


Mit der Einführung großer Modelle und dem Drücken des Gaspedals sind vinzentinische Diagramme zweifellos eine der heißesten Anwendungsrichtungen.
Seit der Geburt von Stable Diffusion gab es im In- und Ausland einen endlosen Strom großer Wen Shengtu-Modelle, und es fühlte sich eine Zeit lang wie ein „Kampf zwischen Göttern“ an. In nur wenigen Monaten wechselte der Titel „The Strongest AI Artist“ mehrfach den Besitzer. Jede technologische Iteration verschiebt weiterhin die Obergrenze der Qualität und Geschwindigkeit der KI-Bilderzeugung.
Jetzt können wir jedes gewünschte Bild erhalten, indem wir ein paar Wörter eingeben. Ob es sich um ein professionelles Werbeplakat oder ein hyperrealistisches Foto handelt, die Genauigkeit der KI-Kartierung hat uns erstaunt. Sogar AI hat den Sony World Photography Award 2023 gewonnen. Bevor der Hauptpreis bekannt gegeben wurde, war dieses „Foto“ im Somerset House in London ausgestellt worden – wenn der Autor es nicht öffentlich preisgab, erfuhr vielleicht niemand, dass das Foto tatsächlich von KI erstellt wurde. E Eldagse und seine KI-Generation arbeiten „Elektriker“
 Wie man die von KI gezeichneten Bilder schöner macht, ist für KI-Techniker untrennbar mit der Beharrlichkeit verbunden.
Wie man die von KI gezeichneten Bilder schöner macht, ist für KI-Techniker untrennbar mit der Beharrlichkeit verbunden. Die Live-Übertragung begann zunächst ausführlich mit der technischen Aktualisierung des Vincent-Diagrammmodells des jüngsten inländischen Großmodells „Top-Tier“ – dem ByteDance Doubao-Großmodell.
Li Liang sagte, dass die Probleme, die das Doubao-Team lösen möchte, hauptsächlich drei Aspekte umfassen: Erstens, wie eine stärkere Bild- und Textanpassung erreicht werden kann, um den Vorstellungen des Benutzers gerecht zu werden, und zweitens, wie schönere Bilder generiert werden können, um ein ultimativeres Ergebnis zu erzielen Benutzererfahrung; drittens geht es darum, Bilder schneller zu erstellen, um sehr große Serviceeinsätze zu bewältigen. In Bezug auf den Bild- und Textabgleich begann das Doubao-Team mit Daten, verfeinerte und filterte die riesigen Bild- und Textdaten und speicherte schließlich Hunderte Milliarden hochwertiger Bilder in der Datenbank. Darüber hinaus trainierte das Team speziell ein multimodales großes Sprachmodell für die Rekapitulationsaufgabe. Dieses Modell wird die physikalischen Beziehungen von Bildern in Bildern umfassender und objektiver beschreiben.
