

Ein Softwareentwicklungsteam zu leiten ist keine leichte Aufgabe. Bis das Projekt zur Ziellinie gelangt, kann ein technischer Projektmanager keine Verschnaufpause einlegen. Aus diesem Grund suchen Software-Engineering-Manager nach Möglichkeiten, die Leistung ihrer Projekte und ihrer Teams zu verbessern. Und genau hier kommen Dinge wie Kpi in Gottes Verkleidung ins Spiel.
KPIs sind wie der Fitness-Tracker Ihres Teams – sie helfen Ihnen zu sehen, wo die Dinge reibungslos funktionieren und wo Sie möglicherweise die Schrauben anziehen müssen. Aber welche sollten Ihnen bei den unzähligen KPIs überhaupt am Herzen liegen? Lassen Sie uns die Top 15 aufschlüsseln, die Sie wie einen Rockstar-Software-Teammanager aussehen lassen, und einige, die Sie vielleicht aufgeben sollten.
KPIs sind mehr als nur Zahlen auf einem Bildschirm – sie sind Ihr Fahrplan für eine bessere Entscheidungsfindung. Durch die Verfolgung der richtigen Kennzahlen können Sie erkennen, wo Ihr Team hervorragende Leistungen erbringt und wo Verbesserungspotenzial besteht. Es ist wie eine Kristallkugel, die Ihnen hilft, Projektzeitpläne, Ressourcenbedarf und potenzielle Hindernisse vorherzusagen.
Stellen Sie sich vor, Sie nehmen an einem Rennen teil, aber anstatt dass Autos über eine Strecke rasen, rast Ihr Team darum, Aufgaben in einem Sprint zu erledigen.
Die Frage ist: Wie schnell können sie von der Startlinie („to-do“) zur Ziellinie („done“) gelangen?
Hier kommt die Zykluszeit ins Spiel – sie ist die Stoppuhr, die Ihnen sagt, wie schnell Ihr Team Aufgaben erledigt.

Bei der Zykluszeit dreht sich alles um Geschwindigkeit, aber es geht nicht nur darum, schnell zu fahren.
Es geht um Effizienz und darum, zu wissen, wo es zu Verzögerungen kommt. Im Durchschnitt haben leistungsstarke Teams eine Zykluszeit von etwa 1,8 bis 3,4 Tagen pro Aufgabe.
Wenn es länger dauert, ist es vielleicht an der Zeit, unter die Haube zu schauen und herauszufinden, was die Verzögerung verursacht – vielleicht ist es ein Prozessengpass, zu viel Multitasking oder einfach nur alte technische Schulden.
Angenommen, Ihr Team arbeitet an einer neuen Funktion für eine mobile App. Die Aufgabe wird am Montagmorgen vom Rückstand auf „In Bearbeitung“ verschoben. Ihr Entwicklerteam beginnt mit dem Codieren, Testen und Pushen von Commits, und am Mittwochnachmittag ist die Aufgabe abgeschlossen und als „erledigt“ markiert. Das entspricht einer Zykluszeit von 3 Tagen.
Nehmen wir an, dass eine andere Aufgabe ins Stocken gerät – vielleicht dauert die Codeüberprüfung ewig, oder es gibt eine Abhängigkeit, die die Dinge aufhält. Wenn sich diese Aufgabe über 7 oder 10 Tage hinzieht, ist das ein Zeichen dafür, dass etwas nicht ganz stimmt.
Hier geschieht die Magie: Indem Sie die Zykluszeit verfolgen, können Sie Muster erkennen.

Vielleicht ist Ihr Team bei manchen Aufgaben superschnell, bei anderen aber steckengeblieben. Mit diesem Einblick können Sie in die Einzelheiten eintauchen und herausfinden, wie Sie den Prozess optimieren können. Vielleicht ist es so einfach, den Codeüberprüfungsprozess zu optimieren oder Aufgaben anders zu priorisieren.
Das Ziel? Um die Zykluszeit zu verkürzen, damit Ihr Team Aufgaben konsequent wie ein Profi erledigt.
Und wenn das passiert, handeln Sie nicht nur schnell, sondern auch intelligent.

