Jetzt verfügt das Long Context Visual Language Model (VLM) über eine neue Full-Stack-Lösung – LongVILA, die System, Modelltraining und Datenentwicklung integriert in eins.
In dieser Phase ist es sehr wichtig, das multimodale Verständnis des Modells mit der Fähigkeit zum langen Kontext zu kombinieren. Das Basismodell, das mehr Modalitäten unterstützt, kann flexiblere Eingabesignale akzeptieren, sodass Menschen diversifizieren können Möglichkeiten zur Interaktion mit Modellen. Und ein längerer Kontext ermöglicht es dem Modell, mehr Informationen zu verarbeiten, z. B. lange Dokumente und lange Videos. Diese Fähigkeit bietet auch die Funktionalität, die für realere Anwendungen erforderlich ist. Das aktuelle Problem besteht jedoch darin, dass einige Arbeiten visuelle Sprachmodelle mit langem Kontext (VLM) ermöglicht haben, jedoch normalerweise in einem vereinfachten Ansatz, anstatt eine umfassende Lösung bereitzustellen. Full-Stack-Design ist für visuelle Sprachmodelle mit langem Kontext von entscheidender Bedeutung. Das Training großer Modelle ist in der Regel eine komplexe und systematische Aufgabe, die ein gemeinsames Design von Datentechnik und Systemsoftware erfordert. Im Gegensatz zu Nur-Text-LLMs erfordern VLMs (z. B. LLaVA) häufig einzigartige Modellarchitekturen und flexible verteilte Trainingsstrategien. Darüber hinaus erfordert die Langkontextmodellierung nicht nur Langkontextdaten, sondern auch eine Infrastruktur, die speicherintensives Langkontexttraining unterstützen kann. Daher ist ein gut geplantes Full-Stack-Design (das System, Daten und Pipeline abdeckt) für VLM mit langem Kontext unerlässlich. In diesem Artikel stellen Forscher von NVIDIA, MIT, UC Berkeley und der University of Texas in Austin LongVILA vor, eine Full-Stack-Lösung zum Trainieren und Bereitstellen von visuellen Sprachmodellen mit langem Kontext, einschließlich Systemdesign und Modelltraining Strategie und Datensatzkonstruktion.
