

Datenstruktur kann als Sammlung verschiedener Datenelemente definiert werden. Datenstruktur in Java ist eine Möglichkeit, Daten und Informationen in einem Computersystem zu speichern und zu organisieren, damit die gespeicherten Daten effizient abgerufen und genutzt werden können. Daher kann die Verwendung einer geeigneten Datenstruktur eine entscheidende Rolle bei der Steigerung der Leistung einer Anwendung spielen.
Starten Sie Ihren kostenlosen Softwareentwicklungskurs
Webentwicklung, Programmiersprachen, Softwaretests und andere
Java API bietet integrierte Unterstützung für gängige Datenstrukturen, die von zwei Typen sind:
Dies sind grundlegende Datenstrukturen und werden nur für grundlegende Operationen verwendet. Ganzzahlen, Gleitkommazahlen, Zahlen, Zeichenfolgen, Zeichen und Zeiger fallen in diese Kategorie von Datenstrukturen.
Dies sind komplexe Datenstrukturen und sollen komplexe datenbezogene Operationen ausführen. Nicht-primitive Datenstrukturen werden von primitiven Datenstrukturen abgeleitet. Nicht-primitive Datenstrukturen können grob in zwei Unterkategorien unterteilt werden: lineare Datenstrukturen und nichtlineare Datenstrukturen. Array, verknüpfte Liste, Stapel und Warteschlange fallen in die Kategorie der linearen Datenstrukturen, während Bäume und Diagramme in die Kategorie der nichtlinearen Datenstrukturen fallen. Jetzt erklären wir jede Datenstruktur im Detail:
Ein Array kann als Sammlung homogener Elemente definiert werden. Ein Array ist eine statische Datenstruktur fester Größe. Jedes einzelne Element eines Arrays wird als Element bezeichnet. Ein Array in Java kann jeden gültigen Datentyp haben, der in einer Java-Programmiersprache verfügbar ist. Alle Elemente im Array werden durch denselben Variablennamen identifiziert, aber jedes Element verfügt über einen eindeutigen Index, über den sein Wert gespeichert oder abgerufen werden kann. Ein Java-Array kann eindimensional, zweidimensional oder mehrdimensional sein. Einzelne Elemente eines Arrays mit dem Variablennamen arr und der Größe 10 sind wie folgt: arr [0], arr [1], arr [2], arr [3]……………………, arr [9].
Verknüpfte Listen verwalten eine Liste im Speicher und sind eine Sammlung von Elementen, die als Knoten bezeichnet werden. Hierbei handelt es sich um eine dynamische Datenstruktur, deren Größe nicht festgelegt ist. Eine verknüpfte Liste hat einen Kopfknoten und einen Endknoten und jeder verfügbare Knoten in einer verknüpften Liste enthält einen Zeiger auf den benachbarten Knoten. Es ist zu beachten, dass Knoten einer verknüpften Liste an nicht zusammenhängenden Stellen im Speicher vorhanden sind.
Es handelt sich um eine dynamische Datenstruktur, in der das Einfügen eines neuen Elements und das Löschen eines vorhandenen Elements nur an einem Ende erfolgen darf. Es folgt der Last-in-First-out-Strategie (LIFO). Der Stack kann in den meisten Programmiersprachen implementiert werden und wird daher als abstrakter Datentyp (ADT) betrachtet.
Dies ist ebenfalls ein abstrakter Datentyp wie Stack und kann in den meisten Programmiersprachen implementiert werden. Hierbei handelt es sich um eine dynamische Datenstruktur, die der FIFO-Strategie (First In First Out) folgt, was bedeutet, dass ein Element, das zuerst eingefügt wird, zuerst entfernt wird. Die Warteschlange hat zwei Enden, die als Front-End und Rear-End bezeichnet werden. In einer Warteschlange kann das Einfügen am hinteren Ende und das Löschen am vorderen Ende erfolgen.
Die Baumdatenstruktur basiert auf der Eltern-Kind-Beziehung. Hierbei handelt es sich um mehrstufige Datenstrukturen, die aus einer Sammlung von Elementen bestehen, die als Knoten bezeichnet werden. Knoten in einer Baumdatenstruktur pflegen hierarchische Beziehungen zwischen ihnen. Der oberste Knoten eines Baumes wird Wurzelknoten genannt und die untersten Knoten werden Blattknoten genannt. Jeder Knoten in einem Baum enthält Zeiger auf benachbarte Knoten. Jeder verfügbare Knoten in einem Baum kann mehr als einen untergeordneten Knoten haben, mit Ausnahme des Blattknotens, während jeder Knoten höchstens einen übergeordneten Knoten haben kann, mit Ausnahme des Wurzelknotens, der der einzige übergeordnete Knoten aller im Baum verfügbaren Knoten ist.
Diese Datenstruktur enthält Elemente, die auf einer bildlichen Darstellung basieren. Jedes einzelne im Diagramm vorhandene Element wird durch einen Scheitelpunkt dargestellt. Elemente in einer Diagrammdatenstruktur sind über Verbindungen, sogenannte Kanten, miteinander verbunden. Der Hauptunterschied zwischen Diagramm und Baum besteht darin, dass die erste Datenstruktur einen Zyklus enthalten kann, während die spätere keinen Zyklus enthalten kann.
Das gesamte Datenstruktur-Framework kann mit Hilfe des folgenden Flussdiagramms zusammengefasst werden:
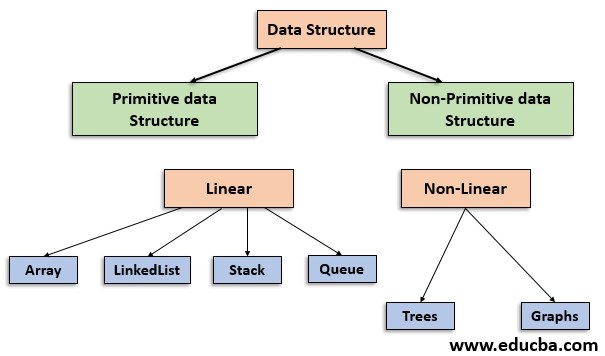
Im Folgenden sind die Hauptvorteile der Verwendung von Datenstrukturen aufgeführt:
Aus dem obigen Artikel haben wir eine klare Einführung in Datenstrukturen in Java. Die Verwendung von Datenstrukturen vereinfacht komplexe Aufgaben in einem System. Außerdem haben wir verschiedene Vorteile der Verwendung von Datenstrukturen gesehen.
Dies ist eine Anleitung zu den Datenstrukturen in Java. Hier diskutieren wir Arten von Datenstrukturen in Java und ihr Framework sowie Vor- und Nachteile. Sie können auch unsere empfohlenen Artikel durchgehen, um mehr zu erfahren –
Das obige ist der detaillierte Inhalt vonDatenstrukturen in Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



