
 Technologie-Peripheriegeräte
KI
Neue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN
Technologie-Peripheriegeräte
KI
Neue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN
Neue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN

Der Schlüssel zum großen Erfolg von Transformer im Bereich Deep Learning ist der Aufmerksamkeitsmechanismus. Der Aufmerksamkeitsmechanismus ermöglicht Transformer-basierten Modellen, sich auf Teile zu konzentrieren, die für die Eingabesequenz relevant sind, und so ein besseres Kontextverständnis zu erreichen. Der Nachteil des Aufmerksamkeitsmechanismus besteht jedoch darin, dass der Rechenaufwand hoch ist, der quadratisch mit der Eingabegröße zunimmt, was es für den Transformer schwierig macht, sehr lange Texte zu verarbeiten.
Vor einiger Zeit hat das Aufkommen von Mamba diese Situation durchbrochen, die mit zunehmender Kontextlänge eine lineare Erweiterung erreichen kann. Mit der Veröffentlichung von Mamba können diese Zustandsraummodelle (SSMs) bereits im kleinen bis mittleren Maßstab mit Transformer mithalten oder diese sogar übertreffen, während gleichzeitig die lineare Skalierbarkeit mit der Sequenzlänge beibehalten wird, was Mamba günstige Bereitstellungseigenschaften verleiht.
Einfach ausgedrückt führt Mamba zunächst einen einfachen, aber effektiven Auswahlmechanismus ein, der SSM entsprechend der Eingabe neu parametrisieren kann, sodass das Modell die erforderlichen Informationen auf unbestimmte Zeit behalten kann, während irrelevante Informationen und zugehörige Daten herausgefiltert werden.
Kürzlich beweist ein Artikel mit dem Titel „The Mamba in the Llama: Distilling and Accelerating Hybrid Models“, dass durch die Wiederverwendung der Gewichte der Aufmerksamkeitsschicht große Transformatoren mit nur minimalem zusätzlichem Rechenaufwand in große hybride lineare RNNs destilliert werden können unter Beibehaltung des größten Teils seiner Verarbeitungsqualität.
Das resultierende Hybridmodell, das ein Viertel der Aufmerksamkeitsebene enthält, erreicht im Chat-Benchmark eine vergleichbare Leistung wie der ursprüngliche Transformer und übertrifft die Daten im Chat-Benchmark und in allgemeinen Benchmarks. Ein Open-Source-Hybrid-Mamba-Modell von Grund auf durch Billionen Token trainiert. Darüber hinaus schlägt die Studie einen hardwarebewussten spekulativen Dekodierungsalgorithmus vor, der die Inferenz für Mamba- und Hybridmodelle beschleunigt.

Papieradresse: https://arxiv.org/pdf/2408.15237
Das leistungsstärkste Modell dieser Studie stammt von Llama3-8B-Instruct Distilled Es erreichte eine längenkontrollierte Gewinnrate von 29,61 bei AlpacaEval 2 im Vergleich zu GPT-4 und eine Gewinnrate von 7,35 bei MT-Bench und übertraf damit das beste anweisungsbereinigte lineare RNN-Modell.
Methoden
Wissensdestillation (KD) ist eine Modellkomprimierungstechnik, mit der Wissen von einem großen Modell (Lehrermodell) auf ein kleineres Modell (Schülermodell) übertragen wird ), deren Ziel es ist, das Schülernetzwerk darin zu trainieren, das Verhalten des Lehrernetzwerks nachzuahmen. Ziel der Forschung ist es, den Transformer so zu destillieren, dass seine Leistung mit dem ursprünglichen Sprachmodell vergleichbar ist.
Diese Studie schlägt eine mehrstufige Destillationsmethode vor, die progressive Destillation, überwachte Feinabstimmung und Richtungspräferenzoptimierung kombiniert. Im Vergleich zur gewöhnlichen Destillation kann diese Methode eine bessere Verwirrung und nachgelagerte Bewertungsergebnisse erzielen.
Die Studie geht davon aus, dass der Großteil des Wissens aus dem Transformer in der vom ursprünglichen Modell übertragenen MLP-Schicht erhalten bleibt, und konzentriert sich auf die Feinabstimmungs- und Ausrichtungsschritte des destillierten LLM. Während dieser Phase bleibt die MLP-Schicht eingefroren und die Mamba-Schicht wird trainiert.