- Papieradresse: https://arxiv.org/pdf/2408.10188
- Codeadresse: https://github.com/NVlabs/VILA/blob/main/LongVILA.md
- Titel des Papiers: LONGVILA: SCALING LONG-CONTEXT VISUAL LANGUAGE MODELS FOR LONG VIDEOS
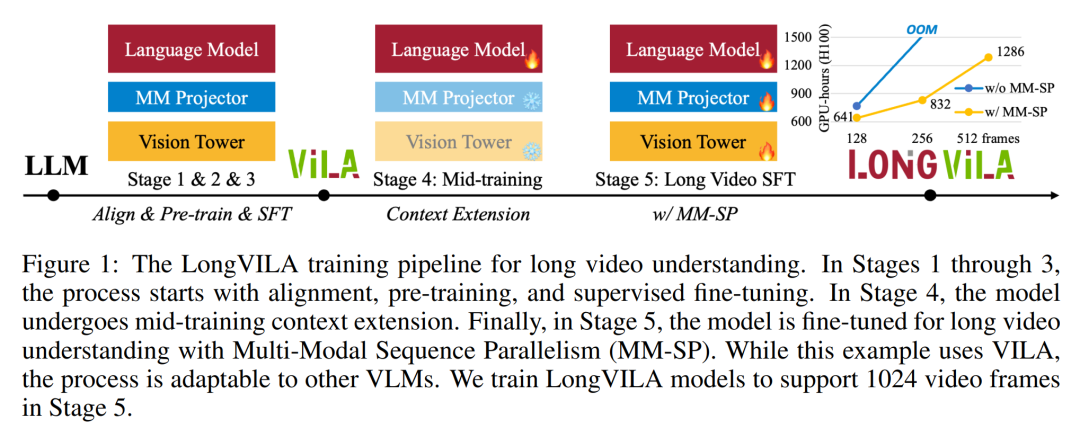
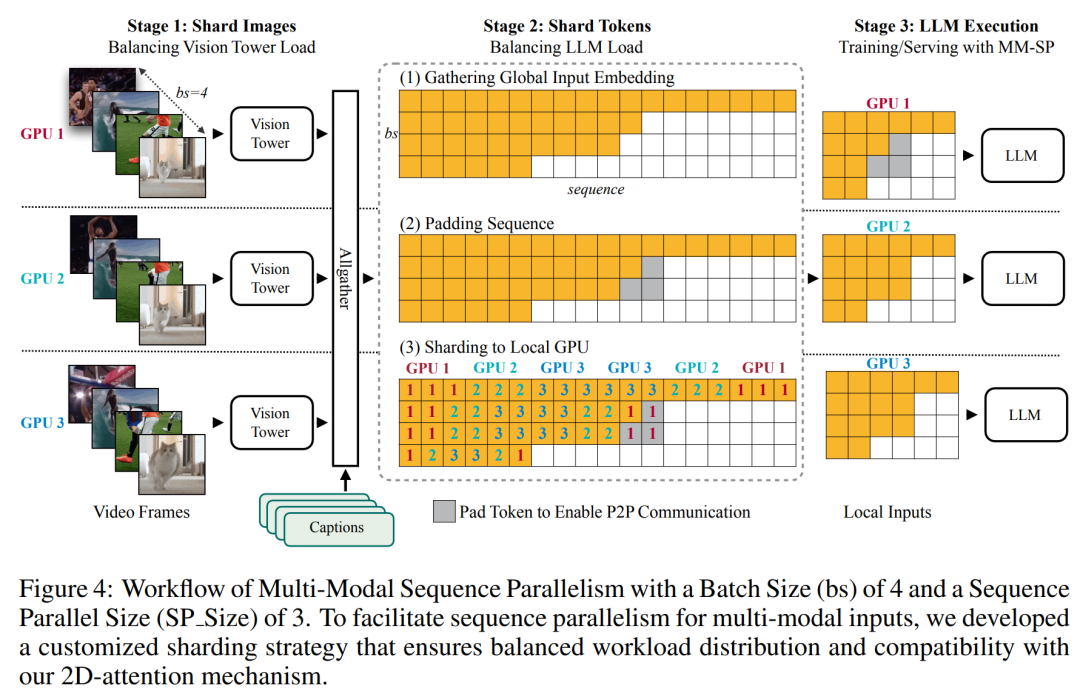
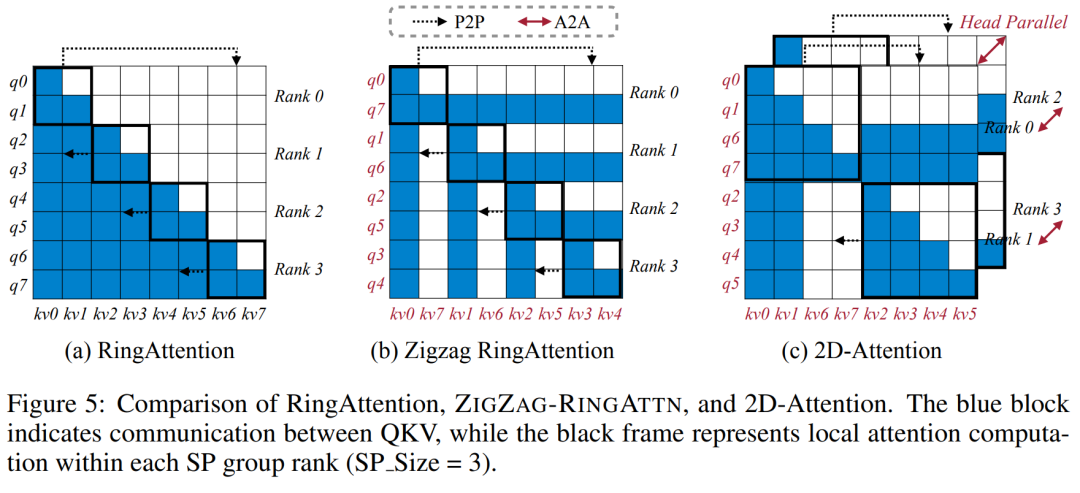
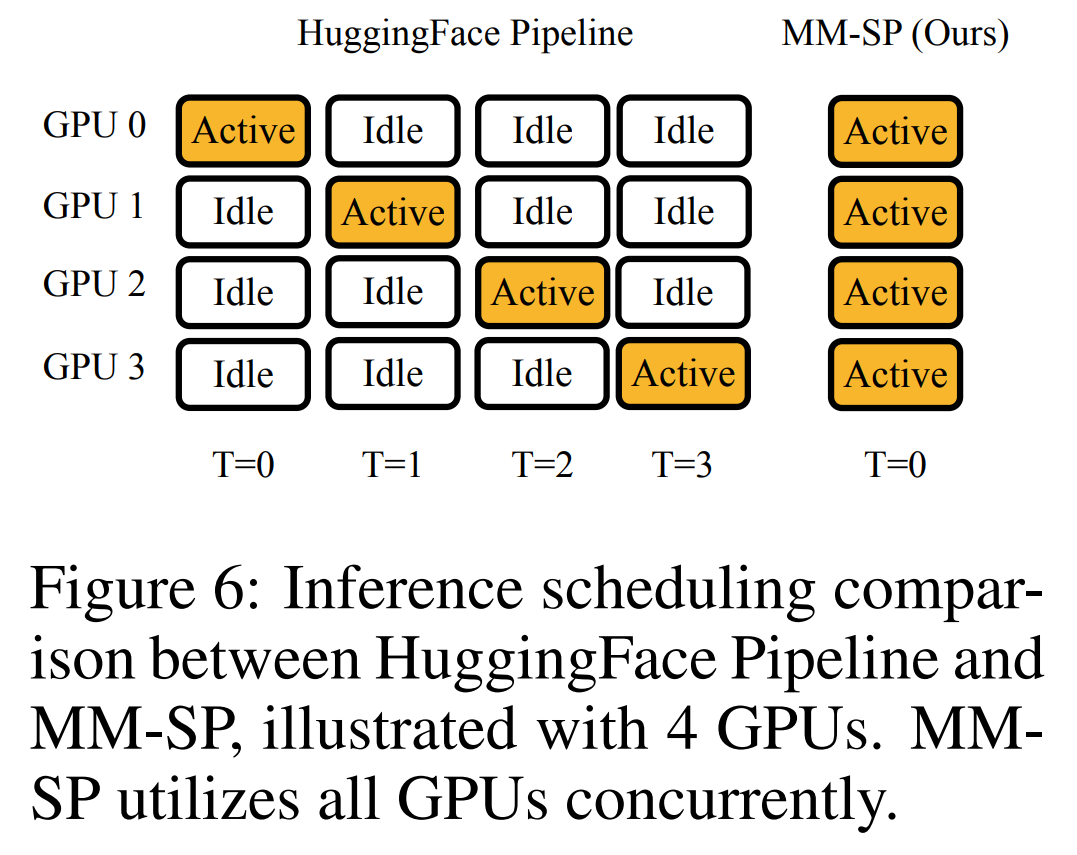
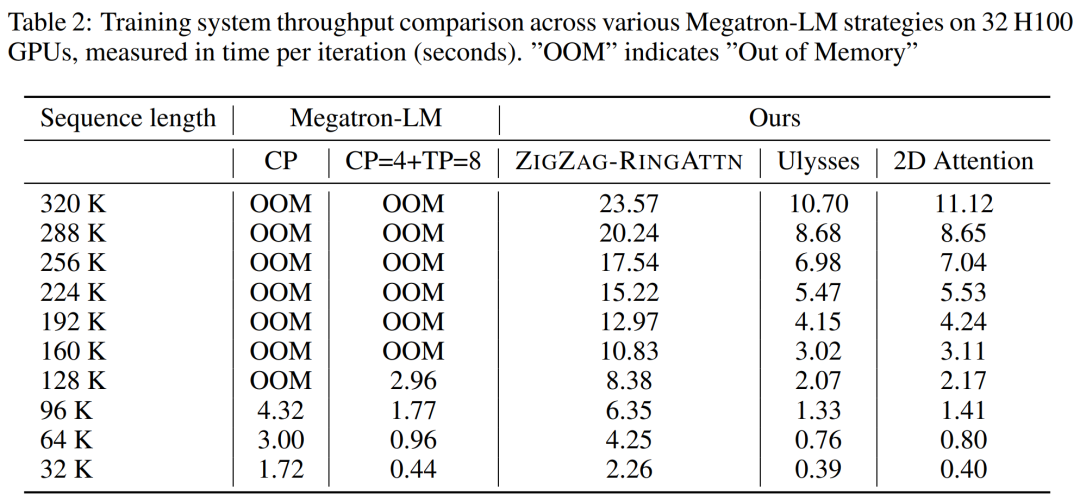
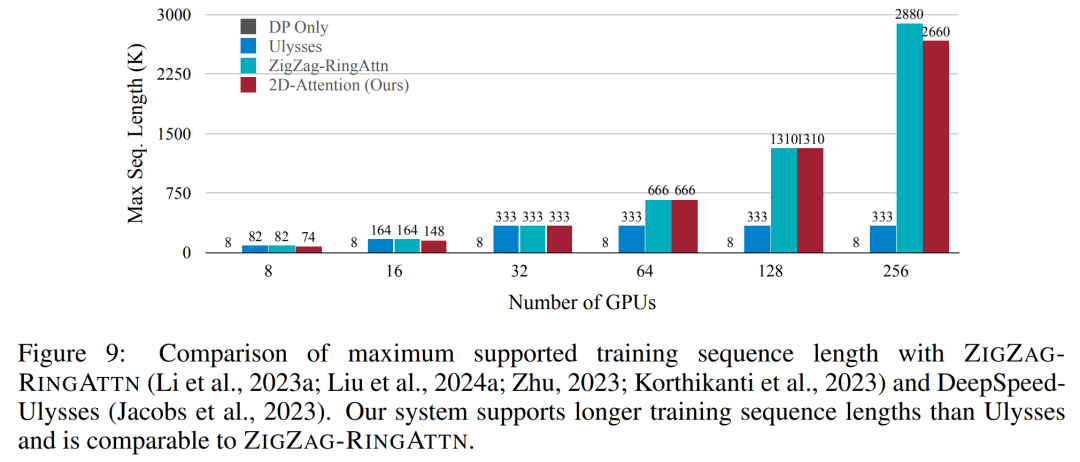
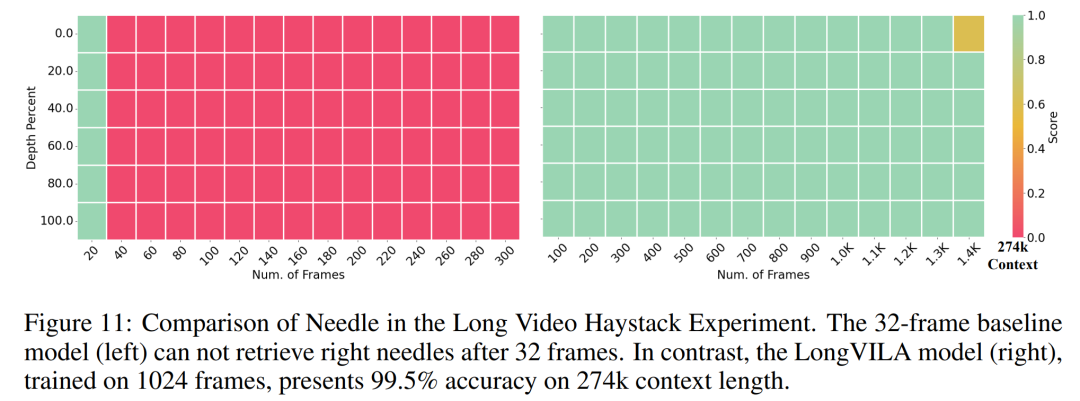
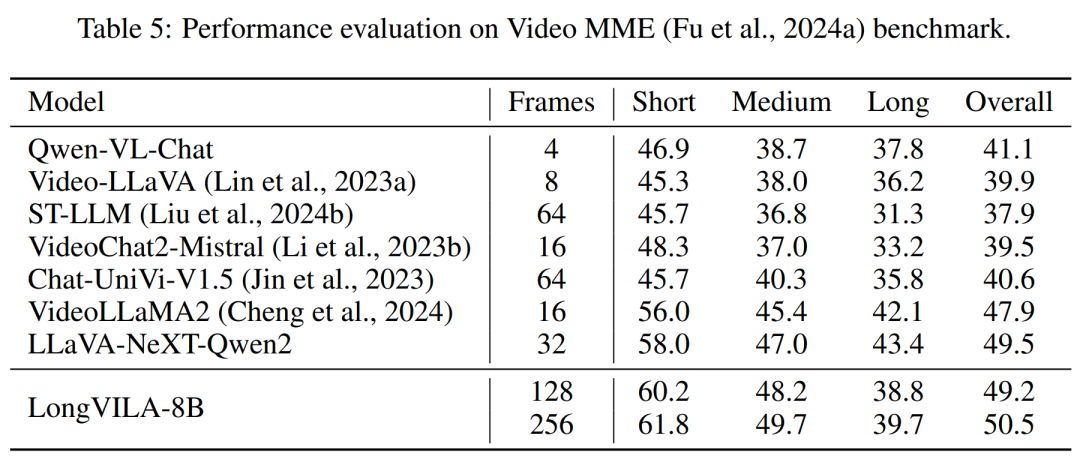
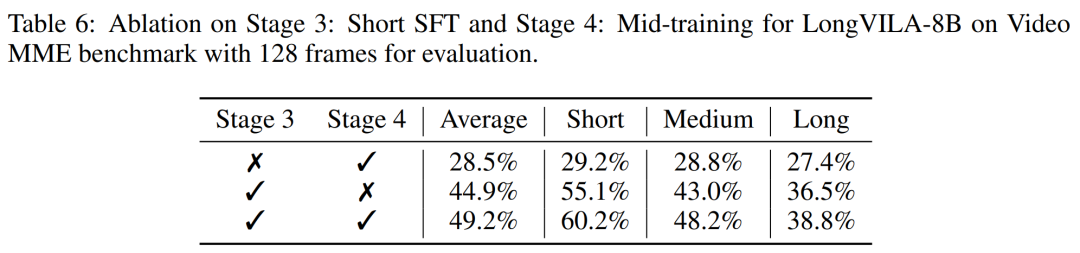
Für die Trainingsinfrastruktur etablierte die Studie ein effizientes und benutzerfreundliches Framework, nämlich Multimodal Sequence Parallel (MM-SP). ), das das Training von Memory-Dense Long Context VLM unterstützt. Für die Trainingspipeline implementierten die Forscher einen fünfstufigen Trainingsprozess, wie in Abbildung 1 dargestellt: nämlich (1) multimodale Ausrichtung, (2) groß angelegtes Vortraining, (3) Kurz- überwachte Feinabstimmung, (4) kontextuelle Erweiterung von LLM und (5) lang überwachte Feinabstimmung. Zur Inferenz löst MM-SP das Problem der KV-Cache-Speichernutzung, die bei der Verarbeitung sehr langer Sequenzen zu einem Engpass werden kann. Durch die Verwendung von LongVILA zur Erhöhung der Anzahl von Videobildern zeigen experimentelle Ergebnisse, dass sich die Leistung dieser Studie bei VideoMME- und langen Video-Untertitelaufgaben weiter verbessert (Abbildung 2). Das auf 1024 Frames trainierte LongVILA-Modell erreichte im Nadel-im-Heuhaufen-Experiment mit 1400 Frames eine Genauigkeit von 99,5 %, was einer Kontextlänge von 274.000 Token entspricht. Darüber hinaus kann das MM-SP-System die Kontextlänge ohne Gradientenprüfpunkte effektiv auf 2 Millionen Token erweitern und so eine 2,1- bis 5,7-fache Beschleunigung im Vergleich zur Ringsequenzparallelität und Megatron-Kontextparallelität erreichen. Die Tensor-Parallelität erreicht eine 1,1- bis 1,4-fache Beschleunigung im Vergleich zu Tensor Parallel. 