

Segmentierung ist eine grundlegende Technik in der Bildanalyse, die es uns ermöglicht, ein Bild basierend auf Objekten, Formen oder Farben in sinnvolle Teile zu unterteilen. Es spielt eine zentrale Rolle bei Anwendungen wie Objekterkennung, Computer Vision und sogar künstlerischer Bildmanipulation. Aber wie können wir eine Segmentierung effektiv erreichen? Glücklicherweise bietet OpenCV (cv2) mehrere benutzerfreundliche und leistungsstarke Methoden zur Segmentierung.
In diesem Tutorial erkunden wir drei beliebte Segmentierungstechniken:
Um dieses Tutorial ansprechend und praktisch zu gestalten, verwenden wir Satelliten- und Luftbilder aus Osaka, Japan, mit Schwerpunkt auf den alten Kofun-Grabhügeln. Sie können diese Bilder und das entsprechende Beispielnotizbuch von der GitHub-Seite des Tutorials herunterladen.
Canny Edge Detection ist eine unkomplizierte und dennoch leistungsstarke Methode zur Identifizierung von Kanten in einem Bild. Es erkennt Bereiche mit schnellen Intensitätsänderungen, bei denen es sich häufig um Objektgrenzen handelt. Diese Technik erzeugt „dünne Kanten“-Konturen durch Anwendung von Intensitätsschwellenwerten. Lassen Sie uns in die Implementierung mit OpenCV eintauchen.
Beispiel: Erkennen von Kanten in einem Satellitenbild
Hier verwenden wir als Testfall ein Satellitenbild von Osaka, insbesondere eines Kofun-Grabhügels.
import cv2
import numpy as np
import matplotlib.pyplot as plt
files = sorted(glob("SAT*.png")) #Get png files
print(len(files))
img=cv2.imread(files[0])
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
#Stadard values
min_val = 100
max_val = 200
# Apply Canny Edge Detection
edges = cv2.Canny(gray, min_val, max_val)
#edges = cv2.Canny(gray, min_val, max_val,apertureSize=5,L2gradient = True )
False
# Show the result
plt.figure(figsize=(15, 5))
plt.subplot(131), plt.imshow(cv2.cvtColor(use_image, cv2.COLOR_BGR2RGB))
plt.title('Original Image'), plt.axis('off')
plt.subplot(132), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image'), plt.axis('off')
plt.subplot(133), plt.imshow(edges, cmap='gray')
plt.title('Canny Edges'), plt.axis('off')
plt.show()

Die Ausgabekanten umreißen deutlich Teile des Kofun-Grabhügels und andere interessante Regionen. Aufgrund der scharfen Schwellenwerte werden jedoch einige Bereiche übersehen. Die Ergebnisse hängen stark von der Wahl von min_val und max_val sowie der Bildqualität ab.
Um die Kantenerkennung zu verbessern, können wir das Bild vorverarbeiten, um die Pixelintensitäten zu verteilen und das Rauschen zu reduzieren. Dies kann durch Histogrammausgleich (cv2.equalizeHist()) und Gaußsche Unschärfe (cv2.GaussianBlur()) erreicht werden.