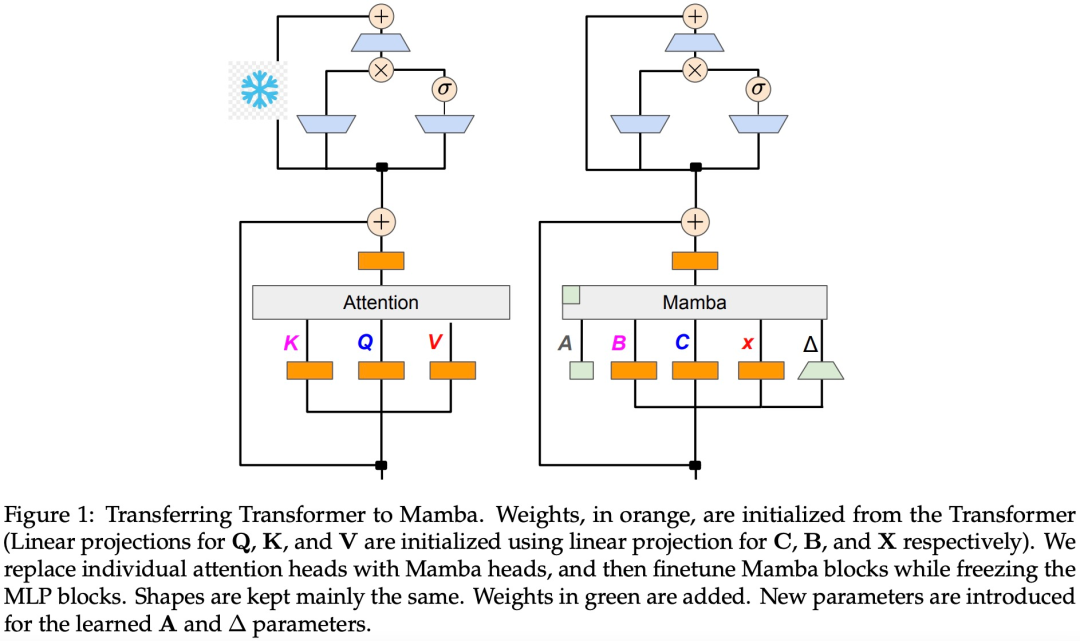
Diese Studie geht davon aus, dass es einige natürliche Zusammenhänge zwischen linearem RNN und Aufmerksamkeitsmechanismus gibt. Die Aufmerksamkeitsformel kann durch Entfernen von Softmax linearisiert werden:
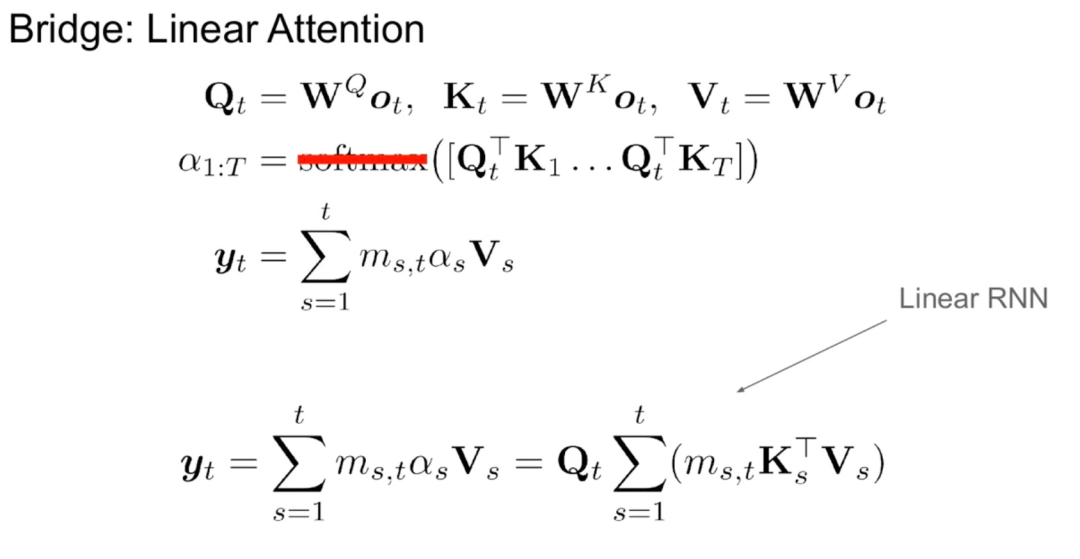
Aber die Linearisierung der Aufmerksamkeit führt zu einer Verschlechterung der Modellfähigkeiten. Um ein effizientes destilliertes lineares RNN zu entwerfen, kommt diese Studie der ursprünglichen Transformer-Parametrisierung so nahe wie möglich und erweitert gleichzeitig die Kapazität des linearen RNN auf effiziente Weise. Diese Studie versucht nicht, das neue Modell die genaue ursprüngliche Aufmerksamkeitsfunktion erfassen zu lassen, sondern verwendet stattdessen eine linearisierte Form als Ausgangspunkt für die Destillation.
