

Vor jeder Funktionsveröffentlichung führe ich Benutzerakzeptanztests („UAT“) durch, um Fehler aufzudecken und sicherzustellen, dass die Geschäftslogik korrekt in Code übersetzt wird.
Ich gebe eine Funktion erst dann zur Veröffentlichung frei, wenn UAT 100 % erfolgreich ist.
Meine Argumentation ist einfach: Sie haben nur eine Chance, beim Endbenutzer einen guten ersten Eindruck zu hinterlassen, und eine schlechte Veröffentlichung macht es doppelt schwierig.

Obwohl es sich hierbei um eine MVP-Funktion handelt, die nicht für die Produktionsveröffentlichung gedacht ist, dachte ich, es wäre gut, ein wenig UAT durchzuführen, um meine Fähigkeiten auf dem neuesten Stand zu halten.
Von den 19 UAT-Szenarien, die ich mir ausgedacht habe, scheiterte eines an einer Änderung in der PDF-Vorlage Depotbankerklärung.
Ich habe dieses Risiko während der Discovery vorhergesehen, aber um ehrlich zu sein, habe ich nicht damit gerechnet, dass das Problem so bald auftauchen würde.
Ich werde später im Artikel auf die Details zur Fehlerbehebung eingehen.
Mein UAT-Prozess beinhaltet die Verwendung der Geschäftslogik oder der Funktionsanforderungen als Referenz, um Testszenarien und erwartete Ergebnisse zu erstellen.
Testszenarien müssen nicht kompliziert sein. Sie können so einfach sein wie: „Die Funktion generiert innerhalb von 30 Sekunden eine CSV-Datei.“
Für die UAT habe ich 71 Seiten Dokumente aus 10 Depotbankauszugs-PDFs verarbeitet. Dies sollte ein ausreichend großer Probensatz sein.
Die erwartete Ausgabe besteht aus drei CSV-Dateien mit spezifischen Datenpunkten aus den Abschnitten Fondsbestände, Wertpapierbestände und Barmittelbestände des Depotbankauszugs-PDFs.
Ich habe mir folgende Testfälle ausgedacht:
CSV 1: Fondsbestände
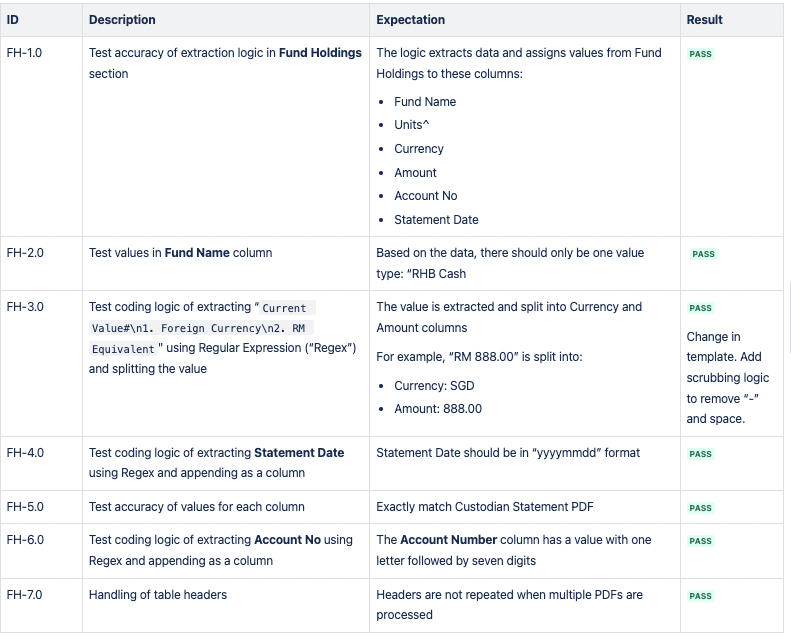
CSV 2: Wertpapierbestände
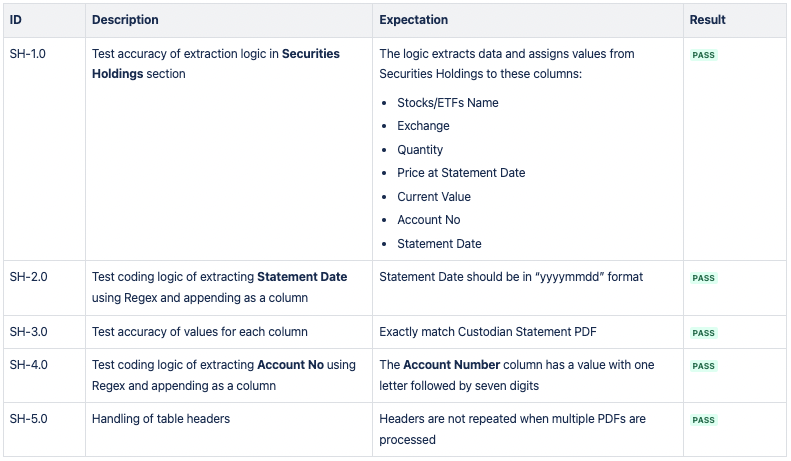
CSV 3: Bargeldbestände

