
 Backend-Entwicklung
Python-Tutorial
Automatisierung der Bereitstellung von Flask und PostgreSQL auf KVM mit Terraform und Ansible
Backend-Entwicklung
Python-Tutorial
Automatisierung der Bereitstellung von Flask und PostgreSQL auf KVM mit Terraform und Ansible
Automatisierung der Bereitstellung von Flask und PostgreSQL auf KVM mit Terraform und Ansible

? Einführung
Hallo, in diesem Beitrag werden wir Libvirt mit Terraform verwenden, um 2 KVM lokal bereitzustellen, und danach werden wir Flask App und PostgreSQL mit Ansible bereitstellen.
Inhalt
- Projektarchitektur
- Anforderungen
- KVM erstellen
-
Erstellen Sie ein Ansible-Playbook
- Playbook zur Installation von Docker
- Playbook zum Installieren und Konfigurieren von Postgresql
- Playbook zum Bereitstellen der Flask-App
- Playbook ausführen und testen
- Fazit
? Projektarchitektur
Also erstellen wir zwei VMs mit Terraform und stellen dann ein Flask-Projekt und die Datenbank mit Ansible bereit.
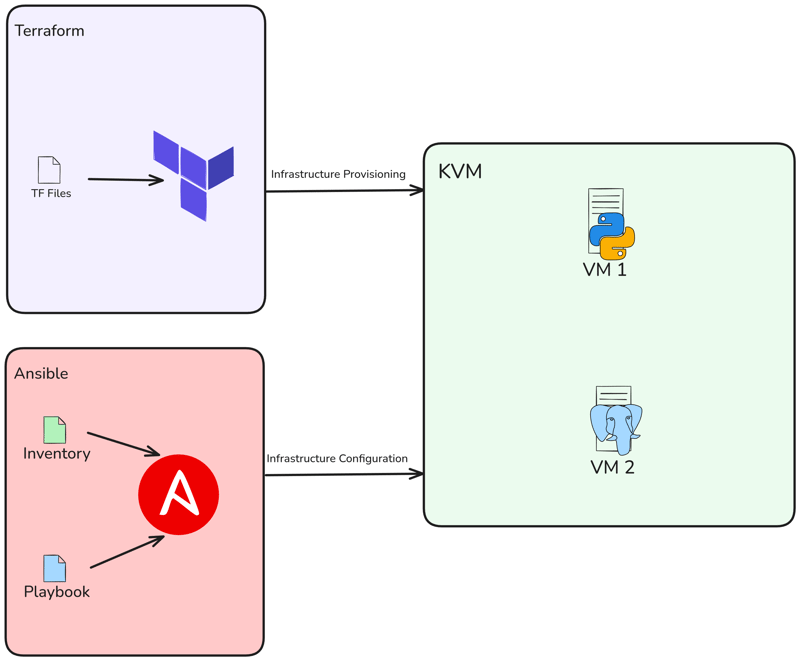
? Anforderungen
Ich habe Ubuntu 22.04 LTS als Betriebssystem für dieses Projekt verwendet. Wenn Sie ein anderes Betriebssystem verwenden, nehmen Sie bitte bei der Installation der erforderlichen Abhängigkeiten die erforderlichen Anpassungen vor.
Die wichtigste Voraussetzung für dieses Setup ist ein KVM-Hypervisor. Sie müssen also KVM in Ihrem System installieren. Wenn Sie Ubuntu verwenden, können Sie diesen Schritt ausführen:
sudo apt -y install bridge-utils cpu-checker libvirt-clients libvirt-daemon qemu qemu-kvm
Führen Sie den folgenden Befehl aus, um sicherzustellen, dass Ihr Prozessor Virtualisierungsfunktionen unterstützt:
$ kvm-ok INFO: /dev/kvm exists KVM acceleration can be used
Installieren Sie Terraform
$ wget -O - https://apt.releases.hashicorp.com/gpg | sudo gpg --dearmor -o /usr/share/keyrings/hashicorp-archive-keyring.gpg $ echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list $ sudo apt update && sudo apt install terraform -y
Installation überprüfen:
$ terraform version Terraform v1.9.8 on linux_amd64
Installieren Sie Ansible
$ sudo apt update $ sudo apt install software-properties-common $ sudo add-apt-repository --yes --update ppa:ansible/ansible $ sudo apt install ansible -y
Installation überprüfen:
$ ansible --version ansible [core 2.15.1] ...