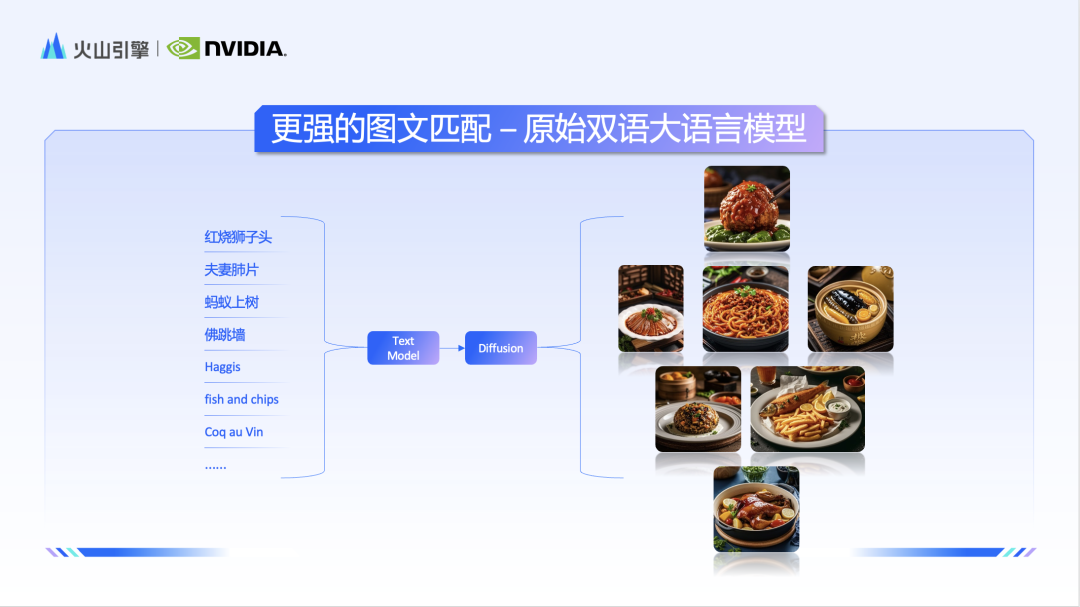
Wenn Sie über hochwertige und detaillierte Bild- und Textdaten verfügen und die Stärke des Modells besser nutzen möchten, müssen Sie die Fähigkeit des Textverständnismoduls verbessern. Das Team verwendet ein natives zweisprachiges Großsprachenmodell als Textkodierer, was die Fähigkeit des Modells, Chinesisch zu verstehen, erheblich verbessert. Daher sind die Doubao- und Vincent-Diagrammmodelle angesichts nationaler Elemente wie „Tang-Dynastie“ und „Laternenfest“ sehr hilfreich zeigen auch ein tieferes Verständnis.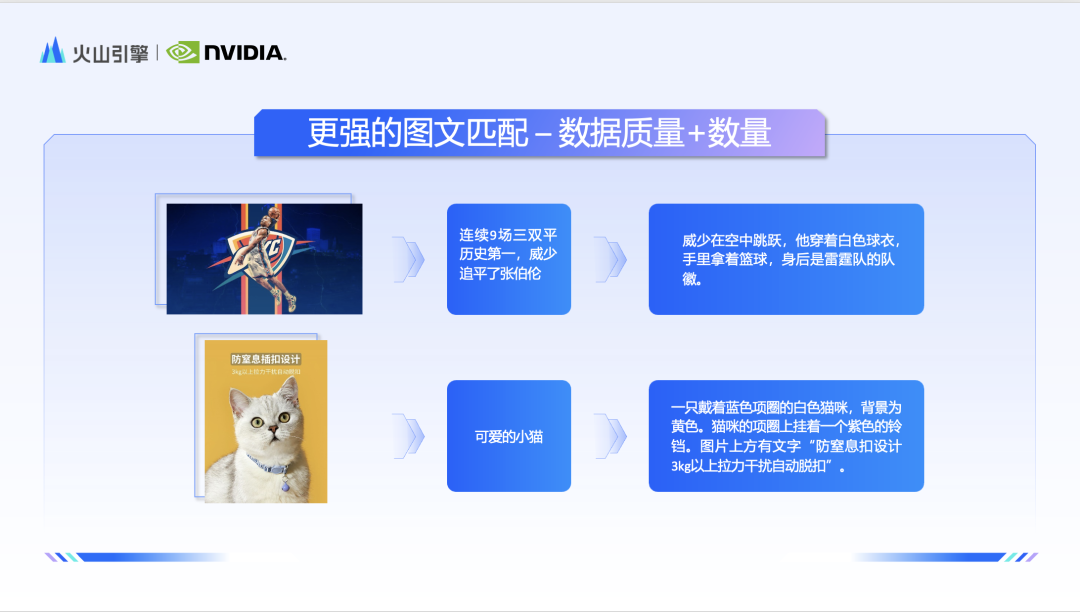
