

Einführung
Übung macht den Meister.
Etwas, das viel mit dem Beruf eines Datenwissenschaftlers gemeinsam hat. Die Theorie ist nur ein Aspekt der Gleichung; Der wichtigste Aspekt ist die Umsetzung der Theorie in die Praxis. Ich werde mir die Mühe machen, den gesamten heutigen Entwicklungsprozess meines Abschlussprojekts aufzuzeichnen, zu dem auch das Studium eines Filmdatensatzes gehört.
Das sind die Ziele:
Ziel:
1. Datenerfassung
Ich habe mich entschieden, Kaggle zu verwenden, um meinen Datensatz zu finden. Es ist wichtig, die entscheidenden Variablen im Auge zu behalten, die Sie für den Datensatz benötigen, mit dem Sie arbeiten. Wichtig ist, dass mein Datensatz Folgendes umfassen sollte: Trends im Erscheinungsjahr, Beliebtheit von Regisseuren, Einschaltquoten und Filmgenres. Daher muss ich sicherstellen, dass der von mir ausgewählte Datensatz mindestens Folgendes aufweist:
Mein Datensatz befand sich auf Kaggle und ich werde den Link unten bereitstellen. Sie können die CSV-Version der Datei erhalten, indem Sie den Datensatz herunterladen, ihn entpacken und extrahieren. Sie können einen Blick darauf werfen, um zu verstehen, was Sie bereits haben, und um wirklich zu erkennen, welche Erkenntnisse Sie aus den zu untersuchenden Daten gewinnen möchten.
2. Beschreiben der Daten
