
 Datenbank
MySQL-Tutorial
MySQL beherrschen: Wichtige Leistungskennzahlen, die jeder Entwickler überwachen sollte
Datenbank
MySQL-Tutorial
MySQL beherrschen: Wichtige Leistungskennzahlen, die jeder Entwickler überwachen sollte
MySQL beherrschen: Wichtige Leistungskennzahlen, die jeder Entwickler überwachen sollte

Die Überwachung der MySQL-Leistungsmetriken und die Verwaltung Ihrer Datenbank müssen nicht schwierig sein. Ja, das hast du richtig gehört. Mit den richtigen Überwachungsstrategien und -tools können Sie endlich in den Hintergrund treten. Die RED-Methode, gepaart mit den leistungsstarken Überwachungsfunktionen und einfach anzuwendenden Konfigurationsempfehlungen von Releem, nimmt Ihnen die schwere Arbeit ab.
Einführung in die RED-Methode
Die RED-Methode wird traditionell zur Überwachung der Leistung von Webanwendungen und -diensten verwendet, kann aber auch auf die MySQL-Leistungsüberwachung angewendet werden. Releem hat festgestellt, dass das Framework bei der Überwachung von MySQL-Leistungsmetriken gleichermaßen wertvoll ist, da die Herausforderungen, denen Datenbanken in Bezug auf Leistung und Zuverlässigkeit gegenüberstehen, denen von Webanwendungen entsprechen.
Bei der Anwendung auf MySQL-Datenbanken gliedert sich die RED-Methode in drei kritische Problembereiche, die jeweils Einblicke in den Betriebszustand Ihrer Datenbank bieten:
Abfragerate (Rate) – Damit wird das Volumen der pro Sekunde ausgeführten Abfragen oder Befehle bewertet und bietet ein direktes Maß für die Arbeitslast des Servers. Es spielt eine entscheidende Rolle bei der Bewertung der Fähigkeit der Datenbank, gleichzeitige Vorgänge zu verarbeiten, und ihrer Reaktionsfähigkeit auf Benutzeranforderungen.
Fehlerrate (Fehler) – Die Verfolgung der Häufigkeit von Fehlern in Abfragen gibt Aufschluss über potenzielle Zuverlässigkeitsprobleme innerhalb der Datenbank. Eine hohe Fehlerrate kann auf zugrunde liegende Probleme mit der Abfragesyntax, dem Datenbankschema oder Systemeinschränkungen hinweisen, die sich auf die Gesamtintegrität der Datenbank auswirken. Die primäre MySQL-Metrik zur Überwachung der Rate ist Aborted_clients.
Abfrageausführungsdauer (Dauer) – Die Dauermetrik ist ein Maß für die Zeit, die für den Abschluss von Abfragen benötigt wird, von der Initiierung bis zur Ausführung. Dieser Leistungsindikator bewertet die Effizienz von Datenabruf- und -verarbeitungsvorgängen, die direkte Auswirkungen auf die Benutzererfahrung und den Systemdurchsatz haben.
Der Zustand dieser Metriken gibt Ihnen ein solides Verständnis für die Leistung Ihrer Datenbank und damit für die Erfahrung Ihrer Benutzer. Mit der RED-Methode können Sie leicht beurteilen, was mit Ihrer Datenbank nicht stimmt und was behoben werden muss. Sollten Sie beispielsweise feststellen, dass Abfragen nur langsam ausgeführt werden, kann dies darauf hinweisen, dass die Indizes angepasst oder die betroffenen Abfragen optimiert werden müssen, um die Effizienz zu steigern.