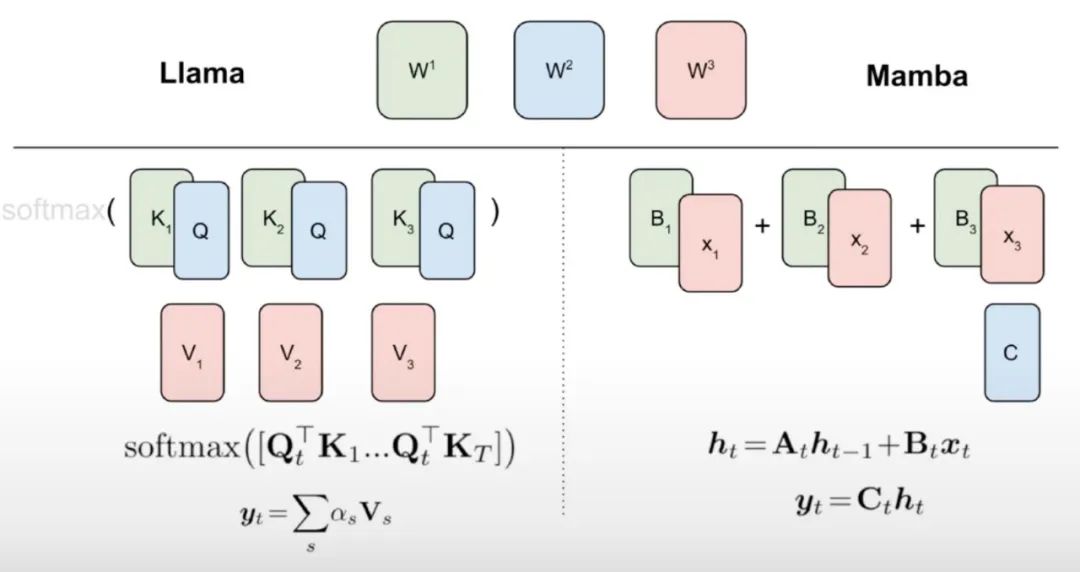
Wie in Algorithmus 1 gezeigt, speist diese Studie die Standard-Q-, K- und V-Köpfe vom Aufmerksamkeitsmechanismus direkt in die Mamba-Diskretisierung ein und wendet dann das resultierende lineare RNN an. Dies kann man sich so vorstellen, dass lineare Aufmerksamkeit für eine grobe Initialisierung verwendet wird und es dem Modell ermöglicht, durch erweiterte verborgene Zustände umfassendere Interaktionen zu lernen.

Diese Studie ersetzt den Transformer-Aufmerksamkeitskopf direkt durch eine fein abgestimmte lineare RNN-Schicht, wobei die Transformer-MLP-Schicht unverändert bleibt und sie nicht trainiert wird. Dieser Ansatz muss auch andere Komponenten verarbeiten, z. B. eine gruppierte Abfrageaufmerksamkeit, die Schlüssel und Werte über mehrere Köpfe hinweg teilt. Das Forschungsteam stellte fest, dass diese Architektur im Gegensatz zu denen, die in vielen Mamba-Systemen verwendet werden, es dieser Initialisierung ermöglicht, alle Aufmerksamkeitsblöcke durch lineare RNN-Blöcke zu ersetzen.
