
 Backend-Entwicklung
Python-Tutorial
IRIS-RAG-Gen: Personalisierung der ChatGPT RAG-Anwendung, unterstützt von IRIS Vector Search
Backend-Entwicklung
Python-Tutorial
IRIS-RAG-Gen: Personalisierung der ChatGPT RAG-Anwendung, unterstützt von IRIS Vector Search
IRIS-RAG-Gen: Personalisierung der ChatGPT RAG-Anwendung, unterstützt von IRIS Vector Search

Hallo Community,
In diesem Artikel werde ich meine Anwendung vorstellen iris-RAG-Gen .
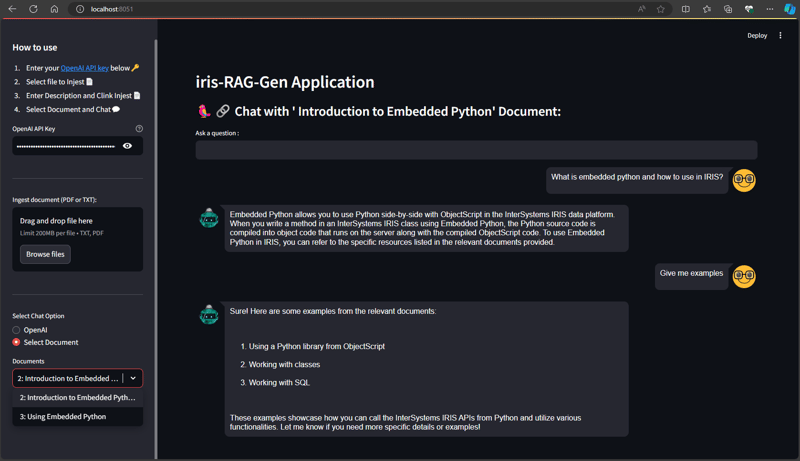
Iris-RAG-Gen ist eine generative AI Retrieval-Augmented Generation (RAG)-Anwendung, die die Funktionalität von IRIS Vector Search nutzt, um ChatGPT mithilfe des Streamlit-Webframeworks, LangChain und OpenAI zu personalisieren. Die Anwendung verwendet IRIS als Vektorspeicher.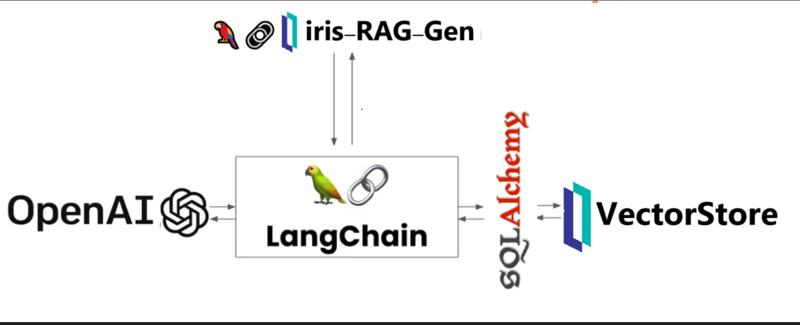
Anwendungsfunktionen
- Dokumente (PDF oder TXT) in IRIS aufnehmen
- Chatten Sie mit dem ausgewählten aufgenommenen Dokument
- Eingenommene Dokumente löschen
- OpenAI ChatGPT
Dokumente (PDF oder TXT) in IRIS aufnehmen
Befolgen Sie die folgenden Schritte, um das Dokument aufzunehmen:
- OpenAI-Schlüssel eingeben
- Dokument auswählen (PDF oder TXT)
- Dokumentbeschreibung eingeben
- Klicken Sie auf die Schaltfläche „Dokument aufnehmen“
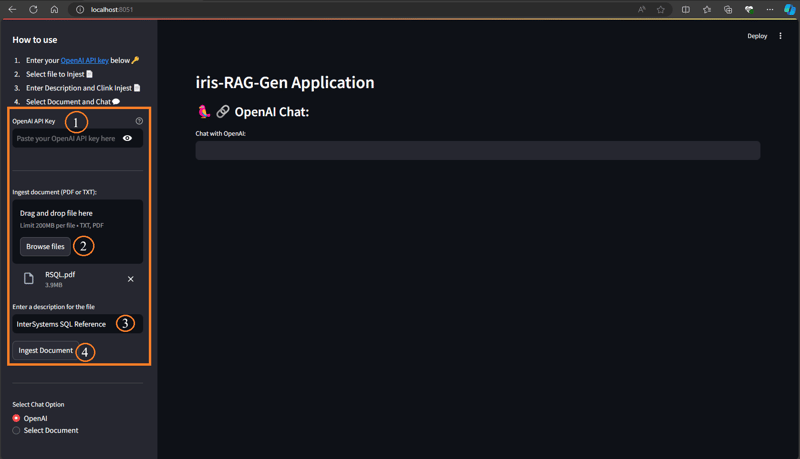
Die Funktion „Dokument aufnehmen“ fügt Dokumentdetails in die Tabelle „rag_documents“ ein und erstellt die Tabelle „rag_document id“ (ID der rag_documents), um Vektordaten zu speichern.

