

Wer möchte nicht sofortige Antworten aus seinen Dokumenten? Das ist genau das, was RAG-Chatbots tun – sie kombinieren das Abrufen mit der KI-Generierung für schnelle, genaue Antworten!
In dieser Anleitung zeige ich Ihnen, wie Sie einen Chatbot mit Retrieval-Augmented Generation (RAG) mit LangChain und Streamlit erstellen. Dieser Chatbot ruft relevante Informationen aus einer Wissensdatenbank ab und verwendet ein Sprachmodell, um Antworten zu generieren.
Ich werde Sie durch jeden Schritt führen und mehrere Optionen für die Antwortgenerierung bereitstellen, unabhängig davon, ob Sie OpenAI, Gemini oder Fireworks verwenden – um eine flexible Lösung zu gewährleisten und kostengünstige Lösung.
RAG ist eine Methode, die Abruf und Generierung kombiniert, um genauere und kontextbezogene Chatbot-Antworten zu liefern. Der Abrufprozess ruft relevante Dokumente aus einer Wissensdatenbank ab, während der Generierungsprozess ein Sprachmodell verwendet, um eine kohärente Antwort basierend auf dem abgerufenen Inhalt zu erstellen. Dadurch wird sichergestellt, dass Ihr Chatbot Fragen mit den aktuellsten Daten beantworten kann, auch wenn das Sprachmodell selbst nicht speziell auf diese Informationen trainiert wurde.
Stellen Sie sich vor, Sie haben einen persönlichen Assistenten, der nicht immer die Antwort auf Ihre Fragen weiß. Wenn Sie also eine Frage stellen, durchsuchen sie Bücher und finden relevante Informationen (Abrufen), dann fassen sie diese Informationen zusammen und teilen sie Ihnen in ihren eigenen Worten mit (Generierung). So funktioniert RAG im Wesentlichen und vereint das Beste aus beiden Welten.
In einem Flussdiagramm sieht der RAG-Prozess in etwa so aus:
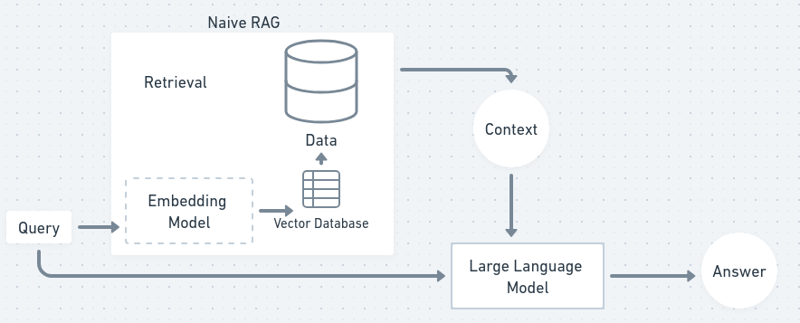
Jetzt fangen wir an und holen uns unseren eigenen Chatbot!
Wir werden in diesem TUTO hauptsächlich Python verwenden. Wenn Sie JS-Experte sind, können Sie den Erklärungen folgen und die Dokumentation von langchain js durchgehen.
Zuerst müssen wir unsere Projektumgebung einrichten. Dazu gehört das Erstellen eines Projektverzeichnisses, das Installieren von Abhängigkeiten und das Einrichten von API-Schlüsseln für verschiedene Sprachmodelle.
Erstellen Sie zunächst einen Projektordner und eine virtuelle Umgebung:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
Als nächstes erstellen Sie eine Datei „requirements.txt“, um alle erforderlichen Abhängigkeiten aufzulisten:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
Jetzt installieren Sie diese Abhängigkeiten:
pip install -r requirements.txt
Wir verwenden OpenAI, Gemini oder Fireworks für die Antwortgenerierung des Chatbots. Sie können diese je nach Ihren Vorlieben auswählen.
Machen Sie sich keine Sorgen, wenn Sie experimentieren, Fireworks stellt API-Schlüssel im Wert von 1 $ kostenlos zur Verfügung, und das Gemini-1.5-Flash-Modell ist in gewissem Umfang ebenfalls kostenlos!
Richten Sie eine .env-Datei ein, um die API-Schlüssel für Ihr bevorzugtes Modell zu speichern:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
Achten Sie darauf, sich für diese Dienste anzumelden und Ihre API-Schlüssel zu erhalten. Sowohl Gemini als auch Fireworks bieten kostenlose Stufen an, während OpenAI nutzungsabhängig abgerechnet wird.
Um dem Chatbot einen Kontext zu geben, müssen wir Dokumente verarbeiten und sie in überschaubare Teile aufteilen. Dies ist wichtig, da große Texte zum Einbetten und Indizieren zerlegt werden müssen.
Erstellen Sie ein neues Python-Skript mit dem Namen document_processor.py, um die Dokumentverarbeitung abzuwickeln:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
Dieses Skript lädt eine Textdatei und teilt sie in kleinere Teile von etwa 1000 Zeichen mit einer kleinen Überlappung auf, um sicherzustellen, dass kein Kontext zwischen den Teilen verloren geht. Nach der Verarbeitung können die Dokumente eingebettet und indiziert werden.