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
gray_og = gray.copy()
gray = cv2.equalizeHist(gray)
gray = cv2.GaussianBlur(gray, (9, 9),1)
plt.figure(figsize=(15, 5))
plt.subplot(121), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image')
plt.subplot(122)
_= plt.hist(gray.ravel(), 256, [0,256],label="Equalized")
_ = plt.hist(gray_og.ravel(), 256, [0,256],label="Original",histtype='step')
plt.legend()
plt.title('Grayscale Histogram')
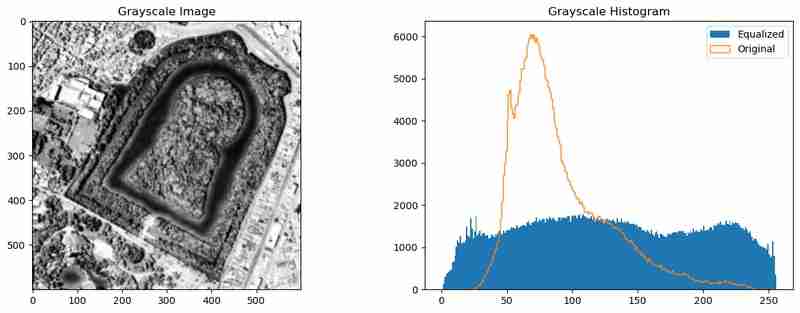
Diese Vorverarbeitung gleicht die Intensitätsverteilung aus und glättet das Bild, wodurch der Canny Edge Detection-Algorithmus aussagekräftigere Kanten erfassen kann.
Kanten sind nützlich, aber sie zeigen nur Grenzen an. Um umschlossene Flächen zu segmentieren, wandeln wir Kanten in Konturen um und visualisieren diese.
# Edges to contours
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Calculate contour areas
areas = [cv2.contourArea(contour) for contour in contours]
# Normalize areas for the colormap
normalized_areas = np.array(areas)
if normalized_areas.max() > 0:
normalized_areas = normalized_areas / normalized_areas.max()
# Create a colormap
cmap = plt.cm.jet
# Plot the contours with the color map
plt.figure(figsize=(10, 10))
plt.subplot(1,2,1)
plt.imshow(gray, cmap='gray', alpha=0.5) # Display the grayscale image in the background
mask = np.zeros_like(use_image)
for contour, norm_area in zip(contours, normalized_areas):
color = cmap(norm_area) # Map the normalized area to a color
color = [int(c*255) for c in color[:3]]
cv2.drawContours(mask, [contour], -1, color,-1 ) # Draw contours on the image
plt.subplot(1,2,2)
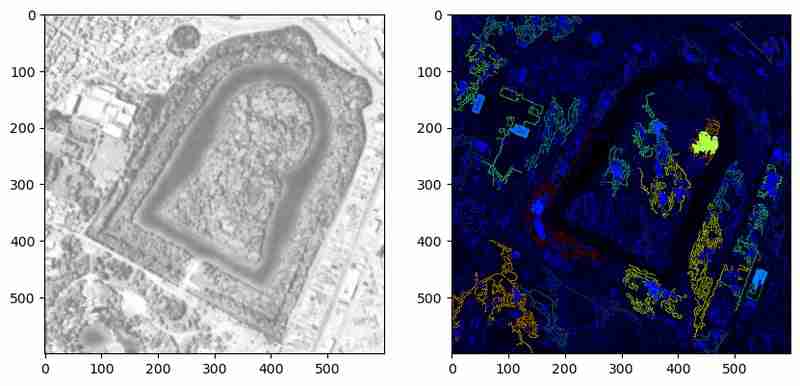
Die obige Methode hebt erkannte Konturen mit Farben hervor, die ihre relativen Bereiche darstellen. Diese Visualisierung hilft zu überprüfen, ob die Konturen geschlossene Körper oder nur Linien bilden. In diesem Beispiel bleiben jedoch viele Konturen ungeschlossene Polygone. Eine weitere Vorverarbeitung oder Parameteroptimierung könnte diese Einschränkungen beheben.
Durch die Kombination von Vorverarbeitung und Konturanalyse wird Canny Edge Detection zu einem leistungsstarken Werkzeug zur Identifizierung von Objektgrenzen in Bildern. Es funktioniert jedoch am besten, wenn die Objekte klar definiert sind und das Rauschen minimal ist. Als Nächstes untersuchen wir K-Means-Clustering, um das Bild nach Farbe zu segmentieren und so eine andere Perspektive auf dieselben Daten zu bieten.
