

Für meinen ersten Beitrag habe ich ein Problem eingereicht, um einem anderen Projekt eine neue Funktion hinzuzufügen, die darin besteht, eine neue Flag-Option hinzuzufügen, um die für die Eingabeaufforderung und die Abschlussgenerierung verwendeten Token anzuzeigen.
 Feat: Chat-Abschluss-Token-Info-Flag-Option
#8
Feat: Chat-Abschluss-Token-Info-Flag-Option
#8

Eine Flag-Option, die dem Benutzer die Anzahl der gesendeten und empfangenen Token anzeigt. Ich denke, dass es eine wichtige Funktion ist, die den Benutzer anleitet, das Token-Budget einzuhalten, wenn er eine Chat-Abschlussanfrage stellt!
Dazu müssten wir ein weiteres Optionsflag hinzufügen, das -t und --token-usage sein könnte. Wenn ein Benutzer dieses Flag in seinen Befehl einfügt, sollte es klar und detailliert anzeigen, wie viele Token bei der Generierung der Vervollständigung und wie viele Token in der Eingabeaufforderung verwendet wurden.
Ich habe mich entschieden, zum Open-Source-Projekt chat-minal von fadingNA beizutragen, einem in Python geschriebenen CLI-Tool, mit dem Sie OpenAI nutzen können, um verschiedene Dinge zu tun, z Text und zusammenfassender Text.
Ich habe schon früher Code in Python geschrieben, aber es ist nicht meine stärkste Fähigkeit. Daher stellt die Mitarbeit an diesem Projekt für mich eine herausfordernde, aber gute Lernerfahrung dar.
Die Herausforderung besteht darin, dass ich den Code einer anderen Person lesen und verstehen und eine geeignete Lösung bereitstellen muss, die das Design des Codes nicht beeinträchtigt. Das Verständnis des Ablaufs ist von entscheidender Bedeutung, damit ich die Funktion effizient hinzufügen kann, ohne große Änderungen am Code vornehmen zu müssen, und um den Code konsistent zu halten.
FEAT: Token-Nutzungsflag
#9
Die Funktion wurde hinzugefügt, um eine Flag-Option --token_usage für den Benutzer einzuschließen. Diese Option gibt dem Benutzer die Information, wie viele Token für die Eingabeaufforderung und den generierten Abschluss verwendet wurden.
Die Lösung, die ich basierend auf dem Codedesign gefunden habe, besteht darin, zu prüfen, ob das token_usage-Flag vorhanden ist. Ich möchte nicht, dass der Code unnötige if-Anweisungen überprüft, wenn das token_usage-Flag nicht verwendet wurde. Deshalb habe ich zwei separate identische Schleifenlogiken erstellt, mit dem Unterschied, dass die Existenz von use_metadata innerhalb des Blocks überprüft wird.
if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)At the end of the execution of get_completions() method, a check for the flag token_usage is added, which then displays the token usage details to stderr if the flag was used.
if token_usage:
logger.error(f"Tokens used for completion: <span class="pl-s1"><span class="pl-kos">{completion_tokens}</span>"</span>)
logger.error(f"Tokens used for prompt: <span class="pl-s1"><span class="pl-kos">{prompt_tokens}</span>"</span>)if token_usage:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
if chunk.usage_metadata:
completion_tokens = chunk.usage_metadata.get('output_tokens')
prompt_tokens = chunk.usage_metadata.get('input_tokens')
else:
for chunk in runnable.stream({"input_text": input_text}):
print(chunk.content, end="", flush=True)
answer.append(chunk.content)
Originally, the code only had one for loop which retrieves the content from a stream and appends it to an array which forms the response of the completion.
My reasoning behind duplicating the for while adding the distinct if block is to prevent the code from repeatedly checking the if block even if the user is not using the newly added --token_usage flag. So instead, I check for the existence of the flag firstly, and then decide which for loop to execute.
Even though my pull request has been accepted by the project owner, I realized late that this way adds complexity to the code's maintainability. For example, if there are changes required in the for loop for processing the stream, that means modifying the code twice since there are two identical for loops.
What I think I could do as an improvement for it is to make it into a function so that any changes required can be done in one function only, keeping the maintainability of the code. This just proves that even if I wrote the code with optimization in mind, there are still other things that I can miss which is crucial to a project, which in this case, is maintainability.
My tool, genereadme, also received a contribution. I received a PR from Mounayer, which is to add the same feature to my project.
feat: added a new flag that displays the number of tokens sent in prompt and received in completion
#13

Closes #12.
This simply required the addition for another flag check --token-usage:
.option("--token-usage", "Show prompt and completion token usage")I've also made sure to keep your naming conventions/formatting style consistent, in the for loop that does the chat completion for each file processed, I have accumulated the total tokens sent and received:
promptTokens += response.usage.prompt_tokens;
completionTokens += response.usage.completion_tokens;which I then display at the end of program run-time if the --token-usage flag is provided as such:
if (program.opts().tokenUsage) {
console.error(`Prompt tokens: <span class="pl-s1"><span class="pl-kos">${promptTokens}</span>`</span>);
console.error(`Completion tokens: <span class="pl-s1"><span class="pl-kos">${completionTokens}</span>`</span>);
}genereadme examples/sum.js --token-usage
This should display something like:
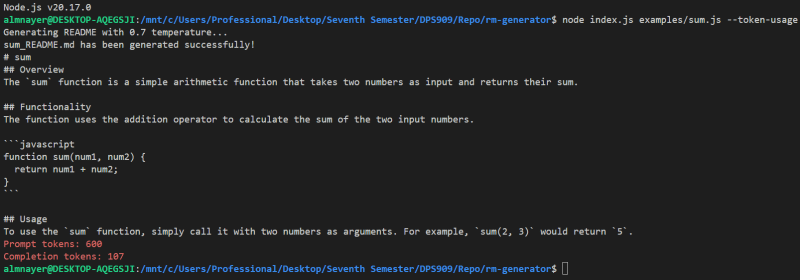
You can try it out with multiple files too, i.e.:
genereadme examples/sum.js examples/createUser.js --token-usage
This time, instead of having to read someone else's code, someone had to read mine and contribute to it. It is nice knowing that someone is able to contribute to my project. To me, it means that they understood how my code works, so they were able to add the feature without breaking anything or adding any complexity to the code base.
With that being mentioned, reading code is also a skill that is not to be underestimated. My code is nowhere near perfect and I know there are still places I can improve on, so credit is also due to being able to read and understand code.
This specific pull request did not really require any back and forth changes as the code that was written by Mounayer is what I would have written myself.
Das obige ist der detaillierte Inhalt vonMein erster Open-Source-Beitrag. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Was ist digitale Währung?
Was ist digitale Währung?
 Der Unterschied zwischen Pfeilfunktionen und gewöhnlichen Funktionen
Der Unterschied zwischen Pfeilfunktionen und gewöhnlichen Funktionen
 Bereinigen Sie den Müll in Win10
Bereinigen Sie den Müll in Win10
 besonderer Symbolpunkt
besonderer Symbolpunkt
 Auf welche Tasten beziehen sich Pfeile in Computern?
Auf welche Tasten beziehen sich Pfeile in Computern?
 So verwenden Sie die Print()-Funktion in Python
So verwenden Sie die Print()-Funktion in Python
 In Word gibt es eine zusätzliche leere Seite, die ich nicht löschen kann.
In Word gibt es eine zusätzliche leere Seite, die ich nicht löschen kann.








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



