


Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Mit der Vertiefung der Forschung zu großen Modellen ist die Frage, wie man sie auf mehr Modalitäten fördern kann, in Wissenschaft und Industrie zu einem heißen Thema geworden. Kürzlich veröffentlichte große Closed-Source-Modelle wie GPT-4o und Claude 3.5 verfügen bereits über starke Bildverständnisfähigkeiten, und Open-Source-Feldmodelle wie LLaVA-NeXT, MiniCPM und InternVL haben ebenfalls eine Leistung gezeigt, die der von Closed-Source immer näher kommt .
In Zeiten von „80.000 Kilogramm pro Mu“ und „einem SoTA alle 10 Tage“ wird ein multimodaler Bewertungsrahmen, der einfach zu verwenden ist, transparente Standards hat und reproduzierbar ist, immer wichtiger, und das ist nicht einfach.
Um die oben genannten Probleme zu lösen, haben Forscher des LMMs-Lab der Nanyang Technological University gemeinsam LMMs-Eval als Open-Source-Lösung entwickelt, ein Evaluierungsframework, das speziell für multimodale Großmodelle entwickelt wurde und die Evaluierung multimodaler Modelle (LMMs) ermöglicht ). Eine effiziente Lösung aus einer Hand.

Code-Repository: https://github.com/EvolvingLMMs-Lab/lmms-eval
Offizielle Homepage: https://lmms-lab.github.io/
Papieradresse : https://arxiv.org/abs/2407.12772
Listenadresse: https://huggingface.co/spaces/lmms-lab/LiveBench
Seit seiner Veröffentlichung im März 2024 ist LMMs-Eval das Framework hat gemeinsame Beiträge von der Open-Source-Community, Unternehmen und Universitäten erhalten. Mittlerweile hat es 1,1.000 Sterne auf Github erhalten, mit mehr als 30 Mitwirkenden, darunter insgesamt mehr als 80 Datensätzen und mehr als 10 Modellen, und die Zahl nimmt weiter zu.

Standardisierter Bewertungsrahmen
Um eine standardisierte Bewertungsplattform bereitzustellen, umfasst LMMs-Eval die folgenden Funktionen:
Einheitliche Schnittstelle: LMMs-Eval basiert auf dem Textbewertungsrahmen lm-evaluation- Harness Es wurde verbessert und erweitert, um Benutzern das Hinzufügen neuer multimodaler Modelle und Datensätze zu erleichtern, indem eine einheitliche Schnittstelle für Modelle, Datensätze und Bewertungsindikatoren definiert wurde.
Ein-Klick-Start: LMMs-Eval hostet über 80 (und wachsende) Datensätze auf HuggingFace, sorgfältig transformiert aus den Originalquellen, einschließlich aller Varianten, Versionen und Splits. Benutzer müssen keine Vorbereitungen treffen. Mit nur einem Befehl werden mehrere Datensätze und Modelle automatisch heruntergeladen und getestet, und die Ergebnisse stehen in wenigen Minuten zur Verfügung.
Transparent und reproduzierbar: LMMs-Eval verfügt über ein integriertes einheitliches Protokollierungstool. Jede vom Modell beantwortete Frage und ob sie richtig ist oder nicht, wird aufgezeichnet, um Reproduzierbarkeit und Transparenz zu gewährleisten. Es erleichtert auch den Vergleich der Vor- und Nachteile verschiedener Modelle.
Die Vision von LMMs-Eval ist, dass zukünftige multimodale Modelle keinen eigenen Datenverarbeitungs-, Inferenz- und Übermittlungscode mehr schreiben müssen. In der heutigen Umgebung, in der multimodale Testsätze stark konzentriert sind, ist dieser Ansatz unrealistisch und die gemessenen Ergebnisse lassen sich nur schwer direkt mit anderen Modellen vergleichen. Durch den Zugriff auf LMMs-Eval können sich Modelltrainer mehr auf die Verbesserung und Optimierung des Modells selbst konzentrieren, anstatt Zeit mit der Bewertung und Ausrichtung von Ergebnissen zu verbringen.
Das „unmögliche Dreieck“ der Bewertung
Das ultimative Ziel von LMMs-Eval ist es, eine 1. breite Abdeckung, 2. niedrige Kosten und 3. keine Datenverlustmethode zur Bewertung von LMMs zu finden. Doch selbst mit LMMs-Eval war es für das Autorenteam schwierig oder sogar unmöglich, alle drei gleichzeitig durchzuführen.
Wie in der folgenden Abbildung dargestellt, wurde es sehr zeitaufwändig, eine umfassende Auswertung dieser Datensätze durchzuführen, als sie den Bewertungsdatensatz auf über 50 erweiterten. Darüber hinaus sind diese Benchmarks auch während des Trainings anfällig für Kontaminationen. Zu diesem Zweck schlug LMMs-Eval LMMs-Eval-Lite vor, um eine breite Abdeckung und niedrige Kosten zu berücksichtigen. Sie haben LiveBench außerdem so konzipiert, dass es kostengünstig ist und keine Datenverluste verursacht.

