

Hallo!
Heute habe ich beschlossen, zwei Bereiche einzubetten: Datenwissenschaft und Cybersicherheit.
Folgen Sie mir und Sie werden sehen, worüber ich schreibe.

Ich habe eine Analyse der Anzahl der Angriffe basierend auf dem Organisationstyp durchgeführt.
Ich habe den Datensatz von Kaggle heruntergeladen.
Dann begann ich mit Jupyter Lab und Python an den Daten zu arbeiten.
Das Notizbuch dient zu Übungszwecken, zum Testen und Beobachten – oder zum Spielen mit Daten.
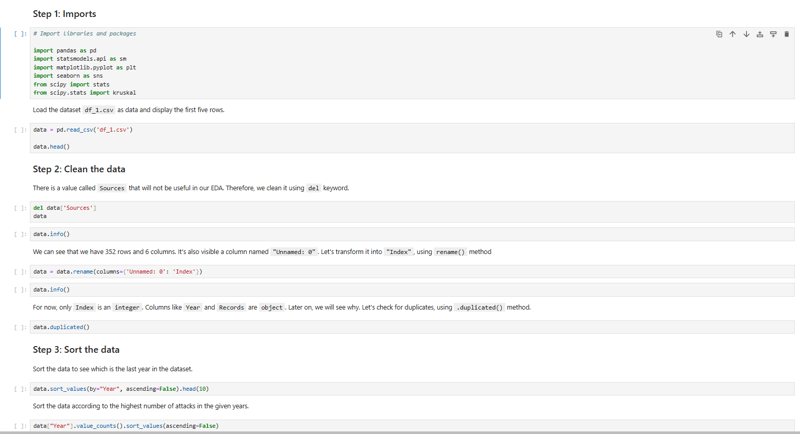
Wie immer habe ich als erstes die Daten importiert. Dann habe ich den Datensatz geladen und bereinigt.
Das Bereinigen der Daten ist ein Schritt, der öfter durchgeführt werden könnte, da EDA (Exploratory Data Analysis) ein iterativer und nicht sequentieller Prozess ist. Deshalb habe ich diesen Prozess später weitergeführt, um aussagekräftige Erkenntnisse zu gewinnen.
Ich habe eine einfache Zufallsstichprobe von n=40 gewählt, um anhand der Anzahl der Angriffe herauszufinden, welche Organisation anfälliger für Cyberangriffe ist. Einfache Zufallsstichproben bedeuten, dass jedes Mitglied der Bevölkerung die gleiche Chance hat, ausgewählt zu werden.
Die Hypothese
Nullhypothese (H0): Es gibt keinen signifikanten Unterschied in der Anzahl der Cyberangriffe, denen verschiedene Arten von Organisationen ausgesetzt sind.
Alternativhypothese (H1): Die Anzahl der Cyberangriffe unterscheidet sich erheblich zwischen verschiedenen Arten von Organisationen.
Anhand der maximalen Anzahl von Angriffen wurde der Schluss gezogen, dass die Gesundheitsbranche mit 6 Angriffen anfälliger ist. Im Gegensatz dazu gab es im Bankwesen die geringste Anzahl an Angriffen, nämlich 1.
Am Ende habe ich einen Shapiro-Wilk-Test durchgeführt, um die Verteilungsnormalität des Datensatzes zu überprüfen. Die Nullhypothese wurde abgelehnt, sodass die Daten nicht normalverteilt aussahen. Ich habe den Kruskal-Wallis-Test angewendet, bei dem ich die Nullhypothese nicht ablehnen konnte – was bedeutet, dass es keinen signifikanten Unterschied zwischen den Gruppen gibt. Einfacher ausgedrückt bedeutet dies, dass es nicht genügend Beweise gab, um mit Sicherheit sagen zu können, dass ein Organisationstyp anfälliger für Cyberangriffe ist als der andere.
Es wurden kein Konfidenzniveau, keine Fehlerspanne und kein Konfidenzintervall festgelegt. Da die Stichprobengröße klein war, ist es schwieriger, statistisch signifikante Unterschiede zu erkennen. In Zukunft werden bei der Auswahl einer Stichprobe diese Schritte beachtet und eine größere Stichprobe in Betracht gezogen.
Sie können die gesamte Arbeit auf meiner GitHub-Seite finden. ?
Wie ich angegeben habe, hat dieser Artikel einen Bonus. Die Kombination aus Datenwissenschaft und Cybersicherheit geht weiter: Ich habe einen Artikel für den TryHackMe-Raum Attacktive Directory erstellt!
Auf den ersten Blick könnte man sagen, dass diese Themen nichts miteinander zu tun haben. Nun, es ist tatsächlich eine Demonstration, wie ein Verstoß stattfinden könnte! ? Weil Datenschutzverletzungen irgendwie und aus irgendeinem Grund auftreten.
Neugierig? Schauen Sie sich meinen Beitrag auf meiner GitHub-Seite an.
Was denken Sie?
Das obige ist der detaillierte Inhalt vonAngewandte Datenwissenschaft zu Datenschutzverletzungen + Bonus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Lösung für den belegten Port phpstudy3306
Lösung für den belegten Port phpstudy3306
 Ranking der zehn besten formellen Handelsplattformen
Ranking der zehn besten formellen Handelsplattformen
 So konfigurieren Sie JDK-Umgebungsvariablen
So konfigurieren Sie JDK-Umgebungsvariablen
 Welche Auflösung ist 1080p?
Welche Auflösung ist 1080p?
 Einführung in die Bedeutung von Cloud-Download-Fenstern
Einführung in die Bedeutung von Cloud-Download-Fenstern
 Der Unterschied zwischen Header-Dateien und Quelldateien
Der Unterschied zwischen Header-Dateien und Quelldateien
 Einführung in Screenshot-Tastenkombinationen im Windows 7-System
Einführung in Screenshot-Tastenkombinationen im Windows 7-System
 Was sind die Konfigurationsparameter des Videoservers?
Was sind die Konfigurationsparameter des Videoservers?
 ppt zu Wort
ppt zu Wort








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



