

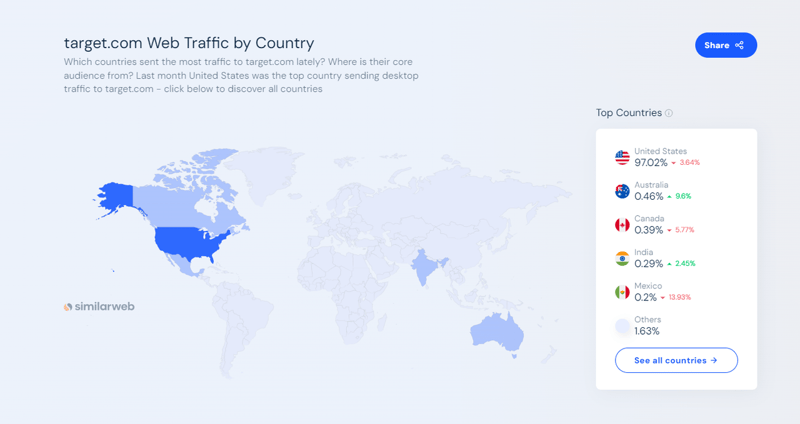
Target.com ist einer der größten E-Commerce- und Shopping-Marktplätze Amerikas. Es ermöglicht Verbrauchern, online und im Geschäft alles einzukaufen, von Lebensmitteln und Grundbedarf bis hin zu Kleidung und Elektronik. Laut Daten von SimilarWeb verzeichnet Target.com im September 2024 einen monatlichen Web-Traffic von mehr als 166 Millionen.
Die Target.com-Website bietet unter anderem Kundenrezensionen, dynamische Preisinformationen, Produktvergleiche und Produktbewertungen. Es ist eine wertvolle Datenquelle für Analysten, Marketingteams, Unternehmen oder Forscher, die entweder Produkttrends verfolgen, die Preise der Konkurrenz überwachen oder die Stimmung der Kunden anhand von Bewertungen analysieren möchten.
In diesem Artikel erfahren Sie, wie Sie:
Am Ende dieses Artikels erfahren Sie, wie Sie mit Python, Selenium und ScraperAPI Produktbewertungen und -bewertungen von Target.com sammeln, ohne blockiert zu werden. Außerdem erfahren Sie, wie Sie Ihre Scraped-Daten für die Stimmungsanalyse verwenden.
Wenn Sie aufgeregt sind, während ich dieses Tutorial schreibe, lassen Sie uns gleich loslegen. ?
Für diejenigen, die es eilig haben, hier ist der vollständige Codeausschnitt, den wir in diesem Tutorial aufbauen werden:
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Sehen Sie sich den vollständigen Code auf GitHub an: https://github.com/Eunit99/target_com_scraper. Möchten Sie jede Codezeile verstehen? Lasst uns gemeinsam den Web Scraper von Grund auf neu bauen!
In einem früheren Artikel haben wir alles behandelt, was Sie zum Scrapen von Target.com-Produktdaten wissen müssen. In diesem Artikel werde ich mich jedoch darauf konzentrieren, Ihnen zu zeigen, wie Sie Target.com mit Python und ScraperAPI nach Produktbewertungen und Rezensionen durchsuchen.
Um diesem Tutorial zu folgen und mit dem Scraping von Target.com zu beginnen, müssen Sie zunächst ein paar Dinge tun.
Beginnen Sie mit einem kostenlosen Konto bei ScraperAPI. Mit ScraperAPI können Sie mit unserer benutzerfreundlichen API für Web-Scraping ohne komplexe und teure Problemumgehungen mit dem Sammeln von Daten aus Millionen von Webquellen beginnen.
ScraperAPI erschließt selbst die anspruchsvollsten Websites, reduziert Infrastruktur- und Entwicklungskosten, ermöglicht Ihnen die schnellere Bereitstellung von Web-Scrapern und gibt Ihnen außerdem 1.000 API-Credits kostenlos, um Dinge zuerst auszuprobieren, und vieles mehr.
Verwenden Sie einen Code-Editor wie Visual Studio Code. Weitere Optionen sind Sublime Text oder PyCharm.
Bevor Sie mit dem Scrapen von Target.com-Bewertungen beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
Es empfiehlt sich, eine virtuelle Umgebung für Python-Projekte zu verwenden, um Abhängigkeiten zu verwalten und Konflikte zu vermeiden.