Wenn es um Code geht, geht es nicht darum, Unmengen davon zu schreiben – es geht darum, sicherzustellen, dass das, was Sie schreiben, tatsächlich funktioniert. Hier kommt die Codeabdeckung ins Spiel.
Stellen Sie sich Code Coverage als die Gesundheitsprüfung Ihres Codes vor.

Hier erfahren Sie, wie viel von Ihrer Codebasis getestet wird, sodass Sie wissen, dass Sie diese heimtückischen Fehler erkennen, bevor sie zu einem Problem werden.
In der Welt der Softwareentwicklung liegt ein guter Maßstab für die Codeabdeckung bei etwa 70–80 %. Wenn du das erreichst, geht es dir ziemlich gut.
Denken Sie jedoch daran, dass Perfektion hier nicht das Ziel ist – eine 100-prozentige Abdeckung ist, als würde man versuchen, jedes Sandkorn am Strand aufzufangen.

Konzentrieren Sie sich stattdessen darauf, sicherzustellen, dass die kritischen Teile Ihres Codes abgedeckt sind.
Stellen Sie sich vor, Sie erstellen eine neue Funktion für eine E-Commerce-Website – sagen wir, es ist ein Warenkorb.

Sie haben Code geschrieben, der Artikel zum Warenkorb hinzufügt, Gesamtbeträge berechnet und Zahlungen verarbeitet. Jetzt möchten Sie sicherstellen, dass dies alles funktioniert, bevor Kunden damit beginnen.
Sie schreiben Tests für jeden Teil:
Artikel zum Warenkorb hinzufügen – Sie testen, ob die Artikel korrekt hinzugefügt wurden.
Berechnung von Gesamtsummen – Sie überprüfen, ob die Rechnung richtig ist, wenn jemand mehrere Elemente hinzufügt.
Zahlungsabwicklung – Sie testen das Zahlungsgateway, um sicherzustellen, dass Transaktionen reibungslos ablaufen.
Wenn Ihre Tests alle diese Szenarien abdecken und fehlerfrei laufen, verfügen Sie über eine solide Codeabdeckung. Wenn Sie jedoch das Testen des Zahlungsvorgangs überspringen (vielleicht weil er komplex ist oder mehr Zeit in Anspruch nimmt), lassen Sie einen wichtigen Teil Ihres Codes ungetestet – das ist so, als würden Sie Ihre Tür nachts unverschlossen lassen.
Indem Sie die Codeabdeckung im Auge behalten, stellen Sie sicher, dass der Großteil Ihres Codes getestet wird, wodurch die Wahrscheinlichkeit verringert wird, dass sich Fehler in die Produktion einschleichen. Es geht darum, Probleme frühzeitig zu erkennen, damit sie später nicht zu Kundenbeschwerden werden.

Stellen Sie sich Folgendes vor: Ihr Entwicklerteam schreibt immer wieder dieselben Codeabschnitte neu. Anstatt dem Fortschritt entgegenzusprinten, stecken sie in einem Hamsterrad fest und drehen sich im Kreis, ohne wirklich vorwärts zu kommen. Das ist Codeüberarbeitung in Aktion und ein Zeichen dafür, dass etwas nicht stimmt.
Idealerweise sollte Ihr Team mehr Zeit damit verbringen, neue Funktionen zu entwickeln und weniger Zeit damit, bereits Erledigtes zu wiederholen. Zu viel Code-Überarbeitung kann ein Produktivitätskiller sein.
Tatsächlich zeigen Studien, dass häufige Nacharbeiten bis zu 40 % der Zeit eines Entwicklers in Anspruch nehmen können – Zeit, die besser für Innovationen genutzt werden könnte.

