
 Backend-Entwicklung
Python-Tutorial
Der vollständige Leitfaden zur Bildkomprimierung mit OpenCV
Backend-Entwicklung
Python-Tutorial
Der vollständige Leitfaden zur Bildkomprimierung mit OpenCV
Der vollständige Leitfaden zur Bildkomprimierung mit OpenCV

Bildkomprimierung ist eine entscheidende Technologie im Computer Vision, die es uns ermöglicht, Bilder effizienter zu speichern und zu übertragen und gleichzeitig die visuelle Qualität beizubehalten. Im Idealfall hätten wir gerne kleine Dateien mit bester Qualität. Wir müssen jedoch einen Kompromiss eingehen und entscheiden, was wichtiger ist.
In diesem Tutorial lernen Sie die Bildkomprimierung mit OpenCV und behandeln Theorie und praktische Anwendungen. Am Ende werden Sie verstehen, wie Sie Fotos für Computer-Vision-Projekte (oder andere Projekte, die Sie möglicherweise haben) erfolgreich komprimieren.
Was ist Bildkomprimierung?
Bildkomprimierung reduziert die Dateigröße eines Bildes und behält gleichzeitig ein akzeptables Maß an visueller Qualität bei. Es gibt zwei Hauptarten der Komprimierung:
- Verlustfreie Komprimierung:Behält alle Originaldaten bei und ermöglicht so eine exakte Bildrekonstruktion.
- Verlustbehaftete Komprimierung: Verwirft einige Daten, um kleinere Dateigrößen zu erreichen, was möglicherweise die Bildqualität verringert.
Warum Bilder komprimieren?
Wenn „Speicherplatz billig ist“, wie wir oft hören, warum dann überhaupt Bilder komprimieren? Im Kleinen spielt die Bildkomprimierung keine große Rolle, im Großen ist sie jedoch von entscheidender Bedeutung.
Wenn Sie beispielsweise ein paar Bilder auf Ihrer Festplatte haben, können Sie diese komprimieren und ein paar Megabyte an Daten sparen. Dies hat keine große Auswirkung, wenn Festplatten in Terabyte gemessen werden. Aber was wäre, wenn Sie 100.000 Bilder auf Ihrer Festplatte hätten? Eine einfache Komprimierung spart Zeit und Geld. Aus Performance-Sicht ist es das Gleiche. Wenn Sie eine Website mit vielen Bildern haben und täglich 10.000 Menschen Ihre Website besuchen, ist die Komprimierung wichtig.
Deshalb machen wir das:
- Reduzierter Speicherbedarf: Speichern Sie mehr Bilder auf demselben Raum
- Schnellere Übertragung: Ideal für Webanwendungen und Szenarien mit eingeschränkter Bandbreite
- Verbesserte Verarbeitungsgeschwindigkeit: Kleinere Bilder können schneller geladen und verarbeitet werden
Theorie hinter der Bildkomprimierung
Bildkomprimierungstechniken nutzen zwei Arten von Redundanzen aus:
- Räumliche Redundanz: Korrelation zwischen benachbarten Pixeln
- Farbredundanz: Ähnlichkeit von Farbwerten in benachbarten Regionen
Räumliche Redundanz nutzt die Tatsache aus, dass benachbarte Pixel in den meisten natürlichen Bildern tendenziell ähnliche Werte haben. Dadurch entstehen fließende Übergänge. Viele Fotos „sehen echt aus“, weil es einen natürlichen Übergang von einem Bereich zum anderen gibt. Wenn die benachbarten Pixel stark unterschiedliche Werte haben, entstehen „verrauschte“ Bilder. Die Pixel wurden geändert, um diese Übergänge weniger „glatt“ zu machen, indem Pixel in einer einzigen Farbe gruppiert wurden, wodurch das Bild kleiner wurde.

Farbredundanz hingegen konzentriert sich darauf, wie benachbarte Bereiche in einem Bild häufig ähnliche Farben aufweisen. Stellen Sie sich einen blauen Himmel oder eine grüne Wiese vor – große Teile des Bildes könnten sehr ähnliche Farbwerte haben. Sie können auch gruppiert und in einer einzigen Farbe gestaltet werden, um Platz zu sparen.

