

Erstellen eines Schachagenten mit DQN

Ich habe kürzlich versucht, einen DQN-basierten Schachagenten zu implementieren.
Nun, jeder, der weiß, wie DQNs und Schach funktionieren, würde Ihnen sagen, dass das eine dumme Idee ist.
Und...das war es, aber als Anfänger hat es mir trotzdem Spaß gemacht. In diesem Artikel teile ich die Erkenntnisse, die ich bei der Arbeit daran gewonnen habe.
Die Umwelt verstehen.
Bevor ich mit der Implementierung des Agenten selbst begann, musste ich mich mit der Umgebung, die ich verwenden werde, vertraut machen und darüber einen benutzerdefinierten Wrapper erstellen, damit er während des Trainings mit dem Agenten interagieren kann.
-
Ich habe die Schachumgebung aus der Bibliothek kaggle_environments verwendet.
from kaggle_environments import make env = make("chess", debug=True)Nach dem Login kopierenNach dem Login kopieren
-
Ich habe auch Chessnut verwendet, eine leichte Python-Bibliothek, die beim Analysieren und Validieren von Schachpartien hilft.
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
Nach dem Login kopierenNach dem Login kopieren
In dieser Umgebung wird der Zustand der Platine im FEN-Format gespeichert.

Es bietet eine kompakte Möglichkeit, alle Figuren auf dem Brett und den aktuell aktiven Spieler darzustellen. Da ich jedoch vorhatte, die Eingabe einem neuronalen Netzwerk zuzuführen, musste ich die Darstellung des Zustands ändern.
Konvertieren von FEN in das Matrixformat
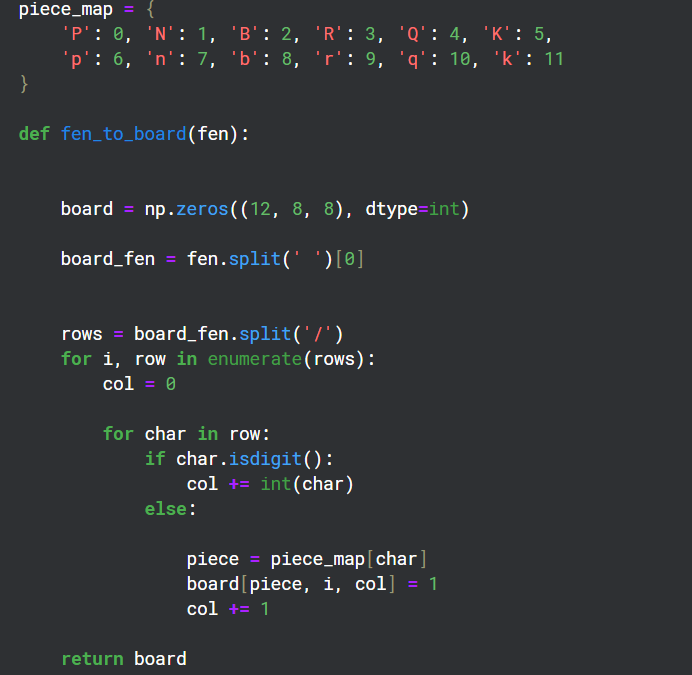
Da es 12 verschiedene Arten von Teilen auf einem Brett gibt, habe ich 12 Kanäle mit 8x8-Rastern erstellt, um den Zustand jedes dieser Arten auf dem Brett darzustellen.
Einen Wrapper für die Umwelt erstellen
class EnvCust:
def __init__(self):
self.env = make("chess", debug=True)
self.game=Game(env.state[0]['observation']['board'])
print(self.env.state[0]['observation']['board'])
self.action_space=game.get_moves();
self.obs_space=(self.env.state[0]['observation']['board'])
def get_action(self):
return Game(self.env.state[0]['observation']['board']).get_moves();
def get_obs_space(self):
return fen_to_board(self.env.state[0]['observation']['board'])
def step(self,action):
reward=0
g=Game(self.env.state[0]['observation']['board']);
if(g.board.get_piece(Game.xy2i(action[2:4]))=='q'):
reward=7
elif g.board.get_piece(Game.xy2i(action[2:4]))=='n' or g.board.get_piece(Game.xy2i(action[2:4]))=='b' or g.board.get_piece(Game.xy2i(action[2:4]))=='r':
reward=4
elif g.board.get_piece(Game.xy2i(action[2:4]))=='P':
reward=2
g=Game(self.env.state[0]['observation']['board']);
g.apply_move(action)
done=False
if(g.status==2):
done=True
reward=10
elif g.status == 1:
done = True
reward = -5
self.env.step([action,'None'])
self.action_space=list(self.get_action())
if(self.action_space==[]):
done=True
else:
self.env.step(['None',random.choice(self.action_space)])
g=Game(self.env.state[0]['observation']['board']);
if g.status==2:
reward=-10
done=True
self.action_space=list(self.get_action())
return self.env.state[0]['observation']['board'],reward,done
Der Zweck dieses Wrappers bestand darin, eine Belohnungsrichtlinie für den Agenten und eine Schrittfunktion bereitzustellen, die zur Interaktion mit der Umgebung während des Trainings verwendet wird.
Chessnut war nützlich, um Informationen zu erhalten, wie z. B. die legalen Züge, die zum aktuellen Stand des Bretts möglich sind, und um Schachmatts während des Spiels zu erkennen.
Ich habe versucht, eine Belohnungsrichtlinie zu erstellen, um positive Punkte für Schachmatt und das Ausschalten gegnerischer Figuren zu vergeben, während negative Punkte für das Verlieren des Spiels vergeben werden.
Erstellen eines Wiedergabepuffers
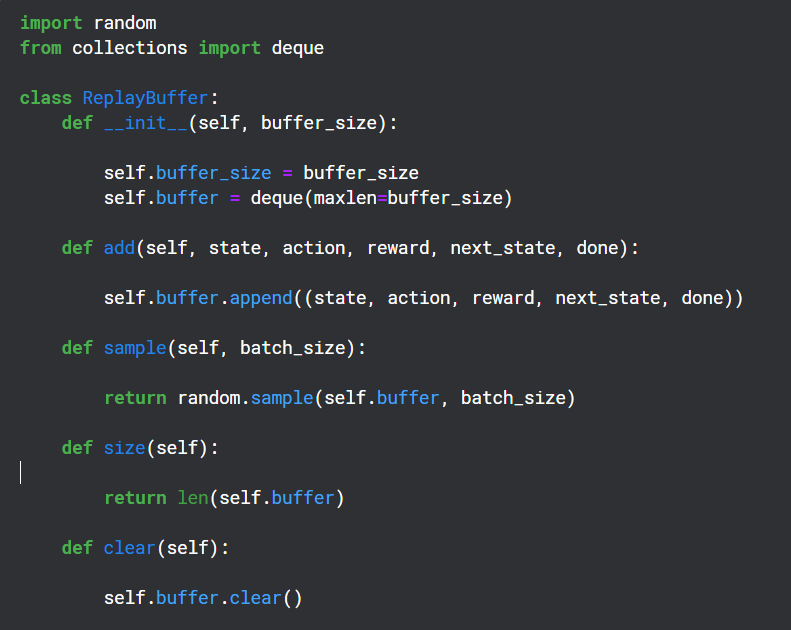
Wiederholungspuffer wird während des Trainingszeitraums verwendet, um die Ausgabe (Zustand, Aktion, Belohnung, nächster Zustand) des Q-Netzwerks zu speichern und später zufällig für die Backpropagation des Zielnetzwerks zu verwenden
Hilfsfunktionen


