

Eine überraschende Sache an den BigQuery-Daten von PyPI

Sie können Download-Nummern für PyPI-Pakete (oder Projekte) aus einem Google BigQuery-Datensatz erhalten. Sie benötigen ein Google-Konto und Anmeldeinformationen und Google stellt 1 TiB kostenloses Kontingent pro Monat zur Verfügung.
Jeden Monat rufe ich automatisch die Downloadzahlen für die 8.000 beliebtesten Pakete der letzten 30 Tage ab und stelle sie als besser zugängliche JSON- und CSV-Dateien unter „Top PyPI-Pakete“ zur Verfügung. Diese Daten werden häufig für die Forschung in Wissenschaft und Industrie verwendet.
Da jedoch mehr Pakete und Releases auf PyPI hochgeladen werden und immer mehr Downloads protokolliert werden, steigt auch die Menge der abgerechneten Daten.
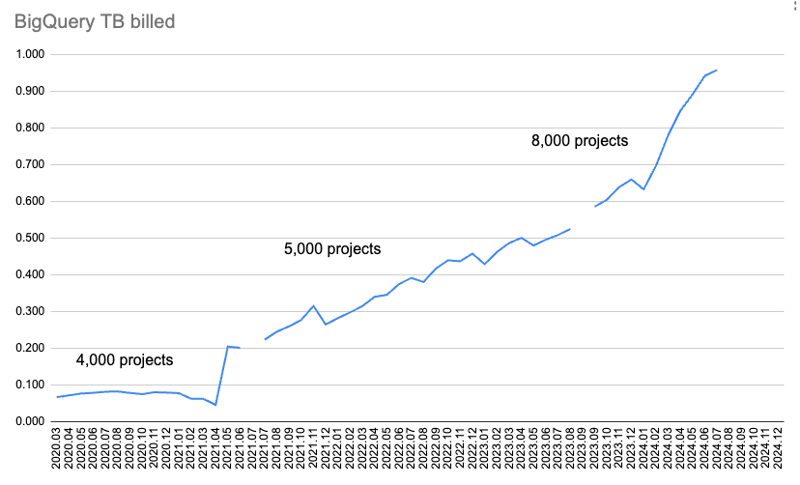
Dieses Diagramm zeigt die pro Monat in Rechnung gestellte Datenmenge.
Zuerst habe ich nur Download-Daten für 4.000 Pakete gesammelt und sie wurden für zwei Abfragen abgerufen: Downloads über 365 Tage und über 30 Tage. Aber mit der Zeit wurde zu viel Kontingent verbraucht, um 365 Tage lang Daten herunterzuladen.
Also habe ich die 365-Tage-Daten verworfen und die 30-Tage-Daten von 4.000 auf 5.000 Pakete erhöht. Später habe ich überprüft, wie viel Kontingent genutzt wurde, und es von 5.000 Paketen auf 8.000 Pakete erhöht.
Aber dann habe ich das monatliche BigQuery-Kontingent von 1 TiB beim Datenabruf für Juli 2024 überschritten.
Um die fehlenden Daten abzurufen und zu untersuchen, was darin vor sich geht, habe ich die 90-tägige kostenlose Testversion von Google Cloud für 300 $ (277,46 €) gestartet ?
Das habe ich gefunden!
Ergebnis: Es kostet mehr, Daten für Downloads nur von pip zu erhalten, als von allen Installern
Ich verwende den Pypinfo-Client, um die Abfrage von BigQuery zu unterstützen. Standardmäßig werden nur Downloads für pip abgerufen.
Nur Pip
Dieser Befehl ruft die Download-Daten eines Tages für die Top-10-Pakete ab, nur für Pip:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
Ergebnisse:
| project | download count |
|---|---|
| boto3 | 37,251,744 |
| aiobotocore | 16,252,824 |
| urllib3 | 16,243,278 |
| botocore | 15,687,125 |
| requests | 13,271,314 |
| s3fs | 12,865,055 |
| s3transfer | 12,014,278 |
| fsspec | 11,982,305 |
| charset-normalizer | 11,684,740 |
| certifi | 11,639,584 |
| Total | 158,892,247 |
Alle Installateure
Durch Hinzufügen des Flags --all werden die Download-Daten eines Tages für die Top-10-Pakete abgerufen, für alle Installer:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
| project | download count |
|---|---|
| boto3 | 39,495,624 |
| botocore | 17,281,187 |
| urllib3 | 17,225,121 |
| aiobotocore | 16,430,826 |
| requests | 14,287,965 |
| s3fs | 12,958,516 |
| charset-normalizer | 12,781,405 |
| certifi | 12,647,098 |
| setuptools | 12,608,120 |
| idna | 12,510,335 |
| Total | 168,226,197 |
Wir sehen also, dass die Standard-Pip-Only-Funktion zusätzliche 25 % der verarbeiteten und in Rechnung gestellten Daten sowie zusätzliche 25 % in Dollar kostet.