Der einzige fehlgeschlagene Test war darauf zurückzuführen, dass sich die Vorlage der PDF-Datei mit der Depotbankerklärung im November geringfügig geändert hat. Genauer gesagt haben die Werte in der Spalte „Aktueller Wert# 1. Fremdwährung 2. RM-Äquivalent“ einer Fondsbestandstabelle jetzt ein zusätzliches „-n“-Präfix.
Anstatt beispielsweise „10.000 USD“ in früheren PDFs zu lesen, lautet der Wert jetzt „- 10.000 USD“.
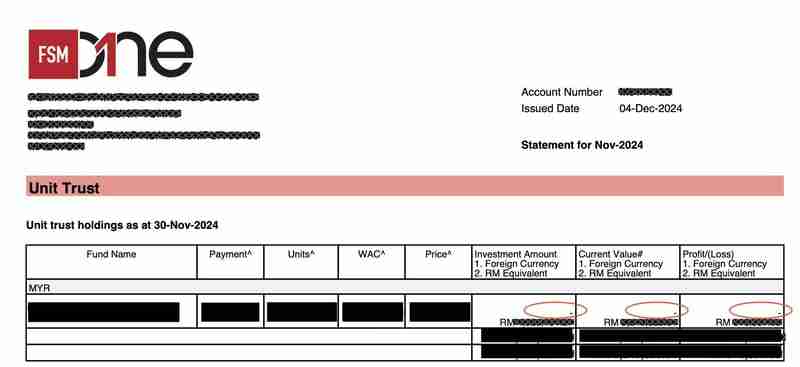
Diese kleine Änderung führte zu folgendem Problem:

Ich habe ChatGPT bezüglich einer Lösung konsultiert und es wurde empfohlen, die folgende Scrubbing-Logik hinzuzufügen, um das falsche „-/n“-Präfix zu entfernen.
# Scrub error prefix
df['Currency'] = df['Currency'].str.replace('[-\n]', '', regex=True)
Das Bereinigen hat seinen Zweck erfüllt und die CSV-Ausgabe der Fondsbestände sieht jetzt wie erwartet aus.
Ich bin jetzt sicher, dass der Code zum Extrahieren von PDF-Daten funktioniert. Allerdings glaube ich nicht, dass eine CSV-Datei der beste Ort zum Speichern all dieser Daten ist.
Obwohl CSV (für mich) benutzerfreundlich ist, erleichtert das Speichern von Daten in einer Datenbank das Abrufen und Bearbeiten von Daten gemäß den Anforderungen des Endbenutzers erheblich.
Ich habe nur sehr begrenzte Erfahrung mit Datenbanken. Was ich also als Nächstes tun werde, ist Discovery für eine Datenbankanwendung, die ich schnell integrieren kann.
--Ende
Das obige ist der detaillierte Inhalt von# | Automatisieren Sie die PDF-Datenextraktion: Benutzerakzeptanztests. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist eine 3c-Zertifizierung?
Was ist eine 3c-Zertifizierung?
 So integrieren Sie Ideen in Tomcat
So integrieren Sie Ideen in Tomcat
 Welche Arten von Lasso-Werkzeugen gibt es in PS?
Welche Arten von Lasso-Werkzeugen gibt es in PS?
 Rangliste der Kryptowährungs-Handelsplattformen
Rangliste der Kryptowährungs-Handelsplattformen
 Eigenschaften der Zweierkomplementarithmetik
Eigenschaften der Zweierkomplementarithmetik
 So erhalten Sie eine URL-Adresse
So erhalten Sie eine URL-Adresse
 Java-Online-Website
Java-Online-Website
 Welche Server gibt es im Web?
Welche Server gibt es im Web?
 So nutzen Sie digitale Währungen
So nutzen Sie digitale Währungen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