Chessnut gibt rechtliche Schritte im UCI-Format zurück, das wie „a2a3“ aussieht. Um jedoch mit dem neuronalen Netzwerk zu interagieren, habe ich jede Aktion mithilfe eines Grundmusters in einen eigenen Index umgewandelt. Es gibt insgesamt 64 Quadrate, daher habe ich beschlossen, für jede Bewegung 64*64 eindeutige Indizes zu verwenden.
Ich weiß, dass nicht alle 64*64-Züge legal wären, aber mit Chessnut konnte ich mit der Legalität umgehen und das Muster war einfach genug.
Struktur des neuronalen Netzwerks
from kaggle_environments import make
env = make("chess", debug=True)
Dieses neuronale Netzwerk verwendet die Faltungsschichten, um die 12-Kanal-Eingabe aufzunehmen, und verwendet außerdem die gültigen Aktionsindizes, um die Belohnungsausgabevorhersage herauszufiltern.
Implementierung des Agenten
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
Dies war offensichtlich ein sehr einfaches Modell, das keine Chance hatte, tatsächlich eine gute Leistung zu erbringen (und das tat es auch nicht), aber es hat mir geholfen, die Funktionsweise von DQNs etwas besser zu verstehen.

Das obige ist der detaillierte Inhalt vonErstellen eines Schachagenten mit DQN. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1652
1652
 14
1413
52
1304
25
1251
29
1224
24
14
1413
52
1304
25
1251
29
1224
24

 Python vs. C: Anwendungen und Anwendungsfälle verglichen
Apr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichen
Apr 12, 2025 am 12:01 AM
Python eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Wie viel Python können Sie in 2 Stunden lernen?
Apr 09, 2025 pm 04:33 PM
Wie viel Python können Sie in 2 Stunden lernen?
Apr 09, 2025 pm 04:33 PM
Sie können die Grundlagen von Python innerhalb von zwei Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master -Steuerungsstrukturen wie wenn Aussagen und Schleifen, 3. Verstehen Sie die Definition und Verwendung von Funktionen. Diese werden Ihnen helfen, einfache Python -Programme zu schreiben.
 Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.
 Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Sie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python ist leichter zu lernen und zu verwenden, während C leistungsfähiger, aber komplexer ist. 1. Python -Syntax ist prägnant und für Anfänger geeignet. Durch die dynamische Tippen und die automatische Speicherverwaltung können Sie die Verwendung einfach zu verwenden, kann jedoch zur Laufzeitfehler führen. 2.C bietet Steuerung und erweiterte Funktionen auf niedrigem Niveau, geeignet für Hochleistungsanwendungen, hat jedoch einen hohen Lernschwellenwert und erfordert manuellem Speicher und Typensicherheitsmanagement.
 Python: Erforschen der primären Anwendungen
Apr 10, 2025 am 09:41 AM
Python: Erforschen der primären Anwendungen
Apr 10, 2025 am 09:41 AM
Python wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Python: Die Kraft der vielseitigen Programmierung
Apr 17, 2025 am 12:09 AM
Python: Die Kraft der vielseitigen Programmierung
Apr 17, 2025 am 12:09 AM
Python ist für seine Einfachheit und Kraft sehr beliebt, geeignet für alle Anforderungen von Anfängern bis hin zu fortgeschrittenen Entwicklern. Seine Vielseitigkeit spiegelt sich in: 1) leicht zu erlernen und benutzten, einfachen Syntax; 2) Reiche Bibliotheken und Frameworks wie Numpy, Pandas usw.; 3) plattformübergreifende Unterstützung, die auf einer Vielzahl von Betriebssystemen betrieben werden kann; 4) Geeignet für Skript- und Automatisierungsaufgaben zur Verbesserung der Arbeitseffizienz.