OpenCV bietet solide Werkzeuge für die Arbeit mit diesen Ideen. Mithilfe räumlicher Redundanz füllt beispielsweise die Funktion cv2.inpaint() von OpenCV fehlende oder beschädigte Bereiche eines Bildes mithilfe von Informationen aus benachbarten Pixeln auf. Mit OpenCV können Entwickler cv2.cvtColor() verwenden, um Bilder zwischen mehreren Farbräumen hinsichtlich der Farbredundanz zu übersetzen. Dies kann als Vorverarbeitungsschritt bei vielen Komprimierungstechniken einigermaßen hilfreich sein, da einige Farbräume bei der Kodierung bestimmter Bildarten effektiver sind als andere.
Wir werden jetzt einige dieser Theorien testen. Lass uns damit spielen.
Praktische Bildkomprimierung
Sehen wir uns an, wie man Bilder mit den Python-Bindungen von OpenCV komprimiert. Schreiben Sie diesen Code aus oder kopieren Sie ihn:
Den Quellcode erhalten Sie auch hier
import cv2
import numpy as np
def compress_image(image_path, quality=90):
# Read the image
img = cv2.imread(image_path)
# Encode the image with JPEG compression
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), quality]
_, encoded_img = cv2.imencode('.jpg', img, encode_param)
# Decode the compressed image
decoded_img = cv2.imdecode(encoded_img, cv2.IMREAD_COLOR)
return decoded_img
# Example usage
original_img = cv2.imread('original_image.jpg')
compressed_img = compress_image('original_image.jpg', quality=50)
# Display results
cv2.imshow('Original', original_img)
cv2.imshow('Compressed', compressed_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# Calculate compression ratio
original_size = original_img.nbytes
compressed_size = compressed_img.nbytes
compression_ratio = original_size / compressed_size
print(f"Compression ratio: {compression_ratio:.2f}")
Dieses Beispiel enthält eine compress_image-Funktion, die zwei Parameter akzeptiert:
- Bildpfad (wo sich das Bild befindet)
- Qualität (die Qualität des gewünschten Bildes)
Dann laden wir das Originalbild in original_img. Anschließend komprimieren wir dasselbe Bild um 50 % und laden es in eine neue Instanz, compress_image.
Dann zeigen wir das Original und das komprimierte Bild, damit Sie sie nebeneinander betrachten können.
Wir berechnen dann das Kompressionsverhältnis und zeigen es an.
Dieses Beispiel zeigt, wie man ein Bild mithilfe der JPEG-Komprimierung in OpenCV komprimiert. Der Qualitätsparameter steuert den Kompromiss zwischen Dateigröße und Bildqualität.
Lass es uns ausführen:

While intially looking at the images, you see little difference. However, zooming in shows you the difference in the quality:
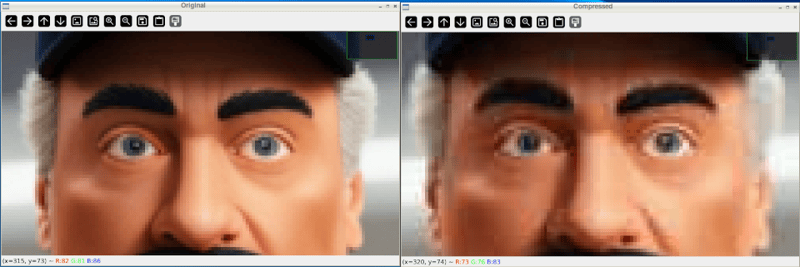
And after closing the windows and looking at the files, we can see the file was reduced in size dramatically:

Also, if we take it down further, we can change our quality to 10%
compressed_img = compress_image('sampleimage.jpg', quality=10)
And the results are much more drastic:
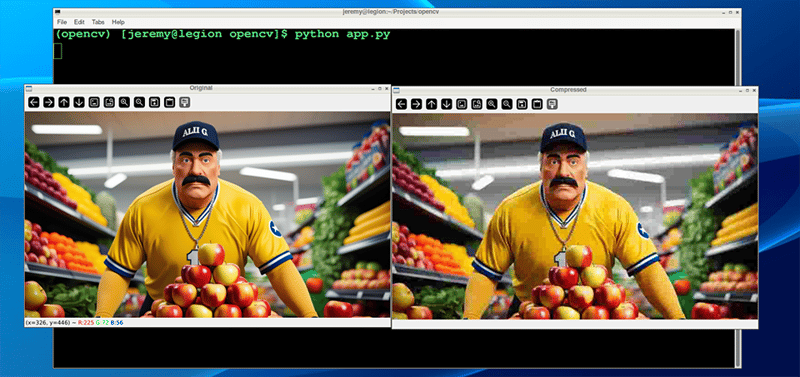
And the file size results are more drastic as well:

You can adjust these parameters quite easily and achieve the desired balance between quality and file size.
Evaluating Compression Quality
To assess the impact of compression, we can use metrics like:
- Mean Squared Error (MSE)
Mean Squared Error (MSE) measures how different two images are from each other. When you compress an image, MSE helps you determine how much the compressed image has changed compared to the original.
It does this by sampling the differences between the colors of corresponding pixels in the two images, squaring those differences, and averaging them. The result is a single number: a lower MSE means the compressed image is closer to the original. In comparison, a higher MSE means there's a more noticeable loss of quality.
Here's some Python code to measure that:
def calculate_mse(img1, img2):
return np.mean((img1 - img2) ** 2)
mse = calculate_mse(original_img, compressed_img)
print(f"Mean Squared Error: {mse:.2f}")
Here's what our demo image compression looks like:

- Peak Signal-to-Noise Ratio (PSNR)
Peak Signal-to-Noise Ratio (PSNR) is a measure that shows how much an image's quality has degraded after compression. This is often visible with your eyes, but it assigns a set value. It compares the original image to the compressed one and expresses the difference as a ratio.
A higher PSNR value means the compressed image is closer in quality to the original, indicating less loss of quality. A lower PSNR means more visible degradation. PSNR is often used alongside MSE, with PSNR providing an easier-to-interpret scale where higher is better.
Here is some Python code that measures that:
def calculate_psnr(img1, img2):
mse = calculate_mse(img1, img2)
if mse == 0:
return float('inf')
max_pixel = 255.0
return 20 * np.log10(max_pixel / np.sqrt(mse))
psnr = calculate_psnr(original_img, compressed_img)
print(f"PSNR: {psnr:.2f} dB")
Here's what our demo image compression looks like:
"Eyeballing" your images after compression to determine quality is fine; however, at a large scale, having scripts do this is a much easier way to set standards and ensure the images follow them.
Let's look at a couple other techniques:
Advanced Compression Techniques
For more advanced compression, OpenCV supports various algorithms:
- PNG Compression:
You can convert your images to PNG format, which has many advantages. Use the following line of code, and you can set your compression from 0 to 9, depending on your needs. 0 means no compression whatsoever, and 9 is maximum. Keep in mind that PNGs are a "lossless" format, so even at maximum compression, the image should remain intact. The big trade-off is file size and compression time.
Here is the code to use PNG compression with OpenCV:
cv2.imwrite('compressed.png', img, [cv2.IMWRITE_PNG_COMPRESSION, 9])
And here is our result:
Note: You may notice sometimes that PNG files are actually larger in size, as in this case. It depends on the content of the image.
- WebP Compression:
You can also convert your images to .webp format. This is a newer method of compression that's gaining in popularity. I have been using this compression on the images on my blog for years.
In the following code, we can write our image to a webp file and set the compression level from 0 to 100. It's the opposite of PNG's scale because 0, because we're setting quality instead of compression. This small distinction matters, because a setting of 0 is the lowest possible quality, with a small file size and significant loss. 100 is the highest quality, which means large files with the best image quality.
Here's the Python code to make that happen:
cv2.imwrite('compressed.webp', img, [cv2.IMWRITE_WEBP_QUALITY, 80])
And here is our result:

These two techniques are great for compressing large amounts of data. You can write scripts to compress thousands or hundreds of thousands of images automatically.
Conclusion
Image compression is fantastic. It's essential for computer vision tasks in many ways, especially when saving space or increasing processing speed. There are also many use cases outside of computer vision anytime you want to reduce hard drive space or save bandwidth. Image compression can help a lot.
By understanding the theory behind it and applying it, you can do some powerful things with your projects.
Remember, the key to effective compression is finding the sweet spot between file size reduction and maintaining acceptable visual quality for your application.
Thanks for reading, and feel free to reach out if you have any comments or questions!
Das obige ist der detaillierte Inhalt vonDer vollständige Leitfaden zur Bildkomprimierung mit OpenCV. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1672
1672
 14
1428
52
1333
25
1277
29
1257
24
14
1428
52
1333
25
1277
29
1257
24

 Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python ist leichter zu lernen und zu verwenden, während C leistungsfähiger, aber komplexer ist. 1. Python -Syntax ist prägnant und für Anfänger geeignet. Durch die dynamische Tippen und die automatische Speicherverwaltung können Sie die Verwendung einfach zu verwenden, kann jedoch zur Laufzeitfehler führen. 2.C bietet Steuerung und erweiterte Funktionen auf niedrigem Niveau, geeignet für Hochleistungsanwendungen, hat jedoch einen hohen Lernschwellenwert und erfordert manuellem Speicher und Typensicherheitsmanagement.
 Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Ist es genug, um Python für zwei Stunden am Tag zu lernen? Es hängt von Ihren Zielen und Lernmethoden ab. 1) Entwickeln Sie einen klaren Lernplan, 2) Wählen Sie geeignete Lernressourcen und -methoden aus, 3) praktizieren und prüfen und konsolidieren Sie praktische Praxis und Überprüfung und konsolidieren Sie und Sie können die Grundkenntnisse und die erweiterten Funktionen von Python während dieser Zeit nach und nach beherrschen.
 Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python ist in der Entwicklungseffizienz besser als C, aber C ist in der Ausführungsleistung höher. 1. Pythons prägnante Syntax und reiche Bibliotheken verbessern die Entwicklungseffizienz. 2. Die Kompilierungsmerkmale von Compilation und die Hardwarekontrolle verbessern die Ausführungsleistung. Bei einer Auswahl müssen Sie die Entwicklungsgeschwindigkeit und die Ausführungseffizienz basierend auf den Projektanforderungen abwägen.
 Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python und C haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1) Python ist aufgrund seiner prägnanten Syntax und der dynamischen Typisierung für die schnelle Entwicklung und Datenverarbeitung geeignet. 2) C ist aufgrund seiner statischen Tipp- und manuellen Speicherverwaltung für hohe Leistung und Systemprogrammierung geeignet.
 Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
PythonlistsarePartThestandardlibrary, whilearraysarenot.listarebuilt-in, vielseitig und UNDUSEDFORSPORINGECollections, während dieArrayRay-thearrayModulei und loses und loses und losesaluseduetolimitedFunctionality.
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python für wissenschaftliches Computer: Ein detailliertes Aussehen
Apr 19, 2025 am 12:15 AM
Python für wissenschaftliches Computer: Ein detailliertes Aussehen
Apr 19, 2025 am 12:15 AM
Zu den Anwendungen von Python im wissenschaftlichen Computer gehören Datenanalyse, maschinelles Lernen, numerische Simulation und Visualisierung. 1.Numpy bietet effiziente mehrdimensionale Arrays und mathematische Funktionen. 2. Scipy erweitert die Numpy -Funktionalität und bietet Optimierungs- und lineare Algebra -Tools. 3.. Pandas wird zur Datenverarbeitung und -analyse verwendet. 4.Matplotlib wird verwendet, um verschiedene Grafiken und visuelle Ergebnisse zu erzeugen.
 Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Zu den wichtigsten Anwendungen von Python in der Webentwicklung gehören die Verwendung von Django- und Flask -Frameworks, API -Entwicklung, Datenanalyse und Visualisierung, maschinelles Lernen und KI sowie Leistungsoptimierung. 1. Django und Flask Framework: Django eignet sich für die schnelle Entwicklung komplexer Anwendungen, und Flask eignet sich für kleine oder hochmobile Projekte. 2. API -Entwicklung: Verwenden Sie Flask oder Djangorestframework, um RESTFUFFUPI zu erstellen. 3. Datenanalyse und Visualisierung: Verwenden Sie Python, um Daten zu verarbeiten und über die Webschnittstelle anzuzeigen. 4. Maschinelles Lernen und KI: Python wird verwendet, um intelligente Webanwendungen zu erstellen. 5. Leistungsoptimierung: optimiert durch asynchrones Programmieren, Caching und Code
