

Verbinden Sie KI/ML mit Ihrer Adaptive Analytics-Lösung

In der heutigen Datenlandschaft stehen Unternehmen vor einer Reihe unterschiedlicher Herausforderungen. Eine davon besteht darin, Analysen auf der Grundlage einer einheitlichen und harmonisierten Datenschicht durchzuführen, die allen Verbrauchern zur Verfügung steht. Eine Ebene, die unabhängig vom verwendeten Dialekt oder Werkzeug dieselben Antworten auf dieselben Fragen liefern kann.
Die InterSystems IRIS Data Platform beantwortet diese Frage mit einem Add-on von Adaptive Analytics, das diese einheitliche semantische Ebene bereitstellen kann. In DevCommunity gibt es viele Artikel über die Verwendung über BI-Tools. In diesem Artikel geht es darum, wie man es mit KI nutzt und wie man einige Erkenntnisse zurückgewinnt.
Gehen wir Schritt für Schritt vor...
Was ist Adaptive Analytics?
Eine Definition finden Sie leicht auf der Website der Entwickler-Community
Kurz gesagt: Es kann Daten in strukturierter und harmonisierter Form an verschiedene Tools Ihrer Wahl zur weiteren Nutzung und Analyse liefern. Es liefert dieselben Datenstrukturen an verschiedene BI-Tools. Aber... es kann auch dieselben Datenstrukturen an Ihre KI/ML-Tools liefern!
Adaptive Analytics verfügt über eine zusätzliche Komponente namens AI-Link, die diese Brücke von KI zu BI schlägt.
Was genau ist AI-Link?
Es handelt sich um eine Python-Komponente, die eine programmatische Interaktion mit der semantischen Ebene ermöglichen soll, um wichtige Phasen des maschinellen Lernworkflows (ML) zu optimieren (z. B. Feature Engineering).
Mit AI-Link können Sie:
- programmgesteuert auf Funktionen Ihres analytischen Datenmodells zugreifen;
- Fragen stellen, Dimensionen und Maße erkunden;
- ML-Pipelines füttern; ... und liefern Ergebnisse zurück an Ihre semantische Ebene, damit sie von anderen erneut genutzt werden können (z. B. über Tableau oder Excel).
Da es sich um eine Python-Bibliothek handelt, kann sie in jeder Python-Umgebung verwendet werden. Einschließlich Notizbücher.
Und in diesem Artikel gebe ich ein einfaches Beispiel für die Erreichung einer Adaptive Analytics-Lösung aus Jupyter Notebook mithilfe von AI-Link.
Hier ist das Git-Repository, das das vollständige Notebook als Beispiel enthält: https://github.com/v23ent/aa-hands-on
Voraussetzungen
Für die weiteren Schritte wird davon ausgegangen, dass die folgenden Voraussetzungen erfüllt sind:
- Adaptive Analytics-Lösung in Betrieb (mit IRIS Data Platform als Data Warehouse)
- Jupyter Notebook läuft
- Verbindung zwischen 1. und 2. kann hergestellt werden
Schritt 1: Einrichtung
Zuerst installieren wir die benötigten Komponenten in unserer Umgebung. Dadurch werden einige Pakete heruntergeladen, die für weitere Schritte erforderlich sind.
„atscale“ – das ist unser Hauptpaket zum Verbinden
„Prophet“ – Paket, das wir für Vorhersagen benötigen
pip install atscale prophet
Dann müssen wir Schlüsselklassen importieren, die einige Schlüsselkonzepte unserer semantischen Ebene darstellen.
Client – Klasse, die wir verwenden, um eine Verbindung zu Adaptive Analytics herzustellen;
Projekt – Klasse zur Darstellung von Projekten innerhalb von Adaptive Analytics;
DataModel – Klasse, die unseren virtuellen Würfel darstellt;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
Schritt 2: Verbindung
Jetzt sollten wir bereit sein, eine Verbindung zu unserer Datenquelle herzustellen.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Fahren Sie fort und geben Sie die Verbindungsdetails Ihrer Adaptive Analytics-Instanz an. Sobald Sie nach der Organisation gefragt werden, antworten Sie im Dialogfeld und geben Sie dann bitte Ihr Passwort aus der AtScale-Instanz ein.