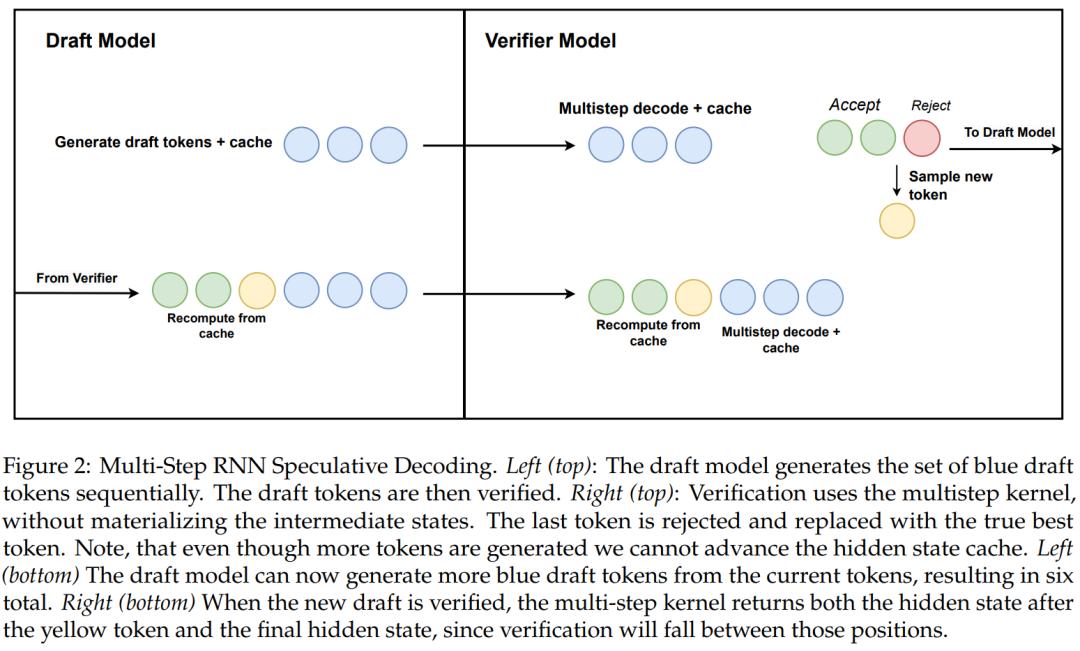
Die Forschung schlägt außerdem einen neuen Algorithmus für die lineare spekulative RNN-Dekodierung unter Verwendung hardwarebewusster mehrstufiger Generierung vor.
Algorithmus 2 und Abbildung 2 zeigen den vollständigen Algorithmus. Dieser Ansatz behält nur einen verborgenen RNN-Zustand zur Überprüfung im Cache und treibt ihn basierend auf dem Erfolg des mehrstufigen Kernels langsam voran. Da das Destillationsmodell Transformatorschichten enthält, erweitert diese Studie die spekulative Dekodierung auch auf eine Attention/RNN-Hybridarchitektur. In diesem Aufbau führt die RNN-Schicht eine Verifizierung gemäß Algorithmus 2 durch, während die Transformer-Schicht nur eine parallele Verifizierung durchführt.

Um die Wirksamkeit dieser Methode zu überprüfen, wurden in der Studie Mamba 7B und Mamba 2.8B als Zielmodelle für Spekulationen verwendet. Die Ergebnisse sind in Tabelle 1 aufgeführt.
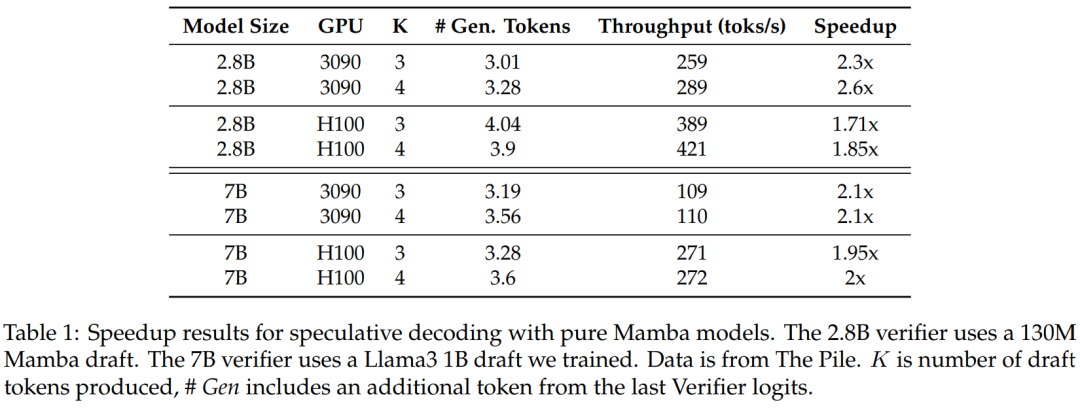
Abbildung 3 zeigt die Leistungsmerkmale des Multi-Step-Kernels selbst.