K-Means-Clustering ist eine beliebte Methode in der Datenwissenschaft, um ähnliche Elemente in Clustern zu gruppieren, und sie ist besonders effektiv für die Segmentierung von Bildern basierend auf Farbähnlichkeit. Die cv2.kmeans-Funktion von OpenCV vereinfacht diesen Prozess und macht ihn für Aufgaben wie Objektsegmentierung, Hintergrundentfernung oder visuelle Analyse zugänglich.
In diesem Abschnitt verwenden wir K-Means-Clustering, um das Bild des Kofun-Grabhügels in Regionen mit ähnlichen Farben zu segmentieren.
Zunächst wenden wir K-Means-Clustering auf die RGB-Werte des Bildes an und behandeln jedes Pixel als Datenpunkt.
import cv2
import numpy as np
import matplotlib.pyplot as plt
files = sorted(glob("SAT*.png")) #Get png files
print(len(files))
img=cv2.imread(files[0])
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
#Stadard values
min_val = 100
max_val = 200
# Apply Canny Edge Detection
edges = cv2.Canny(gray, min_val, max_val)
#edges = cv2.Canny(gray, min_val, max_val,apertureSize=5,L2gradient = True )
False
# Show the result
plt.figure(figsize=(15, 5))
plt.subplot(131), plt.imshow(cv2.cvtColor(use_image, cv2.COLOR_BGR2RGB))
plt.title('Original Image'), plt.axis('off')
plt.subplot(132), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image'), plt.axis('off')
plt.subplot(133), plt.imshow(edges, cmap='gray')
plt.title('Canny Edges'), plt.axis('off')
plt.show()

Im segmentierten Bild sind der Grabhügel und die umliegenden Regionen in verschiedenen Farben gruppiert. Allerdings führen Rauschen und kleine Farbabweichungen zu fragmentierten Clustern, was die Interpretation erschweren kann.
Um Rauschen zu reduzieren und glattere Cluster zu erzeugen, können wir vor der Ausführung von K-Means eine mittlere Unschärfe anwenden.
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
gray_og = gray.copy()
gray = cv2.equalizeHist(gray)
gray = cv2.GaussianBlur(gray, (9, 9),1)
plt.figure(figsize=(15, 5))
plt.subplot(121), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image')
plt.subplot(122)
_= plt.hist(gray.ravel(), 256, [0,256],label="Equalized")
_ = plt.hist(gray_og.ravel(), 256, [0,256],label="Original",histtype='step')
plt.legend()
plt.title('Grayscale Histogram')

Das unscharfe Bild führt zu glatteren Clustern, wodurch das Rauschen reduziert und die segmentierten Bereiche optisch zusammenhängender werden.
Um die Segmentierungsergebnisse besser zu verstehen, können wir mit matplotlib plt.fill_between;
eine Farbkarte der eindeutigen Clusterfarben erstellen
# Edges to contours
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Calculate contour areas
areas = [cv2.contourArea(contour) for contour in contours]
# Normalize areas for the colormap
normalized_areas = np.array(areas)
if normalized_areas.max() > 0:
normalized_areas = normalized_areas / normalized_areas.max()
# Create a colormap
cmap = plt.cm.jet
# Plot the contours with the color map
plt.figure(figsize=(10, 10))
plt.subplot(1,2,1)
plt.imshow(gray, cmap='gray', alpha=0.5) # Display the grayscale image in the background
mask = np.zeros_like(use_image)
for contour, norm_area in zip(contours, normalized_areas):
color = cmap(norm_area) # Map the normalized area to a color
color = [int(c*255) for c in color[:3]]
cv2.drawContours(mask, [contour], -1, color,-1 ) # Draw contours on the image
plt.subplot(1,2,2)

Diese Visualisierung bietet Einblick in die dominanten Farben im Bild und ihre entsprechenden RGB-Werte, die für die weitere Analyse nützlich sein können. Da wir jetzt meinen Farbcode maskieren und auswählen können.