Sobald die Verbindung hergestellt ist, müssen Sie Ihr Projekt aus der Liste der auf dem Server veröffentlichten Projekte auswählen. Sie erhalten die Liste der Projekte als interaktive Eingabeaufforderung und die Antwort sollte die ganzzahlige ID des Projekts sein. Und dann wird das Datenmodell automatisch ausgewählt, wenn es das einzige ist.
project = client.select_project() data_model = project.select_data_model()
Schritt 3: Erkunden Sie Ihren Datensatz
Es gibt eine Reihe von Methoden, die von AtScale in der AI-Link-Komponentenbibliothek vorbereitet wurden. Sie ermöglichen es, den vorhandenen Datenkatalog zu durchsuchen, Daten abzufragen und sogar einige Daten wieder aufzunehmen. Die AtScale-Dokumentation enthält eine ausführliche API-Referenz, die alles beschreibt, was verfügbar ist.
Lassen Sie uns zunächst sehen, was unser Datensatz ist, indem wir einige Methoden von data_model:
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
Die Ausgabe sollte etwa so aussehen
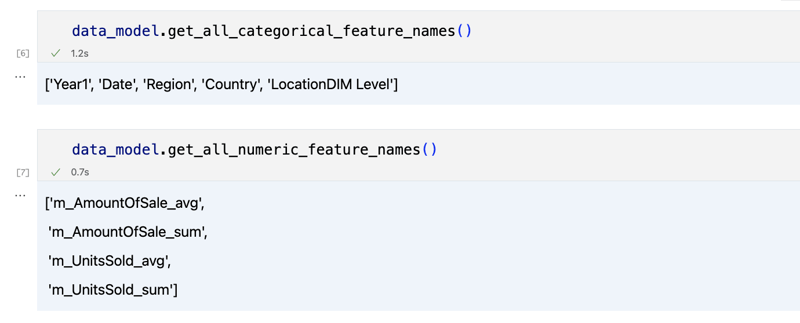
Sobald wir uns ein wenig umgesehen haben, können wir die tatsächlichen Daten, an denen wir interessiert sind, mit der Methode „get_data“ abfragen. Es wird ein Pandas-DataFrame zurückgegeben, der die Abfrageergebnisse enthält.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
Hier wird Ihr Datadrame angezeigt:
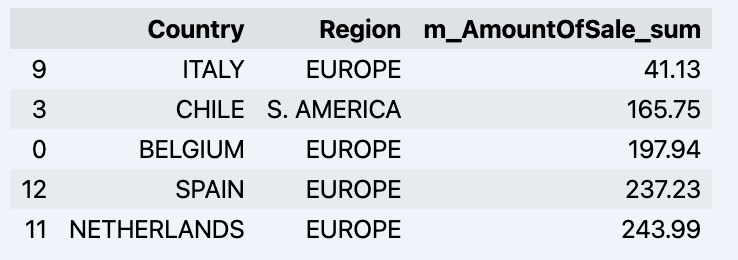
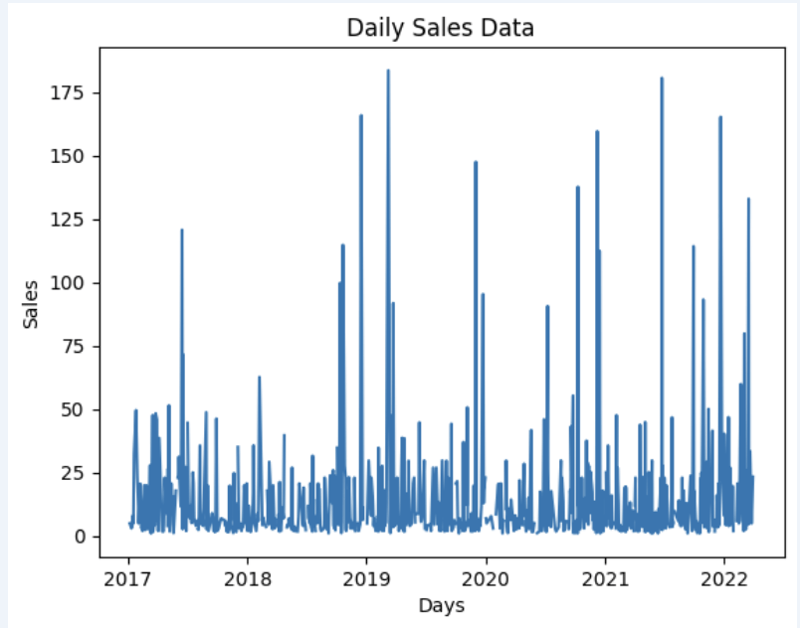
Lassen Sie uns einen Datensatz vorbereiten und ihn schnell in der Grafik anzeigen
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
Ausgabe:
Step 4: Prediction
The next step would be to actually get some value out of AI-Link bridge - let's do some simple prediction!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
We get 2 different datasets here: to train our model and to test it.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
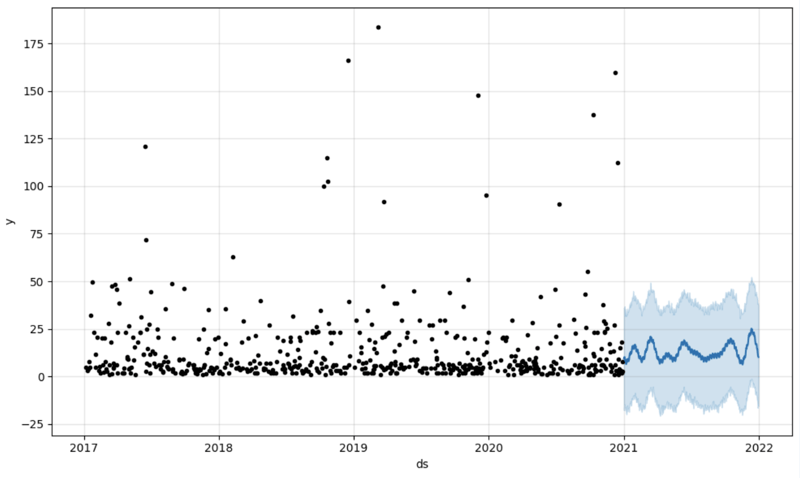
And then we create another dataframe to accomodate our prediction and display it on the graph
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
Output:
Step 5: Writeback
Once we've got our prediction in place we can then put it back to the data warehouse and add an aggregate to our semantic model to reflect it for other consumers. The prediction would be available through any other BI tool for BI analysts and business users.