8 MySQL-Leistungsmetriken, die für die RED-Methode wesentlich sind
Um die RED-Methode effektiv auf die MySQL-Leistungsüberwachung anzuwenden, konzentriert sich Releem auf acht kritische Aspekte Ihrer Datenbank. Jedes davon ist auf die eine oder andere Weise mit Rate, Fehlern oder Dauer verknüpft:
1. MySQL-Latenz
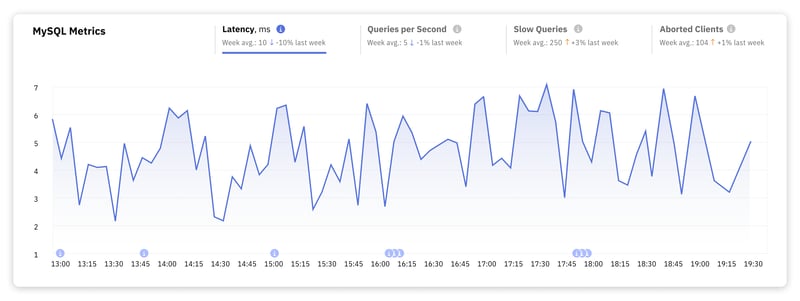
Die Latenz misst die Zeit, die zum Ausführen einer Abfrage benötigt wird – vom Senden einer Abfrage an die Datenbank bis zur Antwort der Datenbank. Die Latenz hat direkten Einfluss darauf, wie Benutzer Ihre Anwendung wahrnehmen.
Für die meisten Webanwendungen gilt das Erreichen einer Latenz im Bereich von einigen Millisekunden bis etwa 10 Millisekunden für Datenbankoperationen als ausgezeichnet. Dieser Bereich gewährleistet ein nahtloses Benutzererlebnis, da die Verzögerung für den Endbenutzer praktisch nicht wahrnehmbar ist.
Sobald die Latenz bei einfachen bis mittelkomplexen Abfragen die 100-Millisekunden-Marke und mehr erreicht, bemerken Benutzer eine Verzögerung. Dies kann problematisch werden, wenn sofortiges Feedback von entscheidender Bedeutung ist, z. B. beim Einreichen von Formularen, bei Suchanfragen oder beim dynamischen Laden von Inhalten.
Weitere Informationen zur MySQL-Latenz
2. Durchsatz
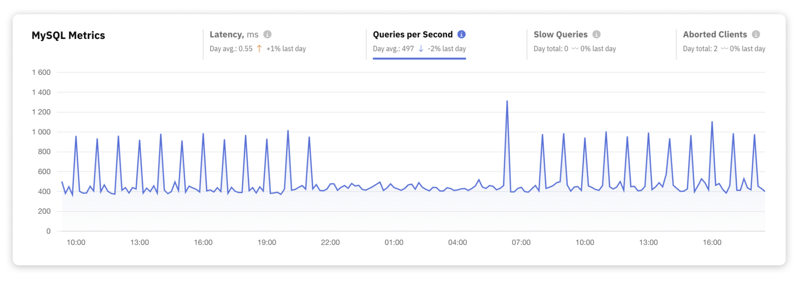
Der Durchsatz, quantifiziert als Abfragen pro Sekunde (Queries per Second, QPS), misst die Effizienz Ihrer Datenbank und ihre Fähigkeit, Arbeitslasten zu verwalten. Ein hoher Durchsatz bedeutet ein gut optimiertes Datenbanksystem, das große Abfragevolumina effizient verarbeiten kann. Ein geringer Durchsatz kann auf Leistungsengpässe oder Ressourcenbeschränkungen hinweisen.
Um einen hohen Durchsatz zu erreichen, ist in der Regel eine Kombination aus optimierten SQL-Abfragen, geeigneten Hardwareressourcen (CPU, Speicher und schnelle E/A-Subsysteme) und fein abgestimmten Datenbankkonfigurationen erforderlich.
Weitere Informationen zum Durchsatz
3. Anzahl langsamer Abfragen
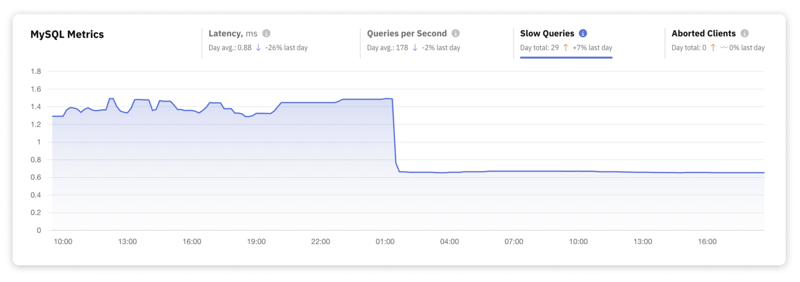
Langsame Abfragen sind im Wesentlichen Datenbankanfragen, die einen vordefinierten Ausführungszeitschwellenwert überschreiten. Sie können diesen Schwellenwert anpassen, um ihn an Ihre spezifischen Leistungsziele oder betrieblichen Benchmarks anzupassen. Durch die Verfolgung der Anzahl langsamer Abfragen können Sie Abfragen identifizieren, die optimiert werden müssen.
