

Streamlit ist ein leistungsstarkes Open-Source-Framework, mit dem Sie mit nur Webanwendungen für Datenwissenschaft und maschinelles Lernen erstellen können ein paar Zeilen Python-Code.
Es ist einfach, intuitiv und erfordert keine Frontend-Erfahrung, was es zu einem großartigen Tool sowohl für Anfänger als auch für erfahrene Entwickler macht, die schnell Modelle für maschinelles Lernen bereitstellen möchten.
In diesem Blog führe ich Sie Schritt für Schritt durch den Prozess zum Erstellen einer einfachen Streamlit-App und eines Projekts für maschinelles Lernen unter Verwendung des Iris-Datensatzes mit einem RandomForestClassifier .
Bevor wir mit dem Projekt beginnen, gehen wir einige grundlegende Streamlit-Funktionen durch, um uns mit dem Framework vertraut zu machen. Sie können Streamlit mit dem folgenden Befehl installieren:
pip install streamlit
Nach der Installation können Sie Ihre erste Streamlit-App starten, indem Sie eine Python-Datei erstellen, beispielsweise app.py, und sie mit folgendem Befehl ausführen:
streamlit run app.py
Lassen Sie uns nun die Kernfunktionen von Streamlit erkunden:
1. Titel schreiben und Text anzeigen
import streamlit as st
# Writing a title
st.title("Hello World")
# Display simple text
st.write("Displaying a simple text")

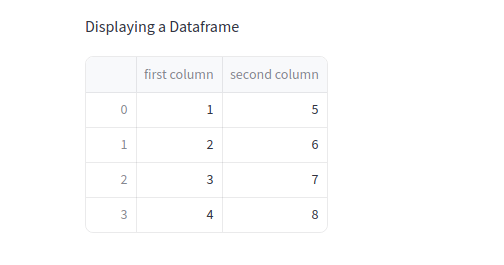
2. DataFrames anzeigen
import pandas as pd
# Creating a DataFrame
df = pd.DataFrame({
"first column": [1, 2, 3, 4],
"second column": [5, 6, 7, 8]
})
# Display the DataFrame
st.write("Displaying a DataFrame")
st.write(df)
3. Daten mit Diagrammen visualisieren
import numpy as np
# Generating random data
chart_data = pd.DataFrame(
np.random.randn(20, 4), columns=['a', 'b', 'c', 'd']
)
# Display the line chart
st.line_chart(chart_data)