Da wir nun unsere Dokumente in Chunks unterteilt haben, besteht der nächste Schritt darin, sie in Einbettungen (numerische Darstellungen von Text) umzuwandeln und sie für einen schnellen Abruf zu indizieren. (Da Maschinen Zahlen leichter verstehen als Wörter)
Erstellen Sie ein weiteres Skript mit dem Namen embedding_indexer.py:
pip install -r requirements.txt
In diesem Skript werden die Einbettungen mithilfe eines Hugging-Face-Modells (alle MiniLM-L6-v2) erstellt. Anschließend speichern wir diese Einbettungen in einem FAISS-Vektorspeicher, der es uns ermöglicht, basierend auf einer Abfrage schnell ähnliche Textabschnitte abzurufen.
Hier kommt der spannende Teil: die Kombination von Retrieval und Sprachgenerierung! Sie erstellen nun eine RAG-Kette, die relevante Blöcke aus dem Vectorstore abruft und mithilfe eines Sprachmodells eine Antwort generiert. (vectorstore ist eine Datenbank, in der wir unsere in Zahlen als Vektoren umgewandelten Daten gespeichert haben)
Lassen Sie uns die Datei rag_chain.py erstellen:
# Uncomment your API key # OPENAI_API_KEY=your_openai_api_key_here # GEMINI_API_KEY=your_gemini_api_key_here # FIREWORKS_API_KEY=your_fireworks_api_key_here
Hier geben wir Ihnen die Wahl zwischen OpenAI, Gemini oder Fireworks basierend auf dem von Ihnen bereitgestellten API-Schlüssel. Die RAG-Kette ruft die drei relevantesten Dokumente ab und generiert mithilfe des Sprachmodells eine Antwort.
Sie können je nach Budget oder Nutzungspräferenzen zwischen den Modellen wechseln – Gemini und Fireworks sind kostenlos, während OpenAI je nach Nutzung abgerechnet wird.
Jetzt erstellen wir eine einfache Chatbot-Schnittstelle, um Benutzereingaben entgegenzunehmen und mithilfe unserer RAG-Kette Antworten zu generieren.
Erstellen Sie eine neue Datei mit dem Namen chatbot.py:
mkdir rag-chatbot cd rag-chatbot python -m venv venv source venv/bin/activate
Dieses Skript erstellt eine Befehlszeilen-Chatbot-Schnittstelle, die kontinuierlich auf Benutzereingaben wartet, diese über die RAG-Kette verarbeitet und die generierte Antwort zurückgibt.
Es ist an der Zeit, Ihren Chatbot noch benutzerfreundlicher zu gestalten, indem Sie eine Weboberfläche mit Streamlit erstellen. Dadurch können Benutzer über einen Browser mit Ihrem Chatbot interagieren.
App.py erstellen:
langchain==0.0.329 streamlit==1.27.2 faiss-cpu==1.7.4 python-dotenv==1.0.0 tiktoken==0.5.1 openai==0.27.10 gemini==0.3.1 fireworks==0.4.0 sentence_transformers==2.2.2
Um Ihre Streamlit-App auszuführen, verwenden Sie einfach:
pip install -r requirements.txt
Dadurch wird eine Weboberfläche gestartet, über die Sie eine Textdatei hochladen, Fragen stellen und Antworten vom Chatbot erhalten können.
Für eine bessere Leistung können Sie beim Teilen des Texts mit der Blockgröße und der Überlappung experimentieren. Größere Blöcke bieten mehr Kontext, kleinere Blöcke können jedoch den Abruf beschleunigen. Sie können auch Streamlit-Caching verwenden, um die Wiederholung teurer Vorgänge wie das Generieren von Einbettungen zu vermeiden.
Wenn Sie die Kosten optimieren möchten, können Sie je nach Komplexität der Abfrage zwischen OpenAI, Gemini oder Fireworks wechseln – verwenden Sie OpenAI für komplexe Fragen und Zwillinge oder Feuerwerk für einfachere Fragen, um Kosten zu senken.
Herzlichen Glückwunsch! Sie haben erfolgreich Ihren eigenen RAG-basierten Chatbot erstellt. Jetzt sind die Möglichkeiten endlos:
Die Reise beginnt hier und das Potenzial ist grenzenlos!
Sie können meine Arbeit auf GitHub verfolgen. Melden Sie sich gerne bei mir – meine DMs sind immer auf X und LinkedIn geöffnet.
Das obige ist der detaillierte Inhalt vonErstellen Sie Ihren eigenen AI RAG Chatbot: Ein Python-Leitfaden mit LangChain. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welches Plugin ist Composer?
Welches Plugin ist Composer?
 Können Daten zwischen dem Hongmeng-System und dem Android-System interoperabel sein?
Können Daten zwischen dem Hongmeng-System und dem Android-System interoperabel sein?
 So öffnen Sie eine NRG-Datei
So öffnen Sie eine NRG-Datei
 Was macht Matcha Exchange?
Was macht Matcha Exchange?
 So verwenden Sie die datediff-Funktion
So verwenden Sie die datediff-Funktion
 Wie man negative Zahlen binär darstellt
Wie man negative Zahlen binär darstellt
 oncontextmenu-Ereignis
oncontextmenu-Ereignis
 Auf welche Tasten beziehen sich Pfeile in Computern?
Auf welche Tasten beziehen sich Pfeile in Computern?
 WeChat-Momente, zwei Striche und ein Punkt
WeChat-Momente, zwei Striche und ein Punkt








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