Der folgende Python-Code speichert das ausgewählte Dokument in Vektoren:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings
from sqlalchemy import create_engine,text
<span>class RagOpr:</span>
#Ingest document. Parametres contains file path, description and file type
<span>def ingestDoc(self,filePath,fileDesc,fileType):</span>
embeddings = OpenAIEmbeddings()
#Load the document based on the file type
if fileType == "text/plain":
loader = TextLoader(filePath)
elif fileType == "application/pdf":
loader = PyPDFLoader(filePath)
#load data into documents
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
#Split text into chunks
texts = text_splitter.split_documents(documents)
#Get collection Name from rag_doucments table.
COLLECTION_NAME = self.get_collection_name(fileDesc,fileType)
# function to create collection_name table and store vector data in it.
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
#Get collection name
<span>def get_collection_name(self,fileDesc,fileType):</span>
# check if rag_documents table exists, if not then create it
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'SQLUser'
AND TABLE_NAME = 'rag_documents';
""")
result = []
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
#if table is not created, then create rag_documents table first
if len(result) == 0:
sql = text("""
CREATE TABLE rag_documents (
description VARCHAR(255),
docType VARCHAR(50) )
""")
try:
result = conn.execute(sql)
except Exception as err:
print("An exception occurred:", err)
return ''
#Insert description value
with self.engine.connect() as conn:
with conn.begin():
sql = text("""
INSERT INTO rag_documents
(description,docType)
VALUES (:desc,:ftype)
""")
try:
result = conn.execute(sql, {'desc':fileDesc,'ftype':fileType})
except Exception as err:
print("An exception occurred:", err)
return ''
#select ID of last inserted record
sql = text("""
SELECT LAST_IDENTITY()
""")
try:
result = conn.execute(sql).fetchall()
except Exception as err:
print("An exception occurred:", err)
return ''
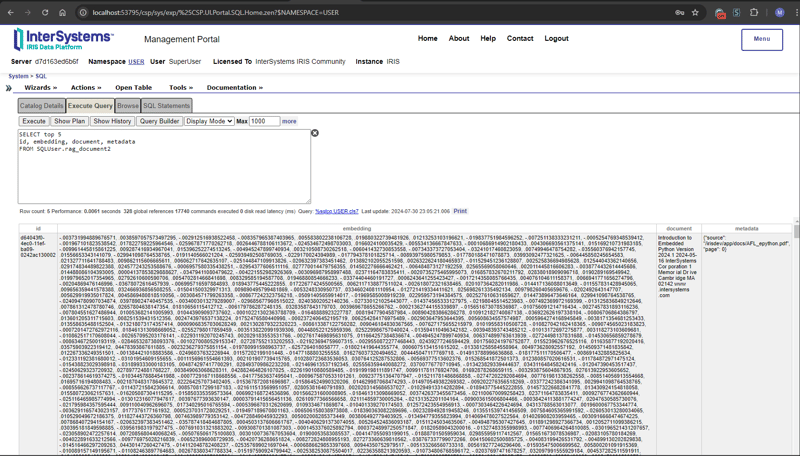
return "rag_document"+str(result[0][0])Geben Sie den folgenden SQL-Befehl im Verwaltungsportal ein, um Vektordaten abzurufen
SELECT top 5 id, embedding, document, metadata FROM SQLUser.rag_document2
Chatten Sie mit dem ausgewählten aufgenommenen Dokument
Wählen Sie das Dokument im Abschnitt „Chat-Option auswählen“ aus und geben Sie die Frage ein. Die Anwendung liest die Vektordaten und gibt die entsprechende Antwort zurück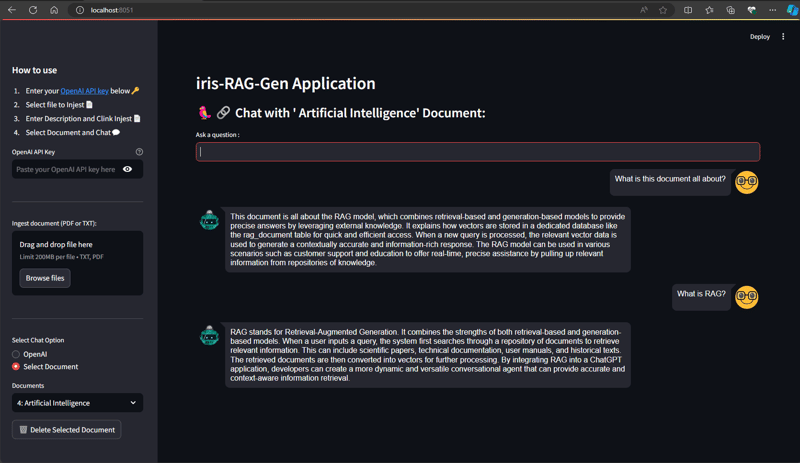
Der folgende Python-Code speichert das ausgewählte Dokument in Vektoren:
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings,ChatOpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationSummaryMemory
from langchain.chat_models import ChatOpenAI
<span>class RagOpr:</span>
<span>def ragSearch(self,prompt,id):</span>
#Concat document id with rag_doucment to get the collection name
COLLECTION_NAME = "rag_document"+str(id)
embeddings = OpenAIEmbeddings()
#Get vector store reference
db2 = IRISVector (
embedding_function=embeddings,
collection_name=COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
#Similarity search
docs_with_score = db2.similarity_search_with_score(prompt)
#Prepair the retrieved documents to pass to LLM
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
#init LLM
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo"
)
#manage and handle LangChain multi-turn conversations
conversation_sum = ConversationChain(
llm=llm,
memory= ConversationSummaryMemory(llm=llm),
verbose=False
)
#Create prompt
template = f"""
Prompt: <span>{prompt}
Relevant Docuemnts: {relevant_docs}
"""</span>
#Return the answer
resp = conversation_sum(template)
return resp['response']
Weitere Informationen finden Sie auf der Seite „offene Austauschbewerbung“ von iris-RAG-Gen.