Es überrascht nicht, dass die tatsächliche Downloadzahl bei allen Installationsprogrammen höher ist. Die Rangfolge hat sich ein wenig geändert, aber ich gehe davon aus, dass wir in den Top-Tausend-Ergebnissen immer noch mehr oder weniger die gleichen Pakete erhalten.
Abfragen
Es wird eine Abfrage wie diese nur für pip:
an BigQuery gesendet
SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) GROUP BY project ORDER BY download_count DESC LIMIT 10
Und für alle Installateure:
$ pypinfo --all --limit 100 --days 1 "" installer Served from cache: False Data processed: 29.49 GiB Data billed: 29.49 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) GROUP BY project ORDER BY download_count DESC LIMIT 8000
Diese Abfragen sind identisch, außer dass die Standardeinstellung eine zusätzliche UND-Bedingung details.installer.name = „pip“ enthält. Es erscheint vernünftig, dass zusätzliche Filterarbeiten mehr kosten würden.
Installateure
Sehen wir uns die Installationsprogramme an:
| installer name | download count |
|---|---|
| pip | 1,121,198,711 |
| uv | 117,194,833 |
| requests | 29,828,272 |
| poetry | 23,009,454 |
| None | 8,916,745 |
| bandersnatch | 6,171,555 |
| setuptools | 1,362,797 |
| Bazel | 1,280,271 |
| Browser | 1,096,328 |
| Nexus | 593,230 |
| Homebrew | 510,247 |
| Artifactory | 69,063 |
| pdm | 62,904 |
| OS | 13,108 |
| devpi | 9,530 |
| conda | 2,272 |
| pex | 194 |
| Total | 1,311,319,514 |
Pip ist immer noch mit Abstand am beliebtesten, und es überrascht nicht, dass uv mit etwa 10 % der Downloads von Pip auch dort oben liegt.
Die anderen enthalten etwa 25 % oder weniger UV. Bei vielen davon handelt es sich um Spiegelungsdienste, die wir zuvor ausschließen wollten.
Ich denke, angesichts der Bedeutung von UV und meiner Erwartung, dass es weiterhin einen größeren Anteil am Kuchen einnehmen wird, und insbesondere der zusätzlichen Kosten für die Filterung nur nach Pip, sollten wir auf das Abrufen von Daten für alle Downloader umsteigen. Außerdem machen die anderen nicht so viel vom Kuchen aus.
Erkenntnis: Die Anzahl der Pakete hat keinen Einfluss auf die Kosten
Das war die größte Überraschung. Früher hatte ich die Anzahl erhöht oder verringert, um unter der Quote zu bleiben. Aber es stellt sich heraus, dass es keinen Unterschied macht, wie viele Pakete Sie abfragen!
Ich habe Daten für nur einen Tag und alle Installer für verschiedene Paketlimits abgerufen: 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000. Beispielabfrage:
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
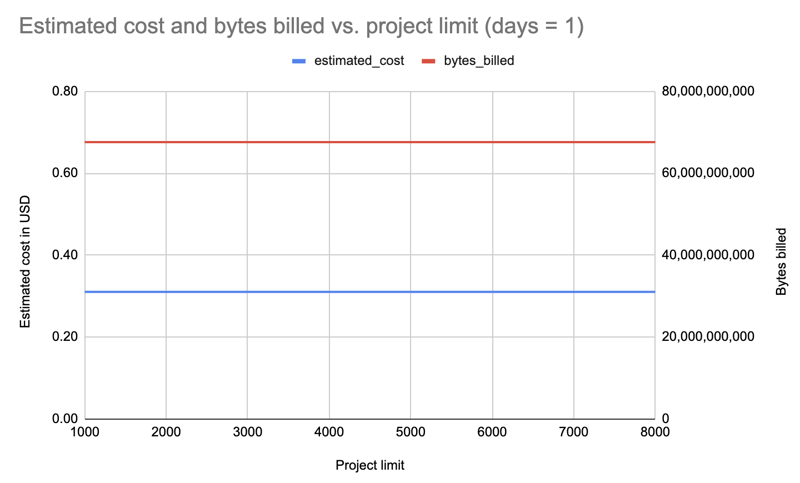
Ergebnis: Interessanterweise sind die Kosten für alle Limits (1000-8000) gleich: 0,31 $.