Stellen Sie sich die Change Failure Rate (CFR) als den „Bug-o-Meter“ Ihres Entwicklerteams vor. Es misst, wie oft Ihre Codeänderungen letztendlich zu Problemen führen. Ein hoher CFR ist wie ein undichtes Boot – Sie schöpfen ständig Wasser ab (beheben Fehler), anstatt reibungslos zu fahren (coole neue Funktionen zu entwickeln).
In einer idealen Welt würde jede Änderung, die Sie an der Codebasis vornehmen, einwandfrei funktionieren. Aber in Wirklichkeit gehen die Dinge kaputt. Laut dem Accelerate State of DevOps Report liegt der Branchendurchschnitt für CFR bei etwa 16–30 %, was bedeutet, dass von 10 Änderungen 1 bis 3 zu Problemen führen können. Wenn Ihr CFR diesen Wert überschreitet, ist das ein Zeichen dafür, dass Ihr Code mehr Pflege benötigt, bevor er in Produktion geht.

Angenommen, Ihr Team führt eine neue Funktion ein und sofort beginnen Benutzer, Abstürze zu melden. Sie untersuchen die Daten und stellen fest, dass 40 % Ihrer letzten Bereitstellungen zu Problemen führten. Autsch! Dieser hohe CFR bedeutet, dass Ihr Team mehr Zeit mit der Beseitigung von Fehlern und weniger Zeit mit Innovationen verbringen wird.
Das Ziel? Senken Sie Ihre CFR, indem Sie Tests und Codeüberprüfungen verbessern, sodass Sie mehr Zeit mit der Entwicklung des nächsten großen Projekts verbringen können und weniger Zeit damit verbringen müssen, bereits Ausgeliefertes zu reparieren.

Defect Detection Ratio (DDR) ist wie Ihre Fehlererkennungs-Scorecard – sie sagt Ihnen, wie viele Fehler Sie erkennen, bevor der Code ins Freie gelangt, und wie viele nach dem Start durchschlüpfen. Je höher Ihr DDR, desto besser ist Ihr Testspiel. Wenn sich jedoch weitere Fehler an Ihnen vorbeischleichen und in der Produktion auftauchen, ist es an der Zeit, Ihre Testtools zu schärfen.
Ein gutes DDR zeigt, dass Ihr Testprozess solide ist und in der Regel darauf abzielt, dass 85 % oder mehr der Fehler vor der Veröffentlichung erkannt werden. Wenn Ihr DDR-Wert niedrig ist, ist es, als würden Sie eine Reihe von Warnsignalen übersehen, nur um es später herauszufinden, wenn Benutzer anfangen, sich zu beschweren.
Stellen Sie sich vor, Sie veröffentlichen ein neues App-Update. Beim Testen fallen Ihnen 8 Fehler auf, aber nach dem Start melden Benutzer weitere 5. Das ergibt einen DDR von 8/13, also etwa 62 %. Nicht großartig. Das bedeutet, dass bei Ihren Tests fast 40 % der Fehler übersehen wurden, was ein klares Zeichen dafür ist, dass es an der Zeit ist, Ihre Prüfungen vor der Veröffentlichung zu verstärken.
Um Ihren DDR zu steigern, sollten Sie erwägen, automatisierte Tests zu verbessern, gründlichere Codeüberprüfungen durchzuführen oder sogar mehr Benutzerakzeptanztests vor der großen Einführung durchzuführen. Je besser Ihr DDR, desto zufriedener sind Ihre Benutzer – und desto weniger „Oh-oh“-Momente nach dem Start!