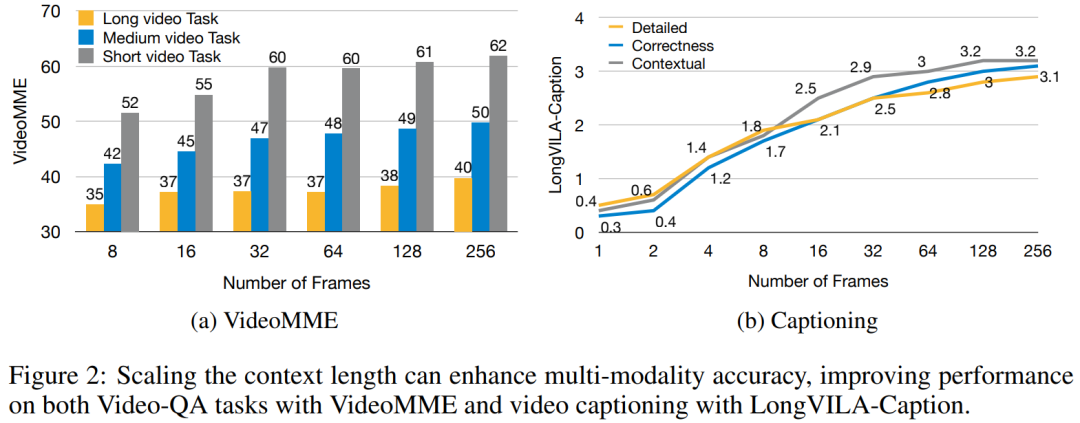 Das Bild unten ist ein Beispiel für die LongVILA-Technologie bei der Verarbeitung langer Videountertitel: Zu Beginn der Untertitel beschreibt das 8-Frame-Basismodell nur ein statisches Bild und zwei Autos. Im Vergleich dazu zeigen 256 Bilder von LongVILA ein Auto auf Schnee, einschließlich Vorder-, Rück- und Seitenansichten des Fahrzeugs. In Bezug auf die Details zeigt das 256-Frame-LongVILA auch Nahaufnahmen des Zündknopfs, des Schalthebels und des Kombiinstruments, die beim 8-Frame-Basismodell fehlen. Multimodale Sequenzparallelität Das Training von Long-Context-Visual-Language-Modellen (VLM) führt zu erheblichen Speicheranforderungen. Im langen Videotraining der Stufe 5 in Abbildung 1 unten enthält beispielsweise eine einzelne Sequenz 200.000 Token, die 1024 Videobilder generieren, was die Speicherkapazität einer einzelnen GPU übersteigt. Forscher haben ein maßgeschneidertes System entwickelt, das auf Sequenzparallelität basiert. Sequentielle Parallelität ist eine Technik, die häufig in aktuellen Basismodellsystemen verwendet wird, um das Nur-Text-LLM-Training zu optimieren. Allerdings stellten Forscher fest, dass bestehende Systeme weder effizient noch skalierbar genug sind, um VLM-Workloads mit langen Kontexten zu bewältigen.Nachdem die Forscher die Einschränkungen bestehender Systeme identifiziert hatten, kamen sie zu dem Schluss, dass bei einem idealen multimodalen Sequenz-Parallel-Ansatz Effizienz und Skalierbarkeit durch Berücksichtigung der Modal- und Netzwerkheterogenität Priorität haben sollten und die Skalierbarkeit nicht durch die Anzahl der