Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Unit-Tests sind ein wichtiges Glied im Softwareentwicklungsprozess und werden hauptsächlich verwendet Stellen Sie sicher, dass die kleinste testbare Einheit, Funktion oder das kleinste testbare Modul in der Software wie erwartet funktioniert. Das Ziel des Unit-Tests besteht darin, sicherzustellen, dass jedes unabhängige Codefragment seine Funktion korrekt ausführen kann, was für die Verbesserung der Softwarequalität und Entwicklungseffizienz von großer Bedeutung ist. Große Modelle allein sind jedoch nicht in der Lage, Testbeispielsätze mit hoher Abdeckung für komplexe zu testende Funktionen zu generieren (Zyklokomplexität größer als 10). Um dieses Problem zu lösen, schlug das Team von Professor Li Ge von der Universität Peking eine neue Methode zur Verbesserung der Testfallabdeckung vor. Diese Methode verwendet Programm-Slicing (Methoden-Slicing), um komplexe zu testende Funktionen basierend auf der Semantik in mehrere einfache Fragmente zu zerlegen Das große Modell generiert Testfälle für jedes einfache Fragment separat. Bei der Generierung eines einzelnen Testfalls muss das große Modell nur ein Fragment der zu testenden Originalfunktion analysieren, wodurch die Schwierigkeit der Analyse und die Generierung von Komponententests, die dieses Fragment abdecken, verringert werden. Diese Aktion kann die Codeabdeckung des gesamten Testbeispielsatzes verbessern. Das zugehörige Papier „HITS: High-coverage LLM-based Unit Test Generation via Method Slicing“ wurde kürzlich von ASE 2024 (auf der 39. IEEE/ACM International Conference am) veröffentlicht Automatisiertes Software Engineering) wird angenommen. 
Papieradresse: https://www.arxiv.org/pdf/2408.11324Schauen Sie sich als nächstes an Inhalt der Papierrecherche des Peking-Universitätsteams: HITS verwendet große Modelle für Programm-ShardingProgramm-Sharding bezeichnet die semantische Aufteilung eines Programms in mehrere Problemlösungsphasen. Ein Programm ist ein formaler Ausdruck einer Lösung eines Problems. Eine Problemlösung besteht normalerweise aus mehreren Schritten, wobei jeder Schritt einem Codeausschnitt im Programm entspricht. Wie in der folgenden Abbildung dargestellt, entspricht ein Farbblock einem Codeabschnitt und einem Schritt zur Lösung des Problems. 
HITS erfordert, dass das große Modell Unit-Test-Code für jeden Codeabschnitt entwirft, der ihn effizient abdecken kann. Nehmen wir die obige Abbildung als Beispiel: Wenn wir die in der Abbildung gezeigten Slices erhalten, erfordert HITS, dass das große Modell Testproben für Slice 1 (grün), Slice 2 (blau) bzw. Slice 3 (rot) generiert. Die für Slice 1 generierten Testbeispiele sollten Slice 1 so weit wie möglich abdecken, unabhängig von Slice 2 und Slice 3. Das Gleiche gilt für andere Codeteile. HITS funktioniert aus zwei Gründen. Erstens sollten große Modelle darüber nachdenken, die Menge des abgedeckten Codes zu reduzieren. Am Beispiel der obigen Abbildung müssen beim Generieren von Testproben für Slice 3 nur die bedingten Zweige in Slice 3 berücksichtigt werden. Um einige bedingte Zweige in Slice 3 abzudecken, müssen Sie nur einen Ausführungspfad in Slice 1 und Slice 2 finden, ohne die Auswirkungen dieses Ausführungspfads auf die Abdeckung von Slice 1 und Slice 2 zu berücksichtigen. Zweitens helfen Codeteile, die auf der Grundlage der Semantik (Problemlösungsschritte) segmentiert sind, großen Modellen dabei, die Zwischenzustände der Codeausführung zu erfassen. Beim Generieren von Testfällen für spätere Codeblöcke müssen Änderungen am Programmstatus berücksichtigt werden, die durch vorherigen Code verursacht wurden. Da Codeblöcke nach tatsächlichen Problemlösungsschritten segmentiert sind, können die Operationen vorheriger Codeblöcke in natürlicher Sprache beschrieben werden (wie in der Anmerkung in der Abbildung oben gezeigt). Da die meisten aktuellen großen Sprachmodelle das Produkt eines gemischten Trainings zwischen natürlicher Sprache und Programmiersprache sind, kann eine gute Zusammenfassung natürlicher