

Bei der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) werden Modelle des maschinellen Lernens verwendet, um mit Text und Sprache zu arbeiten. Das Ziel von NLP ist es, Maschinen beizubringen, gesprochene und geschriebene Wörter zu verstehen. Wenn Sie beispielsweise etwas in Ihr iPhone oder Android-Gerät diktieren und es Ihre Sprache in Text umwandelt, ist das ein NLP-Algorithmus am Werk.
Sie können NLP auch verwenden, um eine Textrezension zu analysieren und vorherzusagen, ob sie positiv oder negativ ist. NLP kann Artikel kategorisieren oder das Genre eines Buches bestimmen. Es kann sogar zur Erstellung maschineller Übersetzer oder Spracherkennungssysteme verwendet werden. In diesen Fällen helfen Klassifizierungsalgorithmen bei der Identifizierung der Sprache. Die meisten NLP-Algorithmen sind Klassifizierungsmodelle, darunter logistische Regression, Naive Bayes, CART (ein Entscheidungsbaummodell), Maximum Entropy (auch im Zusammenhang mit Entscheidungsbäumen) und Hidden-Markov-Modelle (basierend auf Markov-Prozessen).
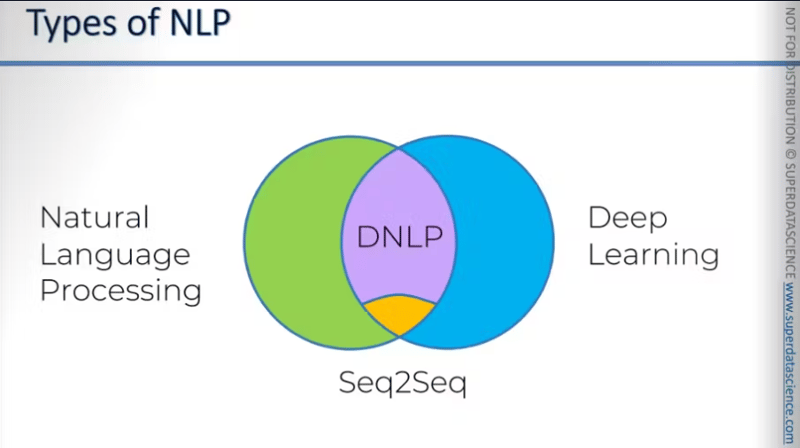
Kleiner Einblick vor dem Start: Auf der linken Seite des Venn-Diagramms steht Grün für NLP. Auf der rechten Seite steht Blau für DL. Im Schnittpunkt haben wir DNLP. Es gibt einen Unterabschnitt von DNLP namens Seq2Seq. Sequence-to-Sequence ist derzeit das modernste und leistungsfähigste Modell für NLP. Allerdings werden wir in diesem Blog nicht auf seq2seq eingehen. Wir werden uns im Wesentlichen mit der Bag-of-Words-Klassifizierung befassen.
In diesem Teil werden Sie Folgendes verstehen und lernen:

Um den vollständigen Blog zu lesen: ML Kapitel 7: Verarbeitung natürlicher Sprache
Das obige ist der detaillierte Inhalt vonML-Kapitel Verarbeitung natürlicher Sprache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 console.readline
console.readline
 So überprüfen Sie, ob Port 445 geschlossen ist
So überprüfen Sie, ob Port 445 geschlossen ist
 Einführung in die Eigenschaften des virtuellen Raums
Einführung in die Eigenschaften des virtuellen Raums
 cmd-Befehl zum Bereinigen von Datenmüll auf Laufwerk C
cmd-Befehl zum Bereinigen von Datenmüll auf Laufwerk C
 Was ist der Unterschied zwischen USB-C und TYPE-C?
Was ist der Unterschied zwischen USB-C und TYPE-C?
 Methode zur Steuerung eines Schrittmotors
Methode zur Steuerung eines Schrittmotors
 Top 30 der globalen digitalen Währungen
Top 30 der globalen digitalen Währungen
 So stellen Sie eine MySQL-Datenbank wieder her
So stellen Sie eine MySQL-Datenbank wieder her








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