Aufmerksamkeitsköpfe eingeschränkt werden sollte. MM-SP-Workflow. Um die Herausforderung der modalen Heterogenität anzugehen, schlagen Forscher eine zweistufige Sharding-Strategie vor, um den Rechenaufwand in den Phasen der Bildkodierung und Sprachmodellierung zu optimieren. Wie in Abbildung 4 unten dargestellt, verteilt die erste Stufe zunächst Bilder (z. B. Videobilder) gleichmäßig auf Geräte innerhalb der sequenziellen parallelen Prozessgruppe, um einen Lastausgleich während der Bildkodierungsphase zu erreichen. In der zweiten Phase aggregieren die Forscher globale visuelle und textliche Eingaben für das Sharding auf Token-Ebene. 2D-Aufmerksamkeitsparallelität. Um Netzwerkheterogenität zu lösen und Skalierbarkeit zu erreichen, kombinieren Forscher die Vorteile der Ringsequenzparallelität und der Ulysses-Sequenzparallelität. Konkret betrachten sie Parallelität über Sequenzdimensionen oder Aufmerksamkeitskopfdimensionen hinweg als „1D SP“. Die Methode skaliert durch parallele Berechnung über Aufmerksamkeitsköpfe und Sequenzdimensionen hinweg und wandelt ein 1D-SP in ein 2D-Gitter um, das aus unabhängigen Gruppen von Ring- (P2P) und Ulysses- (A2A) Prozessen besteht. Wie auf der linken Seite von Abbildung 3 unten gezeigt, verwendete der Forscher 2D-SP, um ein 4×2-Kommunikationsgitter aufzubauen, um eine 8-Grad-Sequenzparallelität über zwei Knoten hinweg zu erreichen. Um weiter zu erklären, wie ZIGZAG-RINGATTN Berechnungen ausbalanciert und wie der 2D-Aufmerksamkeitsmechanismus funktioniert, erläutern die Forscher in Abbildung 5 unten außerdem den Aufmerksamkeitsberechnungsplan mit verschiedenen Methoden. Im Vergleich zur nativen Pipeline-Parallelstrategie von HuggingFace ist der Inferenzmodus dieses Artikels effizienter, da alle Geräte gleichzeitig an der Berechnung teilnehmen und dadurch den Prozess proportional zur Anzahl der Maschinen