Sprache großen Modellen dabei helfen, durch Code verursachte Änderungen im Programmstatus genauer zu erfassen. HITS verwendet große Modelle für das Programm-Sharding. Die Problemlösungsschritte werden normalerweise in natürlicher Sprache mit der subjektiven Farbe des Programmierers ausgedrückt, sodass große Modelle mit überlegenen Fähigkeiten zur Verarbeitung natürlicher Sprache direkt verwendet werden können. Insbesondere nutzt HITS das Lernen im Kontext, um große Modelle aufzurufen. Das Team nutzte seine bisherigen praktischen Erfahrungen in realen Szenarien, um mehrere Programm-Sharding-Beispiele manuell zu schreiben. Nach mehreren Anpassungen entsprach die Wirkung des großen Modells auf das Programm-Sharding den Erwartungen des Forschungsteams. Testbeispiele für Codeausschnitte generierenAngesichts des abzudeckenden Codeausschnitts, Um entsprechende Testproben zu generieren, müssen Sie die folgenden drei Schritte ausführen: 1. Analysieren Sie die Eingabe des Fragments. 2. Erstellen Sie eine Eingabeaufforderung, um das große Modell anzuweisen, eine erste Testprobe zu generieren Selbst-Debug-Anpassung für große Modelle Testen Sie das Beispiel, damit es ordnungsgemäß ausgeführt wird. Analysieren Sie die Eingabe des Fragments, was bedeutet, dass alle externen Eingaben, die vom Fragment akzeptiert werden, für die spätere sofortige Verwendung extrahiert werden. Externe Eingabe bezieht sich auf lokale Variablen, die durch vorherige Fragmente definiert wurden, auf die dieses Fragment angewendet wird, formale Parameter der zu testenden Methode, innerhalb des Fragments aufgerufene Methoden und externe Variablen. Der Wert externer Eingaben bestimmt direkt die Ausführung des abzudeckenden Fragments. Das Extrahieren dieser Informationen zur Eingabe des großen Modells hilft daher dabei, Testfälle gezielt zu entwerfen. Das Forschungsteam stellte in Experimenten fest, dass große Modelle eine gute Fähigkeit haben, externe Eingaben zu extrahieren, daher werden große Modelle verwendet, um diese Aufgabe in HITS zu erfüllen. Als nächstes erstellt HITS eine Gedankenkettenaufforderung, um das große Modell bei der Generierung von Testproben anzuleiten. Die Argumentationsschritte sind wie folgt. Der erste Schritt besteht darin, die externen Eingaben anzugeben und die Permutationen und Kombinationen der verschiedenen bedingten Zweige im abzudeckenden Codeteil zu analysieren. Welche Eigenschaften müssen die externen Eingaben erfüllen? Beispiel: Kombination 1, Zeichenfolge a muss enthalten Zeichen 'x', die Ganzzahlvariable i muss nicht negativ sein; in Kombination 2 muss die Zeichenfolge a nicht leer sein und die Ganzzahlvariable i muss eine Primzahl sein. Analysieren Sie im zweiten Schritt für jede Kombination im vorherigen Schritt die Art der Umgebung, in der der entsprechende zu testende Code ausgeführt wird, einschließlich, aber nicht beschränkt auf die Eigenschaften tatsächlicher Parameter und die Einstellungen globaler Variablen. Der dritte Schritt besteht darin, für jede Kombination ein Testmuster zu erstellen. Das Forschungsteam erstellte für jeden Schritt handgearbeitete Beispiele, damit das große Modell die Anweisungen richtig verstehen und ausführen konnte. Schließlich ermöglicht HITS die korrekte Ausführung von Testbeispielen, die von großen Modellen generiert wurden, durch Nachbearbeitung und Selbst-Debugging. Von großen Modellen generierte Testbeispiele sind oft schwer direkt zu verwenden, und es kommt zu verschiedenen Kompilierungsfehlern und Laufzeitfehlern, die durch falsch geschriebene Testbeispiele verursacht werden. Das Forschungsteam entwarf mehrere Regeln und Fälle zur Behebung häufiger Fehler auf der Grundlage eigener Beobachtungen und Zusammenfassungen bestehender Arbeiten. Versuchen Sie zunächst, das Problem gemäß den Regeln zu beheben. Wenn die Regel nicht repariert werden kann, verwenden Sie die Selbst-Debug-Funktion des großen Modells, um sie zu reparieren. In der Eingabeaufforderung für die Referenz des großen Modells werden Reparaturfälle für häufige Fehler angezeigt. 