Die Fehlerrate misst, wie häufig diese lästigen Fehler in Ihrem Code auftauchen. Eine hohe Fehlerrate kann ein großes Warnsignal sein und darauf hinweisen, dass der Code entweder überstürzt oder von jemandem geschrieben wird, der sich noch mit den Grundlagen vertraut macht. Branchendaten deuten darauf hin, dass erfahrene Teams in der Regel weniger als 10 Fehler pro 1.000 Codezeilen anstreben.
Ihr Team führt eine neue Funktion ein und innerhalb weniger Stunden werden 15 Fehler gemeldet. Wenn Sie so etwas regelmäßig sehen, ist das ein Zeichen dafür, dass Codeüberprüfungen oder -tests mehr Aufmerksamkeit erfordern – oder dass Ihre Entwickler möglicherweise mehr Zeit benötigen, um es richtig zu machen.
Bei MTTR geht es darum, wie schnell Ihr Team nach einem Systemabsturz wieder auf die Beine kommen kann.

Es ist Ihre Stoppuhr für die Notfallwiederherstellung, die zeigt, wie schnell Sie aus einem Schlamassel wieder auf die Beine kommen. Idealerweise möchten Sie eine niedrige MTTR – denken Sie an Minuten, nicht an Stunden.
Ihre Website stürzt um 14:00 Uhr ab und Ihr Team hat sie um 14:15 Uhr wieder online. Das ist eine MTTR von 15 Minuten. Wenn Ihr Team normalerweise eine Stunde braucht, um sich zu erholen, ist es vielleicht an der Zeit, Ihren Incident-Response-Plan zu verfeinern.

Velocity misst, wie viel Arbeit Ihr Team während eines Sprints erledigt. Es ist Ihr Produktivitätsmaßstab, aber vergessen Sie nicht: Es ist nicht immer ein Gleichstand zwischen verschiedenen Teams. Wichtig ist, zu verfolgen, wie sich Ihre Geschwindigkeit im Laufe der Zeit verändert, und nicht nur Zahlen zu vergleichen.
Im letzten Sprint hat Ihr Team 50 Story Points abgeschlossen. Bei diesem Sprint erreichten sie Platz 55. Eine höhere Geschwindigkeit könnte bedeuten, dass Ihr Team in Schwung kommt – oder es könnte bedeuten, dass es einfachere Aufgaben übernommen hat. Achten Sie hier auf die Konsistenz.
Der kumulative Fluss zeigt Ihnen, wo sich Aufgaben in Ihrem Workflow häufen.

Betrachten Sie es als einen Verkehrsbericht für Ihr Projekt – wenn Aufgaben zu lange in einer Phase stecken bleiben, liegt ein Engpass vor.
Sie bemerken, dass eine Reihe von Aufgaben in der „Codeüberprüfung“ verweilen, während andere reibungslos ablaufen. Das könnte bedeuten, dass Sie mehr Gutachter oder besser definierte Kriterien benötigen, um die Dinge voranzutreiben.

Bereitstellungshäufigkeit verfolgt, wie oft Ihr Team Code in die Produktion überträgt. Häufigere Bereitstellungen bedeuten im Allgemeinen, dass Ihr Team agil und anpassungsfähig ist – stellen Sie jedoch sicher, dass Sie nicht die Qualität zugunsten der Geschwindigkeit opfern.
Ihr Team stellt Updates zweimal pro Woche bereit. Das ist gut, wenn diese Updates solide sind, aber wenn jede Bereitstellung zu Fehlern führt, ist es möglicherweise an der Zeit, einen Rückzieher zu machen und sich auf die Qualität zu konzentrieren.

Die Warteschlangenzeit misst, wie lange Aufgaben in einem Wartezustand verweilen, beispielsweise wenn sie im „To-do“-Stapel stecken bleiben. Lange Wartezeiten können auf Ineffizienzen in Ihrem Prozess hinweisen, z. B. wenn zu wenige Teammitglieder zu viele Aufgaben erledigen.
Wenn Aufgaben tagelang auf die QA-Genehmigung warten, ist das ein Zeichen dafür, dass entweder das QA-Team Hilfe benötigt oder die Kriterien für die Weiterentwicklung von Aufgaben optimiert werden müssen.