beschleunigen, wie in Abbildung dargestellt 6 unten. Gleichzeitig ist dieser Inferenzmodus skalierbar, wobei der Speicher gleichmäßig auf die Geräte verteilt wird, um mehr Maschinen zur Unterstützung längerer Sequenzen zu nutzen. LongVILA-TrainingsprozessWie oben erwähnt, wird der Trainingsprozess von LongVILA in 5 Stufen abgeschlossen. Die Hauptaufgaben jeder Stufe sind wie folgt: In Stufe 1 kann nur der multimodale Mapper trainiert werden, andere Mapper werden eingefroren. In Stufe 2 haben die Forscher den visuellen Encoder eingefroren und den LLM und den multimodalen Mapper trainiert. In Stufe 3 verfeinern die Forscher das Modell umfassend für kurze Datenanweisungsaufgaben, z. B. die Verwendung von Bild- und kurzen Videodatensätzen. In Stufe 4 verwenden Forscher Nur-Text-Datensätze, um die Kontextlänge von LLM kontinuierlich vor dem Training zu erweitern. In Stufe 5 verwenden Forscher eine lange Videoüberwachung zur Feinabstimmung, um die Fähigkeit zur Befolgung von Anweisungen zu verbessern. Es ist erwähnenswert, dass in dieser Phase alle Parameter trainierbar sind. Experimentelle ErgebnisseDie Forscher bewerteten die Full-Stack-Lösung in diesem Artikel unter zwei Aspekten: System und Modellierung. Sie präsentieren zunächst Trainings- und Inferenzergebnisse und veranschaulichen die Effizienz und Skalierbarkeit eines Systems, das Langkontexttraining und Inferenz unterstützen kann. Anschließend bewerten wir die Leistung des Langkontextmodells bei Aufgaben zur Untertitelung und zur Befolgung von Anweisungen. Trainings- und InferenzsystemDiese Studie liefert eine quantitative Bewertung des Durchsatzes des Trainingssystems, der Latenz des Inferenzsystems und der maximal unterstützten Sequenzlänge. Tabelle 2 zeigt die Durchsatzergebnisse. Im Vergleich zu ZIGZAG-RINGATTN erreicht dieses System eine 2,1- bis 5,7-fache Beschleunigung