Zuerst müssen wir die erforderlichen Bibliotheken importieren und die erforderlichen Daten laden. Ich verwende für mein Projekt die Programmiersprache Python und Jupyter Notebooks, damit ich meinen Code effizienter schreiben und anzeigen kann.
Sie importieren die Bibliotheken, die wir verwenden werden, und laden die Daten wie unten gezeigt.
Wir führen dann den folgenden Befehl aus, um weitere Details zu unserem Datensatz zu erhalten.
data.head() # dispalys the first rows of the dataset. data.tail() # displays the last rows of the dataset. data.shape # Shows the total number of rows and columns. len(data.columns) # Shows the total number of columns. data.columns # Describes different column names. data.dtypes # Describes different data types.
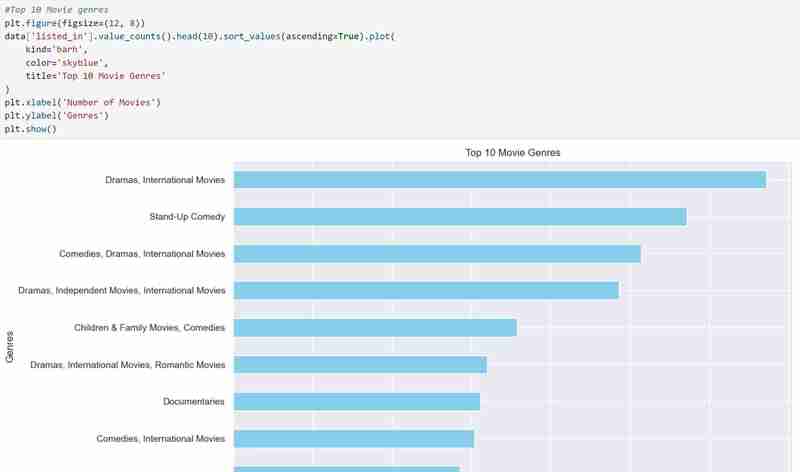
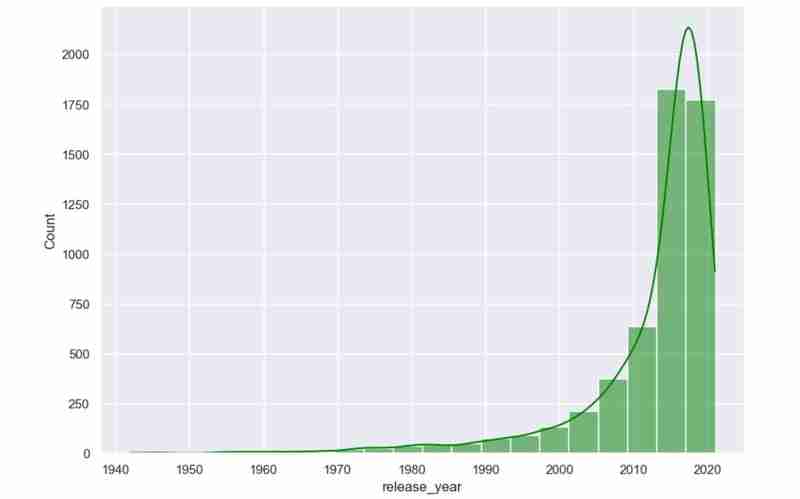
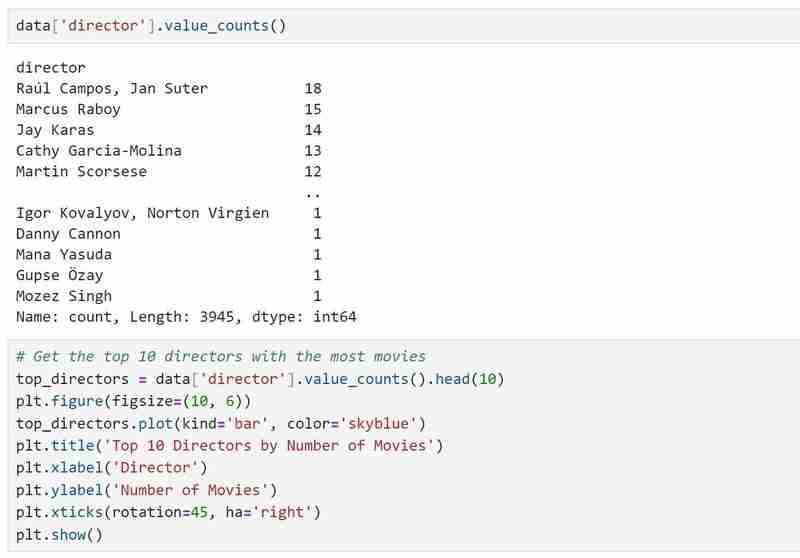
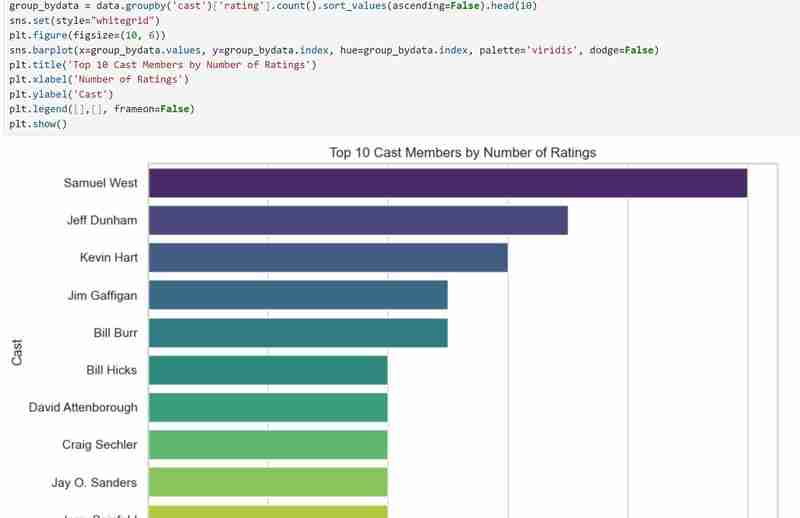
Nachdem wir alle benötigten Beschreibungen erhalten haben, wissen wir jetzt, was der Datensatz umfasst und welche Erkenntnisse wir gewinnen möchten. Beispiel: Mithilfe meines Datensatzes möchte ich Muster in der Beliebtheit von Regisseuren, der Einschaltquotenverteilung und den Filmgenres untersuchen. Ich möchte auch Filme vorschlagen, die auf den vom Benutzer ausgewählten Vorlieben basieren, z. B. bevorzugten Regisseuren und Genres.
