserung von Bereichen mit geringer Qualität anzuleiten, werden Bereiche mit niedrigem Pose-Score durch die folgende Formel hervorgehoben: 
 , x, y die pixelweisen Koordinaten des Bildes sind, H, W die Bildgrößen sind und σ die Varianz der Gaußschen Verteilung ist.
, x, y die pixelweisen Koordinaten des Bildes sind, H, W die Bildgrößen sind und σ die Varianz der Gaußschen Verteilung ist.  stellt die auf das i-te Gelenk konzentrierte Aufmerksamkeit dar. Durch die Kombination der Aufmerksamkeit aller Gelenke können wir die endgültige Aufmerksamkeitskarte
stellt die auf das i-te Gelenk konzentrierte Aufmerksamkeit dar. Durch die Kombination der Aufmerksamkeit aller Gelenke können wir die endgültige Aufmerksamkeitskarte  bilden und eine Schwelle verwenden, um in eine Maske umzuwandeln.
bilden und eine Schwelle verwenden, um in eine Maske umzuwandeln.  daraus und Verwendung und Haltungsführung. Dieselbe Methode erzeugt interaktive Aufmerksamkeit
daraus und Verwendung und Haltungsführung. Dieselbe Methode erzeugt interaktive Aufmerksamkeit  und Maske und wird zur Berechnung des endgültigen Vorhersagerauschens angewendet.
und Maske und wird zur Berechnung des endgültigen Vorhersagerauschens angewendet.  ,採用評估器 Q 獲取其質量分數
,採用評估器 Q 獲取其質量分數 ,然後基於
,然後基於  生成
生成 。為了在最佳化後保留 的主要內容,需要相應的雜訊作為去噪的初始值。
。為了在最佳化後保留 的主要內容,需要相應的雜訊作為去噪的初始值。  來獲取其噪聲潛在特徵
來獲取其噪聲潛在特徵 和文本嵌入
和文本嵌入 ,作為 PIG 的輸入,生成優化後的結果
,作為 PIG 的輸入,生成優化後的結果 。
。  和
和 之間沒有顯著差異,即低於閾值θ,可以認為該流程可能已經對影像做出了充足的修正,因此結束優化並輸出品質分數最高的影像。
之間沒有顯著差異,即低於閾值θ,可以認為該流程可能已經對影像做出了充足的修正,因此結束優化並輸出品質分數最高的影像。  +「影像」產生任務設計的現有模型和基準,論文作者收集並整合了一個人物互動影像生成基準,包括一個含有150 個人物互動類別的真實人物互動影像資料集,以及若干為人物互動影像產生客製化的評量指標。 該資料集從開源人物交互檢測資料集 HICO-DET [5] 中篩選得到 150 個人物交互類別,涵蓋了人 - 物體、人 - 動物和人 - 人三種不同交互場景。共計收集了 5k 人物交互真實圖像作為該論文的參考資料集,用於評估生成人物交互圖像的品質。
+「影像」產生任務設計的現有模型和基準,論文作者收集並整合了一個人物互動影像生成基準,包括一個含有150 個人物互動類別的真實人物互動影像資料集,以及若干為人物互動影像產生客製化的評量指標。 該資料集從開源人物交互檢測資料集 HICO-DET [5] 中篩選得到 150 個人物交互類別,涵蓋了人 - 物體、人 - 動物和人 - 人三種不同交互場景。共計收集了 5k 人物交互真實圖像作為該論文的參考資料集,用於評估生成人物交互圖像的品質。 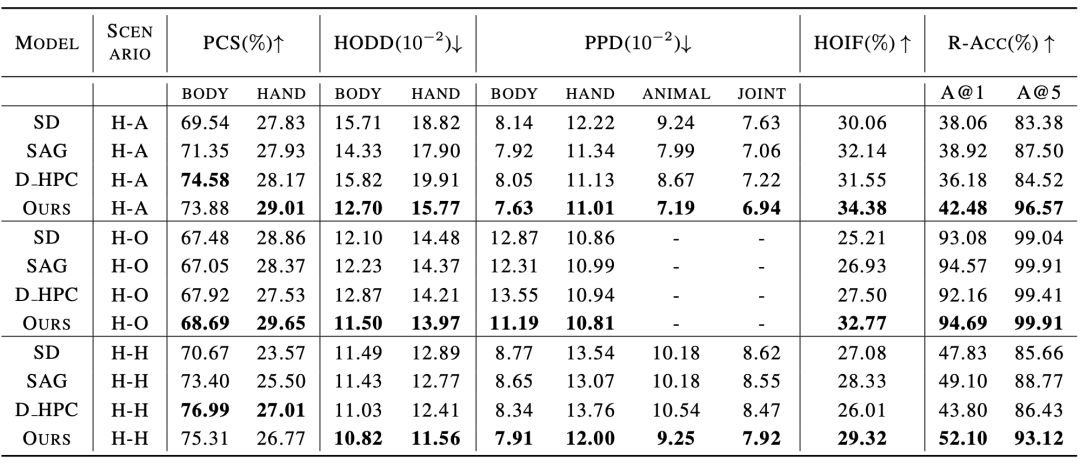 ¢ 表2:與現有方法使用常規影像產生指標時的實驗結果相較
¢ 表2:與現有方法使用常規影像產生指標時的實驗結果相較

Das obige ist der detaillierte Inhalt vonICML 2024 |. Jetzt verstehe ich Ihre Aufforderungswörter besser. Die Peking-Universität führt ein Framework zur Generierung von Charakterinteraktionsbildern ein, das auf semantischer Wahrnehmung basiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist HDMI?
Was ist HDMI?
 Welche Währung ist USD?
Welche Währung ist USD?
 Webseite maximieren
Webseite maximieren
 Lösung für Syntaxfehler beim Ausführen von Python
Lösung für Syntaxfehler beim Ausführen von Python
 CSS außerhalb der Anzeige ...
CSS außerhalb der Anzeige ...
 Können Douyin-Funken wieder entzündet werden, wenn sie länger als drei Tage ausgeschaltet waren?
Können Douyin-Funken wieder entzündet werden, wenn sie länger als drei Tage ausgeschaltet waren?
 So kommentieren Sie Code in HTML
So kommentieren Sie Code in HTML
 Mit welchen Methoden kann Docker in den Container gelangen?
Mit welchen Methoden kann Docker in den Container gelangen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