Wiederholung mit einem Tag, aber nur Filterung nach Pip:
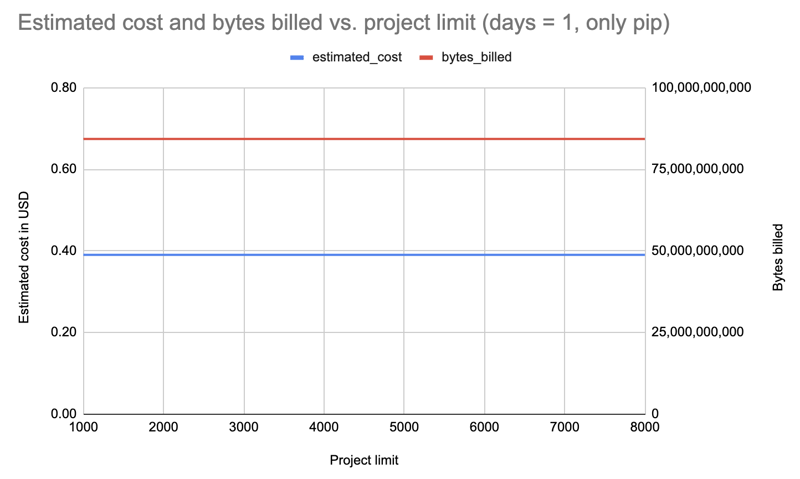
Ergebnis: Die Kosten stiegen auf 0,39 $, blieben aber für alle Limits gleich.
Lass es uns mit allen Installateuren wiederholen, aber 30 Tage lang, und dieses Mal in abnehmenden Grenzen abfragen, für den Fall, dass wir nur für inkrementelle Änderungen zahlen würden: 8000, 7000, 6000, 5000, 4000, 3000, 2000, 1000:
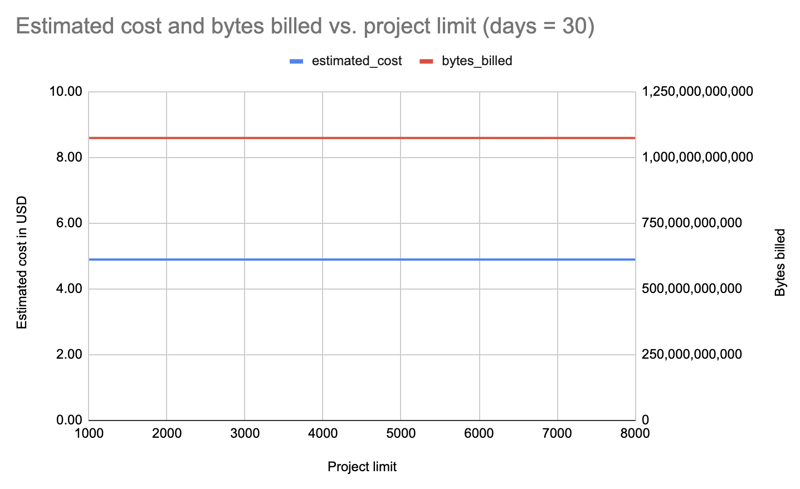
Ergebnis: Auch hier sind die Kosten unabhängig vom Paketlimit gleich: 4,89 $ pro Abfrage.