Um eine virtuelle Umgebung zu erstellen, führen Sie diesen Befehl in Ihrem Terminal aus:
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Aktivieren Sie die virtuelle Umgebung basierend auf Ihrem Betriebssystem:
python3 -m venv env
Einige IDEs können die virtuelle Umgebung automatisch aktivieren.
Um diesem Artikel effektiv folgen zu können, ist es wichtig, über ein grundlegendes Verständnis von CSS-Selektoren zu verfügen. CSS-Selektoren werden verwendet, um auf bestimmte HTML-Elemente auf einer Webseite abzuzielen, sodass Sie die benötigten Informationen extrahieren können.
Außerdem ist es wichtig, mit den Browser-DevTools vertraut zu sein, um die Struktur von Webseiten zu überprüfen und zu identifizieren.
Nachdem die oben genannten Voraussetzungen erfüllt sind, ist es an der Zeit, Ihr Projekt einzurichten. Erstellen Sie zunächst einen Ordner, der den Quellcode des Target.com-Scrapers enthält. In diesem Fall nenne ich meinen Ordner python-target-dot-com-scraper.
Führen Sie die folgenden Befehle aus, um einen Ordner mit dem Namen python-target-dot-com-scraper zu erstellen:
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
Geben Sie den Ordner ein und erstellen Sie eine neue Python-Datei „main.py“, indem Sie die folgenden Befehle ausführen:
mkdir python-target-dot-com-scraper
Erstellen Sie eine Datei „requirements.txt“, indem Sie den folgenden Befehl ausführen:
cd python-target-dot-com-scraper && touch main.py
Für diesen Artikel verwende ich die Bibliotheken Selenium und Beautiful Soup sowie den Webdriver Manager für Python, um den Web Scraper zu erstellen. Selenium übernimmt die Browserautomatisierung und die Beautiful Soup-Bibliothek extrahiert Daten aus dem HTML-Inhalt der Target.com-Website. Gleichzeitig bietet der Webdriver Manager für Python eine Möglichkeit, Treiber für verschiedene Browser automatisch zu verwalten.
Fügen Sie die folgenden Zeilen zu Ihrer Datei „requirements.txt“ hinzu, um die erforderlichen Pakete anzugeben:
touch requirements.txt
Um die Pakete zu installieren, führen Sie den folgenden Befehl aus:
selenium~=4.25.0 bs4~=0.0.2 python-dotenv~=1.0.1 webdriver_manager selenium-wire blinker==1.7.0 python-dotenv==1.0.1
In diesem Abschnitt werde ich Sie durch eine Schritt-für-Schritt-Anleitung zum Erhalten von Produktbewertungen und Rezensionen von einer Produktseite wie dieser von Target.com führen.
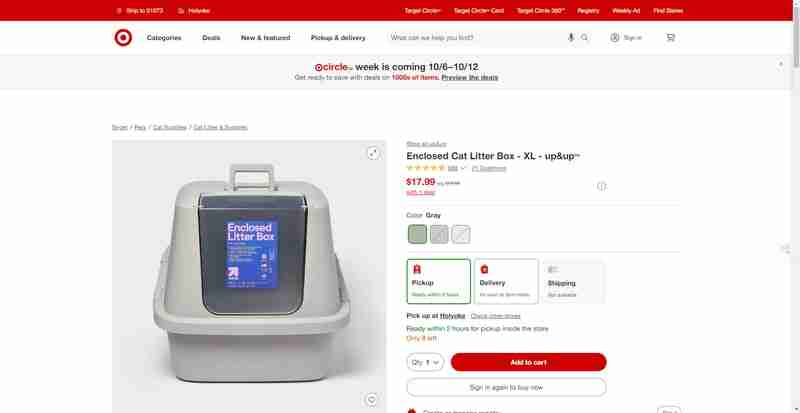
Ich werde mich auf die Rezensionen und Bewertungen dieser Abschnitte der Website konzentrieren, die in diesem Screenshot unten hervorgehoben sind:
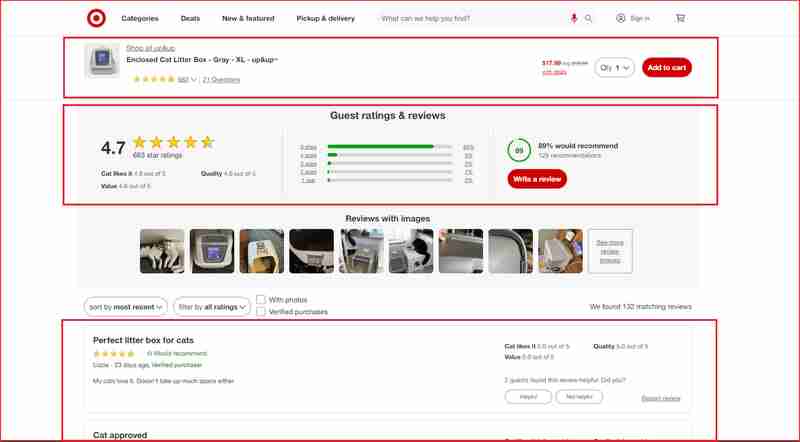
Bevor Sie weiter darauf eingehen, müssen Sie die HTML-Struktur verstehen und den DOM-Selektor identifizieren, der mit dem HTML-Tag verknüpft ist, der die Informationen umschließt, die wir extrahieren möchten. In diesem nächsten Abschnitt werde ich Sie durch die Verwendung der Chrome DevTools führen, um die Site-Struktur von Target.com zu verstehen.