3. Datenbereinigung
In dieser Phase geht es darum, alle Nullwerte zu finden und zu entfernen. Um mit der Datenvisualisierung fortzufahren, werden wir unseren Datensatz auch auf Duplikate untersuchen und alle gefundenen Duplikate entfernen. Dazu führen wir den folgenden Code aus:
1. data['show_id'].value_counts().sum() # Checks for the total number of rows in my dataset 2. data.isna().sum() # Checks for null values(I found null values in director, cast and country columns) 3. data[['director', 'cast', 'country']] = data[['director', 'cast', 'country']].replace(np.nan, "Unknown ") # Fill null values with unknown.
Wir löschen dann die Zeilen mit unbekannten Werten und bestätigen, dass wir sie alle gelöscht haben. Wir prüfen auch die Anzahl der verbleibenden Zeilen mit bereinigten Daten.
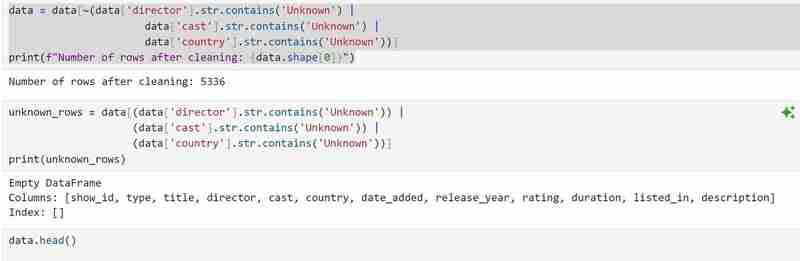
Der folgende Code sucht nach eindeutigen Merkmalen und Duplikaten. Obwohl mein Datensatz keine Duplikate enthält, müssen Sie ihn möglicherweise dennoch verwenden, falls dies in zukünftigen Datensätzen der Fall sein sollte.
data.duplicated().sum() # Checks for duplicates data.nunique() # Checks for unique features data.info # Confirms if nan values are present and also shows datatypes.
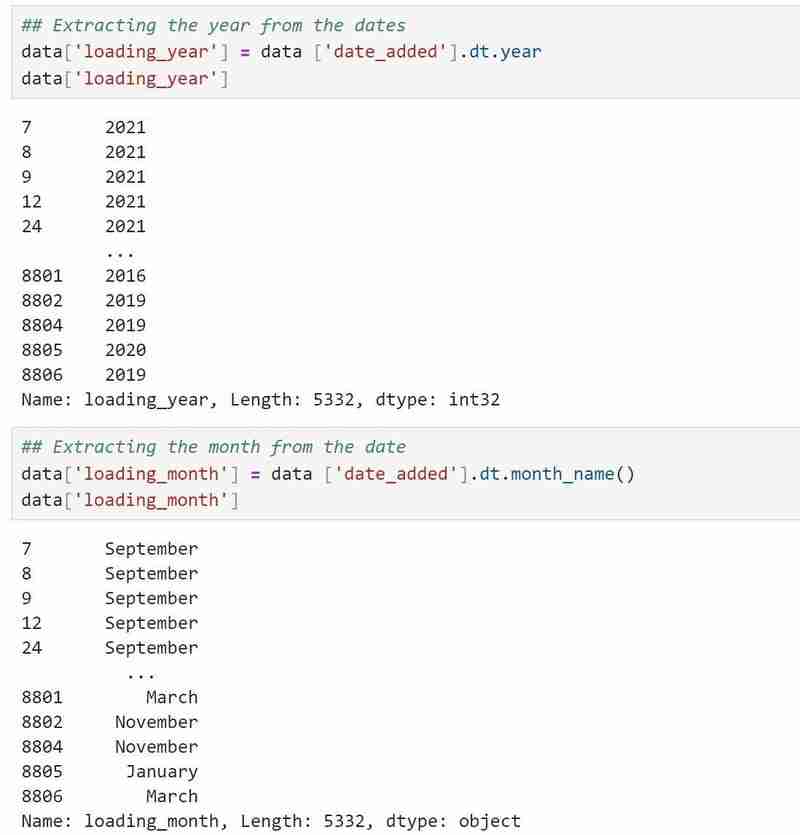
Mein Datums-/Uhrzeitdatentyp ist ein Objekt und ich möchte, dass es im richtigen Datums-/Uhrzeitformat vorliegt, das ich verwendet habe
data['date_added']=data['date_added'].astype('datetime64[ms]'), um es in das richtige Format zu konvertieren.