KVM erstellen
Wir werden den libvirt-Anbieter mit Terraform verwenden, um eine virtuelle KVM-Maschine bereitzustellen.
Erstellen Sie main.tf, geben Sie einfach den Anbieter und die Version an, die Sie verwenden möchten:
terraform {
required_providers {
libvirt = {
source = "dmacvicar/libvirt"
version = "0.8.1"
}
}
}
provider "libvirt" {
uri = "qemu:///system"
}
Führen Sie anschließend den Befehl terraform init aus, um die Umgebung zu initialisieren:
$ terraform init Initializing the backend... Initializing provider plugins... - Reusing previous version of hashicorp/template from the dependency lock file - Reusing previous version of dmacvicar/libvirt from the dependency lock file - Reusing previous version of hashicorp/null from the dependency lock file - Using previously-installed hashicorp/template v2.2.0 - Using previously-installed dmacvicar/libvirt v0.8.1 - Using previously-installed hashicorp/null v3.2.3 Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.
Erstellen Sie nun unsere Variables.tf. Diese Variable.tf-Datei definiert Eingaben für den libvirt-Datenträgerpoolpfad, die Ubuntu 20.04-Image-URL als Betriebssystem für die VMs und eine Liste von VM-Hostnamen.
variable "libvirt_disk_path" {
description = "path for libvirt pool"
default = "default"
}
variable "ubuntu_20_img_url" {
description = "ubuntu 20.04 image"
default = "https://cloud-images.ubuntu.com/releases/focal/release/ubuntu-20.04-server-cloudimg-amd64.img"
}
variable "vm_hostnames" {
description = "List of VM hostnames"
default = ["vm1", "vm2"]
}
Lassen Sie uns unsere main.tf aktualisieren:
resource "null_resource" "cache_image" {
provisioner "local-exec" {
command = "wget -O /tmp/ubuntu-20.04.qcow2 ${var.ubuntu_20_img_url}"
}
}
resource "libvirt_volume" "base" {
name = "base.qcow2"
source = "/tmp/ubuntu-20.04.qcow2"
pool = var.libvirt_disk_path
format = "qcow2"
depends_on = [null_resource.cache_image]
}
# Volume for VM with size 10GB
resource "libvirt_volume" "ubuntu20-qcow2" {
count = length(var.vm_hostnames)
name = "ubuntu20-${count.index}.qcow2"
base_volume_id = libvirt_volume.base.id
pool = var.libvirt_disk_path
size = 10737418240 # 10GB
}
data "template_file" "user_data" {
count = length(var.vm_hostnames)
template = file("${path.module}/config/cloud_init.yml")
}
data "template_file" "network_config" {
count = length(var.vm_hostnames)
template = file("${path.module}/config/network_config.yml")
}
resource "libvirt_cloudinit_disk" "commoninit" {
count = length(var.vm_hostnames)
name = "commoninit-${count.index}.iso"
user_data = data.template_file.user_data[count.index].rendered
network_config = data.template_file.network_config[count.index].rendered
pool = var.libvirt_disk_path
}
resource "libvirt_domain" "domain-ubuntu" {
count = length(var.vm_hostnames)
name = var.vm_hostnames[count.index]
memory = "1024" # VM memory
vcpu = 1 # VM CPU
cloudinit = libvirt_cloudinit_disk.commoninit[count.index].id
network_interface {
network_name = "default"
wait_for_lease = true
hostname = var.vm_hostnames[count.index]
}
console {
type = "pty"
target_port = "0"
target_type = "serial"
}
console {
type = "pty"
target_type = "virtio"
target_port = "1"
}
disk {
volume_id = libvirt_volume.ubuntu20-qcow2[count.index].id
}
graphics {
type = "spice"
listen_type = "address"
autoport = true
}
}
Das Skript stellt mehrere KVM-VMs mithilfe des Libvirt-Anbieters bereit. Es lädt ein Ubuntu 20.04-Basisimage herunter, klont es für jede VM, konfiguriert Cloud-Init für Benutzer- und Netzwerkeinstellungen und stellt VMs mit angegebenen Hostnamen, 1 GB Speicher und SPICE-Grafiken bereit. Das Setup passt sich dynamisch an die Anzahl der in var.vm_hostnames.