Öffnen Sie Chrome DevTools, indem Sie F12 drücken oder mit der rechten Maustaste auf eine beliebige Stelle auf der Seite klicken und „Inspizieren“ wählen. Die Überprüfung der Seite über die obige URL zeigt Folgendes:
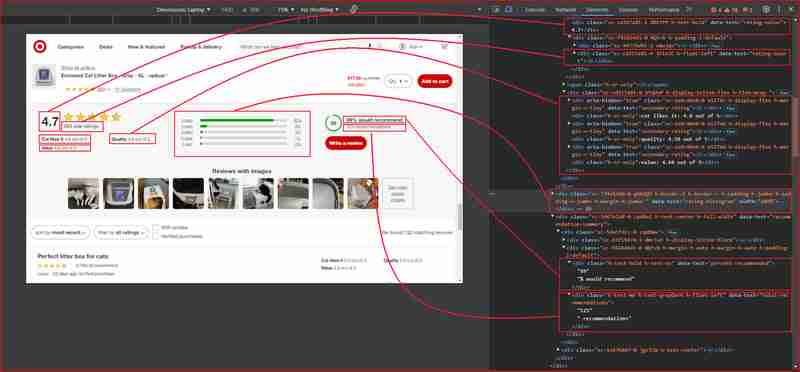
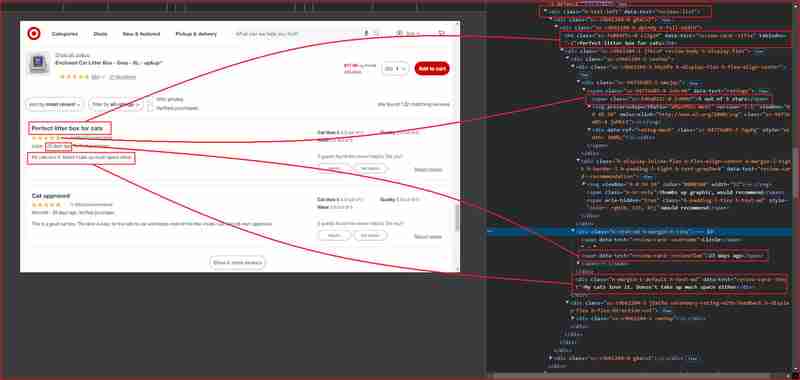
Auf den obigen Bildern sind hier alle DOM-Selektoren aufgeführt, auf die der Web Scraper abzielt, um die Informationen zu extrahieren:
| Information | DOM selector | Value |
|---|---|---|
| Product ratings | ||
| Rating value | div[data-test='rating-value'] | 4.7 |
| Rating count | div[data-test='rating-count'] | 683 star ratings |
| Secondary rating | div[data-test='secondary-rating'] | 683 star ratings |
| Rating histogram | div[data-test='rating-histogram'] | 5 stars 85%4 stars 8%3 stars 3%2 stars 1%1 star 2% |
| Percent recommended | div[data-test='percent-recommended'] | 89% would recommend |
| Total recommendations | div[data-test='total-recommendations'] | 125 recommendations |
| Product reviews | ||
| Reviews list | div[data-test='reviews-list'] | Returns children elements corresponding to individual product review |
| Review card title | h4[data-test='review-card--title'] | Perfect litter box for cats |
| Ratings | span[data-test='ratings'] | 4.7 out of 5 stars with 683 reviews |
| Review time | span[data-test='review-card--reviewTime'] | 23 days ago |
| Review card text | div[data-test='review-card--text'] | My cats love it. Doesn't take up much space either |
Jetzt haben wir alle Anforderungen dargelegt und die verschiedenen Elemente, die uns interessieren, auf der Produktbewertungsseite von Target.com gefunden. Wir gehen zum nächsten Schritt über, der den Import der notwendigen Module beinhaltet:
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
In diesem Code dient jedes Modul einem bestimmten Zweck zum Aufbau unseres Web Scrapers:
In diesem Schritt initialisieren Sie den Chrome WebDriver von Selenium und konfigurieren wichtige Browseroptionen. Zu diesen Optionen gehören das Deaktivieren unnötiger Funktionen zur Leistungssteigerung, das Festlegen der Fenstergröße und das Verwalten von Protokollen. Sie instanziieren den WebDriver mit webdriver.Chrome(), um den Browser während des Scraping-Vorgangs zu steuern.