Die Anzahl der Cluster (K) hat erheblichen Einfluss auf die Ergebnisse. Eine Erhöhung von K führt zu einer detaillierteren Segmentierung, während niedrigere Werte zu breiteren Gruppierungen führen. Zum Experimentieren können wir über mehrere K-Werte iterieren.
import cv2
import numpy as np
import matplotlib.pyplot as plt
files = sorted(glob("SAT*.png")) #Get png files
print(len(files))
img=cv2.imread(files[0])
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
#Stadard values
min_val = 100
max_val = 200
# Apply Canny Edge Detection
edges = cv2.Canny(gray, min_val, max_val)
#edges = cv2.Canny(gray, min_val, max_val,apertureSize=5,L2gradient = True )
False
# Show the result
plt.figure(figsize=(15, 5))
plt.subplot(131), plt.imshow(cv2.cvtColor(use_image, cv2.COLOR_BGR2RGB))
plt.title('Original Image'), plt.axis('off')
plt.subplot(132), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image'), plt.axis('off')
plt.subplot(133), plt.imshow(edges, cmap='gray')
plt.title('Canny Edges'), plt.axis('off')
plt.show()

Die Clustering-Ergebnisse für verschiedene K-Werte zeigen einen Kompromiss zwischen Detail und Einfachheit:
・Niedrigere K-Werte (z. B. 2-3): Breite Cluster mit klaren Unterscheidungen, geeignet für eine Segmentierung auf hoher Ebene.
・Höhere K-Werte (z. B. 12–15): Detailliertere Segmentierung, jedoch auf Kosten erhöhter Komplexität und potenzieller Übersegmentierung.
K-Means Clustering ist eine leistungsstarke Technik zur Segmentierung von Bildern basierend auf Farbähnlichkeit. Mit den richtigen Vorverarbeitungsschritten entstehen klare und aussagekräftige Regionen. Seine Leistung hängt jedoch von der Wahl von K, der Qualität des Eingabebildes und der angewandten Vorverarbeitung ab. Als Nächstes untersuchen wir den Watershed-Algorithmus, der topografische Merkmale verwendet, um eine präzise Segmentierung von Objekten und Regionen zu erreichen.
Der Wassereinzugsgebietsalgorithmus ist von topografischen Karten inspiriert, in denen Wassereinzugsgebiete Einzugsgebiete trennen. Bei dieser Methode werden Graustufen-Intensitätswerte als Höhenwerte behandelt, wodurch effektiv „Spitzen“ und „Täler“ erzeugt werden. Durch die Identifizierung von interessierenden Bereichen kann der Algorithmus Objekte mit präzisen Grenzen segmentieren. Es ist besonders nützlich, um überlappende Objekte zu trennen, was es zu einer großartigen Wahl für komplexe Szenarien wie Zellsegmentierung, Objekterkennung und Unterscheidung dicht gepackter Merkmale macht.
Der erste Schritt ist die Vorverarbeitung des Bildes, um die Funktionen zu verbessern, gefolgt von der Anwendung des Watershed-Algorithmus.
use_image= img[0:600,700:1300]
gray = cv2.cvtColor(use_image, cv2.COLOR_BGR2GRAY)
gray_og = gray.copy()
gray = cv2.equalizeHist(gray)
gray = cv2.GaussianBlur(gray, (9, 9),1)
plt.figure(figsize=(15, 5))
plt.subplot(121), plt.imshow(gray, cmap='gray')
plt.title('Grayscale Image')
plt.subplot(122)
_= plt.hist(gray.ravel(), 256, [0,256],label="Equalized")
_ = plt.hist(gray_og.ravel(), 256, [0,256],label="Original",histtype='step')
plt.legend()
plt.title('Grayscale Histogram')
Die segmentierten Regionen und Grenzen können zusammen mit Zwischenverarbeitungsschritten visualisiert werden.