angegebenen Hostnamen anWie ich bereits erwähnt habe, verwende ich Cloud-Init. Richten wir also die Netzwerkkonfiguration und Cloud-Init im Konfigurationsverzeichnis ein:
mkdir config/
Dann erstellen Sie unsere config/cloud_init.yml. Stellen Sie nur sicher, dass Sie Ihren öffentlichen SSH-Schlüssel für den SSH-Zugriff in der Konfiguration konfigurieren:
#cloud-config
runcmd:
- sed -i '/PermitRootLogin/d' /etc/ssh/sshd_config
- echo "PermitRootLogin yes" >> /etc/ssh/sshd_config
- systemctl restart sshd
ssh_pwauth: true
disable_root: false
chpasswd:
list: |
root:cloudy24
expire: false
users:
- name: ubuntu
gecos: ubuntu
groups:
- sudo
sudo:
- ALL=(ALL) NOPASSWD:ALL
home: /home/ubuntu
shell: /bin/bash
lock_passwd: false
ssh_authorized_keys:
- ssh-rsa AAAA...
Und dann Netzwerkkonfiguration, in config/network_config.yml:
version: 2
ethernets:
ens3:
dhcp4: true
Unsere Projektstruktur sollte so aussehen:
sudo apt -y install bridge-utils cpu-checker libvirt-clients libvirt-daemon qemu qemu-kvm
Erstellen Sie nun einen Plan, um zu sehen, was getan werden soll:
$ kvm-ok INFO: /dev/kvm exists KVM acceleration can be used
Und führen Sie terraform apply aus, um unsere Bereitstellung auszuführen:
$ wget -O - https://apt.releases.hashicorp.com/gpg | sudo gpg --dearmor -o /usr/share/keyrings/hashicorp-archive-keyring.gpg $ echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list $ sudo apt update && sudo apt install terraform -y
Überprüfen Sie die VM-Erstellung mit dem virsh-Befehl:
$ terraform version Terraform v1.9.8 on linux_amd64
Instanzen-IP-Adresse abrufen:
$ sudo apt update $ sudo apt install software-properties-common $ sudo add-apt-repository --yes --update ppa:ansible/ansible $ sudo apt install ansible -y
Versuchen Sie, mit dem Ubuntu-Benutzer:
auf die VM zuzugreifen
$ ansible --version ansible [core 2.15.1] ...
Erstellen Sie ein Ansible-Playbook
Jetzt erstellen wir das Ansible Playbook, um Flask und Postgresql auf Docker bereitzustellen. Zuerst müssen Sie ein Ansible-Verzeichnis und eine Ansible.cfg-Datei erstellen:
terraform {
required_providers {
libvirt = {
source = "dmacvicar/libvirt"
version = "0.8.1"
}
}
}
provider "libvirt" {
uri = "qemu:///system"
}
$ terraform init Initializing the backend... Initializing provider plugins... - Reusing previous version of hashicorp/template from the dependency lock file - Reusing previous version of dmacvicar/libvirt from the dependency lock file - Reusing previous version of hashicorp/null from the dependency lock file - Using previously-installed hashicorp/template v2.2.0 - Using previously-installed dmacvicar/libvirt v0.8.1 - Using previously-installed hashicorp/null v3.2.3 Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.