und die Leistung ist vergleichbar mit DeepSpeed-Ulysses. Im Vergleich zur optimierteren Ringsequenz-Parallelimplementierung in Megatron-LM CP wird eine Geschwindigkeitssteigerung von 3,1x bis 4,3x erreicht. Kajian ini menilai panjang jujukan maksimum yang disokong oleh bilangan GPU tetap dengan meningkatkan panjang jujukan secara beransur-ansur daripada 1k kepada 10k sehingga ralat ingatan hilang. berlaku. Hasilnya diringkaskan dalam Rajah 9. Apabila menskalakan kepada 256 GPU, kaedah kami boleh menyokong lebih kurang 8 kali panjang konteks. Tambahan pula, sistem yang dicadangkan mencapai penskalaan panjang konteks yang serupa dengan ZIGZAG-RINGATTN, menyokong lebih daripada 2 juta panjang konteks pada 256 GPU. Jadual 3 membandingkan panjang jujukan maksimum yang disokong, dan kaedah yang dicadangkan dalam kajian ini menyokong jujukan yang 2.9 kali lebih lama daripada yang disokong oleh HuggingFace Pipeline. Rajah 11 menunjukkan keputusan eksperimen video panjang jarum dalam timbunan jerami. Sebaliknya, model LongVILA (kanan) menunjukkan prestasi yang dipertingkatkan merentas pelbagai bingkai dan kedalaman. Jadual 5 menyenaraikan prestasi pelbagai model pada penanda aras Video MME, membandingkannya pada keberkesanan video pendek, sederhana dan panjang serta prestasi keseluruhan. LongVILA-8B menggunakan 256 bingkai dan mempunyai skor keseluruhan 50.5. Para penyelidik juga menjalankan kajian ablasi tentang kesan peringkat 3 dan 4 dalam Jadual 6. Jadual 7 menunjukkan metrik prestasi model LongVILA yang dilatih dan dinilai pada bilangan bingkai yang berbeza (8, 128 dan 256). Apabila bilangan bingkai bertambah, prestasi model bertambah baik dengan ketara. Secara khususnya, skor purata meningkat daripada 2.00 kepada 3.26, menyerlahkan keupayaan model untuk menjana sari kata yang tepat dan kaya pada bilangan bingkai yang lebih tinggi.