python3 -m venv env
In diesem Abschnitt erstellen wir eine Funktion zum Scrollen durch die gesamte Seite. Die Target.com-Website lädt zusätzliche Inhalte (z. B. Bewertungen) dynamisch, wenn der Benutzer nach unten scrollt.
# On Unix or MacOS (bash shell): /path/to/venv/bin/activate # On Unix or MacOS (csh shell): /path/to/venv/bin/activate.csh # On Unix or MacOS (fish shell): /path/to/venv/bin/activate.fish # On Windows (command prompt): \path\to\venv\Scripts\activate.bat # On Windows (PowerShell): \path\to\venv\Scripts\Activate.ps1
Die Funktion scroll_down_page() scrollt die Webseite schrittweise um eine festgelegte Anzahl von Pixeln (Entfernung) mit einer kurzen Pause (Verzögerung) zwischen jedem Scrollen. Es berechnet zunächst die Gesamthöhe der Seite und scrollt nach unten, bis das Ende erreicht ist. Beim Scrollen wird die gesamte Seitenhöhe dynamisch aktualisiert, um neuen Inhalten Rechnung zu tragen, die während des Vorgangs geladen werden können.
In diesem Abschnitt kombinieren wir die Stärken von Selenium und BeautifulSoup, um ein effizientes und zuverlässiges Web-Scraping-Setup zu erstellen. Während Selenium zur Interaktion mit dynamischen Inhalten wie dem Laden von Seiten und der Verarbeitung von JavaScript-gerenderten Elementen verwendet wird, ist BeautifulSoup effektiver beim Parsen und Extrahieren statischer HTML-Elemente. Wir verwenden Selenium zunächst zum Navigieren auf der Webseite und warten darauf, dass bestimmte Elemente wie Produktbewertungen und die Anzahl der Rezensionen geladen werden. Diese Elemente werden mit der WebDriverWait-Funktion von Selenium extrahiert, die sicherstellt, dass die Daten sichtbar sind, bevor sie erfasst werden. Allerdings kann die Bearbeitung einzelner Bewertungen allein über Selenium komplex und ineffizient werden.
Mit BeautifulSoup vereinfachen wir das Durchlaufen mehrerer Bewertungen auf der Seite. Sobald Selenium die Seite vollständig geladen hat, analysiert BeautifulSoup den HTML-Inhalt, um Bewertungen effizient zu extrahieren. Mit den Methoden select() und select_one() von BeautifulSoup können wir durch die Seitenstruktur navigieren und den Titel, die Bewertung, die Zeit und den Text für jede Rezension erfassen. Dieser Ansatz ermöglicht ein saubereres, strukturierteres Scraping wiederholter Elemente (z. B. Bewertungslisten) und bietet eine größere Flexibilität bei der Handhabung des HTML im Vergleich zur alleinigen Verwaltung alles über Selenium.