Dann erstellen Sie eine Inventardatei namens hosts:
variable "libvirt_disk_path" {
description = "path for libvirt pool"
default = "default"
}
variable "ubuntu_20_img_url" {
description = "ubuntu 20.04 image"
default = "https://cloud-images.ubuntu.com/releases/focal/release/ubuntu-20.04-server-cloudimg-amd64.img"
}
variable "vm_hostnames" {
description = "List of VM hostnames"
default = ["vm1", "vm2"]
}
Überprüfen unserer VMs mit dem Ansible-Ping-Befehl:
resource "null_resource" "cache_image" {
provisioner "local-exec" {
command = "wget -O /tmp/ubuntu-20.04.qcow2 ${var.ubuntu_20_img_url}"
}
}
resource "libvirt_volume" "base" {
name = "base.qcow2"
source = "/tmp/ubuntu-20.04.qcow2"
pool = var.libvirt_disk_path
format = "qcow2"
depends_on = [null_resource.cache_image]
}
# Volume for VM with size 10GB
resource "libvirt_volume" "ubuntu20-qcow2" {
count = length(var.vm_hostnames)
name = "ubuntu20-${count.index}.qcow2"
base_volume_id = libvirt_volume.base.id
pool = var.libvirt_disk_path
size = 10737418240 # 10GB
}
data "template_file" "user_data" {
count = length(var.vm_hostnames)
template = file("${path.module}/config/cloud_init.yml")
}
data "template_file" "network_config" {
count = length(var.vm_hostnames)
template = file("${path.module}/config/network_config.yml")
}
resource "libvirt_cloudinit_disk" "commoninit" {
count = length(var.vm_hostnames)
name = "commoninit-${count.index}.iso"
user_data = data.template_file.user_data[count.index].rendered
network_config = data.template_file.network_config[count.index].rendered
pool = var.libvirt_disk_path
}
resource "libvirt_domain" "domain-ubuntu" {
count = length(var.vm_hostnames)
name = var.vm_hostnames[count.index]
memory = "1024" # VM memory
vcpu = 1 # VM CPU
cloudinit = libvirt_cloudinit_disk.commoninit[count.index].id
network_interface {
network_name = "default"
wait_for_lease = true
hostname = var.vm_hostnames[count.index]
}
console {
type = "pty"
target_port = "0"
target_type = "serial"
}
console {
type = "pty"
target_type = "virtio"
target_port = "1"
}
disk {
volume_id = libvirt_volume.ubuntu20-qcow2[count.index].id
}
graphics {
type = "spice"
listen_type = "address"
autoport = true
}
}
Erstellen Sie nun playbook.yml und Rollen. Dieses Playbook installiert und konfiguriert Docker, Flask und PostgreSQL:
mkdir config/
Playbook zur Installation von Docker
Erstellen Sie nun ein neues Verzeichnis mit dem Namen „roles/docker:“
#cloud-config
runcmd:
- sed -i '/PermitRootLogin/d' /etc/ssh/sshd_config
- echo "PermitRootLogin yes" >> /etc/ssh/sshd_config
- systemctl restart sshd
ssh_pwauth: true
disable_root: false
chpasswd:
list: |
root:cloudy24
expire: false
users:
- name: ubuntu
gecos: ubuntu
groups:
- sudo
sudo:
- ALL=(ALL) NOPASSWD:ALL
home: /home/ubuntu
shell: /bin/bash
lock_passwd: false
ssh_authorized_keys:
- ssh-rsa AAAA...
Erstellen Sie im Docker ein neues Verzeichnis mit dem Namen „Tasks“ und erstellen Sie dann die neue Datei „main.yml“. Diese Datei installiert Docker und Docker Compose:
version: 2
ethernets:
ens3:
dhcp4: true
$ tree . ├── config │ ├── cloud_init.yml │ └── network_config.yml ├── main.tf └── variables.tf
Playbook zum Installieren und Konfigurieren von Postgresql
Dann erstellen Sie ein neues Verzeichnis mit dem Namen psql und ein Unterverzeichnis mit dem Namen vars, tempalates & task:
$ terraform plan data.template_file.user_data[1]: Reading... data.template_file.user_data[0]: Reading... data.template_file.network_config[1]: Reading... data.template_file.network_config[0]: Reading... ... Plan: 8 to add, 0 to change, 0 to destroy
Danach erstellen Sie in vars main.yml. Dies sind Variablen, die zum Festlegen von Benutzernamen, Passwörtern usw. verwendet werden:
$ terraform apply ... null_resource.cache_image: Creation complete after 10m36s [id=4239391010009470471] libvirt_volume.base: Creating... libvirt_volume.base: Creation complete after 3s [id=/var/lib/libvirt/images/base.qcow2] libvirt_volume.ubuntu20-qcow2[1]: Creating... libvirt_volume.ubuntu20-qcow2[0]: Creating... libvirt_volume.ubuntu20-qcow2[1]: Creation complete after 0s [id=/var/lib/libvirt/images/ubuntu20-1.qcow2] libvirt_volume.ubuntu20-qcow2[0]: Creation complete after 0s [id=/var/lib/libvirt/images/ubuntu20-0.qcow2] libvirt_domain.domain-ubuntu[1]: Creating... ... libvirt_domain.domain-ubuntu[1]: Creation complete after 51s [id=6221f782-48b7-49a4-9eb9-fc92970f06a2] Apply complete! Resources: 8 added, 0 changed, 0 destroyed
Als nächstes erstellen wir eine Jinja-Datei mit dem Namen docker-compose.yml.j2. Mit dieser Datei erstellen wir einen Postgresql-Container:
$ virsh list Id Name State ---------------------- 1 vm1 running 2 vm2 running
Als nächstes erstellen Sie main.yml für Aufgaben. Also kopieren wir docker-compose.yml.j2 und führen es mit docker compose:
aus
$ virsh net-dhcp-leases --network default Expiry Time MAC address Protocol IP address Hostname Client ID or DUID ----------------------------------------------------------------------------------------------------------------------------------------------- 2024-12-09 19:50:00 52:54:00:2e:0e:86 ipv4 192.168.122.19/24 vm1 ff:b5:5e:67:ff:00:02:00:00:ab:11:b0:43:6a:d8:bc:16:30:0d 2024-12-09 19:50:00 52:54:00:86:d4:ca ipv4 192.168.122.15/24 vm2 ff:b5:5e:67:ff:00:02:00:00:ab:11:39:24:8c:4a:7e:6a:dd:78
Playbook zum Bereitstellen der Flask-App
Zuerst müssen Sie ein Verzeichnis namens flask erstellen und dann erneut ein Unterverzeichnis erstellen:
$ ssh ubuntu@192.168.122.15 The authenticity of host '192.168.122.15 (192.168.122.15)' can't be established. ED25519 key fingerprint is SHA256:Y20zaCcrlOZvPTP+/qLLHc7vJIOca7QjTinsz9Bj6sk. This key is not known by any other names Are you sure you want to continue connecting (yes/no/[fingerprint])? yes Warning: Permanently added '192.168.122.15' (ED25519) to the list of known hosts. Welcome to Ubuntu 20.04.6 LTS (GNU/Linux 5.4.0-200-generic x86_64) ... ubuntu@ubuntu:~$
Als nächstes fügen Sie main.yml zu vars hinzu. Diese Datei bezieht sich zuvor auf die Variable posgtresql, mit zusätzlicher IP-Adresse von VM2 (Datenbank-VM):
$ mkdir ansible && cd ansible
Als nächstes erstellen Sie config.py.j2 für Vorlagen. Diese Datei ersetzt die alte Konfigurationsdatei aus dem Flask-Projekt:
[defaults] inventory = hosts host_key_checking = True deprecation_warnings = False collections = ansible.posix, community.general, community.postgresql
Als nächstes erstellen Sie docker-compose.yml.j2 für Vorlagen. Mit dieser Datei erstellen wir einen Container mit Docker Compose:
[vm1] 192.168.122.19 ansible_user=ubuntu [vm2] 192.168.122.15 ansible_user=ubuntu
Als nächstes erstellen Sie main.yml in Aufgaben. Mit dieser Datei klonen wir das Flask-Projekt, fügen eine Compose-Datei hinzu, ersetzen config.py und erstellen einen neuen Container mit Docker Compose:
$ ansible -m ping all
192.168.122.15 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
192.168.122.19 | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
Unsere Projektstruktur sollte so aussehen:
---
- name: Deploy Flask
hosts: vm1
become: true
remote_user: ubuntu
roles:
- flask
- config
- name: Deploy Postgresql
hosts: vm2
become: true
remote_user: ubuntu
roles:
- psql
- config
Führen Sie Playbook aus und testen Sie es
Lassen Sie uns abschließend Ansible-Playbook ausführen, um PostgreSQL und Flask bereitzustellen:
$ mkdir roles $ mkdir docker
Stellen Sie nach Abschluss sicher, dass kein Fehler vorliegt. Dann sehen Sie, dass zwei erstellt wurden. In VM1 ist Flask und in VM2 ist Postgresql:
sudo apt -y install bridge-utils cpu-checker libvirt-clients libvirt-daemon qemu qemu-kvm
Versuchen Sie, über Browser auf die App zuzugreifen. Geben Sie einfach http://

Versuchen Sie, eine neue Aufgabe hinzuzufügen und dann werden die Daten zur Datenbank hinzugefügt:

Abschluss
Abschließend vielen Dank, dass Sie diesen Artikel gelesen haben. Hinterlassen Sie gerne einen Kommentar, wenn Sie Fragen, Anregungen oder Feedback haben.