Die Identifizierung und Protokollierung dieser langsamen Abfragen erfolgt im slow_query_log, einer speziellen Datei, die zum Speichern von Details zu Abfragen erstellt wurde, die die festgelegten Leistungsstandards nicht erfüllen.
Weitere Informationen zur Anzahl langsamer Abfragen
4. Abgebrochene Clients
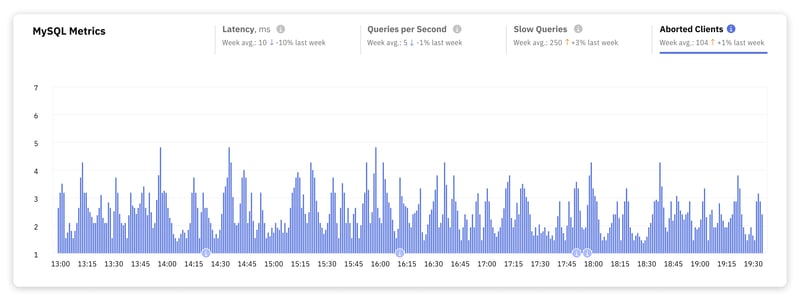
Diese Metrik zählt die Anzahl der Verbindungen, die abgebrochen wurden, weil der Client die Verbindung nicht ordnungsgemäß geschlossen hat. Eine hohe Anzahl abgebrochener Klienten kann auf eine Reihe von Ursachen hinweisen:
- Netzwerklatenz und Jitter verursachen Zeitüberschreitungen
- Serverkapazitätsbeschränkungen führen zu Verbindungsablehnungen
- Ressourcenkonflikt zwischen Abfragen
- Ineffizienzen durch lang laufende Abfragen
- Fehlkonfigurationen in den MySQL-Einstellungen
- Anwendungsfehler führen zu vorzeitigen Verbindungsabbrüchen
Weitere Informationen zu abgebrochenen Klienten
5. CPU-Auslastung
Die CPU ist das Gehirn Ihres Servers. Es führt Befehle aus und führt Berechnungen durch, die es Ihrer Datenbank ermöglichen, Daten zu speichern, abzurufen, zu ändern und zu löschen. Wenn Sie die CPU-Auslastung genau im Auge behalten, können Sie sicherstellen, dass der Server über genügend Rechenleistung verfügt, um seine Arbeitslast zu bewältigen. Eine hohe CPU-Auslastung kann ein verräterisches Zeichen dafür sein, dass ein überlasteter Server Schwierigkeiten hat, mit den an ihn gestellten Anforderungen Schritt zu halten.
Hier sind einige allgemeine Richtlinien, die Sie bei der CPU-Auslastung beachten sollten:
50-70 % nachhaltig – Auf dieser Stufe bewältigt Ihre CPU eine mittlere bis hohe Arbeitslast effektiv, es gibt jedoch noch etwas Spielraum für Spitzenlasten. Dies ist ein gesunder Bereich für Server im Normalbetrieb.
70–90 % dauerhaft – Wenn die CPU-Auslastung dauerhaft in diesem Bereich liegt, deutet dies auf eine hohe Arbeitslast hin, die nur begrenzten Spielraum für die Bewältigung von Spitzenlasten lässt. Sie sollten den Server genau überwachen.
Über 90 % dauerhaft – Dies ist ein starker Indikator dafür, dass der Server fast ausgelastet ist oder fast ausgelastet ist. Erkennbare Leistungsprobleme, darunter langsame Antwortzeiten bei Abfragen und mögliche Zeitüberschreitungen, sind wahrscheinlich. Es ist wichtig, die Ursache zu untersuchen und Optimierungen umzusetzen oder die Ressourcen entsprechend zu skalieren.