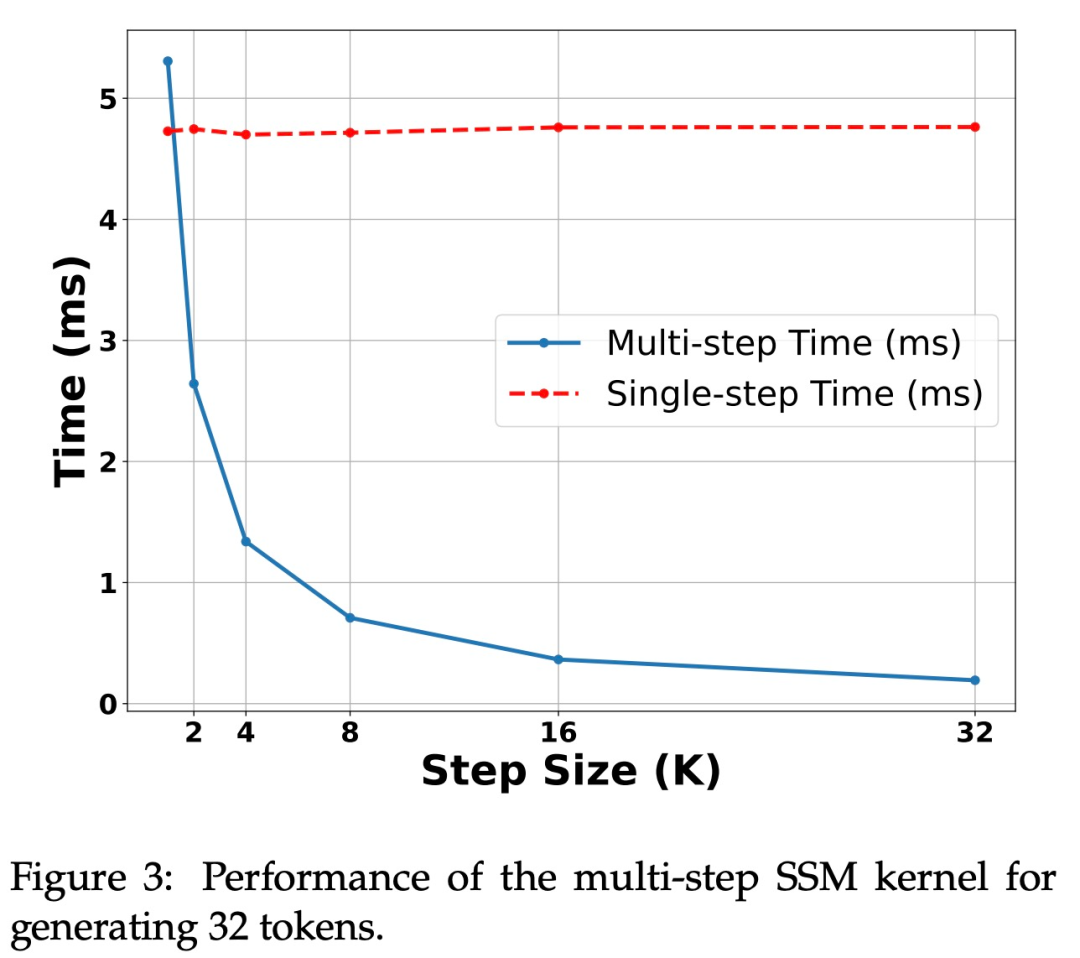
Beschleunigung auf der H100-GPU. Der in dieser Studie vorgeschlagene Algorithmus zeigt eine starke Leistung auf der Ampere-GPU, wie in Tabelle 1 oben gezeigt. Aber es gibt große Herausforderungen für die H100-GPU. Dies liegt hauptsächlich daran, dass GEMM-Operationen zu schnell sind, wodurch der durch Caching- und Neuberechnungsvorgänge verursachte Overhead stärker spürbar wird. Tatsächlich erzielte eine einfache Implementierung des untersuchten Algorithmus (unter Verwendung mehrerer verschiedener Kernel-Aufrufe) eine erhebliche Beschleunigung auf der 3090-GPU, jedoch überhaupt keine Beschleunigung auf der H100.
Experimente und Ergebnisse
Diese Studie verwendet zwei LLM-Chat-Modelle für Experimente: Zephyr-7B basiert auf dem Mistral-7B-Modell und Llama-3 Instruct 8B. Für das lineare RNN-Modell verwendet diese Studie eine Hybridversion von Mamba und Mamba2 mit Aufmerksamkeitsschichten von 50 %, 25 %, 12,5 % bzw. 0 % und nennt 0 % ein reines Mamba-Modell. Mamba2 ist eine Architekturvariante von Mamba, die hauptsächlich für aktuelle GPU-Architekturen entwickelt wurde.