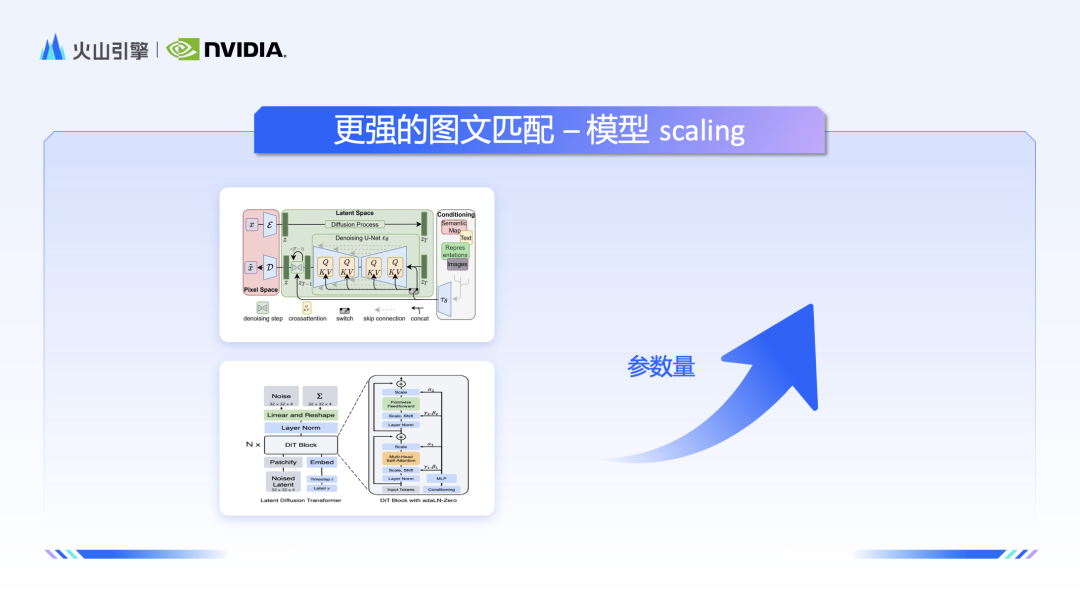
다음으로 NVIDIA 솔루션 아키텍트 Zhao Yijia는 기본 기술부터 시작하여 Vincent Graph의 가장 주류인 두 가지 Unet 기반 SD 및 DIT 모델 아키텍처와 해당 특성을 설명하고 NVIDIA의 Tensorrt, Tensorrt-LLM과 같은 How 도구를 소개했습니다. , Triton 및 Nemo Megatron은 모델 배포를 지원하고 대규모 모델이 보다 효율적으로 추론할 수 있도록 돕습니다.
Zhao Yijia는 먼저 Stable Diffusion 모델의 원리에 대해 자세히 설명하고 Clip, VAE, Unet과 같은 주요 구성 요소의 작동 원리에 대해 자세히 설명했습니다. Sora가 인기를 끌면서 DiT(Diffusion Transformer) 아키텍처도 인기를 끌었습니다. Zhao Yijia는 모델 구조, 특성, 컴퓨팅 전력 소비라는 세 가지 측면에서 SD와 DiT의 장점을 포괄적으로 비교했습니다.