Hinweis: Gelegentliche Spitzen über diesen Schwellenwerten weisen möglicherweise nicht unbedingt auf ein Problem hin, da Datenbanken für die Bewältigung variabler Lasten ausgelegt sind. Das Schlüsselwort ist nachhaltig. Eine hohe Dauerauslastung ist ein Zeichen dafür, dass Ihr Server einer erheblichen Belastung ausgesetzt ist.
6. RAM-Nutzung
RAM ist eine wichtige Ressource für Datenbanken, da er aktive Daten und Indizes speichert und so einen schnellen Zugriff und eine effiziente Abfrageverarbeitung ermöglicht. Durch die ordnungsgemäße Verwaltung der RAM-Nutzung wird sichergestellt, dass die Datenbank Arbeitslasten effizient bewältigen kann und sowohl der Datenabruf als auch die Bearbeitungsvorgänge optimiert werden.
Hier sind einige allgemeine Richtlinien, die Sie bei der RAM-Nutzung beachten sollten:
<60-70 % Auslastung – Dieser Bereich gilt allgemein als sicher und zeigt an, dass ausreichend Speicher sowohl für aktuelle Datenbankvorgänge als auch für zusätzliche Arbeitslastspitzen verfügbar ist.
70-85 % Auslastung – Wenn die RAM-Auslastung dauerhaft in diesem Bereich liegt, deutet dies darauf hin, dass die Datenbank den verfügbaren Speicher gut nutzt, aber allmählich den Schwellenwert für eine sorgfältige Überwachung erreicht . Wenn Sie zu Spitzenzeiten in diesem Bereich bleiben, kann der Puffer für die Bewältigung plötzlicher Nachfragesteigerungen eingeschränkt sein.
85-90 % Auslastung – In diesem Bereich nähert sich der Server seiner Speicherkapazität. Eine hohe Speicherauslastung kann zu einem Anstieg der Festplatten-E/A führen, wenn das System beginnt, Daten von und zur Festplatte auszutauschen. Betrachten Sie dies als Warnsignal dafür, dass entweder die Arbeitslast optimiert oder der physische Speicher des Servers erweitert werden muss.
>95 % Auslastung – Der Betrieb mit oder über 95 % RAM-Auslastung ist kritisch und führt wahrscheinlich zu Leistungsproblemen. Auf dieser Ebene greift der Server möglicherweise häufig auf Auslagerungen zurück, was zu erheblichen Verlangsamungen und möglicherweise zu Zeitüberschreitungen bei Clientanwendungen führt. Es ist sofortiges Handeln Ihrerseits erforderlich.
7. SWAP-Nutzung
Swap-Speicherplatz wird verwendet, wenn der physische RAM Ihrer Datenbank vollständig ausgenutzt ist, sodass das System einige der weniger häufig aufgerufenen Daten auf den Festplattenspeicher verlagern kann. Während dieser Mechanismus ein hilfreicher Puffer gegen Fehler aufgrund von unzureichendem Arbeitsspeicher ist, kann die Verwendung von SWAP aufgrund der deutlich langsameren Zugriffszeiten im Vergleich zu RAM die Leistung erheblich beeinträchtigen.
Idealerweise sollte ein MySQL-Server eine geringe bis minimale SWAP-Nutzung aufweisen. Dies zeigt an, dass die Datenbank innerhalb ihres verfügbaren RAM betrieben wird.
Eine hohe SWAP-Nutzung ist ein Warnsignal dafür, dass der physische Speicher des Servers für seine Arbeitslast nicht ausreicht, sodass er für routinemäßige Datenvorgänge auf Festplattenspeicher angewiesen ist. Sie sollten sofort Maßnahmen ergreifen, um dieses Problem zu beheben, indem Sie den Speicherbedarf der Anwendung optimieren oder den RAM des Servers vergrößern.
8. Eingabe-/Ausgabeoperationen pro Sekunde (IOPS)
Die Kennzahl Input/Output Operations per Second (IOPS) gibt an, wie intensiv Ihre Datenbank mit dem zugrunde liegenden Speichersystem – der Festplatte – interagiert. Hohe IOPS-Werte weisen auf eine hohe Datenlast hin und von den Speichermedien hin, was zwar auf eine ausgelastete Datenbank hinweist, aber auch auf mögliche Engpässe bei der Festplattenleistung hinweisen kann.