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Beim Scraping komplexer Websites, insbesondere solcher mit robusten Anti-Bot-Maßnahmen wie Target.com, treten häufig Herausforderungen wie IP-Verbote, Ratenbegrenzungen oder Zugriffsbeschränkungen auf. Die Verwendung von Selenium für solche Aufgaben wird kompliziert, insbesondere wenn ein Headless-Browser bereitgestellt wird. Headless-Browser ermöglichen eine Interaktion ohne GUI, die manuelle Verwaltung von Proxys wird in dieser Umgebung jedoch zu einer Herausforderung. Sie müssen Proxy-Einstellungen konfigurieren, IPs rotieren und andere Interaktionen wie JavaScript-Rendering verarbeiten, wodurch das Scraping langsamer und fehleranfälliger wird.
Im Gegensatz dazu rationalisiert ScraperAPI diesen Prozess erheblich, indem Proxys automatisch verwaltet werden. Anstatt sich mit manuellen Konfigurationen in Selenium zu befassen, verteilt der Proxy-Modus von ScraperAPI Anfragen auf mehrere IP-Adressen und sorgt so für ein reibungsloseres Scraping, ohne sich Gedanken über IP-Verbote, Ratenbeschränkungen oder geografische Einschränkungen machen zu müssen. Dies ist besonders nützlich bei der Arbeit mit Headless-Browsern, bei denen die Verarbeitung dynamischer Inhalte und komplexer Website-Interaktionen zusätzliche Codierung erfordert.
Die Integration des Proxy-Modus von ScraperAPI in Selenium wird durch die Verwendung von Selenium Wire vereinfacht, einem Tool, das eine einfache Proxy-Konfiguration ermöglicht. Hier ist eine schnelle Einrichtung:
Nach der Integration ermöglicht diese Konfiguration reibungslosere Interaktionen mit dynamischen Seiten, automatisch rotierenden IP-Adressen und die Umgehung von Ratenbeschränkungen, ohne dass der manuelle Aufwand für die Verwaltung von Proxys in einer Headless-Browserumgebung anfällt.
Das folgende Snippet zeigt, wie der Proxy von ScraperAPI in Python konfiguriert wird:
import os
import time
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from selenium.common.exceptions import NoSuchElementException, TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# Load environment variables
load_dotenv()
def target_com_scraper():
"""
SCRAPER SETTINGS
- API_KEY: Your ScraperAPI key. Get your API Key ==> https://www.scraperapi.com/?fp_ref=eunit
"""
API_KEY = os.getenv("API_KEY", "yourapikey")
# ScraperAPI proxy settings (with HTTP and HTTPS variants)
scraper_api_proxies = {
'proxy': {
'http': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'http://scraperapi:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# URLs to scrape
url_list = [
"https://www.target.com/p/enclosed-cat-litter-box-xl-up-up/-/A-90310047?preselect=87059440#lnk=sametab",
]
# Store scraped data
scraped_data = []
# Setup Selenium options with proxy
options = Options()
# options.add_argument("--headless") # Uncomment for headless mode
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-extensions")
options.add_argument("--disable-in-process-stack-traces")
options.add_argument("--window-size=1920,1080")
options.add_argument("--log-level=3")
options.add_argument("--disable-logging")
options.add_argument("--start-maximized")
# Initialize Selenium WebDriver
driver = webdriver.Chrome(service=ChromeService(
ChromeDriverManager().install()), options=options, seleniumwire_options=scraper_api_proxies)
def scroll_down_page(distance=100, delay=0.2):
"""
Scroll down the page gradually until the end.
Args:
- distance: Number of pixels to scroll by in each step.
- delay: Time (in seconds) to wait between scrolls.
"""
total_height = driver.execute_script(
"return document.body.scrollHeight")
scrolled_height = 0
while scrolled_height < total_height:
# Scroll down by 'distance' pixels
driver.execute_script(f"window.scrollBy(0, {distance});")
scrolled_height += distance
time.sleep(delay) # Pause between scrolls
# Update the total page height after scrolling
total_height = driver.execute_script(
"return document.body.scrollHeight")
print("Finished scrolling.")
try:
for url in url_list:
# Use Selenium to load the page
driver.get(url)
time.sleep(5) # Give the page time to load
# Scroll down the page
scroll_down_page()
# Extract single elements with Selenium
def extract_element_text(selector, description):
try:
# Wait for the element and extract text
element = WebDriverWait(driver, 5).until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, selector))
)
text = element.text.strip()
return text if text else None # Return None if the text is empty
except TimeoutException:
print(f"Timeout: Could not find {description}. Setting to None.")