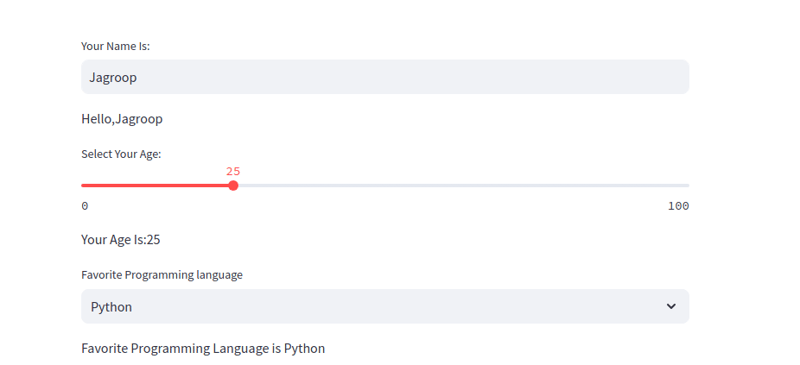
4. Benutzerinteraktion: Texteingabe, Schieberegler und Auswahlfelder
Streamlit ermöglicht interaktive Widgets wie Texteingaben, Schieberegler und Auswahlfelder, die dynamisch basierend auf Benutzereingaben aktualisiert werden.
# Text input
name = st.text_input("Your Name Is:")
if name:
st.write(f'Hello, {name}')
# Slider
age = st.slider("Select Your Age:", 0, 100, 25)
if age:
st.write(f'Your Age Is: {age}')
# Select Box
choices = ["Python", "Java", "Javascript"]
lang = st.selectbox('Favorite Programming Language', choices)
if lang:
st.write(f'Favorite Programming Language is {lang}')
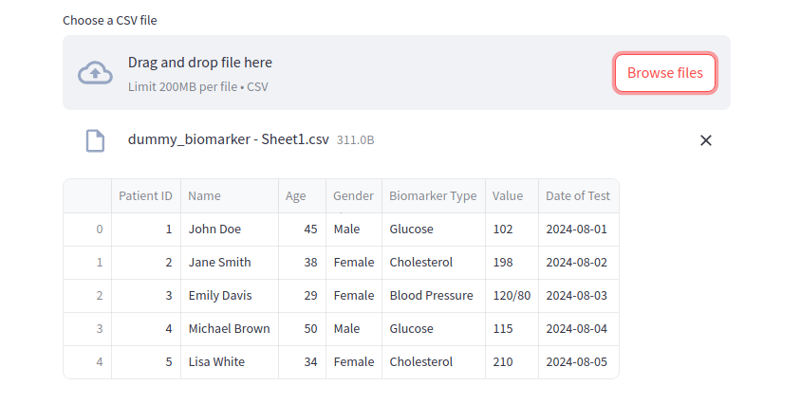
5. Datei hochladen
Sie können Benutzern erlauben, Dateien hochzuladen und ihre Inhalte dynamisch in Ihrer Streamlit-App anzuzeigen:
# File uploader for CSV files
file = st.file_uploader('Choose a CSV file', 'csv')
if file:
data = pd.read_csv(file)
st.write(data)
Da Sie nun mit den Grundlagen vertraut sind, beginnen wir mit der Erstellung eines Projekts für maschinelles Lernen. Wir werden den berühmten Iris-Datensatz verwenden und ein einfaches Klassifizierungs-Modell mit RandomForestClassifier von scikit-learn erstellen.
Projektstruktur:
1. Installieren Sie die erforderlichen Abhängigkeiten
Zuerst installieren wir die notwendigen Bibliotheken:
pip install streamlit scikit-learn numpy pandas
2. Bibliotheken importieren und Daten laden
Importieren wir die erforderlichen Bibliotheken und laden den Iris-Datensatz:
import streamlit as st
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# Cache data for efficient loading
@st.cache_data
def load_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["species"] = iris.target
return df, iris.target_names
df, target_name = load_data()
3. Trainieren Sie das Modell des maschinellen Lernens
Sobald wir die Daten haben, trainieren wir einen RandomForestClassifier, um die Art einer Blume anhand ihrer Merkmale vorherzusagen:
# Train RandomForestClassifier model = RandomForestClassifier() model.fit(df.iloc[:, :-1], df["species"])
4. Erstellen der Eingabeschnittstelle
Jetzt erstellen wir Schieberegler in der Seitenleiste, damit Benutzer Funktionen zum Erstellen von Vorhersagen eingeben können:
# Sidebar for user input
st.sidebar.title("Input Features")
sepal_length = st.sidebar.slider("Sepal length", float(df['sepal length (cm)'].min()), float(df['sepal length (cm)'].max()))
sepal_width = st.sidebar.slider("Sepal width", float(df['sepal width (cm)'].min()), float(df['sepal width (cm)'].max()))
petal_length = st.sidebar.slider("Petal length", float(df['petal length (cm)'].min()), float(df['petal length (cm)'].max()))
petal_width = st.sidebar.slider("Petal width", float(df['petal width (cm)'].min()), float(df['petal width (cm)'].max()))
5. Vorhersage der Arten
Nachdem wir die Benutzereingaben erhalten haben, werden wir mithilfe des trainierten Modells eine Vorhersage treffen:
# Prepare the input data
input_data = [[sepal_length, sepal_width, petal_length, petal_width]]
# Prediction
prediction = model.predict(input_data)
prediction_species = target_name[prediction[0]]
# Display the prediction
st.write("Prediction:")
st.write(f'Predicted species is {prediction_species}')
Das sieht so aus:


Schließlich macht esStreamlit unglaublich einfach, eine Webschnittstelle für maschinelles Lernen mit minimalem Aufwand zu erstellen und bereitzustellen. ? In nur wenigen Codezeilen haben wir eine interaktive App erstellt? das es Benutzern ermöglicht, Merkmale einzugeben und die Art einer Blume vorherzusagen? unter Verwendung eines maschinellen Lernmodells. ??
Viel Spaß beim Codieren! ?
Das obige ist der detaillierte Inhalt vonStreamlit: Der Zauberstab für die Erstellung von ML-Apps. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