Einige Schlüsselfaktoren, die den IOPS beeinflussen, sind:
- Die Art des Speichermediums, wobei SSDs in der Regel schneller sind als HDDs
- RAID-Konfigurationen, die für Lese- oder Schreibvorgänge optimiert werden können
- Die spezifischen Anforderungen der Datenbank-Workload, ob leselastig oder schreibintensiv
- Der Grad der Parallelität und Wirksamkeit von Caching-Strategien
Releems umfassende Strategie für das Datenbankmanagement
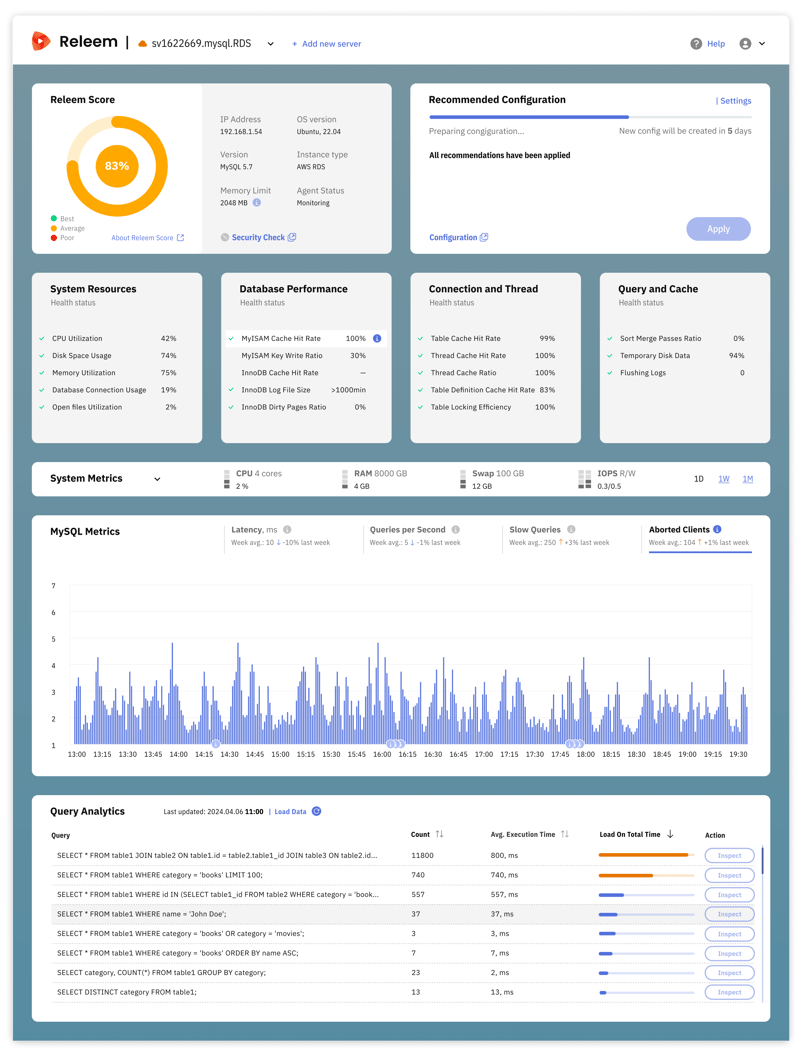
Releems Ansatz zur MySQL-Leistungsüberwachung besteht darin, die wichtigen Details im Auge zu behalten. Diese Strategie umfasst die sorgfältige Verfolgung der 8 genannten Metriken – MySQL-Latenz, Durchsatz, langsame Abfragen, abgebrochene Clients, CPU, RAM, SWAP-Nutzung und IOPS – alles im Rahmen der RED-Methode. Durch die Integration dieser Überwachung als Teil der zweimal täglichen Gesundheitsprüfungen (19 Metriken!) hilft Releem Ihrer Datenbank, ein hohes Maß an Leistung, Zuverlässigkeit und Skalierbarkeit zu erreichen und aufrechtzuerhalten.