return None
except NoSuchElementException:
print(f"Element not found: {description}. Setting to None.")
return None
# Extract single elements
reviews_data = {}
reviews_data["secondary_rating"] = extract_element_text("div[data-test='secondary-rating']",
"secondary_rating")
reviews_data["rating_count"] = extract_element_text(
"div[data-test='rating-count']", "rating_count")
reviews_data["rating_histogram"] = extract_element_text("div[data-test='rating-histogram']",
"rating_histogram")
reviews_data["percent_recommended"] = extract_element_text("div[data-test='percent-recommended']",
"percent_recommended")
reviews_data["total_recommendations"] = extract_element_text("div[data-test='total-recommendations']",
"total_recommendations")
# Extract reviews from 'reviews-list'
scraped_reviews = []
# Use Beautiful Soup to extract other content
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Select all reviews in the list using BeautifulSoup
reviews_list = soup.select("div[data-test='reviews-list'] > div")
for review in reviews_list:
# Create a dictionary to store each review's data
ratings = {}
# Extract title
title_element = review.select_one(
"h4[data-test='review-card--title']")
ratings['title'] = title_element.text.strip(
) if title_element else None
# Extract rating
rating_element = review.select_one("span[data-test='ratings']")
ratings['rating'] = rating_element.text.strip(
) if rating_element else None
# Extract time
time_element = review.select_one(
"span[data-test='review-card--reviewTime']")
ratings['time'] = time_element.text.strip(
) if time_element else None
# Extract review text
text_element = review.select_one(
"div[data-test='review-card--text']")
ratings['text'] = text_element.text.strip(
) if text_element else None
# Append each review to the list of reviews
scraped_reviews.append(ratings)
# Append the list of reviews to the main product data
reviews_data["reviews"] = scraped_reviews
# Append the overall data to the scraped_data list
scraped_data.append(reviews_data)
# Output the scraped data
print(f"Scraped data: {scraped_data}")
except Exception as e:
print(f"Error: {e}")
finally:
# Ensure driver quits after scraping
driver.quit()
if __name__ == "__main__":
target_com_scraper()
Mit diesem Setup werden an den ScraperAPI-Proxyserver gesendete Anfragen an die Target.com-Website umgeleitet, wodurch Ihre echte IP verborgen bleibt und ein robuster Schutz gegen Anti-Scraping-Mechanismen der Target.com-Website bereitgestellt wird. Der Proxy kann auch angepasst werden, indem Parameter wie render=true für die JavaScript-Wiedergabe eingefügt oder ein Ländercode für die Geolokalisierung angegeben wird.
Der folgende JSON-Code ist ein Beispiel der Antwort mit dem Target Reviews Scraper:
python3 -m venv env
Wenn Sie Ihre Target.com-Bewertungen schnell erhalten möchten, ohne Ihre Umgebung einzurichten, zu programmieren oder Proxys einzurichten, können Sie unsere Target Scraper API verwenden, um die Daten, die Sie benötigen, kostenlos zu erhalten. Die Target Scraper API wird auf der Apify-Plattform gehostet und ist ohne Einrichtung einsatzbereit.
Gehen Sie zu Apify und klicken Sie auf „Kostenlos testen“, um jetzt loszulegen.

Da Sie nun Ihre Bewertungs- und Bewertungsdaten von Target.com haben, ist es an der Zeit, diese Daten zu verstehen. Diese Rezensionen und Bewertungsdaten können wertvolle Einblicke in die Meinungen der Kunden zu einem bestimmten Produkt oder einer bestimmten Dienstleistung liefern. Durch die Analyse dieser Bewertungen können Sie häufiges Lob und Beschwerden erkennen, die Kundenzufriedenheit messen, zukünftiges Verhalten vorhersagen und diese Bewertungen in umsetzbare Erkenntnisse umwandeln.
Als Marketingprofi oder Geschäftsinhaber, der nach Möglichkeiten sucht, Ihre Hauptzielgruppe besser zu verstehen und Ihre Marketing- und Produktstrategien zu verbessern. Im Folgenden finden Sie einige Möglichkeiten, wie Sie diese Daten in umsetzbare Erkenntnisse umwandeln können, um Marketingbemühungen zu optimieren, Produktstrategien zu verbessern und die Kundenbindung zu steigern:
Durch die Verwendung von ScraperAPI zum Sammeln umfangreicher Bewertungsdaten in großem Maßstab können Sie Stimmungsanalysen automatisieren und skalieren und so eine bessere Entscheidungsfindung und Wachstum ermöglichen.