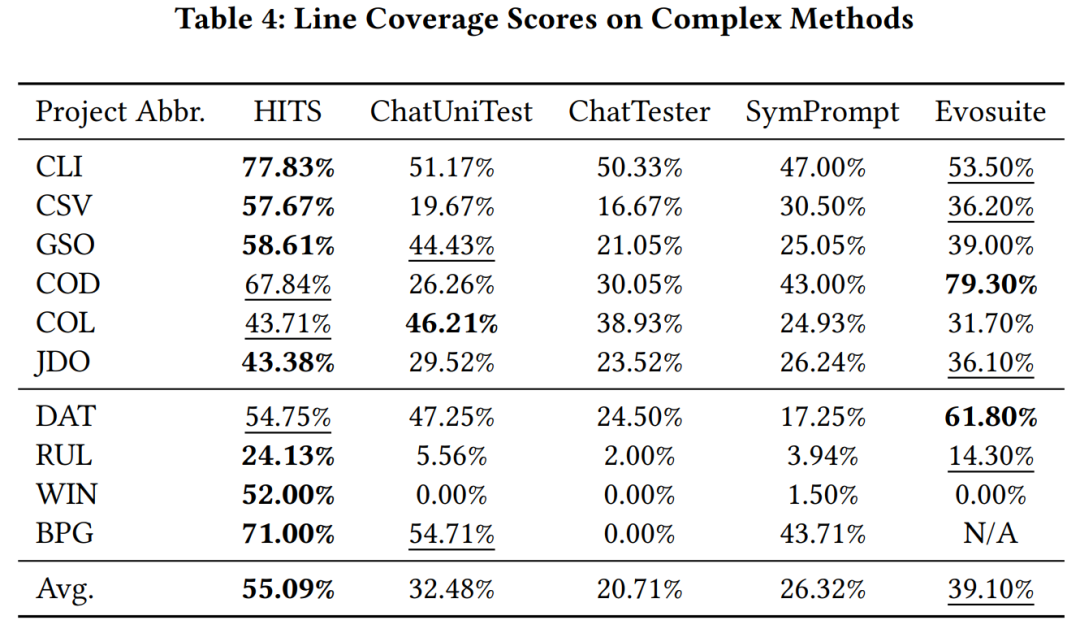
研究團隊使用gpt-3.5-turbo 作為HITS 呼叫的大模型,分別在大模型學習過和未學習過的Java 專案中的複雜函數(環複雜度大於10)上對比HITS,其他基於大模型的單元測試方法和evosuite 的程式碼覆蓋率。實驗結果顯示 HITS 相較於被比較的諸方法有較明顯的效能提升。
🎜>
團隊透過範例分析展示分片方法如何提升程式碼覆蓋率。如圖所示。 
此案例中,基線方法產生的測試範例未能完全覆蓋 Slice 2 中的紅色程式碼片段。然而,HITS 由於聚焦於Slice 2,對其所引用的外部變量進行了分析,捕捉到“如果要覆蓋紅色代碼片段,變量'arguments' 需要非空“的性質,根據該性質構建了測試樣例,成功實現了對紅色區域代碼的覆蓋。 提升單元測試覆蓋率,增強系統的可靠性和穩定性,進而提高軟體品質。 HITS使用程式分片實驗證明,該技術不僅能大幅提升整體測試樣本程式碼覆蓋率,且實施方法簡潔直接,未來有望在真實場景實踐中,幫助團隊更早發現並修正開發中的錯誤,提升軟體交付品質。 Das obige ist der detaillierte Inhalt vonDas Li Ge-Team der Universität Peking schlug eine neue Methode zur Generierung einzelner Tests für große Modelle vor, wodurch die Code-Testabdeckung erheblich verbessert wurde.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