Hinweis: Projekt-Repo: danielcristho/that-i-write
Das obige ist der detaillierte Inhalt vonAutomatisierung der Bereitstellung von Flask und PostgreSQL auf KVM mit Terraform und Ansible. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python vs. C: Lernkurven und Benutzerfreundlichkeit
Apr 19, 2025 am 12:20 AM
Python ist leichter zu lernen und zu verwenden, während C leistungsfähiger, aber komplexer ist. 1. Python -Syntax ist prägnant und für Anfänger geeignet. Durch die dynamische Tippen und die automatische Speicherverwaltung können Sie die Verwendung einfach zu verwenden, kann jedoch zur Laufzeitfehler führen. 2.C bietet Steuerung und erweiterte Funktionen auf niedrigem Niveau, geeignet für Hochleistungsanwendungen, hat jedoch einen hohen Lernschwellenwert und erfordert manuellem Speicher und Typensicherheitsmanagement.
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python vs. C: Erforschung von Leistung und Effizienz erforschen
Apr 18, 2025 am 12:20 AM
Python ist in der Entwicklungseffizienz besser als C, aber C ist in der Ausführungsleistung höher. 1. Pythons prägnante Syntax und reiche Bibliotheken verbessern die Entwicklungseffizienz. 2. Die Kompilierungsmerkmale von Compilation und die Hardwarekontrolle verbessern die Ausführungsleistung. Bei einer Auswahl müssen Sie die Entwicklungsgeschwindigkeit und die Ausführungseffizienz basierend auf den Projektanforderungen abwägen.
 Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Python lernen: Ist 2 Stunden tägliches Studium ausreichend?
Apr 18, 2025 am 12:22 AM
Ist es genug, um Python für zwei Stunden am Tag zu lernen? Es hängt von Ihren Zielen und Lernmethoden ab. 1) Entwickeln Sie einen klaren Lernplan, 2) Wählen Sie geeignete Lernressourcen und -methoden aus, 3) praktizieren und prüfen und konsolidieren Sie praktische Praxis und Überprüfung und konsolidieren Sie und Sie können die Grundkenntnisse und die erweiterten Funktionen von Python während dieser Zeit nach und nach beherrschen.
 Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python vs. C: Verständnis der wichtigsten Unterschiede
Apr 21, 2025 am 12:18 AM
Python und C haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1) Python ist aufgrund seiner prägnanten Syntax und der dynamischen Typisierung für die schnelle Entwicklung und Datenverarbeitung geeignet. 2) C ist aufgrund seiner statischen Tipp- und manuellen Speicherverwaltung für hohe Leistung und Systemprogrammierung geeignet.
 Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
Welches ist Teil der Python Standard Library: Listen oder Arrays?
Apr 27, 2025 am 12:03 AM
PythonlistsarePartThestandardlibrary, whilearraysarenot.listarebuilt-in, vielseitig und UNDUSEDFORSPORINGECollections, während dieArrayRay-thearrayModulei und loses und loses und losesaluseduetolimitedFunctionality.
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Python für die Webentwicklung: Schlüsselanwendungen
Apr 18, 2025 am 12:20 AM
Zu den wichtigsten Anwendungen von Python in der Webentwicklung gehören die Verwendung von Django- und Flask -Frameworks, API -Entwicklung, Datenanalyse und Visualisierung, maschinelles Lernen und KI sowie Leistungsoptimierung. 1. Django und Flask Framework: Django eignet sich für die schnelle Entwicklung komplexer Anwendungen, und Flask eignet sich für kleine oder hochmobile Projekte. 2. API -Entwicklung: Verwenden Sie Flask oder Djangorestframework, um RESTFUFFUPI zu erstellen. 3. Datenanalyse und Visualisierung: Verwenden Sie Python, um Daten zu verarbeiten und über die Webschnittstelle anzuzeigen. 4. Maschinelles Lernen und KI: Python wird verwendet, um intelligente Webanwendungen zu erstellen. 5. Leistungsoptimierung: optimiert durch asynchrones Programmieren, Caching und Code