The prediction itself will be placed into our data warehouse and stored there.
from atscale.db.connections import Iris<br>
db = Iris(<br>
username,<br>
host,<br>
namespace,<br>
driver,<br>
schema, <br>
port=1972,<br>
password=None, <br>
warehouse_id=None<br>
)
<p>data_model.writeback(dbconn=db,<br>
table_name= 'SalesPrediction',<br>
DataFrame = forecast)</p>
<p>data_model.create_aggregate_feature(dataset_name='SalesPrediction',<br>
column_name='SalesForecasted',<br>
name='sum_sales_forecasted',<br>
aggregation_type='SUM')<br>
</p>
Fin
That is it!
Good luck with your predictions!
Das obige ist der detaillierte Inhalt vonVerbinden Sie KI/ML mit Ihrer Adaptive Analytics-Lösung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So verwenden Sie Python, um die ZiPF -Verteilung einer Textdatei zu finden
Mar 05, 2025 am 09:58 AM
So verwenden Sie Python, um die ZiPF -Verteilung einer Textdatei zu finden
Mar 05, 2025 am 09:58 AM
So verwenden Sie Python, um die ZiPF -Verteilung einer Textdatei zu finden
 So herunterladen Sie Dateien in Python
Mar 01, 2025 am 10:03 AM
So herunterladen Sie Dateien in Python
Mar 01, 2025 am 10:03 AM
So herunterladen Sie Dateien in Python

 Wie benutze ich eine schöne Suppe, um HTML zu analysieren?
Mar 10, 2025 pm 06:54 PM
Wie benutze ich eine schöne Suppe, um HTML zu analysieren?
Mar 10, 2025 pm 06:54 PM
Wie benutze ich eine schöne Suppe, um HTML zu analysieren?
 Wie man mit PDF -Dokumenten mit Python arbeitet
Mar 02, 2025 am 09:54 AM
Wie man mit PDF -Dokumenten mit Python arbeitet
Mar 02, 2025 am 09:54 AM
Wie man mit PDF -Dokumenten mit Python arbeitet
 Wie kann man mit Redis in Django -Anwendungen zwischenstrichen
Mar 02, 2025 am 10:10 AM
Wie kann man mit Redis in Django -Anwendungen zwischenstrichen
Mar 02, 2025 am 10:10 AM
Wie kann man mit Redis in Django -Anwendungen zwischenstrichen
 Einführung des natürlichen Sprach -Toolkits (NLTK)
Mar 01, 2025 am 10:05 AM
Einführung des natürlichen Sprach -Toolkits (NLTK)
Mar 01, 2025 am 10:05 AM
Einführung des natürlichen Sprach -Toolkits (NLTK)
 Wie führe ich ein tiefes Lernen mit Tensorflow oder Pytorch durch?
Mar 10, 2025 pm 06:52 PM
Wie führe ich ein tiefes Lernen mit Tensorflow oder Pytorch durch?
Mar 10, 2025 pm 06:52 PM
Wie führe ich ein tiefes Lernen mit Tensorflow oder Pytorch durch?