Na dann wiederholen wir es mit einer um Zehnerpotenzen erhöhten Grenze bis zu 1.000.000! Letzteres ruft Daten für alle 531.022 Pakete auf PyPI ab:
| limit | projects count | estimated cost | bytes billed | bytes processed |
|---|---|---|---|---|
| 1 | 1 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 10 | 10 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 100 | 100 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 1000 | 1,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 8000 | 8,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 10000 | 10,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 100000 | 100,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 1000000 | 531,022 | 0.20 | 43,447,746,560 | 43,447,720,943 |
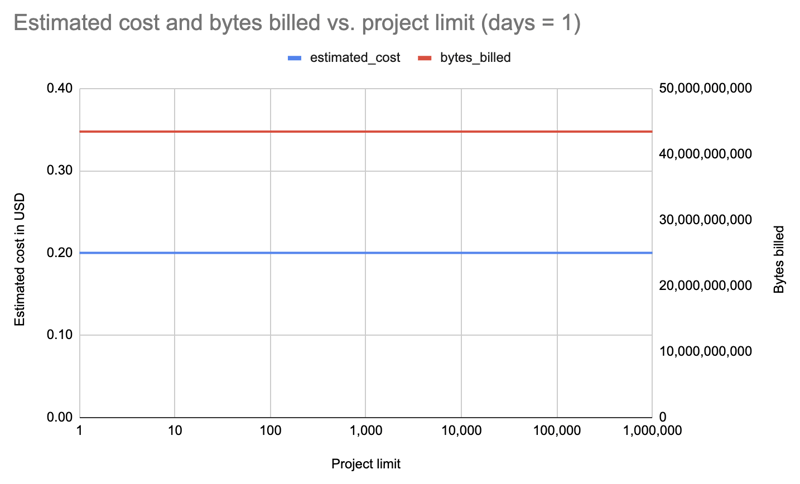
Ergebnis: Wieder die gleichen Kosten, egal ob für 1 Paket oder 531.022 Pakete!
Feststellung: Die Anzahl der Tage beeinflusst die Kosten
Keine Überraschung. Mir war schon früher aufgefallen, dass 365 Tage auch viel Kontingent beanspruchten und ich mit 30 Tagen weitermachen konnte.
Hier sind die geschätzten Kosten und in Rechnung gestellten Bytes (für ein Paket, alle Installer) zwischen einem und 30 Tagen (f"pypinfo --all --json --indent 0 --days {days} --limit 1'' Projekt "), was einen ungefähr linearen Anstieg zeigt:
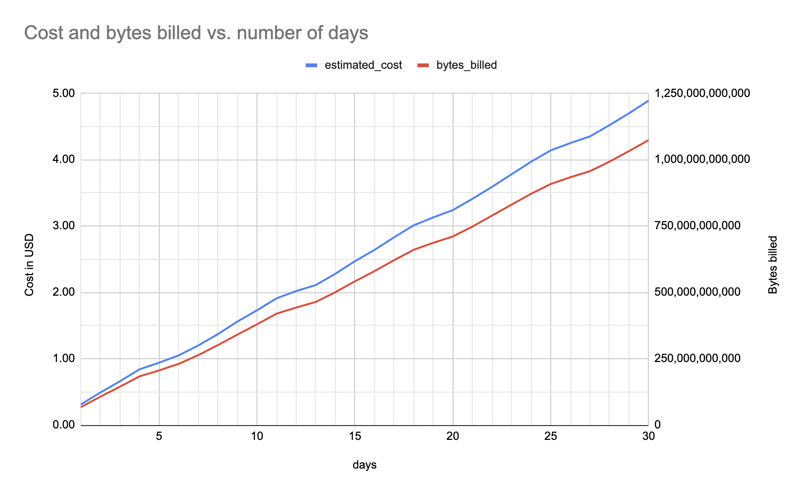
Abschluss
Es spielt keine Rolle, für wie viele Pakete ich Daten abrufe, ich kann genauso gut alle abholen und sie allen zur Verfügung stellen, abhängig von der Größe der Datendatei. Es wird sinnvoll sein, immer noch eine kleinere Datei mit etwa 8.000 Paketen anzubieten: Oft braucht man nur eine größere, aber überschaubare Anzahl.
Es kostet mehr, nur nach Downloads von pip zu filtern, deshalb habe ich auf das Abrufen von Daten für alle Installer umgestellt.
Die Anzahl der Tage wirkt sich auf die Kosten aus, daher muss ich diese in Zukunft verringern, um innerhalb des Kontingents zu bleiben. Beispielsweise kann es sein, dass ich irgendwann von 30 auf 25 Tage und später von 25 auf 20 Tage umstellen muss.
Weitere Details zur Untersuchung, die Skripte und Datendateien finden Sie unter
hugovk/top-pypi-packages#36.
Und lassen Sie mich wissen, wenn Sie Tricks kennen, um die Kosten zu senken!