Ja, es ist legal, Target.com nach öffentlich zugänglichen Informationen wie Produktbewertungen und Rezensionen zu durchsuchen. Es ist jedoch wichtig zu bedenken, dass diese öffentlichen Informationen möglicherweise dennoch persönliche Daten enthalten.
Wir haben einen Blogbeitrag über die rechtlichen Aspekte von Web Scraping und ethische Überlegungen geschrieben. Dort erfahren Sie mehr.
Ja, Target.com implementiert verschiedene Anti-Scraping-Maßnahmen, um automatisierte Scraper zu blockieren. Dazu gehören IP-Blockierung, Ratenbegrenzung und CAPTCHA-Herausforderungen, die alle darauf ausgelegt sind, übermäßige, automatisierte Anfragen von Scrapern oder Bots zu erkennen und zu stoppen.
Um eine Blockierung durch Target.com zu vermeiden, sollten Sie die Anzahl der Anfragen verlangsamen, Benutzeragenten rotieren, CAPTCHA-Lösungstechniken verwenden und wiederholte oder häufige Anfragen vermeiden. Die Kombination dieser Methoden mit Proxys kann dazu beitragen, die Erkennungswahrscheinlichkeit zu verringern.
Erwägen Sie außerdem die Verwendung dedizierter Scraper wie der Target Scraper API oder der Scraping API, um diese Target.com-Einschränkungen zu umgehen.
Ja, die Verwendung von Proxys ist für ein effektives Scraping von Target.com unerlässlich. Proxys helfen dabei, Anfragen auf mehrere IP-Adressen zu verteilen und minimieren so das Risiko einer Blockierung. ScraperAPI-Proxys verbergen Ihre IP, wodurch es für Anti-Scraping-Systeme schwieriger wird, Ihre Aktivitäten zu erkennen.
In diesem Artikel haben Sie erfahren, wie Sie mit Python und Selenium einen Target.com-Bewertungs- und Rezensions-Scraper erstellen und ScraperAPI verwenden, um die Anti-Scraping-Mechanismen von Target.com effektiv zu umgehen, IP-Verbote zu vermeiden und die Scraping-Leistung zu verbessern.
Mit diesem Tool können Sie effizient und zuverlässig wertvolles Kundenfeedback sammeln.
Sobald Sie diese Daten gesammelt haben, besteht der nächste Schritt darin, mithilfe der Stimmungsanalyse wichtige Erkenntnisse zu gewinnen. Durch die Analyse von Kundenbewertungen können Sie als Unternehmen Produktstärken identifizieren, Schwachstellen angehen und Ihre Marketingstrategien optimieren, um die Bedürfnisse Ihrer Kunden besser zu erfüllen.
Durch die Verwendung der Target Scraper API für die umfangreiche Datenerfassung können Sie Bewertungen kontinuierlich überwachen und die Kundenstimmung besser verstehen, sodass Sie die Produktentwicklung verfeinern und gezieltere Marketingkampagnen erstellen können.
Testen Sie jetzt ScraperAPI für die nahtlose Extraktion großer Datenmengen oder nutzen Sie unseren Cloud Target.com Reviews Scraper!
Für weitere Tutorials und tolle Inhalte folgen Sie mir bitte auf Twitter (X) @eunit99
Das obige ist der detaillierte Inhalt vonSo kratzen Sie Target.com-Bewertungen mit Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So entfernen Sie den Rand des Textfelds
So entfernen Sie den Rand des Textfelds
 Lösung für die Blockierung von Google Mail
Lösung für die Blockierung von Google Mail
 So kaufen Sie Dogecoin
So kaufen Sie Dogecoin
 Verwendung der MySQL-Datediff-Funktion
Verwendung der MySQL-Datediff-Funktion
 Die Rolle der Subnetzmaske
Die Rolle der Subnetzmaske
 Detaillierte Erläuterung der Verwendung der Oracle-Substr-Funktion
Detaillierte Erläuterung der Verwendung der Oracle-Substr-Funktion
 Was bedeutet Open-Source-Code?
Was bedeutet Open-Source-Code?
 So lesen Sie Py-Dateien in Python
So lesen Sie Py-Dateien in Python








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