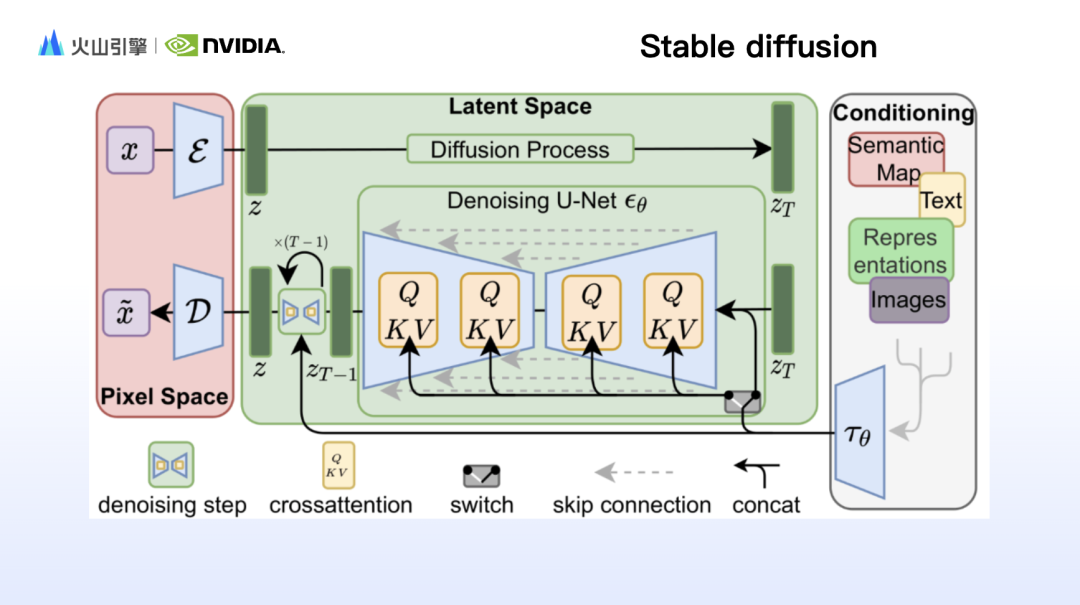
안정적인 확산을 사용하여 이미지를 생성할 때 생성된 결과에 프롬프트 단어 내용이 표시되지만 이미지가 원하는 것과 다르다는 느낌을 받는 경우가 많습니다. 이는 텍스트 렌더링을 기반으로 하는 안정적인 확산이 좋지 않기 때문입니다. 구성, 움직임, 얼굴 특징, 공간 관계 등과 같은 세부 사항을 제어합니다. 따라서 연구진은 안정 확산의 작동 원리를 바탕으로 안정 확산의 단점을 보완하기 위해 많은 제어 모듈을 설계했습니다. Zhao Yijia는 대표적인 IP 어댑터와 ControlNet을 추가했습니다. 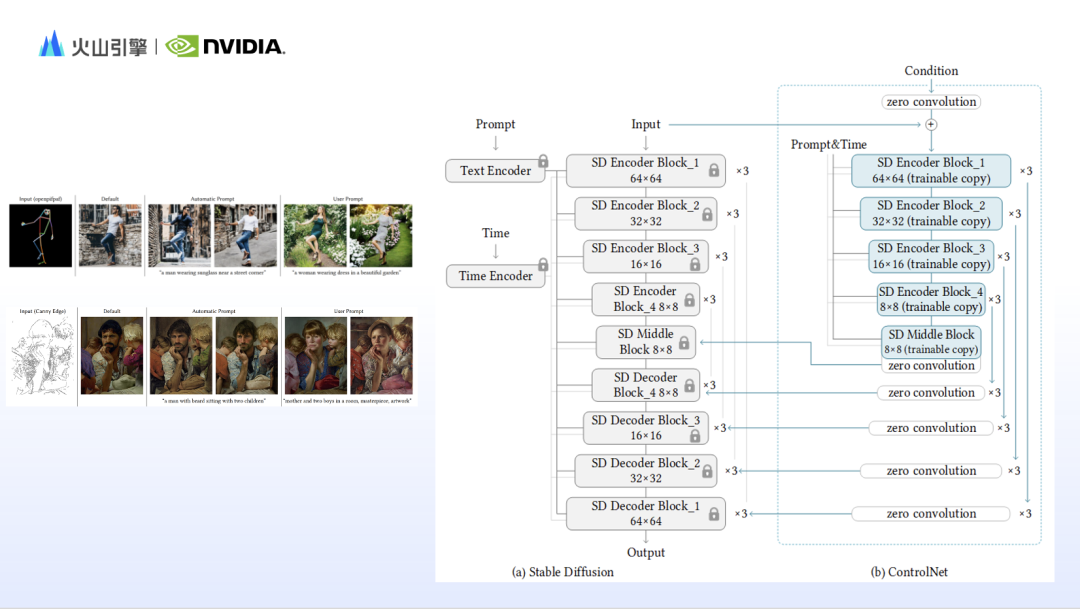
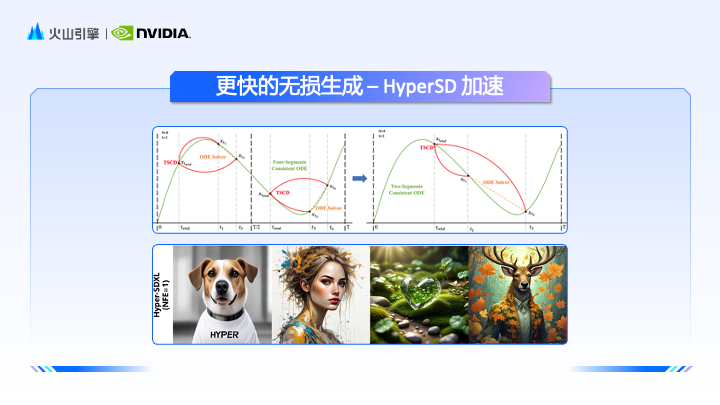
계산량이 많은 Vincent 그래프 모델의 추론 속도를 높이려면 NVIDIA의 기술 지원이 핵심적인 역할을 합니다. Zhao Yijia는 고성능 컨볼루션, 효율적인 스케줄링 및 분산 배포 기술을 통해 이미지 및 텍스트 생성 모델의 추론 프로세스를 최적화하는 Nvidia TensorRT 및 TensorRT-LLM 도구를 소개했습니다. 동시에 NVIDIA의 Ada, Hopper 및 곧 출시될 BlackWell 하드웨어 아키텍처는 이미 FP8 교육 및 추론을 지원하므로 모델 교육에 보다 원활한 경험을 제공할 것입니다.

6번의 멋진 라이브 방송 끝에 볼케이노 엔진, 엔비디아, 본 사이트, CMO CLUB이 공동으로 론칭한 "AIGC 체험 파티"가 성공적으로 마무리되었습니다. 이 6개의 에피소드를 통해 AIGC가 어떻게 '흥미로움'에서 '유용함'으로 바뀌는지에 대해 모두가 더 깊이 이해하게 되었다고 믿습니다. 우리는 또한 "AIGC 체험 학교"가 프로그램에 대한 논의에 머물 뿐만 아니라 실제로 마케팅 분야의 지능형 업그레이드 과정을 가속화하기를 기대합니다.
"AIGC 체험학교" 6개 이슈 전체 리뷰 주소: https://vtizr.xetlk.com/s/7CjTy
Das obige ist der detaillierte Inhalt vonKI produziert Bilder schneller, schöner und versteht Ihre Gedanken besser. Welche technischen Geheimnisse hat das hochschöne Vincent-Bildmodell gepflegt?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So erstellen Sie eine responsive Webseite
So erstellen Sie eine responsive Webseite
 Der Unterschied zwischen Server und Cloud-Host
Der Unterschied zwischen Server und Cloud-Host
 Der Unterschied zwischen leichtgewichtigen Anwendungsservern und Cloud-Servern
Der Unterschied zwischen leichtgewichtigen Anwendungsservern und Cloud-Servern
 Der Unterschied zwischen PD-Schnellladen und allgemeinem Schnellladen
Der Unterschied zwischen PD-Schnellladen und allgemeinem Schnellladen
 Verwendung der C-Sprache printf-Funktion
Verwendung der C-Sprache printf-Funktion
 Warum der Computer immer wieder automatisch neu startet
Warum der Computer immer wieder automatisch neu startet
 Verwendung der Snoopy-Klasse in PHP
Verwendung der Snoopy-Klasse in PHP
 So verwenden Sie insertBefore in Javascript
So verwenden Sie insertBefore in Javascript








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