Bewertung beim Chat-Benchmark
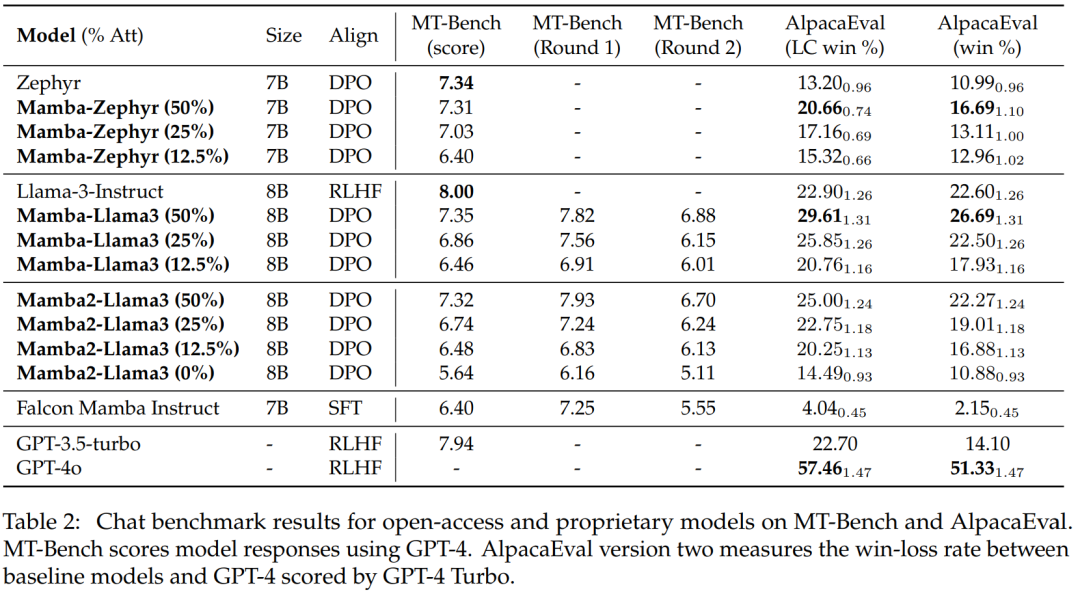
Tabelle 2 zeigt die Leistung des Modells beim Chat-Benchmark. Das wichtigste verglichene Modell ist das große Transformer-Modell. Die Ergebnisse zeigen:
Das destillierte Hybrid-Mamba-Modell (50 %) erzielt ähnliche Ergebnisse wie das Lehrermodell im MT-Benchmark und ist hinsichtlich der LC-Gewinnrate und etwas besser als das Lehrermodell im AlpacaEval-Benchmark Gesamtgewinnquote.
Die Leistung der destillierten Hybrid-Mamba (25 % und 12,5 %) ist etwas schlechter als die des Lehrermodells im MT-Benchmark, aber selbst mit mehr Parametern in AlpcaaEval übertrifft sie immer noch einige große Transformer.
Die Genauigkeit des destillierten reinen (0 %) Mamba-Modells nimmt erheblich ab.
Es ist erwähnenswert, dass das destillierte Hybridmodell eine bessere Leistung erbringt als Falcon Mamba, das von Grund auf mit mehr als 5T-Tokens trainiert wird.
Allgemeine Benchmark-Auswertung
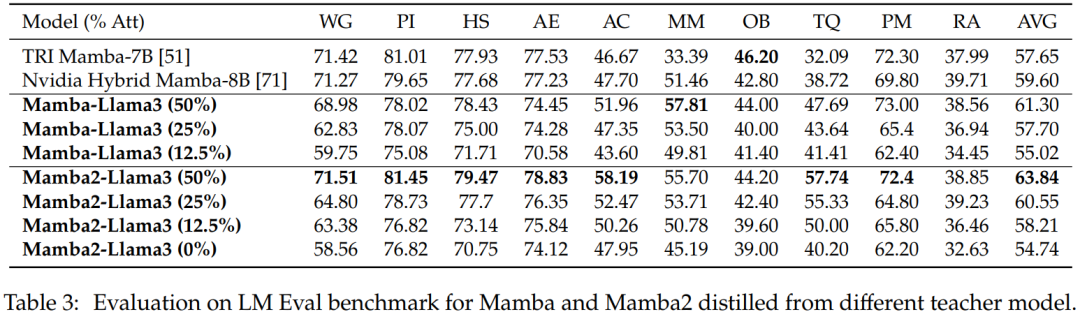
Nullstichprobenauswertung. Tabelle 3 zeigt die Zero-Shot-Leistung von Mamba und Mamba2, destilliert aus verschiedenen Lehrermodellen beim LM Eval-Benchmark. Die aus Llama-3 Instruct 8B destillierten Hybridmodelle Mamba-Llama3 und Mamba2-Llama3 schnitten im Vergleich zu den von Grund auf trainierten Open-Source-Modellen TRI Mamba und Nvidia Mamba besser ab.