4. Datenvisualisierung
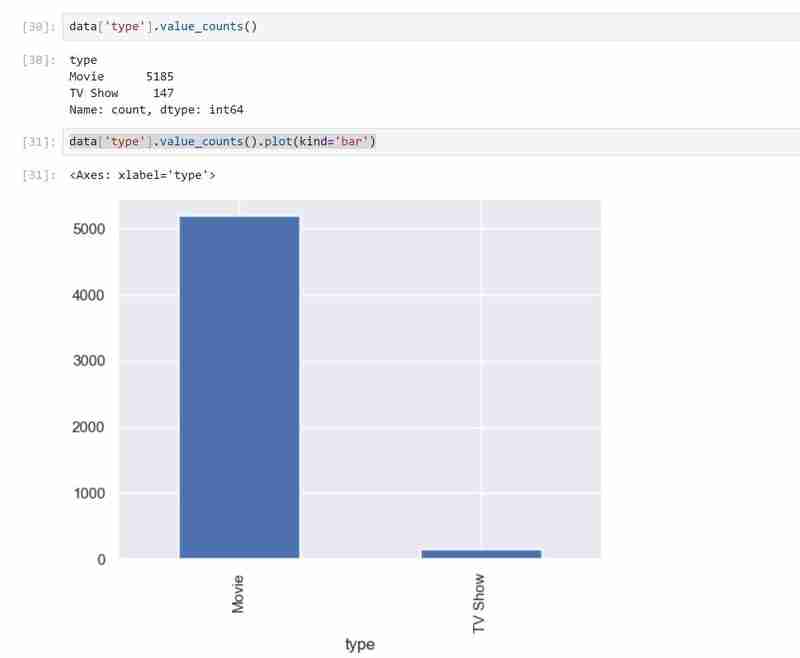
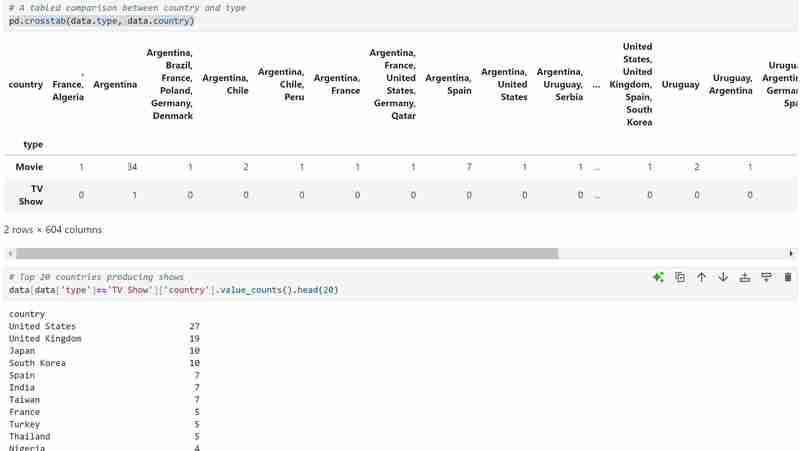
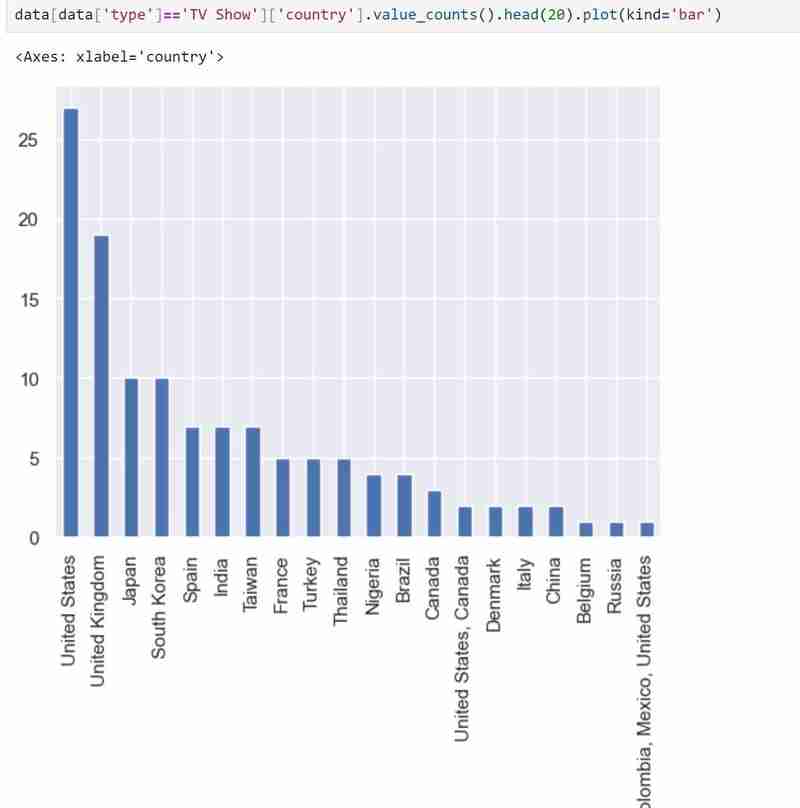
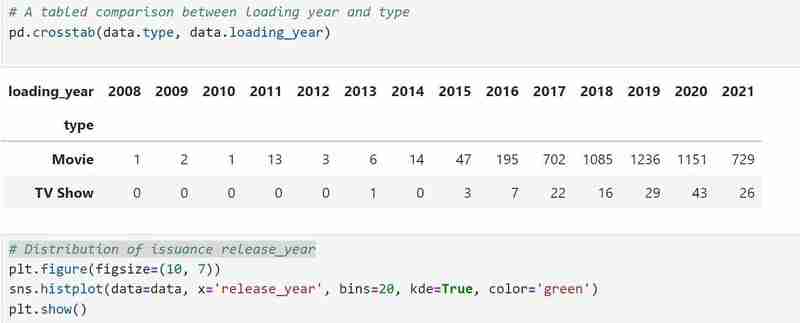
Mein Datensatz enthält zwei Arten von Variablen, nämlich die Typen „TV-Sendungen“ und „Filme“, und ich habe ein