# Edges to contours
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Calculate contour areas
areas = [cv2.contourArea(contour) for contour in contours]
# Normalize areas for the colormap
normalized_areas = np.array(areas)
if normalized_areas.max() > 0:
normalized_areas = normalized_areas / normalized_areas.max()
# Create a colormap
cmap = plt.cm.jet
# Plot the contours with the color map
plt.figure(figsize=(10, 10))
plt.subplot(1,2,1)
plt.imshow(gray, cmap='gray', alpha=0.5) # Display the grayscale image in the background
mask = np.zeros_like(use_image)
for contour, norm_area in zip(contours, normalized_areas):
color = cmap(norm_area) # Map the normalized area to a color
color = [int(c*255) for c in color[:3]]
cv2.drawContours(mask, [contour], -1, color,-1 ) # Draw contours on the image
plt.subplot(1,2,2)
Der Algorithmus identifiziert erfolgreich unterschiedliche Regionen und zieht klare Grenzen um Objekte herum. In diesem Beispiel ist der Kofun-Grabhügel genau segmentiert. Die Leistung des Algorithmus hängt jedoch stark von Vorverarbeitungsschritten wie Schwellenwertbildung, Rauschentfernung und morphologischen Operationen ab.
Das Hinzufügen einer erweiterten Vorverarbeitung, wie z. B. Histogrammausgleich oder adaptive Unschärfe, kann die Ergebnisse weiter verbessern. Zum Beispiel:
# Kmean color segmentation
use_image= img[0:600,700:1300]
#use_image = cv2.medianBlur(use_image, 15)
# Reshape image for k-means
pixel_values = use_image.reshape((-1, 3)) if len(use_image.shape) == 3 else use_image.reshape((-1, 1))
pixel_values = np.float32(pixel_values)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 3
attempts=10
ret,label,center=cv2.kmeans(pixel_values,K,None,criteria,attempts,cv2.KMEANS_PP_CENTERS)
centers = np.uint8(center)
segmented_data = centers[label.flatten()]
segmented_image = segmented_data.reshape(use_image.shape)
plt.figure(figsize=(10, 6))
plt.subplot(1,2,1),plt.imshow(use_image[:,:,::-1])
plt.title("RGB View")
plt.subplot(1,2,2),plt.imshow(segmented_image[:,:,[2,1,0]])
plt.title(f"Kmean Segmented Image K={K}")

Mit diesen Anpassungen können mehr Regionen genau segmentiert und Rauschartefakte minimiert werden.
Der Watershed-Algorithmus eignet sich hervorragend für Szenarien, die eine präzise Grenzabgrenzung und Trennung überlappender Objekte erfordern. Durch die Nutzung von Vorverarbeitungstechniken können selbst komplexe Bilder wie die Region des Kofun-Grabhügels effektiv verarbeitet werden. Der Erfolg hängt jedoch von einer sorgfältigen Parameterabstimmung und Vorverarbeitung ab.
Segmentierung ist ein wesentliches Werkzeug in der Bildanalyse und bietet einen Weg, verschiedene Elemente innerhalb eines Bildes zu isolieren und zu verstehen. In diesem Tutorial wurden drei leistungsstarke Segmentierungstechniken vorgestellt – Canny Edge Detection, K-Means Clustering und Watershed-Algorithmus –, die jeweils auf bestimmte Anwendungen zugeschnitten sind. Von der Umrisszeichnung der alten Kofun-Grabhügel in Osaka bis hin zur Gruppierung städtischer Landschaften und der Trennung verschiedener Regionen unterstreichen diese Methoden die Vielseitigkeit von OpenCV bei der Bewältigung realer Herausforderungen.
Jetzt wenden Sie einige dieser Methoden auf eine Anwendung Ihrer Wahl an, kommentieren und teilen Sie die Ergebnisse. Auch wenn Sie andere einfache Segmentierungsmethoden kennen, teilen Sie diese bitte mit
Das obige ist der detaillierte Inhalt von[Python-CVImage-Segmentierung: Canny Edges-, Watershed- und K-Means-Methoden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