LMMs-Eval-Lite: Leichte Evaluierung mit breiter Abdeckung

Bei der Bewertung großer Modelle erhöhen die große Anzahl an Parametern und Testaufgaben häufig den Zeit- und Kostenaufwand für die Bewertungsaufgabe erheblich. Daher entscheiden sich Menschen häufig für die Verwendung kleinerer Datensätze oder für die Verwendung spezifischer Datensätze zur Bewertung. Eine eingeschränkte Bewertung führt jedoch häufig zu einem Mangel an Verständnis für die Modellfähigkeiten. Um sowohl der Vielfalt der Bewertung als auch den Kosten der Bewertung Rechnung zu tragen, hat LMMs-Eval LMMs-Eval-Lite

LMMs-Eval- eingeführt. Lite Wir erstellen einen vereinfachten Benchmark-Satz, um während der Modellentwicklung nützliche und schnelle Signale bereitzustellen und so das Aufblähungsproblem der heutigen Tests zu vermeiden. Wenn wir eine Teilmenge des vorhandenen Testsatzes finden können, bei der die absoluten Ergebnisse und relativen Rankings zwischen den Modellen dem vollständigen Satz ähnlich bleiben, können wir es als sicher erachten, diese Datensätze zu bereinigen.
Um die hervorstechenden Datenpunkte im Datensatz zu finden, verwendet LMMs-Eval zunächst CLIP- und BGE-Modelle, um den multimodalen Bewertungsdatensatz in die Form der Vektoreinbettung umzuwandeln, und verwendet die k-Greedy-Clustering-Methode, um die zu finden Daten hervorstechende Punkte. In Tests zeigten diese kleineren Datensätze immer noch ähnliche Auswertungsfähigkeiten wie der gesamte Satz.

Anschließend verwendete LMMs-Eval dieselbe Methode, um eine Lite-Version zu erstellen, die mehr Datensätze abdeckt. Diese Datensätze sollen dabei helfen, Evaluierungskosten während der Entwicklung zu sparen, um die Modellleistung schnell beurteilen zu können