Danke
Das obige ist der detaillierte Inhalt vonIRIS-RAG-Gen: Personalisierung der ChatGPT RAG-Anwendung, unterstützt von IRIS Vector Search. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?
Apr 02, 2025 am 07:15 AM
Wie kann man vom Browser vermeiden, wenn man überall Fiddler für das Lesen des Menschen in der Mitte verwendet?
Apr 02, 2025 am 07:15 AM
Wie kann man nicht erkannt werden, wenn Sie Fiddlereverywhere für Man-in-the-Middle-Lesungen verwenden, wenn Sie FiddLereverywhere verwenden ...
 Wie behandle ich die mit Kommas getrennten Listen-Abfrageparameter in Fastapi?
Apr 02, 2025 am 06:51 AM
Wie behandle ich die mit Kommas getrennten Listen-Abfrageparameter in Fastapi?
Apr 02, 2025 am 06:51 AM
Fastapi ...
 Wie löste ich Berechtigungsprobleme bei der Verwendung von Python -Verssionsbefehl im Linux Terminal?
Apr 02, 2025 am 06:36 AM
Wie löste ich Berechtigungsprobleme bei der Verwendung von Python -Verssionsbefehl im Linux Terminal?
Apr 02, 2025 am 06:36 AM
Verwenden Sie Python im Linux -Terminal ...
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?
Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?
Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...
 Python Asyncio Telnet Connection wird sofort getrennt: Wie löst ich das serverseitige Blockierungsproblem?
Apr 02, 2025 am 06:30 AM
Python Asyncio Telnet Connection wird sofort getrennt: Wie löst ich das serverseitige Blockierungsproblem?
Apr 02, 2025 am 06:30 AM
Über Pythonasyncio ...
 Wie bekomme ich Nachrichtendaten, die den Anti-Crawler-Mechanismus von Investing.com umgehen?
Apr 02, 2025 am 07:03 AM
Wie bekomme ich Nachrichtendaten, die den Anti-Crawler-Mechanismus von Investing.com umgehen?
Apr 02, 2025 am 07:03 AM
Verständnis der Anti-Crawling-Strategie von Investing.com Viele Menschen versuchen oft, Nachrichten von Investing.com (https://cn.investing.com/news/latest-news) zu kriechen ...
 Python 3.6 Laden Sie Giftedatei Fehler ModulenotFoundError: Was soll ich tun, wenn ich die Gurkendatei '__builtin__' lade?
Apr 02, 2025 am 06:27 AM
Python 3.6 Laden Sie Giftedatei Fehler ModulenotFoundError: Was soll ich tun, wenn ich die Gurkendatei '__builtin__' lade?
Apr 02, 2025 am 06:27 AM
Laden Sie die Gurkendatei in Python 3.6 Umgebungsfehler: ModulenotFoundError: Nomodulenamed ...
 Was ist der Grund, warum Pipeline -Dateien bei der Verwendung von Scapy Crawler nicht geschrieben werden können?
Apr 02, 2025 am 06:45 AM
Was ist der Grund, warum Pipeline -Dateien bei der Verwendung von Scapy Crawler nicht geschrieben werden können?
Apr 02, 2025 am 06:45 AM
Diskussion über die Gründe, warum Pipeline -Dateien beim Lernen und Verwendung von Scapy -Crawlern für anhaltende Datenspeicher nicht geschrieben werden können, können Sie auf Pipeline -Dateien begegnen ...