Die Scope Completion Rate gibt Ihnen Auskunft darüber, wie viel von der von Ihrem Team geplanten Arbeit tatsächlich erledigt wird. Wenn Ihr Team regelmäßig Aufgaben unvollendet lässt, kann das bedeuten, dass es mehr abbekommt, als es ertragen kann.
Votre équipe avait prévu d'accomplir 20 tâches ce sprint, mais n'en a terminé que 15. Un faible taux d'achèvement comme celui-ci peut indiquer que votre équipe doit se fixer des objectifs plus réalistes ou mieux gérer son temps.

Portée ajoutée : suit la fréquence à laquelle de nouvelles tâches sont ajoutées après le démarrage d'un sprint. Un taux élevé ici peut être le signe d'une mauvaise planification ou, pire encore, d'une dérive de la portée --- lorsque les objectifs de votre projet continuent de s'étendre sans ajuster les délais ou les ressources.
Vous démarrez un sprint avec 10 tâches, mais à la fin, vous en avez ajouté 5 de plus. Cela représente une augmentation de 50 % de la portée, ce qui peut signifier que votre équipe n'évalue pas suffisamment le travail lors de la planification.
Le délai d'exécution mesure le temps total écoulé entre la création d'une tâche et son achèvement. C'est comme le parcours complet de l'idée à l'exécution. Un délai de livraison plus court signifie généralement que votre équipe est efficace, tandis qu'un délai plus long peut signaler des retards ou des goulots d'étranglement dans votre processus.
Une demande de fonctionnalité arrive et il faut deux semaines pour passer du concept au déploiement. Si des tâches similaires prenaient auparavant une semaine, il est temps d'enquêter sur ce qui ralentit les choses --il y a peut-être des retards d'approbation ou trop de transferts entre les équipes.
Lisez également : Délai de mise en œuvre des modifications : une analyse approfondie des métriques DORA et de leur impact sur la livraison de logiciels

Churn Rate suit la fréquence à laquelle votre code est réécrit ou modifié de manière significative peu de temps après son écriture. Un taux de désabonnement élevé peut être le signe que votre approche initiale n'était pas tout à fait correcte ou que les exigences changent trop.
Votre équipe écrit une fonctionnalité, et en une semaine, elle doit en réécrire la moitié car la mise en œuvre initiale n'a pas répondu aux besoins. Si cela continue, c'est le signe qu'il faut consacrer plus de temps à la planification ou que les exigences doivent être plus claires dès le départ.

Vous vous demandez quels KPI méritent votre attention ? Concentrez-vous sur ceux qui vous donnent une image complète des performances et des progrès de votre équipe. Attention :
Efficacité du codage : avec quelle rapidité et fluidité votre code découle de "Hé, j'ai écrit ceci !" à "Wow, ça marche!"
Mesures de collaboration : dans quelle mesure votre équipe joue de manière synchronisée --- comme un groupe bien répété ou une équipe de nage synchronisée.
Mesures de prévisibilité : avec quelle précision vous pouvez prévoir les résultats du projet, rendant vos prévisions aussi fiables qu'une application météo (mais plus précises !).
Mesures de fiabilité : la solidité de votre code et la capacité de vos tests à détecter ces bogues sournois avant qu'ils ne deviennent des obstacles.
Ces KPI vous aident à éviter les surprises et à maintenir vos projets sur la bonne voie. Considérez-les comme les éléments essentiels de votre boîte à outils de réussite : pas de superflu, juste les bonnes choses !
Voici donc la vérité : les KPI ne sont pas que des chiffres : ils sont votre arme secrète pour une prise de décision intelligente. Il vous aide à naviguer dans les méandres de votre productivité en ingénierie comme un pro. Et lorsque vous ajoutez les métriques DORA de Middleware à l’ensemble, vous obtenez une équipe imbattable. Le middleware élimine les incertitudes en suivant sans effort les métriques DORA telles que la fréquence de déploiement, le délai d'exécution, le taux d'échec des modifications et le temps moyen de récupération.
C'est comme avoir un acolyte personnel qui garde un œil sur vos KPI et s'assure que vous êtes toujours sur la bonne voie. Avec Middleware, vous ne vous contentez pas de réagir aux problèmes : vous les anticipez et orientez votre développement logiciel vers le succès. Consultez notre dépôt open source !
 middlewarehq
/
intergiciel
middlewarehq
/
intergiciel