Das Bild unten ist ein Beispiel für die LongVILA-Technologie bei der Verarbeitung langer Videountertitel: Zu Beginn der Untertitel beschreibt das 8-Frame-Basismodell nur ein statisches Bild und zwei Autos. Im Vergleich dazu zeigen 256 Bilder von LongVILA ein Auto auf Schnee, einschließlich Vorder-, Rück- und Seitenansichten des Fahrzeugs. In Bezug auf die Details zeigt das 256-Frame-LongVILA auch Nahaufnahmen des Zündknopfs, des Schalthebels und des Kombiinstruments, die beim 8-Frame-Basismodell fehlen. Multimodale Sequenzparallelität Das Training von Long-Context-Visual-Language-Modellen (VLM) führt zu erheblichen Speicheranforderungen. Im langen Videotraining der Stufe 5 in Abbildung 1 unten enthält beispielsweise eine einzelne Sequenz 200.000 Token, die 1024 Videobilder generieren, was die Speicherkapazität einer einzelnen GPU übersteigt. Forscher haben ein maßgeschneidertes System entwickelt, das auf Sequenzparallelität basiert. Sequentielle Parallelität ist eine Technik, die häufig in aktuellen Basismodellsystemen verwendet wird, um das Nur-Text-LLM-Training zu optimieren. Allerdings stellten Forscher fest, dass bestehende Systeme weder effizient noch skalierbar genug sind, um VLM-Workloads mit langen Kontexten zu bewältigen.Nachdem die Forscher die Einschränkungen bestehender Systeme identifiziert hatten, kamen sie zu dem Schluss, dass bei einem idealen multimodalen Sequenz-Parallel-Ansatz Effizienz und Skalierbarkeit durch Berücksichtigung der Modal- und Netzwerkheterogenität Priorität haben sollten und die Skalierbarkeit nicht durch die Anzahl der Aufmerksamkeitsköpfe eingeschränkt werden sollte. MM-SP-Workflow. Um die Herausforderung der modalen Heterogenität anzugehen, schlagen Forscher eine zweistufige Sharding-Strategie vor, um den Rechenaufwand in den Phasen der Bildkodierung und Sprachmodellierung zu optimieren. Wie in Abbildung 4 unten dargestellt, verteilt die erste Stufe zunächst Bilder (z. B. Videobilder) gleichmäßig auf Geräte innerhalb der sequenziellen parallelen Prozessgruppe, um einen Lastausgleich während der Bildkodierungsphase zu erreichen. In der zweiten Phase aggregieren die Forscher globale visuelle und textliche Eingaben für das Sharding auf Token-Ebene. 2D-Aufmerksamkeitsparallelität. Um Netzwerkheterogenität zu lösen und Skalierbarkeit zu erreichen, kombinieren Forscher die Vorteile der Ringsequenzparallelität und der Ulysses-Sequenzparallelität. Konkret betrachten sie Parallelität über Sequenzdimensionen oder Aufmerksamkeitskopfdimensionen hinweg als „1D SP“. Die Methode skaliert durch parallele Berechnung über Aufmerksamkeitsköpfe und Sequenzdimensionen hinweg und wandelt ein 1D-SP in ein 2D-Gitter um, das aus unabhängigen Gruppen von Ring- (P2P) und Ulysses- (A2A) Prozessen besteht. Wie auf der linken Seite von Abbildung 3 unten gezeigt, verwendete der Forscher 2D-SP, um ein 4×2-Kommunikationsgitter aufzubauen, um eine 8-Grad-Sequenzparallelität über zwei Knoten hinweg zu erreichen. Um weiter zu erklären, wie ZIGZAG-RINGATTN Berechnungen ausbalanciert und wie der 2D-Aufmerksamkeitsmechanismus funktioniert, erläutern die Forscher in Abbildung 5 unten außerdem den Aufmerksamkeitsberechnungsplan mit verschiedenen Methoden. Im Vergleich zur nativen Pipeline-Parallelstrategie von HuggingFace ist der Inferenzmodus dieses Artikels effizienter, da alle Geräte gleichzeitig an der Berechnung teilnehmen und dadurch den Prozess proportional zur Anzahl der Maschinen beschleunigen, wie in Abbildung dargestellt 6 unten. Gleichzeitig ist dieser Inferenzmodus skalierbar, wobei der Speicher gleichmäßig auf die Geräte verteilt wird, um mehr Maschinen zur Unterstützung längerer Sequenzen zu nutzen. LongVILA-TrainingsprozessWie oben erwähnt, wird der Trainingsprozess von LongVILA in 5 Stufen abgeschlossen. Die Hauptaufgaben jeder Stufe sind wie folgt: In Stufe 1 kann nur der multimodale Mapper trainiert werden, andere Mapper werden eingefroren. In Stufe 2 haben die Forscher den visuellen Encoder eingefroren und den LLM und den multimodalen Mapper trainiert. In Stufe 3 verfeinern die