Balkendiagramm verwendet, um die kategorialen Daten mit den Werten darzustellen, die sie darstellen.
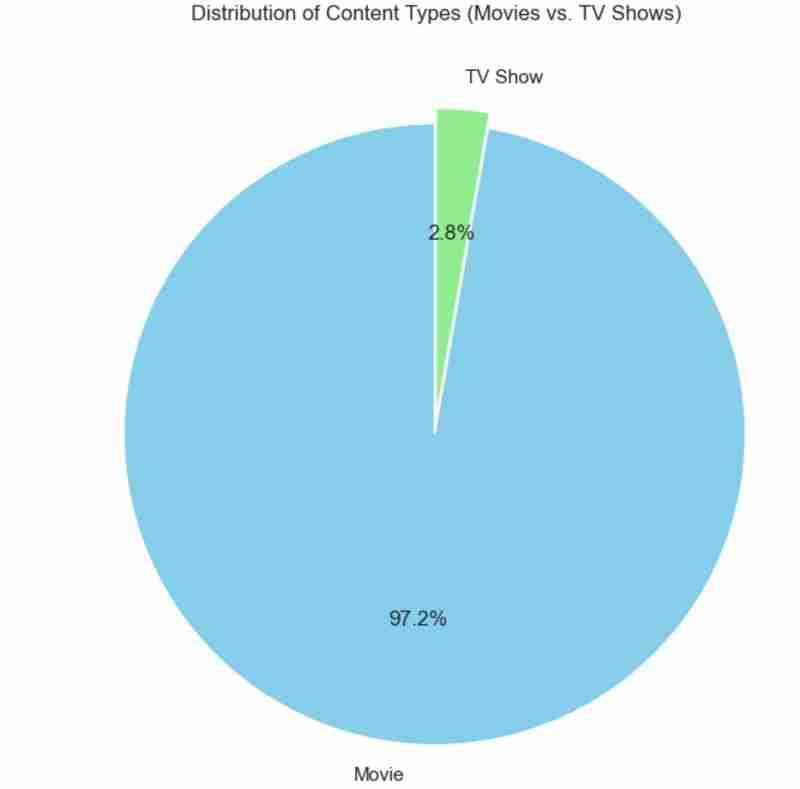
Ich habe auch ein Kreisdiagramm verwendet, um das Gleiche wie oben darzustellen. Der verwendete Code ist wie folgt und das erwartete Ergebnis wird unten angezeigt.