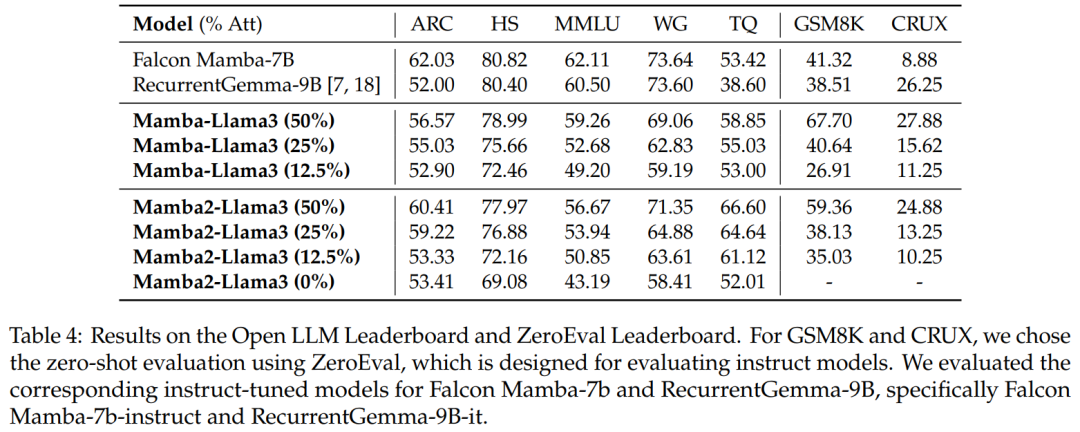
Benchmark-Bewertung. Tabelle 4 zeigt, dass die Leistung des destillierten Hybridmodells mit dem besten linearen Open-Source-RNN-Modell im Open LLM Leaderboard übereinstimmt und gleichzeitig das entsprechende Open-Source-Anweisungsmodell in GSM8K und CRUX übertrifft.
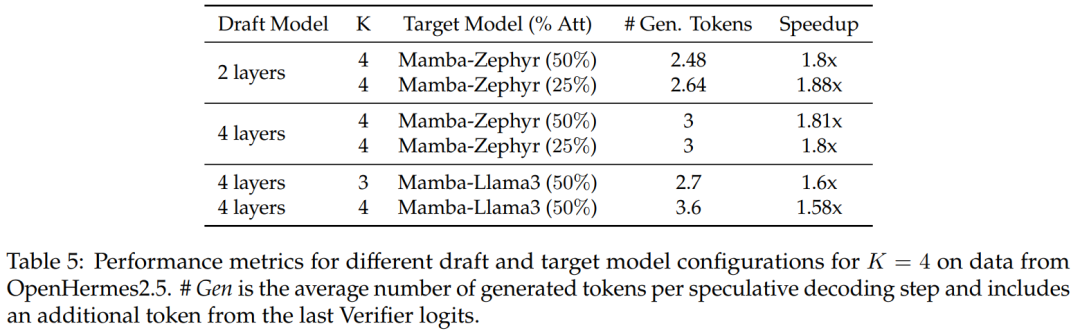
Hybride spekulative Dekodierung
Für die 50 %- und 25 %-Destillationsmodelle im Vergleich zur nicht spekulativen Basislinie, diese Studie Über 1,8-fache Beschleunigung auf Zephyr-Hybrid erreicht.
Experimente zeigen auch, dass das in dieser Studie trainierte 4-Schicht-Entwurfsmodell eine höhere Empfangsrate erreicht, aber aufgrund der Vergrößerung des Entwurfsmodells auch der zusätzliche Overhead größer wird. In der nachfolgenden Arbeit wird sich diese Forschung auf die Verkleinerung dieser Entwurfsmodelle konzentrieren.
Vergleich mit anderen Destillationsmethoden: Tabelle 6 (links) vergleicht die Ratlosigkeit verschiedener Modellvarianten. Die Studie führte eine Destillation innerhalb einer Epoche mit Ultrachat als Samenaufforderung durch und verglich die Verwirrung. Es stellt sich heraus, dass das Entfernen weiterer Schichten die Situation verschlimmert. Die Studie verglich die Destillationsmethode auch mit früheren Basislinien und stellte fest, dass die neue Methode einen geringeren Abbau aufwies, während das Distill Hyena-Modell anhand des WikiText-Datensatzes unter Verwendung eines viel kleineren Modells trainiert wurde und einen größeren Verwirrungsgrad des Abbaus aufwies.