Gestion de l'ingénierie open source qui libère le potentiel des développeurs





Rejoignez notre communauté Open Source
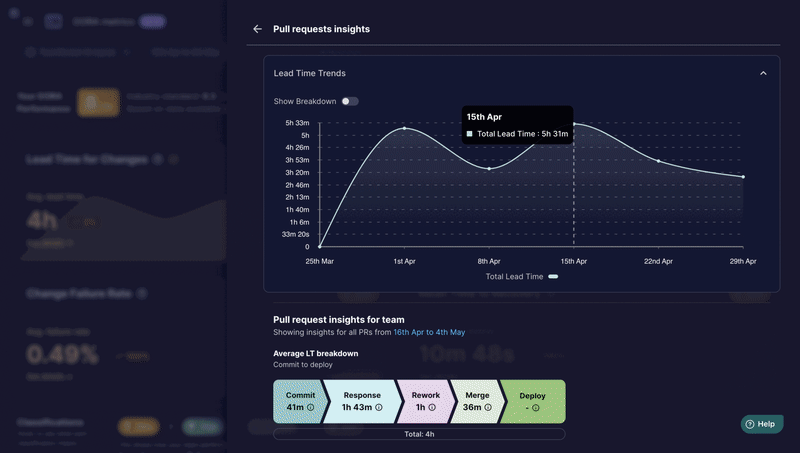
Middleware est un outil open source conçu pour aider les responsables de l'ingénierie à mesurer et analyser l'efficacité de leurs équipes à l'aide des métriques DORA. Les métriques DORA sont un ensemble de quatre valeurs clés qui fournissent des informations sur les performances de livraison de logiciels et l'efficacité opérationnelle.
Ils sont :
Table des matières
Un KPI (Key Performance Indicator) de développement logiciel est une valeur mesurable utilisée pour évaluer l'efficacité et l'efficience des processus de développement, y compris des mesures telles que la qualité du code, la fréquence de déploiement et les délais. Les KPI aident à évaluer les progrès vers des objectifs spécifiques et à améliorer les performances globales.
Pour suivre les KPI, y compris les métriques DORA, utilisez Middleware pour un suivi complet des performances, ainsi que Jira pour la gestion de projet et GitHub pour des informations sur le code.
Das obige ist der detaillierte Inhalt vonDie wichtigsten KPIs für die Softwareentwicklung, die Sie in 5 verfolgen sollten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So exportieren Sie Excel-Dateien aus Kingsoft Documents
So exportieren Sie Excel-Dateien aus Kingsoft Documents
 Laptop-Leistung
Laptop-Leistung
 So lösen Sie das Problem, dass JS-Code nach der Formatierung nicht ausgeführt werden kann
So lösen Sie das Problem, dass JS-Code nach der Formatierung nicht ausgeführt werden kann
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Ist ein Upgrade von Windows 11 notwendig?
Ist ein Upgrade von Windows 11 notwendig?
 Der Unterschied zwischen Sass und weniger
Der Unterschied zwischen Sass und weniger
 So verbinden Sie HTML-Dateien und CSS-Dateien
So verbinden Sie HTML-Dateien und CSS-Dateien
 Einführung in die Online-Rechnersoftware
Einführung in die Online-Rechnersoftware
 Der Unterschied zwischen vscode und vs
Der Unterschied zwischen vscode und vs








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