Forscher das Modell umfassend für kurze Datenanweisungsaufgaben, z. B. die Verwendung von Bild- und kurzen Videodatensätzen. In Stufe 4 verwenden Forscher Nur-Text-Datensätze, um die Kontextlänge von LLM kontinuierlich vor dem Training zu erweitern. In Stufe 5 verwenden Forscher eine lange Videoüberwachung zur Feinabstimmung, um die Fähigkeit zur Befolgung von Anweisungen zu verbessern. Es ist erwähnenswert, dass in dieser Phase alle Parameter trainierbar sind. Experimentelle ErgebnisseDie Forscher bewerteten die Full-Stack-Lösung in diesem Artikel unter zwei Aspekten: System und Modellierung. Sie präsentieren zunächst Trainings- und Inferenzergebnisse und veranschaulichen die Effizienz und Skalierbarkeit eines Systems, das Langkontexttraining und Inferenz unterstützen kann. Anschließend bewerten wir die Leistung des Langkontextmodells bei Aufgaben zur Untertitelung und zur Befolgung von Anweisungen. Trainings- und InferenzsystemDiese Studie liefert eine quantitative Bewertung des Durchsatzes des Trainingssystems, der Latenz des Inferenzsystems und der maximal unterstützten Sequenzlänge. Tabelle 2 zeigt die Durchsatzergebnisse. Im Vergleich zu ZIGZAG-RINGATTN erreicht dieses System eine 2,1- bis 5,7-fache Beschleunigung und die Leistung ist vergleichbar mit DeepSpeed-Ulysses. Im Vergleich zur optimierteren Ringsequenz-Parallelimplementierung in Megatron-LM CP wird eine Geschwindigkeitssteigerung von 3,1x bis 4,3x erreicht. Kajian ini menilai panjang jujukan maksimum yang disokong oleh bilangan GPU tetap dengan meningkatkan panjang jujukan secara beransur-ansur daripada 1k kepada 10k sehingga ralat ingatan hilang. berlaku. Hasilnya diringkaskan dalam Rajah 9. Apabila menskalakan kepada 256 GPU, kaedah kami boleh menyokong lebih kurang 8 kali panjang konteks. Tambahan pula, sistem yang dicadangkan mencapai penskalaan panjang konteks yang serupa dengan ZIGZAG-RINGATTN, menyokong lebih daripada 2 juta panjang konteks pada 256 GPU. Jadual 3 membandingkan panjang jujukan maksimum yang disokong, dan kaedah yang dicadangkan dalam kajian ini menyokong jujukan yang 2.9 kali lebih lama daripada yang disokong oleh HuggingFace Pipeline. Rajah 11 menunjukkan keputusan eksperimen video panjang jarum dalam timbunan jerami. Sebaliknya, model LongVILA (kanan) menunjukkan prestasi yang dipertingkatkan merentas pelbagai bingkai dan kedalaman. Jadual 5 menyenaraikan prestasi pelbagai model pada penanda aras Video MME, membandingkannya pada keberkesanan video pendek, sederhana dan panjang serta prestasi keseluruhan. LongVILA-8B menggunakan 256 bingkai dan mempunyai skor keseluruhan 50.5. Para penyelidik juga menjalankan kajian ablasi tentang kesan peringkat 3 dan 4 dalam Jadual 6. Jadual 7 menunjukkan metrik prestasi model LongVILA yang dilatih dan dinilai pada bilangan bingkai yang berbeza (8, 128 dan 256). Apabila bilangan bingkai bertambah, prestasi model bertambah baik dengan ketara. Secara khususnya, skor purata meningkat daripada 2.00 kepada 3.26, menyerlahkan keupayaan model untuk menjana sari kata yang tepat dan kaya pada bilangan bingkai yang lebih tinggi. Das obige ist der detaillierte Inhalt vonNVIDIA „LongVILA' unterstützt 1024 Bilder und eine Genauigkeit von nahezu 100 % und beginnt mit der Entwicklung langer Videos. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!






 So beheben Sie den Fehlercode 8024401C
So beheben Sie den Fehlercode 8024401C
 Ist das Hongmeng-System einfach zu bedienen?
Ist das Hongmeng-System einfach zu bedienen?
 Die Beziehung zwischen Bandbreite und Netzwerkgeschwindigkeit
Die Beziehung zwischen Bandbreite und Netzwerkgeschwindigkeit
 Verwendung von Hintergrundbildern
Verwendung von Hintergrundbildern
 Welche Methoden gibt es, Crawler zu verhindern?
Welche Methoden gibt es, Crawler zu verhindern?
 Empfehlungen für Android-Desktop-Software
Empfehlungen für Android-Desktop-Software
 Was ist das Dateiformat von mkv?
Was ist das Dateiformat von mkv?
 Was ist ein Root-Domain-Nameserver?
Was ist ein Root-Domain-Nameserver?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