Tabelle 6 (rechts) zeigt, dass die alleinige Verwendung von SFT oder DPO keine große Verbesserung bringt, während die Verwendung von SFT + DPO die beste Punktzahl liefert.
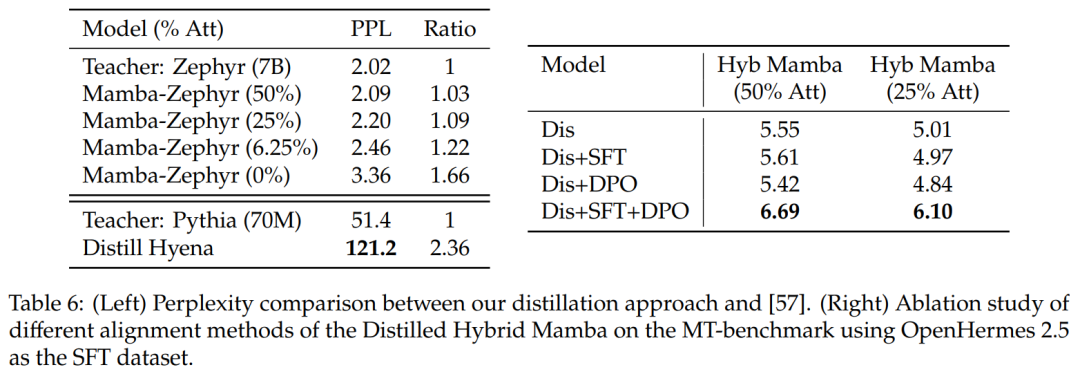
Tabelle 7 vergleicht Ablationsstudien für verschiedene Modelle. Tabelle 7 (links) zeigt die Destillationsergebnisse bei verschiedenen Initialisierungen und Tabelle 7 (rechts) zeigt die kleineren Gewinne durch progressive Destillation und verschachtelte Aufmerksamkeitsschichten mit Mamba.
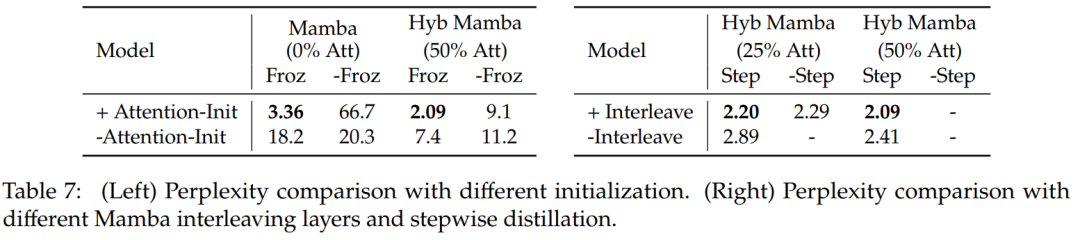
Tabelle 8 vergleicht die Leistung von Hybridmodellen mit zwei verschiedenen Initialisierungsmethoden: Die Ergebnisse bestätigen, dass die Initialisierung von Aufmerksamkeitsgewichten entscheidend ist.

Tabelle 9 vergleicht die Leistung von Modellen mit und ohne Mamba-Blöcke. Modelle mit Mamba-Blöcken schneiden deutlich besser ab als Modelle ohne Mamba-Blöcke. Dies bestätigt, dass das Hinzufügen der Mamba-Schicht von entscheidender Bedeutung ist und dass die Leistungsverbesserung nicht ausschließlich auf den verbleibenden Aufmerksamkeitsmechanismus zurückzuführen ist.

Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonNeue Arbeit vom Autor von Mamba: Distilling Llama3 in ein hybrides lineares RNN. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 Das erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source
Jul 17, 2024 am 02:46 AM
Das erste Mamba-basierte MLLM ist da! Modellgewichte, Trainingscode usw. waren alle Open Source
Jul 17, 2024 am 02:46 AM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Einleitung In den letzten Jahren hat die Anwendung multimodaler großer Sprachmodelle (MLLM) in verschiedenen Bereichen bemerkenswerte Erfolge erzielt. Als Grundmodell für viele nachgelagerte Aufgaben besteht aktuelles MLLM jedoch aus dem bekannten Transformer-Netzwerk, das