Releem überwacht nicht nur die Leistung von MySQL, sondern geht noch einen Schritt weiter, indem es maßgeschneiderte Konfigurationsvorschläge anbietet, die darauf abzielen, bei der Überwachung aufgedeckte Probleme zu beheben. Wir nennen diese Funktion Autopilot für MySQL. Wenn Sie beispielsweise Probleme mit hoher Latenz haben, liefert Releem umsetzbare Erkenntnisse, um Ihre Latenzzahlen wieder in Einklang zu bringen. Unser oberstes Ziel ist es, die Notwendigkeit einer manuellen Überwachung durch eine leistungsstarke, intuitive Software zu beseitigen, die alle Komplexitäten der Datenbankverwaltung bewältigt, über die Sie sich lieber keine Sorgen machen möchten.
Releem verfügt über eine weitreichende Kompatibilität. Ganz gleich, ob Sie Percona, MySQL oder MariaDB für Ihr Datenbankverwaltungssystem verwenden – Releem kann Ihnen helfen. Sehen Sie sich hier die offizielle Liste der unterstützten Systeme an.
Für eine ausführliche Untersuchung der einzelnen Metriken und Best Practices für die Überwachung und Optimierung von MySQL-Datenbanken sollten Sie Releem.com besuchen.
Das obige ist der detaillierte Inhalt vonMySQL beherrschen: Wichtige Leistungskennzahlen, die jeder Entwickler überwachen sollte. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
Die Hauptaufgabe von MySQL in Webanwendungen besteht darin, Daten zu speichern und zu verwalten. 1.Mysql verarbeitet effizient Benutzerinformationen, Produktkataloge, Transaktionsunterlagen und andere Daten. 2. Durch die SQL -Abfrage können Entwickler Informationen aus der Datenbank extrahieren, um dynamische Inhalte zu generieren. 3.Mysql arbeitet basierend auf dem Client-Server-Modell, um eine akzeptable Abfragegeschwindigkeit sicherzustellen.
 Erläutern Sie die Rolle von InnoDB -Wiederherstellung von Protokollen und Rückgängigscheinen.
Apr 15, 2025 am 12:16 AM
Erläutern Sie die Rolle von InnoDB -Wiederherstellung von Protokollen und Rückgängigscheinen.
Apr 15, 2025 am 12:16 AM
InnoDB verwendet Redologs und undologische, um Datenkonsistenz und Zuverlässigkeit zu gewährleisten. 1.REDOLOogen zeichnen Datenseitenänderung auf, um die Wiederherstellung und die Durchführung der Crash -Wiederherstellung und der Transaktion sicherzustellen. 2.Strundologs zeichnet den ursprünglichen Datenwert auf und unterstützt Transaktionsrollback und MVCC.
 MySQL gegen andere Programmiersprachen: Ein Vergleich
Apr 19, 2025 am 12:22 AM
MySQL gegen andere Programmiersprachen: Ein Vergleich
Apr 19, 2025 am 12:22 AM
Im Vergleich zu anderen Programmiersprachen wird MySQL hauptsächlich zum Speichern und Verwalten von Daten verwendet, während andere Sprachen wie Python, Java und C für die logische Verarbeitung und Anwendungsentwicklung verwendet werden. MySQL ist bekannt für seine hohe Leistung, Skalierbarkeit und plattformübergreifende Unterstützung, die für Datenverwaltungsanforderungen geeignet sind, während andere Sprachen in ihren jeweiligen Bereichen wie Datenanalysen, Unternehmensanwendungen und Systemprogramme Vorteile haben.
 MySQL für Anfänger: Erste Schritte mit der Datenbankverwaltung
Apr 18, 2025 am 12:10 AM
MySQL für Anfänger: Erste Schritte mit der Datenbankverwaltung
Apr 18, 2025 am 12:10 AM
Zu den grundlegenden Operationen von MySQL gehört das Erstellen von Datenbanken, Tabellen und die Verwendung von SQL zur Durchführung von CRUD -Operationen für Daten. 1. Erstellen Sie eine Datenbank: createdatabasemy_first_db; 2. Erstellen Sie eine Tabelle: CreateTableBooks (IDINGAUTO_INCRECTIONPRIMARYKEY, Titelvarchar (100) Notnull, AuthorVarchar (100) Notnull, veröffentlicht_yearint); 3.. Daten einfügen: InsertIntoBooks (Titel, Autor, veröffentlicht_year) va
 MySQL gegen andere Datenbanken: Vergleich der Optionen
Apr 15, 2025 am 12:08 AM
MySQL gegen andere Datenbanken: Vergleich der Optionen
Apr 15, 2025 am 12:08 AM
MySQL eignet sich für Webanwendungen und Content -Management -Systeme und ist beliebt für Open Source, hohe Leistung und Benutzerfreundlichkeit. 1) Im Vergleich zu Postgresql führt MySQL in einfachen Abfragen und hohen gleichzeitigen Lesevorgängen besser ab. 2) Im Vergleich zu Oracle ist MySQL aufgrund seiner Open Source und niedrigen Kosten bei kleinen und mittleren Unternehmen beliebter. 3) Im Vergleich zu Microsoft SQL Server eignet sich MySQL besser für plattformübergreifende Anwendungen. 4) Im Gegensatz zu MongoDB eignet sich MySQL besser für strukturierte Daten und Transaktionsverarbeitung.