Headerfoto: „The Balancing Rock, Stonehenge, Near Glen Innes, NSW“ von der Royal Australian Historical Society, ohne bekannte Urheberrechtsbeschränkungen.
Das obige ist der detaillierte Inhalt vonEine überraschende Sache an den BigQuery-Daten von PyPI. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1672
1672
 14
1428
52
1333
25
1277
29
1257
24
14
1428
52
1333
25
1277
29
1257
24

 Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python ist leichter zu lernen und zu verwenden, während C leistungsfähiger, aber komplexer ist. 1. Python -Syntax ist prägnant und für Anfänger geeignet. Durch die dynamische Tippen und die automatische Speicherverwaltung können Sie die Verwendung einfach zu verwenden, kann jedoch zur Laufzeitfehler führen. 2.C bietet Steuerung und erweiterte Funktionen auf niedrigem Niveau, geeignet für Hochleistungsanwendungen, hat jedoch einen hohen Lernschwellenwert und erfordert manuellem Speicher und Typensicherheitsmanagement.
 Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Ist es genug, um Python für zwei Stunden am Tag zu lernen? Es hängt von Ihren Zielen und Lernmethoden ab. 1) Entwickeln Sie einen klaren Lernplan, 2) Wählen Sie geeignete Lernressourcen und -methoden aus, 3) praktizieren und prüfen und konsolidieren Sie praktische Praxis und Überprüfung und konsolidieren Sie und Sie können die Grundkenntnisse und die erweiterten Funktionen von Python während dieser Zeit nach und nach beherrschen.
 Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python ist in der Entwicklungseffizienz besser als C, aber C ist in der Ausführungsleistung höher. 1. Pythons prägnante Syntax und reiche Bibliotheken verbessern die Entwicklungseffizienz. 2. Die Kompilierungsmerkmale von Compilation und die Hardwarekontrolle verbessern die Ausführungsleistung. Bei einer Auswahl müssen Sie die Entwicklungsgeschwindigkeit und die Ausführungseffizienz basierend auf den Projektanforderungen abwägen.
 Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python und C haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1) Python ist aufgrund seiner prägnanten Syntax und der dynamischen Typisierung für die schnelle Entwicklung und Datenverarbeitung geeignet. 2) C ist aufgrund seiner statischen Tipp- und manuellen Speicherverwaltung für hohe Leistung und Systemprogrammierung geeignet.
 Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
PythonlistsarePartThestandardlibrary, whilearraysarenot.listarebuilt-in, vielseitig und UNDUSEDFORSPORINGECollections, während dieArrayRay-thearrayModulei und loses und loses und losesaluseduetolimitedFunctionality.
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python für wissenschaftliches Computer: Ein detailliertes Aussehen
Apr 19, 2025 am 12:15 AM
Python für wissenschaftliches Computer: Ein detailliertes Aussehen
Apr 19, 2025 am 12:15 AM
Zu den Anwendungen von Python im wissenschaftlichen Computer gehören Datenanalyse, maschinelles Lernen, numerische Simulation und Visualisierung. 1.Numpy bietet effiziente mehrdimensionale Arrays und mathematische Funktionen. 2. Scipy erweitert die Numpy -Funktionalität und bietet Optimierungs- und lineare Algebra -Tools. 3.. Pandas wird zur Datenverarbeitung und -analyse verwendet. 4.Matplotlib wird verwendet, um verschiedene Grafiken und visuelle Ergebnisse zu erzeugen.
 Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Zu den wichtigsten Anwendungen von Python in der Webentwicklung gehören die Verwendung von Django- und Flask -Frameworks, API -Entwicklung, Datenanalyse und Visualisierung, maschinelles Lernen und KI sowie Leistungsoptimierung. 1. Django und Flask Framework: Django eignet sich für die schnelle Entwicklung komplexer Anwendungen, und Flask eignet sich für kleine oder hochmobile Projekte. 2. API -Entwicklung: Verwenden Sie Flask oder Djangorestframework, um RESTFUFFUPI zu erstellen. 3. Datenanalyse und Visualisierung: Verwenden Sie Python, um Daten zu verarbeiten und über die Webschnittstelle anzuzeigen. 4. Maschinelles Lernen und KI: Python wird verwendet, um intelligente Webanwendungen zu erstellen. 5. Leistungsoptimierung: optimiert durch asynchrones Programmieren, Caching und Code