LiveBench: Dynamisches Testen von LMMs
Traditionelle Benchmarks konzentrieren sich auf die statische Bewertung anhand fester Fragen und Antworten. Mit dem Fortschritt der multimodalen Forschung sind Open-Source-Modelle im Punktevergleich oft besser als kommerzielle Modelle wie GPT-4V, fallen aber bei der tatsächlichen Benutzererfahrung zurück. Dynamische, benutzergesteuerte Chatbots Arenas und WildVision werden für die Modellbewertung immer beliebter, erfordern jedoch die Erfassung Tausender Benutzerpräferenzen und sind äußerst kostspielig in der Bewertung.
Die Kernidee von LiveBench besteht darin, die Leistung des Modells anhand eines kontinuierlich aktualisierten Datensatzes zu bewerten, um eine Kontaminationsfreiheit zu erreichen und die Kosten niedrig zu halten. Das Autorenteam sammelte Bewertungsdaten aus dem Internet und baute eine Pipeline auf, um automatisch die neuesten globalen Informationen von Websites wie Nachrichten und Community-Foren zu sammeln. Um die Aktualität und Authentizität der Informationen sicherzustellen, wählte das Autorenteam Quellen aus mehr als 60 Nachrichtenagenturen aus, darunter CNN, BBC, Japans Asahi Shimbun und Chinas Nachrichtenagentur Xinhua sowie Foren wie Reddit. Die spezifischen Schritte sind wie folgt:
Erstellen Sie einen Screenshot der Startseite und entfernen Sie Anzeigen und Nicht-Nachrichtenelemente.
Entwerfen Sie Frage- und Antwortsätze mit den leistungsstärksten derzeit verfügbaren multimodalen Modellen wie GPT4-V, Claude-3-Opus und Gemini-1.5-Pro.
Fragen wurden von einem anderen Modell überprüft und überarbeitet, um Genauigkeit und Relevanz sicherzustellen.
Der endgültige Fragen- und Antwortsatz wird manuell überprüft, jeden Monat werden etwa 500 Fragen gesammelt und 100–300 werden als endgültiger Livebench-Fragensatz aufbewahrt.
Unter Verwendung der Bewertungskriterien von LLaVA-Wilder und Vibe-Eval bewertet das Bewertungsmodell basierend auf den bereitgestellten Standardantworten und der Bewertungsbereich beträgt [1, 10]. Das Standardbewertungsmodell ist GPT-4o, wobei Claude-3-Opus und Gemini 1.5 Pro als Alternativen ebenfalls enthalten sind. Die endgültigen gemeldeten Ergebnisse basieren auf Punktzahlen, die in eine Genauigkeitsmetrik im Bereich von 0 bis 100 umgewandelt werden.
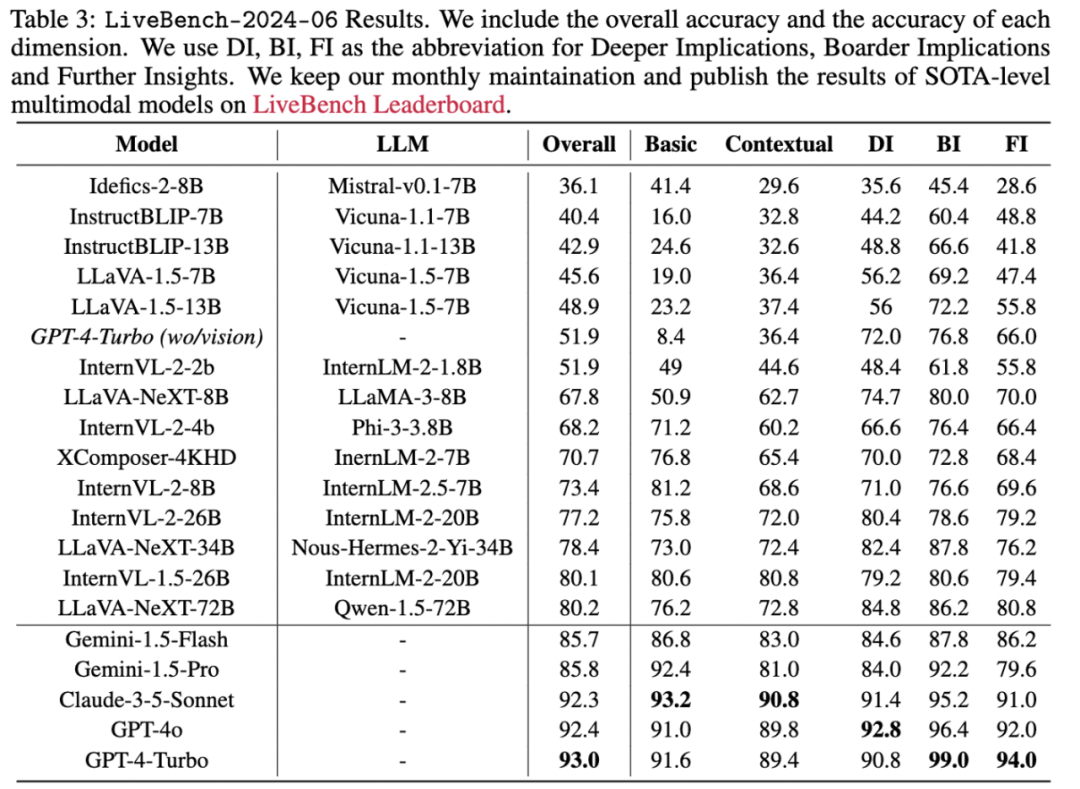
Zukünftig können Sie in unserer dynamisch aktualisierten Liste auch die neuesten Evaluierungsdaten multimodaler Modelle einsehen, die jeden Monat dynamisch aktualisiert werden, sowie die neuesten Evaluierungsergebnisse in der Liste.
Das obige ist der detaillierte Inhalt vonDas multimodale Modellbewertungsframework lmms-eval ist veröffentlicht! Umfassende Abdeckung, niedrige Kosten, keine Umweltverschmutzung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So beheben Sie den Fehlercode 8024401C
So beheben Sie den Fehlercode 8024401C
 Ist das Hongmeng-System einfach zu bedienen?
Ist das Hongmeng-System einfach zu bedienen?
 Die Beziehung zwischen Bandbreite und Netzwerkgeschwindigkeit
Die Beziehung zwischen Bandbreite und Netzwerkgeschwindigkeit
 Verwendung von Hintergrundbildern
Verwendung von Hintergrundbildern
 Welche Methoden gibt es, Crawler zu verhindern?
Welche Methoden gibt es, Crawler zu verhindern?
 Empfehlungen für Android-Desktop-Software
Empfehlungen für Android-Desktop-Software
 Was ist das Dateiformat von mkv?
Was ist das Dateiformat von mkv?
 Was ist ein Root-Domain-Nameserver?
Was ist ein Root-Domain-Nameserver?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