 Erläutern Sie den InnoDB -Pufferpool und seine Bedeutung für die Leistung.
Apr 19, 2025 am 12:24 AM
Erläutern Sie den InnoDB -Pufferpool und seine Bedeutung für die Leistung.
Apr 19, 2025 am 12:24 AM
InnoDbbufferpool reduziert die Scheiben -E/A durch Zwischenspeicherung von Daten und Indizieren von Seiten und Verbesserung der Datenbankleistung. Das Arbeitsprinzip umfasst: 1. Daten lesen: Daten von Bufferpool lesen; 2. Daten schreiben: Schreiben Sie nach der Änderung der Daten an Bufferpool und aktualisieren Sie sie regelmäßig auf Festplatte. 3. Cache -Management: Verwenden Sie den LRU -Algorithmus, um Cache -Seiten zu verwalten. 4. Lesemechanismus: Last benachbarte Datenseiten im Voraus. Durch die Größe des Bufferpool und die Verwendung mehrerer Instanzen kann die Datenbankleistung optimiert werden.
 MySQL: Strukturierte Daten und relationale Datenbanken
Apr 18, 2025 am 12:22 AM
MySQL: Strukturierte Daten und relationale Datenbanken
Apr 18, 2025 am 12:22 AM
MySQL verwaltet strukturierte Daten effizient durch Tabellenstruktur und SQL-Abfrage und implementiert Inter-Tisch-Beziehungen durch Fremdschlüssel. 1. Definieren Sie beim Erstellen einer Tabelle das Datenformat und das Typ. 2. Verwenden Sie fremde Schlüssel, um Beziehungen zwischen Tabellen aufzubauen. 3.. Verbessern Sie die Leistung durch Indexierung und Abfrageoptimierung. 4. regelmäßig Sicherung und Überwachung von Datenbanken, um die Datensicherheit und die Leistungsoptimierung der Daten zu gewährleisten.
 Lernen von MySQL: Eine Schritt-für-Schritt-Anleitung für neue Benutzer
Apr 19, 2025 am 12:19 AM
Lernen von MySQL: Eine Schritt-für-Schritt-Anleitung für neue Benutzer
Apr 19, 2025 am 12:19 AM
MySQL ist es wert, gelernt zu werden, da es sich um ein leistungsstarkes Open -Source -Datenbankverwaltungssystem handelt, das für Datenspeicher, Verwaltung und Analyse geeignet ist. 1) MySQL ist eine relationale Datenbank, die SQL zum Betrieb von Daten verwendet und für die strukturierte Datenverwaltung geeignet ist. 2) Die SQL -Sprache ist der Schlüssel zur Interaktion mit MySQL und unterstützt CRUD -Operationen. 3) Das Arbeitsprinzip von MySQL umfasst Client/Server -Architektur, Speicher -Engine und Abfrageoptimierer. 4) Die grundlegende Nutzung umfasst das Erstellen von Datenbanken und Tabellen, und die erweiterte Verwendung umfasst das Verbinden von Tabellen mit dem Join. 5) Zu den häufigen Fehlern gehören Syntaxfehler und Erlaubnisprobleme, und die Debugging -Fähigkeiten umfassen die Überprüfung der Syntax und die Verwendung von Erklärungskenntnissen. 6) Die Leistungsoptimierung umfasst die Verwendung von Indizes, die Optimierung von SQL -Anweisungen und die regelmäßige Wartung von Datenbanken.