## Pie chart display
plt.figure(figsize=(8, 8))
data['type'].value_counts().plot(
kind='pie',
autopct='%1.1f%%',
colors=['skyblue', 'lightgreen'],
startangle=90,
explode=(0.05, 0)
)
plt.title('Distribution of Content Types (Movies vs. TV Shows)')
plt.ylabel('')
plt.show()
5. Recommendation System
I then built a recommendation system that takes in genre or director's name as input and produces a list of movies as per the user's preference. If the input cannot be matched by the algorithm then the user is notified.

The code for the above is as follows:
def recommend_movies(genre=None, director=None):
recommendations = data
if genre:
recommendations = recommendations[recommendations['listed_in'].str.contains(genre, case=False, na=False)]
if director:
recommendations = recommendations[recommendations['director'].str.contains(director, case=False, na=False)]
if not recommendations.empty:
return recommendations[['title', 'director', 'listed_in', 'release_year', 'rating']].head(10)
else:
return "No movies found matching your preferences."
print("Welcome to the Movie Recommendation System!")
print("You can filter movies by Genre or Director (or both).")
user_genre = input("Enter your preferred genre (or press Enter to skip): ")
user_director = input("Enter your preferred director (or press Enter to skip): ")
recommendations = recommend_movies(genre=user_genre, director=user_director)
print("\nRecommended Movies:")
print(recommendations)
Conclusion
My goals were achieved, and I had a great time taking on this challenge since it helped me realize that, even though learning is a process, there are days when I succeed and fail. This was definitely a success. Here, we celebrate victories as well as defeats since, in the end, each teach us something. Do let me know if you attempt this.
Till next time!
Note!!
The code is in my GitHub:
https://github.com/MichelleNjeri-scientist/Movie-Dataset-Exploration-and-Visualization
The Kaggle dataset is:
https://www.kaggle.com/datasets/shivamb/netflix-shows
Das obige ist der detaillierte Inhalt vonErkundung und Visualisierung von Filmdatensätzen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Ajax-Tutorial
Ajax-Tutorial
 So zeigen Sie den Tomcat-Quellcode an
So zeigen Sie den Tomcat-Quellcode an
 Was tun, wenn das Login-Token ungültig ist?
Was tun, wenn das Login-Token ungültig ist?
 Welche Möglichkeiten gibt es, Shell-Skripte auszuführen?
Welche Möglichkeiten gibt es, Shell-Skripte auszuführen?
 Der Zweck des Levels
Der Zweck des Levels
 Was bedeutet es, alle Cookies zu blockieren?
Was bedeutet es, alle Cookies zu blockieren?
 So setzen Sie Chinesisch in Eclipse ein
So setzen Sie Chinesisch in Eclipse ein
 Win10 unterstützt die Festplattenlayoutlösung der Uefi-Firmware nicht
Win10 unterstützt die Festplattenlayoutlösung der Uefi-Firmware nicht








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



